Word Embedding and Word2Vec with Example
⚡ Smart Summary
Word Embedding and Word2Vec convert text into dense numeric vectors so machine learning models recognize words with similar meaning. This resource explains the technique, its CBOW and Skip-Gram architectures, activation functions, and a complete Gensim implementation for real applications.
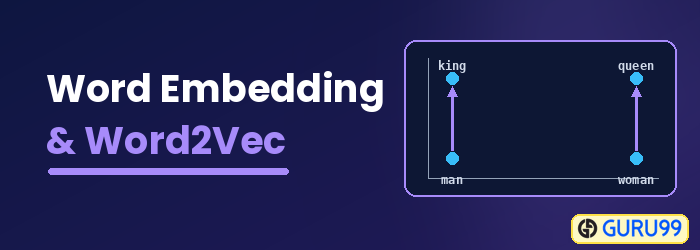
What is Word Embedding?
Word Embedding is a word representation type that allows machine learning algorithms to understand words with similar meanings. It is a language modeling and feature learning technique to map words into vectors of real numbers using neural networks, probabilistic models, or dimension reduction on the word co-occurrence matrix. Some word embedding models are Word2vec (Google), GloVe (Stanford), and fastText (Facebook).
Word Embedding is also called a distributed semantic model, distributed represented model, semantic vector space, or vector space model. As you read these names, you come across the word semantic, which means categorizing similar words together. For example, fruits like apple, mango, and banana should be placed close together, whereas books will be placed far away from these words. In a broader sense, word embedding will create a vector of fruits that is placed far away from the vector representation of books.
Where is Word Embedding used?
Word embedding helps in feature generation, document clustering, text classification, and natural language processing tasks. Let us list these applications and discuss each one.
- Compute similar words: Word embedding is used to suggest similar words to the word being subjected to the prediction model. Along with that, it also suggests dissimilar words, as well as the most common words.
- Create a group of related words: It is used for semantic grouping, which groups things of similar characteristics together and pushes dissimilar items far away.
- Feature for text classification: Text is mapped into arrays of vectors that are fed to the model for training as well as prediction. Text-based classifier models cannot be trained on strings, so this converts the text into a machine-trainable form. Its semantic-building features further help in text-based classification.
- Document clustering: This is another application where Word Embedding and Word2vec are widely used.
- Natural language processing: There are many applications where word embedding is useful and wins over feature extraction phases, such as parts-of-speech tagging, sentiment analysis, and syntactic analysis.
Now that you understand where word embedding is applied, let us look at the most popular model used to create these embeddings.
What is Word2vec?
Word2vec is a technique or model that produces word embeddings for better word representation. It is a natural language processing method that captures a large number of precise syntactic and semantic word relationships. It is a shallow two-layered neural network that can detect synonymous words and suggest additional words for partial sentences once it is trained.
Before going further, please see the difference between a shallow and a deep neural network as shown in the below Word embedding example diagram:
The shallow neural network consists of only one hidden layer between input and output, whereas a deep neural network contains multiple hidden layers between input and output. Input is subjected to nodes, whereas the hidden layer, as well as the output layer, contains neurons.
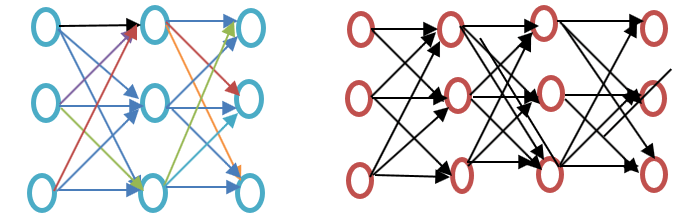
Word2vec is a two-layer network where there is an input, one hidden layer, and an output.
Word2vec was developed by a group of researchers headed by Tomas Mikolov at Google. Word2vec is better and more efficient than the latent semantic analysis model.
Why Word2vec?
