Seq2seq (Sequence to Sequence) Model with PyTorch
⚡ Smart Summary
Seq2Seq is an encoder-decoder architecture that maps an input sequence to an output sequence using two recurrent neural networks, powering machine translation and other natural language processing tasks where input and output lengths differ.

What is NLP?
NLP or Natural Language Processing is one of the popular branches of Artificial Intelligence that helps computers understand, manipulate, or respond to a human in their natural language. NLP is the engine behind Google Translate that helps us understand other languages.
What is Seq2Seq?
Seq2Seq is a method of encoder-decoder based machine translation and language processing that maps an input of sequence to an output of sequence with a tag and attention value. The idea is to use 2 RNNs that will work together with a special token and try to predict the next state sequence from the previous sequence.
How to Predict sequence from the previous sequence
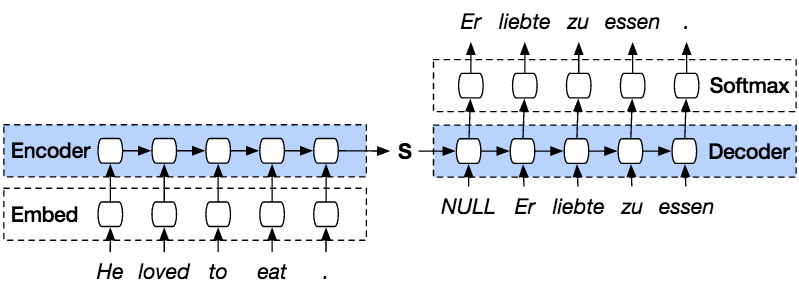
Following are the steps to predict a sequence from the previous sequence with PyTorch.
Step 1) Loading our Data
For our dataset, you will use a dataset from Tab-delimited Bilingual Sentence Pairs. Here I will use the English to Indonesian dataset. You can choose anything you like but remember to change the file name and directory in the code.
from __future__ import unicode_literals, print_function, division import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F import numpy as np import pandas as pd import os import re import random device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Step 2) Data Preparation
You cannot use the dataset directly. You need to split the sentences into words and convert it into a One-Hot Vector. Every word will be uniquely indexed in the Lang class to make a dictionary. The Lang class will store every sentence and split it word by word with addSentence. Then create a dictionary by indexing every unknown word for Sequence to sequence models.
SOS_token = 0 EOS_token = 1 MAX_LENGTH = 20 #initialize Lang Class class Lang: def __init__(self): #initialize containers to hold the words and corresponding index self.word2index = {} self.word2count = {} self.index2word = {0: "SOS", 1: "EOS"} self.n_words = 2 # Count SOS and EOS #split a sentence into words and add it to the container def addSentence(self, sentence): for word in sentence.split(' '): self.addWord(word) #If the word is not in the container, the word will be added to it, else, update the word counter def addWord(self, word): if word not in self.word2index: self.word2index[word] = self.n_words self.word2count[word] = 1 self.index2word[self.n_words] = word self.n_words += 1 else: self.word2count[word] += 1
The Lang class is a class that will help us make a dictionary. For each language, every sentence will be split into words and then added to the container. Each container will store the words in the appropriate index, count the word, and add the index of the word so we can use it to find the index of a word or find a word from its index.
Because our data is separated by TAB, you need to use pandas as our data loader. Pandas will read our data as a dataFrame and split it into our source and target sentence. For every sentence that you have, you will normalize it to lower case, remove all non-characters, convert to ASCII from Unicode, and split the sentences so you have each word in it.
#Normalize every sentence def normalize_sentence(df, lang): sentence = df[lang].str.lower() sentence = sentence.str.replace('[^A-Za-z\s]+', '') sentence = sentence.str.normalize('NFD') sentence = sentence.str.encode('ascii', errors='ignore').str.decode('utf-8') return sentence def read_sentence(df, lang1, lang2): sentence1 = normalize_sentence(df, lang1) sentence2 = normalize_sentence(df, lang2) return sentence1, sentence2 def read_file(loc, lang1, lang2): df = pd.read_csv(loc, delimiter='\t', header=None, names=[lang1, lang2]) return df def process_data(lang1,lang2): df = read_file('text/%s-%s.txt' % (lang1, lang2), lang1, lang2) print("Read %s sentence pairs" % len(df)) sentence1, sentence2 = read_sentence(df, lang1, lang2) source = Lang() target = Lang() pairs = [] for i in range(len(df)): if len(sentence1[i].split(' ')) < MAX_LENGTH and len(sentence2[i].split(' ')) < MAX_LENGTH: full = [sentence1[i], sentence2[i]] source.addSentence(sentence1[i]) target.addSentence(sentence2[i]) pairs.append(full) return source, target, pairs
Another useful function that you will use is converting pairs into Tensors. This is very important because our network only reads tensor type data. It is also important because this is the part where, at every end of the sentence, there will be a token to tell the network that the input is finished. For every word in the sentence, it will get the index from the appropriate word in the dictionary and add a token at the end of the sentence.
