PyTorch Tutorial
⚡ Smart Summary
PyTorch is the open-source deep learning framework from Meta, now powering 85 percent of AI research papers in 2026. Lessons cover installation, framework basics, simple regression, image classification, and AWS SageMaker deployment.

What is PyTorch?
PyTorch is an open-source Torch based Machine Learning library for natural language processing using Python. It is similar to NumPy but with powerful GPU support. It offers Dynamic Computational Graphs that you can modify on the go with the help of autograd. PyTorch is also faster than some other frameworks. It was developed by Facebook’s AI Research Group in 2016.
Knowing what PyTorch is sets up a balanced look at its strengths and drawbacks.
PyTorch Advantages and Disadvantages
Following are the advantages and disadvantages of PyTorch:
Advantages of PyTorch
- Simple Library
PyTorch code is simple. It is easy to understand, and you use the library instantly. For example, take a look at the code snippet below:
class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.layer = torch.nn.Linear(1, 1) def forward(self, x): x = self.layer(x) return x
As mentioned above, you can define the network model easily, and you can understand the code quickly without much training.
- Dynamic Computational Graph

Image Source: Exploring Deep Learning with PyTorch
PyTorch offers Dynamic Computational Graph (DAG). Computational graphs is a way to express mathematical expressions in graph models or theories such as nodes and edges. The node will do the mathematical operation, and the edge is a Tensor that will be fed into the nodes and carries the output of the node in Tensor.
DAG is a graph that holds arbitrary shape and able to do operations between different input graphs. Every iteration, a new graph is created. So, it is possible to have the same graph structure or create a new graph with a different operation, or we can call it a dynamic graph.
- Better Performance
Communities and researchers, benchmark and compare frameworks to see which one is faster. A GitHub repo Benchmark on Deep Learning Frameworks and GPUs reported that PyTorch is faster than the other framework in terms of images processed per second.
As you can see below, the comparison graphs with vgg16 and resnet152


- Native Python
PyTorch is more python based. For example, if you want to train a model, you can use native control flow such as looping and recursions without the need to add more special variables or sessions to be able to run them. This is very helpful for the training process.
PyTorch also implements Imperative Programming, and it’s definitely more flexible. So, it’s possible to print out the tensor value in the middle of a computation process.
Disadvantage of PyTorch
PyTorch requires third-party applications for Visualization. It also needs an API server for production.
Next in this PyTorch tutorial, we will learn about the difference between PyTorch and TensorFlow.
PyTorch Vs. TensorFlow
| Parameter | PyTorch | TensorFlow |
|---|---|---|
| Model Definition | The model is defined in a subclass and offers easy to use package | The model is defined with many, and you need to understand the syntax |
| GPU Support | Yes | Yes |
| Graph Type | Dynamic | Static |
| Tools | No visualization tool | You can use Tensorboard visualization tool |
| Community | The community still growing | Large active communities |
With the comparison in mind, the next step is getting PyTorch running locally or in the cloud.
Installing PyTorch
Linux
It’s straightforward to install it in Linux. You can choose to use a virtual environment or install it directly with root access. Type this command in the terminal
pip3 install --upgrade torch torchvision
AWS Sagemaker
Sagemaker is one of the platforms in Amazon Web Service that offers a powerful Machine Learning engine with pre-installed deep learning configurations for data scientist or developers to build, train, and deploy models at any scale.
First Open the Amazon Sagemaker console and click on Create notebook instance and fill all the details for your notebook.

Next Step, Click on Open to launch your notebook instance.