Word2vec represents words in a vector space representation. Words are represented in the form of vectors, and placement is done in such a way that similar-meaning words appear together and dissimilar words are located far away. This is also termed a semantic relationship. Neural networks do not understand text; instead, they understand only numbers. Word Embedding provides a way to convert text to a numeric vector.
Word2vec reconstructs the linguistic context of words. Before going further, let us understand what linguistic context is. In a general scenario, when we speak or write to communicate, other people try to figure out the objective of the sentence. For example, “What is the temperature of India?” Here, the context is that the user wants to know the “temperature of India.” In short, the main objective of a sentence is context. The words or sentences surrounding spoken or written language help in determining the meaning of context. Word2vec learns the vector representation of words through these contexts.
What Word2vec does?
Before Word Embedding
It is important to know which approach was used before word embedding and what its demerits are, and then we will see how those demerits are overcome by word embedding using the Word2vec approach. Finally, we will move to how Word2vec works, because it is important to understand its working.
Approach for Latent Semantic Analysis
This is the approach that was used before word embeddings. It used the concept of a Bag of Words, where words are represented in the form of encoded vectors. It is a sparse vector representation where the dimension is equal to the size of the vocabulary. If the word occurs in the dictionary, it is counted; otherwise, it is not. To understand more, please see the program below.
Word2vec Example

from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() data_corpus = ["guru99 is the best site for online tutorials. I love to visit guru99."] vocabulary = vectorizer.fit(data_corpus) X = vectorizer.transform(data_corpus) print(X.toarray()) print(vectorizer.get_feature_names_out())
Output:
[[1 2 1 1 1 1 1 1 1 1]] [u'best', u'guru99', u'is', u'love', u'online', u'sitefor', u'the', u'to', u'tutorials', u'visit']
Code Explanation
- CountVectorizer is the module used to store the vocabulary based on fitting the words in it. This is imported from sklearn.
- Make the object using the class CountVectorizer.
- Write the data in the list that is to be fitted in the CountVectorizer.
- Data is fit in the object created from the class CountVectorizer.
- Apply a bag-of-words approach to count words in the data using the vocabulary. If a word or token is not available in the vocabulary, then such an index position is set to zero.
- The variable in line 5, which is x, is converted to an array (a method available for x). This provides the count of each token in the sentence or list provided in line 3.
- This shows the features that are part of the vocabulary when it is fitted using the data in line 4.
In the Latent Semantic approach, the row represents unique words, whereas the column represents the number of times that word appears in the document. It is a representation of words in the form of a document matrix. Term Frequency-Inverse Document Frequency (TF-IDF) is used to count the frequency of words in the document, which is the frequency of the term in the document divided by the frequency of the term in the entire corpus.
Shortcoming of Bag of Words method
- It ignores the order of the word; for example, this is bad = bad is this.
- It ignores the context of words. Suppose we write the sentence “He loved books. Education is best found in books.” It would create two vectors: one for “He loved books” and another for “Education is best found in books.” It would treat both of them as orthogonal, which makes them independent, but in reality, they are related to each other.
To overcome these limitations, word embedding was developed, and Word2vec is one approach used to implement it.
How Word2vec works?
Word2vec learns a word by predicting its surrounding context. For example, let us take the word “He loves Football.”
We want to calculate the Word2vec for the word: loves.
Suppose:
loves = Vin. P(Vout / Vin) is calculated where, Vin is the input word. P is the probability of likelihood. Vout is the output word.
The word loves moves over each word in the corpus. Syntactic as well as semantic relationships between words are encoded. This helps in finding similar and analogous words.
All random features of the word loves are calculated. These features are changed or updated with respect to neighbor or context words with the help of a Back Propagation method.
Another way of learning is that if the contexts of two words are similar, or two words have similar features, then such words are related.
Word2vec Architecture
There are two architectures used by Word2vec:
- Continuous Bag of Words (CBOW)
- Skip-gram
Before going further, let us discuss why these architectures or models are important from a word representation point of view. Learning word representation is essentially unsupervised, but targets/labels are needed to train the model. Skip-gram and CBOW convert the unsupervised representation into a supervised form for model training.
