Apache ZooKeeper Tutorial
⚡ Smart Summary
Apache ZooKeeper Tutorial introduces the centralized service for configuration, naming, synchronization, and group services in distributed systems. Lessons cover architecture, data model, watches, ensembles, applications, advantages, and disadvantages.

What is a Distributed System?
A distributed application is an application which can run on multiple systems in a network. It runs simultaneously by coordinating themselves to complete a certain task. These tasks may take plenty of hours to complete by any non-distributed application.
What is Zookeeper?
Apache Zookeeper is an open source distributed coordination service that helps to manage a large set of hosts. Management and coordination in a distributed environment is tricky. Zookeeper automates this process and allows developers to focus on building software features rather than worry about it’s distributed nature.
Zookeeper helps you to maintain configuration information, naming, group services for distributed applications. It implements different protocols on the cluster so that the application should not implement on their own. It provides a single coherent view of multiple machines.


Why Apache Zookeeper?
Here, are important reasons behind the popularity of the Zookeeper:
- It allows for mutual exclusion and cooperation between server processes
- It ensures that your application runs consistently.
- The transaction process is never completed partially. It is either given the status of Success or failure. The distributed state can be held up, but it’s never wrong
- Irrespective o the server that it connects to, a client will be able to see the same view of the service
- Helps you to encode the data as per the specific set of rules
- It helps to maintain a standard hierarchical namespace similar to files and directories
- Computers, which run as a single system which can be locally or geographically connected
- It allows to Join/leave node in a cluster and node status at the real time
- You can increase performance by deploying more machines
- It allows you to elect a node as a leader for better coordination
- ZooKeeper works fast with workloads where reads to the data are more common than writes
ZooKeeper Architecture: How it works?
Here is a brief explanation about Apache Zookeeper architecture:
- Zookeeper follows a Client-Server Architecture
- All systems store a copy of the data
- Leaders are elected at startup

Server: The server sends an acknowledge when any client connects. In the case when there is no response from the connected server, the client automatically redirects the message to another server.
Client: Client is one of the nodes in the distributed application cluster. It helps you to accesses information from the server. Every client sends a message to the server at regular intervals that helps the server to know that the client is alive.
Leader: One of the servers is designated a Leader. It gives all the information to the clients as well as an acknowledgment that the server is alive. It would performs automatic recovery if any of the connected nodes failed.
Follower: Server node which follows leader instruction is called a follower.
- Client read requests are handled by the correspondingly connected Zookeeper server
- The client writes requests are handled by the Zookeeper leader.
Ensemble/Cluster: Group of Zookeeper servers which is called ensemble or a Cluster. You can use ZooKeeper infrastructure in the cluster mode to have the system at the optimal value when you are running the Apache.
ZooKeeper WebUI: If you want to work with ZooKeeper resource management, then you need to use WebUI. It allows working with ZooKeeper using the web user interface, instead of using the command line. It offers fast and effective communication with the ZooKeeper application.
The Zookeeper Data Model (ZDM)
Now in this ZooKeeper tutorial, let’s learn about Zookeeper Data Model. The Below figure explains Apache Zookeeper Data Model:

- The zookeeper data model follows a Hierarchal namespace where each node is called a ZNode. A node is a system where the cluster runs.
- Every ZNode has data. It may or may not have children
- ZNode paths:
- Canonical, slash-separated and absolute
- Not use any relative references
- Names may have Unicode characters
- ZNode maintains stat structure and version number for data changes.
Types of Zookeeper Nodes
There are three types of Znodes:
Persistence znode: This type of znode is alive even after the client which created that specific znode, is disconnected. By default, in zookeeper, all nodes are persistent if it is not specified.
Ephemeral znode: This type of zookeeper znode are alive until the client is alive. Therefore, when the client gets a disconnect from the zookeeper, it will also be deleted. Moreover, ephemeral nodes are not allowed to have children.
Sequential znode: Sequential znodes can be either ephemeral or persistent. So when a new znode is created as a sequential znode. You can assign the path of the znode by attaching a 10 digit sequence number to the original name.
ZDM- Watches
Zookeeper, a watch event is a one-time trigger which is sent to the client that set watch. It occurred when data from that watch changes. ZDM watch allows clients to get notifications when znode changes. ZDM read operations like getData(), getChidleren(), exist have the option of setting a watch.
Watches are ordered, the order of watch events corresponds to the order of the updates. A client will able to see a watch event for znode before seeing the new data which corresponds to that znode.
ZDM- Access Control list
Zookeeper uses ACLs to control access to its znodes. ACL is made up of a pair of (Scheme: id, permission)
Build in ACL schemes:
world: has a single id, anyone
auth: Not use any id, It represents any authenticated user
digest: use a username: password
host: Allows you to use client’s hostname as ACL id identity
IP: use the client host IP address as ACL id identity
ACL Permissions:
- CREATE
- READ
- WRITE
- DELETE
- ADMIN
E.x. (IP: 192.168.0.0/16, READ)
The ZKS – Session States and Lifetime
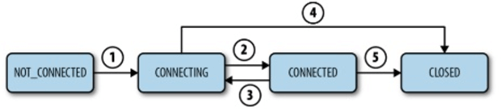
- Before executing any request, it is important that the client must establish a session with service
- All operations clients are sent to service are automatically associated with a session
- The client may connect to any server in the cluster. But it will connect to only a single server
- The session provides “order guarantees”. The requests in the session are executed in FIFO order
- The main states for a session are 1) Connecting, 2) Connected 3) Closed 4) Not Connected.
How to Install ZooKeeper
Step 1) Click on Continue to Subscribe
Go to this link and click ‘Continue to Subscribe’

Step 2) Accept Terms & Conditions
On next page, Accept License Agreement
Step 3) Thank You Message shown
You will see the following message

Step 4) Click on Continue to Configure
Refresh the page after 5 minutes and Proceed for Configuration

Step 5) Click on ‘Continue to Launch’
In next screen, Launch ZooKeeper

Step 6) Congratulations!
You are done!
Apache ZooKeeper Applications
Apache Zookeeper used for following purposes:
- Managing the configuration
- Naming services
- Choosing the leader
- Queuing the messages
- Managing the notification system
- Synchronization
- Distributed Cluster Management
Companies using Zookeeper
- Yahoo
- eBay
- Netflix
- Zynga
- Nutanix
Disadvantages of using Zookeeper
- Data loss may occur if you are adding new Zookeeper Servers
- No Migration allowed for users
- Not offer support for Rack placement and awareness
- Zookeeper does not allow you to reduce the number of pods to prevent accidental data loss
- You can’t switch service to host networking without a full re-installation when the service is deployed on a virtual network
- Service doesn’t support changing volume requirements once the initial deployment is over
- There are large numbers of node involved so there could be more than one point of failure
- Messages can be lost in the communication network, which requires special software to recover it again