Finally, In Jupyter, Click on New and choose conda_pytorch_p36 and you are ready to use your notebook instance with PyTorch installed.
Next in this PyTorch tutorial, we will learn about PyTorch framework basics.
Installation in place, the API itself is the next stop.
PyTorch Framework Basics
Let’s learn the basic concepts of PyTorch before we deep dive. PyTorch uses Tensor for every variable similar to numpy’s ndarray but with GPU computation support. Here we will explain the network model, loss function, Backprop, and Optimizer.
Network Model
The network can be constructed by subclassing the torch.nn. There are 2 main parts,
- The first part is to define the parameters and layers that you will use
- The second part is the main task called the forward process that will take an input and predict the output.
Import torch import torch.nn as nn import torch.nn.functional as F class Model(nn.Module): def __init__(self): super(Model, self).__init__() self.conv1 = nn.Conv2d(3, 20, 5) self.conv2 = nn.Conv2d(20, 40, 5) self.fc1 = nn.Linear(320, 10) def forward(self, x): x = F.relu(self.conv1(x)) x = F.relu(self.conv2(x)) x = x.view(-1, 320) x = F.relu(self.fc1(x)) return F.log_softmax(x) net = Model()
As you can see above, you create a class of nn.Module called Model. It contains 2 Conv2d layers and a Linear layer. The first conv2d layer takes an input of 3 and the output shape of 20. The second layer will take an input of 20 and will produce an output shape of 40. The last layer is a fully connected layer in the shape of 320 and will produce an output of 10.
The forward process will take an input of X and feed it to the conv1 layer and perform ReLU function,
Similarly, it will also feed the conv2 layer. After that, the x will be reshaped into (-1, 320) and feed into the final FC layer. Before you send the output, you will use the softmax activation function.
The backward process is automatically defined by autograd, so you only need to define the forward process.
Loss Function
The loss function is used to measure how well the prediction model is able to predict the expected results. PyTorch already has many standard loss functions in the torch.nn module. For example, you can use the Cross-Entropy Loss to solve a multi-class PyTorch classification problem. It’s easy to define the loss function and compute the losses:
loss_fn = nn.CrossEntropyLoss() #training process loss = loss_fn(out, target)
It’s easy to use your own loss function calculation with PyTorch.
Backprop
To perform the backpropagation, you simply call the los.backward(). The error will be computed but remember to clear the existing gradient with zero_grad()
net.zero_grad() # to clear the existing gradient loss.backward() # to perform backpropragation
Optimizer
The torch.optim provides common optimization algorithms. You can define an optimizer with a simple step:
optimizer = torch.optim.SGD(net.parameters(), lr = 0.01, momentum=0.9)
You need to pass the network model parameters and the learning rate so that at every iteration the parameters will be updated after the backprop process.
The cleanest way to learn the API is a small, end-to-end example.
Simple Regression with PyTorch
Let’s learn simple regression with PyTorch examples:
Step 1) Creating our network model
Our network model is a simple Linear layer with an input and an output shape of 1.
from __future__ import print_function import torch import torch.nn as nn import torch.nn.functional as F from torch.autograd import Variable class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.layer = torch.nn.Linear(1, 1) def forward(self, x): x = self.layer(x) return x net = Net() print(net)
And the network output should be like this
Net( (hidden): Linear(in_features=1, out_features=1, bias=True) )
Step 2) Test Data
Before you start the training process, you need to know our data. You make a random function to test our model. Y = x3 sin(x)+ 3x+0.8 rand(100)
# Visualize our data import matplotlib.pyplot as plt import numpy as np x = np.random.rand(100) y = np.sin(x) * np.power(x,3) + 3*x + np.random.rand(100)*0.8 plt.scatter(x, y) plt.show()
Here is the scatter plot of our function:

Before you start the training process, you need to convert the numpy array to Variables that supported by Torch and autograd as shown in the below PyTorch regression example.
# convert numpy array to tensor in shape of input size x = torch.from_numpy(x.reshape(-1,1)).float() y = torch.from_numpy(y.reshape(-1,1)).float() print(x, y)
Step 3) Optimizer and Loss
Next, you should define the Optimizer and the Loss Function for our training process.
# Define Optimizer and Loss Function optimizer = torch.optim.SGD(net.parameters(), lr=0.2) loss_func = torch.nn.MSELoss()
Step 4) Training
Now let’s start our training process. With an epoch of 250, you will iterate our data to find the best value for our hyperparameters.
inputs = Variable(x) outputs = Variable(y) for i in range(250): prediction = net(inputs) loss = loss_func(prediction, outputs) optimizer.zero_grad() loss.backward() optimizer.step() if i % 10 == 0: # plot and show learning process plt.cla() plt.scatter(x.data.numpy(), y.data.numpy()) plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=2) plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 10, 'color': 'red'}) plt.pause(0.1) plt.show()
Step 5) Result
As you can see below, you successfully performed PyTorch regression with a neural network. Actually, on every iteration, the red line in the plot will update and change its position to fit the data. But in this picture, it only show you the final result as shown in the below PyTorch example:

Regression is a warm-up; image classification exercises the deep-learning muscles of PyTorch.
Image Classification Example with PyTorch
One of the popular methods to learn the basics of deep learning is with the MNIST dataset. It is the “Hello World” in deep learning. The dataset contains handwritten numbers from 0 – 9 with the total of 60,000 training samples and 10,000 test samples that are already labeled with the size of 28×28 pixels.