In CBOW, the current word is predicted using the window of surrounding context windows. For example, if wi-1, wi-2, wi+1, wi+2 are given words or context, this model will provide wi.
Skip-Gram performs the opposite of CBOW, which implies that it predicts the given sequence or context from the word. You can reverse the example to understand it. If wi is given, this will predict the context, or wi-1, wi-2, wi+1, wi+2.
Word2vec provides an option to choose between CBOW (Continuous Bag of Words) and skip-gram. Such parameters are provided during the training of the model. One can have the option of using negative sampling or a hierarchical softmax layer.
Continuous Bag of Words
Let us draw a simple Word2vec example diagram to understand the continuous bag-of-words architecture.

Let us calculate the equations mathematically. Suppose V is the vocabulary size and N is the hidden layer size. Input is defined as { xi-1, xi-2, xi+1, xi+2 }. We obtain the weight matrix by multiplying V * N. Another matrix is obtained by multiplying the input vector with the weight matrix. This can also be understood by the following equation.
h = xitW
where xit and W are the input vector and weight matrix respectively.
To calculate the match between context and the next word, please refer to the below equation.
u = predictedrepresentation * h
where predictedrepresentation is obtained from the model in the above equation.
Skip-Gram Model
The Skip-Gram approach is used to predict a sentence given an input word. To understand it better, let us draw the diagram shown in the below Word2vec example.

One can treat it as the reverse of the Continuous Bag of Words model, where the input is the word and the model provides the context or the sequence. We can also conclude that the target is fed to the input, and the output layer is replicated multiple times to accommodate the chosen number of context words. The error vector from all output layers is summed up to adjust weights via a backpropagation method.
Which model to choose?
CBOW is several times faster than skip-gram and provides a better frequency for frequent words, whereas skip-gram needs a small amount of training data and represents even rare words or phrases. The table below compares both architectures at a glance.
| Aspect | CBOW | Skip-Gram |
|---|---|---|
| Prediction | Predicts the target word from context | Predicts context from the target word |
| Training speed | Faster | Slower |
| Frequent words | Higher accuracy | Lower accuracy |
| Rare words | Weaker representation | Stronger representation |
| Training data | Needs more data | Works with less data |
The relation between Word2vec and NLTK
NLTK is the Natural Language Toolkit. It is used for preprocessing of text. One can perform different operations such as parts-of-speech tagging, lemmatizing, stemming, stop-word removal, and removing rare or least-used words. It helps in cleaning the text as well as preparing features from the effective words. On the other hand, Word2vec is used for semantic (closely related items together) and syntactic (sequence) matching. Using Word2vec, one can find similar words, dissimilar words, dimensional reduction, and many others. Another important feature of Word2vec is to convert the higher-dimensional representation of text into lower-dimensional vectors.
Where to use NLTK and Word2vec?
If one has to accomplish some general-purpose tasks as mentioned above, like tokenization, POS tagging, and parsing, one must go for NLTK, whereas for predicting words according to some context, topic modeling, or document similarity, one must use Word2vec.
Relation of NLTK and Word2vec with the help of code
NLTK and Word2vec can be used together to find similar word representations or syntactic matching. The NLTK toolkit can be used to load many packages that come with NLTK, and a model can be created using Word2vec. It can then be tested on real-time words. Let us see the combination of both in the following code. Before processing further, please have a look at the corpora that NLTK provides. You can download it using the command:
nltk(nltk.download('all'))

Please see the screenshot for the code.
import nltk import gensim from nltk.corpus import abc model = gensim.models.Word2Vec(abc.sents()) X = list(model.wv.vocab) data = model.most_similar('science') print(data)

Output:
[('law', 0.9415997266769409), ('practice', 0.9276568293571472), ('discussion', 0.9259148836135864), ('agriculture', 0.9257254004478455), ('media', 0.9232194423675537), ('policy', 0.922248125076294), ('general', 0.9166069030761719), ('undertaking', 0.916458249092102), ('tight', 0.9129181504249573), ('board', 0.9107444286346436)]
Explanation of Code
- The nltk library is imported, from where you can download the abc corpus that we will use in the next step.