def indexesFromSentence(lang, sentence): return [lang.word2index[word] for word in sentence.split(' ')] def tensorFromSentence(lang, sentence): indexes = indexesFromSentence(lang, sentence) indexes.append(EOS_token) return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1) def tensorsFromPair(input_lang, output_lang, pair): input_tensor = tensorFromSentence(input_lang, pair[0]) target_tensor = tensorFromSentence(output_lang, pair[1]) return (input_tensor, target_tensor)
Seq2Seq Model

PyTorch Seq2seq model is a kind of model that uses a PyTorch encoder decoder on top of the model. The Encoder will encode the sentence word by word into an index of vocabulary or known words with an index, and the decoder will predict the output of the coded input by decoding the input in sequence and will try to use the last input as the next input if it is possible. With this method, it is also possible to predict the next input to create a sentence. Each sentence will be assigned a token to mark the end of the sequence. At the end of prediction, there will also be a token to mark the end of the output. So, from the encoder, it will pass a state to the decoder to predict the output.

The Encoder will encode our input sentence word by word in sequence, and in the end there will be a token to mark the end of a sentence. The encoder consists of an Embedding layer and a GRU layer. The Embedding layer is a lookup table that stores the embedding of our input into a fixed-sized dictionary of words. It will be passed to a GRU layer. The GRU layer is a Gated Recurrent Unit that consists of a multiple-layer type of RNN that will calculate the sequenced input. This layer will calculate the hidden state from the previous one and update the reset, update, and new gates.

The Decoder will decode the input from the encoder output. It will try to predict the next output and try to use it as the next input if it is possible. The Decoder consists of an Embedding layer, a GRU layer, and a Linear layer. The embedding layer will make a lookup table for the output and pass it into a GRU layer to calculate the predicted output state. After that, a Linear layer will help to calculate the activation function to determine the true value of the predicted output.
class Encoder(nn.Module): def __init__(self, input_dim, hidden_dim, embbed_dim, num_layers): super(Encoder, self).__init__() #set the encoder input dimesion , embbed dimesion, hidden dimesion, and number of layers self.input_dim = input_dim self.embbed_dim = embbed_dim self.hidden_dim = hidden_dim self.num_layers = num_layers #initialize the embedding layer with input and embbed dimention self.embedding = nn.Embedding(input_dim, self.embbed_dim) #intialize the GRU to take the input dimetion of embbed, and output dimention of hidden and #set the number of gru layers self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers) def forward(self, src): embedded = self.embedding(src).view(1,1,-1) outputs, hidden = self.gru(embedded) return outputs, hidden class Decoder(nn.Module): def __init__(self, output_dim, hidden_dim, embbed_dim, num_layers): super(Decoder, self).__init__() #set the encoder output dimension, embed dimension, hidden dimension, and number of layers self.embbed_dim = embbed_dim self.hidden_dim = hidden_dim self.output_dim = output_dim self.num_layers = num_layers # initialize every layer with the appropriate dimension. For the decoder layer, it will consist of an embedding, GRU, a Linear layer and a Log softmax activation function. self.embedding = nn.Embedding(output_dim, self.embbed_dim) self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers) self.out = nn.Linear(self.hidden_dim, output_dim) self.softmax = nn.LogSoftmax(dim=1) def forward(self, input, hidden): # reshape the input to (1, batch_size) input = input.view(1, -1) embedded = F.relu(self.embedding(input)) output, hidden = self.gru(embedded, hidden) prediction = self.softmax(self.out(output[0])) return prediction, hidden class Seq2Seq(nn.Module): def __init__(self, encoder, decoder, device, MAX_LENGTH=MAX_LENGTH): super().__init__() #initialize the encoder and decoder self.encoder = encoder self.decoder = decoder self.device = device def forward(self, source, target, teacher_forcing_ratio=0.5): input_length = source.size(0) #get the input length (number of words in sentence) batch_size = target.shape[1] target_length = target.shape[0] vocab_size = self.decoder.output_dim #initialize a variable to hold the predicted outputs outputs = torch.zeros(target_length, batch_size, vocab_size).to(self.device) #encode every word in a sentence for i in range(input_length): encoder_output, encoder_hidden = self.encoder(source[i]) #use the encoder's hidden layer as the decoder hidden decoder_hidden = encoder_hidden.to(device) #add a token before the first predicted word decoder_input = torch.tensor([SOS_token], device=device) # SOS #topk is used to get the top K value over a list #predict the output word from the current target word. If we enable the teaching force, then the next decoder input is the next word, else, use the decoder output highest value. for t in range(target_length): decoder_output, decoder_hidden = self.decoder(decoder_input, decoder_hidden) outputs[t] = decoder_output teacher_force = random.random() < teacher_forcing_ratio topv, topi = decoder_output.topk(1) input = (target[t] if teacher_force else topi) if(teacher_force == False and input.item() == EOS_token): break return outputs
Step 3) Training the Model
The training process in Seq2seq models starts with converting each pair of sentences into Tensors from their Lang index. Our sequence to sequence model will use SGD as the optimizer and the NLLLoss function to calculate the losses. The training process begins with feeding the pair of a sentence to the model to predict the correct output. At each step, the output from the model will be calculated with the true words to find the losses and update the parameters. So because you will use 75000 iterations, our sequence to sequence model will generate 75000 random pairs from our dataset.