Step 1) Preprocess the Data
In the first step of this PyTorch classification example, you will load the dataset using torchvision module.
Before you start the training process, you need to understand the data. Torchvision will load the dataset and transform the images with the appropriate requirement for the network such as the shape and normalizing the images.
import torch import torchvision import numpy as np from torchvision import datasets, models, transforms # This is used to transform the images to Tensor and normalize it transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) training = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform) train_loader = torch.utils.data.DataLoader(training, batch_size=4, shuffle=True, num_workers=2) testing = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform) test_loader = torch.utils.data.DataLoader(testing, batch_size=4, shuffle=False, num_workers=2) classes = ('0', '1', '2', '3', '4', '5', '6', '7', '8', '9') import matplotlib.pyplot as plt import numpy as np #create an iterator for train_loader # get random training images data_iterator = iter(train_loader) images, labels = data_iterator.next() #plot 4 images to visualize the data rows = 2 columns = 2 fig=plt.figure() for i in range(4): fig.add_subplot(rows, columns, i+1) plt.title(classes[labels[i]]) img = images[i] / 2 + 0.5 # this is for unnormalize the image img = torchvision.transforms.ToPILImage()(img) plt.imshow(img) plt.show()
The transform function converts the images into tensor and normalizes the value. The function torchvision.transforms.MNIST, will download the dataset (if it’s not available) in the directory, set the dataset for training if necessary and do the transformation process.
To visualize the dataset, you use the data_iterator to get the next batch of images and labels. You use matplot to plot these images and their appropriate label. As you can see below our images and their labels.
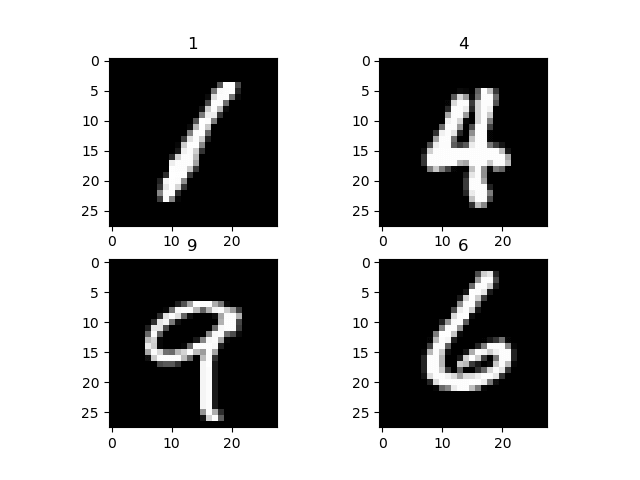
Step 2) Network Model Configuration
Now in this PyTorch example, you will make a simple neural network for PyTorch image classification.
Here, we introduce you another way to create the Network model in PyTorch. We will use nn.Sequential to make a sequence model instead of making a subclass of nn.Module.
import torch.nn as nn # flatten the tensor into class Flatten(nn.Module): def forward(self, input): return input.view(input.size(0), -1) #sequential based model seq_model = nn.Sequential( nn.Conv2d(1, 10, kernel_size=5), nn.MaxPool2d(2), nn.ReLU(), nn.Dropout2d(), nn.Conv2d(10, 20, kernel_size=5), nn.MaxPool2d(2), nn.ReLU(), Flatten(), nn.Linear(320, 50), nn.ReLU(), nn.Linear(50, 10), nn.Softmax(), ) net = seq_model print(net)
Here is the output of our network model
Sequential( (0): Conv2d(1, 10, kernel_size=(5, 5), stride=(1, 1)) (1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (2): ReLU() (3): Dropout2d(p=0.5) (4): Conv2d(10, 20, kernel_size=(5, 5), stride=(1, 1)) (5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (6): ReLU() (7): Flatten() (8): Linear(in_features=320, out_features=50, bias=True) (9): ReLU() (10): Linear(in_features=50, out_features=10, bias=True) (11): Softmax() )
Network Explanation
- The sequence is that the first layer is a Conv2D layer with an input shape of 1 and output shape of 10 with a kernel size of 5
- Next, you have a MaxPool2D layer
- A ReLU activation function
- a Dropout layer to drop low probability values.
- Then a second Conv2d with the input shape of 10 from the last layer and the output shape of 20 with a kernel size of 5
- Next a MaxPool2d layer
- ReLU activation function.
- After that, you will flatten the tensor before you feed it into the Linear layer