- Gensim is imported. If Gensim Word2vec is not installed, please install it using the command “pip3 install gensim”. Please see the below screenshot.

- Import the abc corpus, which has been downloaded using nltk.download(‘abc’).
- Pass the files to the Word2vec model, which is imported using Gensim, as sentences.
- Vocabulary is stored in the form of a variable.
- The model is tested on the sample word science, as these files are related to science.
- Here, the similar word of “science” is predicted by the model.
Activators and Word2Vec
The activation function of a neuron defines the output of that neuron given a set of inputs. It is biologically inspired by activity in our brains, where different neurons are activated using different stimuli. Let us understand the activation function through the following diagram.

Here x1, x2, … x4 are the nodes of the neural network.
w1, w2, w3 are the weights of the nodes.
The summation (Σ) of all weights and node values works as the activation function.
Why Activation function?
If no activation function is used, the output would be linear, but the functionality of a linear function is limited. To achieve complex functionality such as object detection, image classification, typing text using voice, and many other non-linear outputs, an activation function is needed.
How the activation layer is computed in the word embedding (Word2vec)
The Softmax Layer (normalized exponential function) is the output-layer function that activates or fires each node. Another approach used is Hierarchical softmax, where the complexity is calculated by O(log2V), whereas in softmax it is O(V), where V is the vocabulary size. The difference between these is the reduction of the complexity in the hierarchical softmax layer. To understand its functionality, please look at the below Word embedding example:

Suppose we want to compute the probability of observing the word love given a certain context. The flow from the root to the leaf node will first move to node 2 and then to node 5. So if we have a vocabulary size of 8, only three computations are needed. This allows decomposing the calculation of the probability of one word (love).
What other options are available other than Hierarchical Softmax?
In a general sense, the word embedding options available are Differentiated Softmax, CNN-Softmax, Importance Sampling, Adaptive Importance Sampling, Noise Contrastive Estimation, Negative Sampling, Self-Normalization, and Infrequent Normalization.
Speaking specifically about Word2vec, we have negative sampling available.
Negative Sampling is a way to sample the training data. It is somewhat like stochastic gradient descent, but with some difference. Negative sampling looks only for negative training examples. It is based on noise contrastive estimation and randomly samples words that are not in the context. It is a fast training method and chooses the context randomly. If the predicted word appears in the randomly chosen context, both vectors are close to each other.
What conclusion can be drawn?
Activators fire the neurons just like our neurons are fired using external stimuli. The Softmax layer is one of the output-layer functions that fires the neurons in the case of word embeddings. In Word2vec, we have options such as hierarchical softmax and negative sampling. Using activators, one can convert a linear function into a non-linear function, and a complex machine learning algorithm can be implemented using such functions.
What is Gensim?
Gensim is an open-source topic modeling and natural language processing toolkit that is implemented in Python and Cython. The Gensim toolkit allows users to import Word2vec for topic modeling to discover hidden structure in the text body. Gensim provides not only an implementation of Word2vec but also Doc2vec and FastText.
This section is focused on Word2vec, so we will stick to the current topic.
How to Implement Word2vec using Gensim
Until now, we have discussed what Word2vec is, its different architectures, why there is a shift from a bag of words to Word2vec, the relation between Word2vec and NLTK with live code, and activation functions.
Below is the step-by-step method to implement Word2vec using Gensim:
Step 1) Data Collection
The first step to implement any machine learning model or implementing natural language processing is data collection.
Please observe the data to build an intelligent chatbot as shown in the below Gensim Word2vec example.
[{"tag": "welcome",
"patterns": ["Hi", "How are you", "Is any one to talk?", "Hello", "hi are you available"],
"responses": ["Hello, thanks for contacting us", "Good to see you here", "Hi there, how may I assist you?"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "I will come back soon"],
"responses": ["See you later, thanks for visiting", "have a great day ahead", "Wish you Come back again soon."]
