NLTK Tokenize: Words and Sentences Tokenizer with Example
⚡ Smart Summary
NLTK Tokenize splits large text into smaller units called tokens, a foundational step in natural language processing. The toolkit provides word_tokenize for breaking sentences into words and sent_tokenize for dividing text into individual sentences.

What is Tokenization?
Tokenization is the process by which a large quantity of text is divided into smaller parts called tokens. These tokens are very useful for finding patterns and are considered as a base step for stemming and lemmatization. Tokenization also helps to substitute sensitive data elements with non-sensitive data elements.
Natural language processing is used for building applications such as Text classification, intelligent chatbot, sentimental analysis, language translation, etc. It becomes vital to understand the pattern in the text to achieve the above-stated purpose.
For the time being, don’t worry about stemming and lemmatization but treat them as steps for textual data cleaning using NLP (Natural language processing). We will discuss stemming and lemmatization later in the tutorial. Tasks such as Text classification or spam filtering makes use of NLP along with deep learning libraries such as Keras and Tensorflow.
Natural Language toolkit has very important module NLTK tokenize sentences which further comprises of sub-modules
- word tokenize
- sentence tokenize
Tokenization of words
We use the method word_tokenize() to split a sentence into words. The output of word tokenization can be converted to Data Frame for better text understanding in machine learning applications. It can also be provided as input for further text cleaning steps such as punctuation removal, numeric character removal or stemming. Machine learning models need numeric data to be trained and make a prediction. Word tokenization becomes a crucial part of the text (string) to numeric data conversion. Please read about Bag of Words or CountVectorizer. Please refer to below word tokenize NLTK example to understand the theory better.
from nltk.tokenize import word_tokenize text = "God is Great! I won a lottery." print(word_tokenize(text)) Output: ['God', 'is', 'Great', '!', 'I', 'won', 'a', 'lottery', '.']
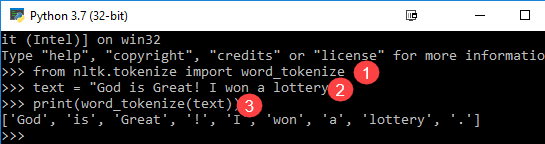
Code Explanation
- word_tokenize module is imported from the NLTK library.
- A variable “text” is initialized with two sentences.
- Text variable is passed in word_tokenize module and printed the result. This module breaks each word with punctuation which you can see in the output.
Tokenization of Sentences
Sub-module available for the above is sent_tokenize. An obvious question in your mind would be why sentence tokenization is needed when we have the option of word tokenization. Imagine you need to count average words per sentence, how you will calculate? For accomplishing such a task, you need both NLTK sentence tokenizer as well as NLTK word tokenizer to calculate the ratio. Such output serves as an important feature for machine training as the answer would be numeric.
Check the below NLTK tokenizer example to learn how sentence tokenization is different from words tokenization.
from nltk.tokenize import sent_tokenize text = "God is Great! I won a lottery." print(sent_tokenize(text)) Output: ['God is Great!', 'I won a lottery ']
We have 12 words and two sentences for the same input.
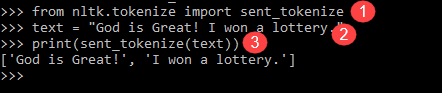
Explanation of the program
- In a line like the previous program, imported the sent_tokenize module.
- We have taken the same sentence. Further sentence tokenizer in NLTK module parsed that sentences and show output. It is clear that this function breaks each sentence.
Above word tokenizer Python examples are good settings stones to understand the mechanics of the word and sentence tokenization.