- Linear Layer will map our output at the second Linear layer with softmax activation function
Step 3)Train the Model
Before you start the training process, it is required to set up the criterion and optimizer function.
For the criterion, you will use the CrossEntropyLoss. For the Optimizer, you will use the SGD with a learning rate of 0.001 and a momentum of 0.9 as shown in the below PyTorch example.
import torch.optim as optim criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
The forward process will take the input shape and pass it to the first conv2d layer. Then from there, it will be feed into the maxpool2d and finally put into the ReLU activation function. The same process will occur in the second conv2d layer. After that, the input will be reshaped into (-1,320) and feed into the fc layer to predict the output.
Now, you will start the training process. You will iterate through our dataset 2 times or with an epoch of 2 and print out the current loss at every 2000 batch.
for epoch in range(2): #set the running loss at each epoch to zero running_loss = 0.0 # we will enumerate the train loader with starting index of 0 # for each iteration (i) and the data (tuple of input and labels) for i, data in enumerate(train_loader, 0): inputs, labels = data # clear the gradient optimizer.zero_grad() #feed the input and acquire the output from network outputs = net(inputs) #calculating the predicted and the expected loss loss = criterion(outputs, labels) #compute the gradient loss.backward() #update the parameters optimizer.step() # print statistics running_loss += loss.item() if i % 1000 == 0: print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 1000)) running_loss = 0.0
At each epoch, the enumerator will get the next tuple of input and corresponding labels. Before we feed the input to our network model, we need to clear the previous gradient. This is required because after the backward process (backpropagation process), the gradient will be accumulated instead of being replaced. Then, we will calculate the losses from the predicted output from the expected output. After that, we will do a backpropagation to calculate the gradient, and finally, we will update the parameters.
Here’s the output of the training process
[1, 1] loss: 0.002 [1, 1001] loss: 2.302 [1, 2001] loss: 2.295 [1, 3001] loss: 2.204 [1, 4001] loss: 1.930 [1, 5001] loss: 1.791 [1, 6001] loss: 1.756 [1, 7001] loss: 1.744 [1, 8001] loss: 1.696 [1, 9001] loss: 1.650 [1, 10001] loss: 1.640 [1, 11001] loss: 1.631 [1, 12001] loss: 1.631 [1, 13001] loss: 1.624 [1, 14001] loss: 1.616 [2, 1] loss: 0.001 [2, 1001] loss: 1.604 [2, 2001] loss: 1.607 [2, 3001] loss: 1.602 [2, 4001] loss: 1.596 [2, 5001] loss: 1.608 [2, 6001] loss: 1.589 [2, 7001] loss: 1.610 [2, 8001] loss: 1.596 [2, 9001] loss: 1.598 [2, 10001] loss: 1.603 [2, 11001] loss: 1.596 [2, 12001] loss: 1.587 [2, 13001] loss: 1.596 [2, 14001] loss: 1.603
Step 4) Test the Model
After you train our model, you need to test or evaluate with other sets of images.
We will use an iterator for the test_loader, and it will generate a batch of images and labels that will be passed to the trained model. The predicted output will be displayed and compared with the expected output.
#make an iterator from test_loader #Get a batch of training images test_iterator = iter(test_loader) images, labels = test_iterator.next() results = net(images) _, predicted = torch.max(results, 1) print('Predicted: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4))) fig2 = plt.figure() for i in range(4): fig2.add_subplot(rows, columns, i+1) plt.title('truth ' + classes[labels[i]] + ': predict ' + classes[predicted[i]]) img = images[i] / 2 + 0.5 # this is to unnormalize the image img = torchvision.transforms.ToPILImage()(img) plt.imshow(img) plt.show()