},
{"tag": "thankful",
"patterns": ["Thanks for helping me", "Thank your guidance", "That's helpful and kind from you"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "It is my duty to help you"]
},
{"tag": "hoursopening",
"patterns": ["What hours are you open?", "Tell your opening time?", "When are you open?", "Just your timing please"],
"responses": ["We're open every day 8am-7pm", "Our office hours are 8am-7pm every day", "We open office at 8 am and close at 7 pm"]
},
{"tag": "payments",
"patterns": ["Can I pay using credit card?", "Can I pay using Mastercard?", "Can I pay using cash only?"],
"responses": ["We accept VISA, Mastercard and credit card", "We accept credit card, debit cards and cash. Please don't worry"]
}
]
Here is what we understand from the data:
- This data contains three things: tag, pattern, and responses. The tag is the intent (what is the topic of discussion).
- The data is in JSON format.
- A pattern is a question users will ask the bot.
- Responses are the answers that the chatbot will provide to the corresponding question/pattern.
Step 2) Data preprocessing
It is very important to process the raw data. If cleaned data is fed to the machine, then the model will respond more accurately and will learn the data more efficiently.
This step involves removing stop words, stemming, unnecessary words, etc. Before going ahead, it is important to load data and convert it into a data frame. Please see the below code for this.
import json json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f)
Explanation of Code:
- As data is in JSON format, json is imported.
- The file is stored in the variable.
- The file is opened and loaded into the data variable.
Now data is imported, and it is time to convert the data into a data frame. Please see the below code for the next step.
import pandas as pd df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join)
Explanation of Code:
1. Data is converted into a data frame using pandas, which was imported above.
2. It converts the list in the column patterns to a string.
from nltk.corpus import stopwords from textblob import Word stop = stopwords.words('english') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
Code Explanation:
1. English stop words are imported using the stop-word module from the nltk toolkit.
2. All the words of the text are converted into lower case using a for condition and a lambda function. A Lambda function is an anonymous function.
3. All the rows of the text in the data frame are checked for string punctuation, and these are filtered.
4. Characters such as numbers or dots are removed using a regular expression.
5. Digits are removed from the text.
6. Stop words are removed at this stage.
7. Words are filtered now, and different forms of the same word are removed using lemmatization. With these, we have finished the data preprocessing.
Output:
, patterns, responses, tag 0,hi one talk hello hi available,"['Hello, thanks for contacting us', 'Good to see you here', ' Hi there, how may I assist you?']",welcome 1,bye see later goodbye come back soon,"['See you later, thanks for visiting', 'have a great day ahead', 'Wish you Come back again soon.']",goodbye 2,thanks helping thank guidance thats helpful kind,"['Happy to help!', 'Any time!', 'My pleasure', 'It is my duty to help you']",thankful 3,hour open tell opening time open timing please,"[""We're open every day 8am-7pm"", 'Our office hours are 8am-7pm every day', 'We open office at 8 am and close at 7 pm']",hoursopening 4,pay using credit card pay using mastercard pay using cash,"['We accept VISA, Mastercard and credit card', 'We accept credit card, debit cards and cash. Please dont worry']",payments
Step 3) Neural Network building using Word2vec
Now it is time to build a model using the Gensim Word2vec module. We have to import Word2vec from Gensim. Let us do this, and then we will build it, and in the final stage we will check the model on real-time data.
from gensim.models import Word2Vec
Now we can successfully build the model using Word2Vec. Please refer to the next line of code to learn how to create the model using Word2Vec. Text is provided to the model in the form of a list, so we will convert the text from the data frame to a list using the below code.
Bigger_list = [] for i in df['patterns']: li = list(i.split("")) Bigger_list.append(li) Model = Word2Vec(Bigger_list, min_count=1, size=300, workers=4)
Explanation of Code:
1. Created the bigger_list where the inner list is appended. This is the format that is fed to the model Word2Vec.
2. A loop is implemented, and each entry of the patterns column of the data frame is iterated.
3. Each element of the column patterns is split and stored in the inner list li.
4. The inner list is appended with the outer list.
5. This list is provided to the Word2Vec model. Let us understand some of the parameters provided here.
Min_count: It ignores all the words with a total frequency lower than this.
Size: It tells the dimensionality of the word vectors.
Workers: These are the threads to train the model.
There are also other options available, and some important ones are explained below.
Window: Maximum distance between the current and predicted word within a sentence.
Sg: It is a training algorithm: 1 for skip-gram and 0 for a Continuous Bag of Words. We have discussed these in detail above.
Hs: If this is 1, then we are using hierarchical softmax for training, and if 0, then negative sampling is used.
Alpha: Initial learning rate.
Let us display the final code below:
# list of libraries used by the code import string from gensim.models import Word2Vec import logging from nltk.corpus import stopwords from textblob import Word import json import pandas as pd # data in json format json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f) # displaying the list of stopwords stop = stopwords.words('english') # dataframe df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join) # cleaning the data using the NLP approach print(df) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()])) # taking the outer list bigger_list = [] for i in df['patterns']: li = list(i.split(" ")) bigger_list.append(li) # structure of data to be taken by the model.word2vec print("Data format for the overall list:", bigger_list) # custom data is fed to machine for further processing model = Word2Vec(bigger_list, min_count=1, size=300, workers=4)
Step 4) Model saving
The model can be saved in the form of a bin and a model file. Bin is the binary format. Please see the below lines to save the model.
model.save("word2vec.model") model.save("model.bin")
Explanation of the above code
1. The model is saved in the form of a .model file.
2. The model is saved in the form of a .bin file.
We will use this model to do real-time testing such as similar words, dissimilar words, and most common words.
Step 5) Loading model and performing real time testing
The model is loaded using the below code:
model = Word2Vec.load('model.bin')
If you want to print the vocabulary from it, it is done using the below command:
vocab = list(model.wv.vocab)
Please see the result:
['see', 'thank', 'back', 'thanks', 'soon', 'open', 'mastercard', 'card', 'time', 'pay', 'talk', 'cash', 'one', 'please', 'goodbye', 'thats', 'helpful', 'hour', 'credit', 'hi', 'later', 'guidance', 'opening', 'timing', 'hello', 'helping', 'bye', 'tell', 'come', 'using', 'kind', 'available']
Step 6) Most Similar words checking
Let us implement the things practically:
similar_words = model.most_similar('thanks') print(similar_words)
Please see the result:
[('kind', 0.16104359924793243), ('using', 0.1352398842573166), ('come', 0.11500970274209976), ('later', 0.09989878535270691), ('helping', 0.04855936020612717), ('credit', 0.04659383371472359), ('pay', 0.0329081267118454), ('thank', 0.02484947443008423), ('hour', 0.0202352125197649), ('opening', 0.018177658319473267)]
Step 7) Does not match word from words supplied
dissimlar_words = model.doesnt_match('See you later, thanks for visiting'.split()) print(dissimlar_words)
We have supplied the words ‘See you later, thanks for visiting’. This prints the most dissimilar word from these words. Let us run this code and find the result.
The result after execution of the above code:
Thanks
Step 8) Finding the similarity between two words
This tells the result in terms of the probability of similarity between two words. Please see the below code on how to execute this section.
similarity_two_words = model.similarity('please', 'see') print("Please provide the similarity between these two words:") print(similarity_two_words)
The result of the above code is as below:
0.13706
You can further find similar words by executing the below code:
similar = model.similar_by_word('kind') print(similar)
Output of the above code:
[('credit', 0.11764447391033173), ('cash', 0.11440904438495636), ('one', 0.11151769757270813), ('hour', 0.0944807156920433), ('using', 0.0705675333738327), ('thats', 0.05206916481256485), ('later', 0.04502468928694725), ('bye', 0.03960943967103958), ('back', 0.03837274760007858), ('thank', 0.0380823090672493)]