teacher_forcing_ratio = 0.5 def clacModel(model, input_tensor, target_tensor, model_optimizer, criterion): model_optimizer.zero_grad() input_length = input_tensor.size(0) loss = 0 epoch_loss = 0 # print(input_tensor.shape) output = model(input_tensor, target_tensor) num_iter = output.size(0) print(num_iter) #calculate the loss from a predicted sentence with the expected result for ot in range(num_iter): loss += criterion(output[ot], target_tensor[ot]) loss.backward() model_optimizer.step() epoch_loss = loss.item() / num_iter return epoch_loss def trainModel(model, source, target, pairs, num_iteration=20000): model.train() optimizer = optim.SGD(model.parameters(), lr=0.01) criterion = nn.NLLLoss() total_loss_iterations = 0 training_pairs = [tensorsFromPair(source, target, random.choice(pairs)) for i in range(num_iteration)] for iter in range(1, num_iteration+1): training_pair = training_pairs[iter - 1] input_tensor = training_pair[0] target_tensor = training_pair[1] loss = clacModel(model, input_tensor, target_tensor, optimizer, criterion) total_loss_iterations += loss if iter % 5000 == 0: avarage_loss= total_loss_iterations / 5000 total_loss_iterations = 0 print('%d %.4f' % (iter, avarage_loss)) torch.save(model.state_dict(), 'mytraining.pt') return model
Step 4) Test the Model
The evaluation process of Seq2seq PyTorch is to check the model output. Each pair of Sequence to sequence models will be fed into the model and generate the predicted words. After that, you will look at the highest value at each output to find the correct index. And in the end, you will compare it to see our model prediction with the true sentence.
def evaluate(model, input_lang, output_lang, sentences, max_length=MAX_LENGTH): with torch.no_grad(): input_tensor = tensorFromSentence(input_lang, sentences[0]) output_tensor = tensorFromSentence(output_lang, sentences[1]) decoded_words = [] output = model(input_tensor, output_tensor) # print(output_tensor) for ot in range(output.size(0)): topv, topi = output[ot].topk(1) # print(topi) if topi[0].item() == EOS_token: decoded_words.append('' ) break else: decoded_words.append(output_lang.index2word[topi[0].item()]) return decoded_words def evaluateRandomly(model, source, target, pairs, n=10): for i in range(n): pair = random.choice(pairs) print('source {}'.format(pair[0])) print('target {}'.format(pair[1])) output_words = evaluate(model, source, target, pair) output_sentence = ' '.join(output_words) print('predicted {}'.format(output_sentence))
Now, let us start our training with Seq to Seq, with the number of iterations of 75000 and num of RNN layers of 1 with the hidden size of 512.
lang1 = 'eng' lang2 = 'ind' source, target, pairs = process_data(lang1, lang2) randomize = random.choice(pairs) print('random sentence {}'.format(randomize)) #print number of words input_size = source.n_words output_size = target.n_words print('Input : {} Output : {}'.format(input_size, output_size)) embed_size = 256 hidden_size = 512 num_layers = 1 num_iteration = 100000 #create encoder-decoder model encoder = Encoder(input_size, hidden_size, embed_size, num_layers) decoder = Decoder(output_size, hidden_size, embed_size, num_layers) model = Seq2Seq(encoder, decoder, device).to(device) #print model print(encoder) print(decoder) model = trainModel(model, source, target, pairs, num_iteration) evaluateRandomly(model, source, target, pairs)
As you can see, our predicted sentence is not matched very well, so in order to get higher accuracy, you need to train with a lot more data and try to add more iterations and number of layers using Sequence to sequence learning.
random sentence ['tom is finishing his work', 'tom sedang menyelesaikan pekerjaannya'] Input : 3551 Output : 4253 Encoder( (embedding): Embedding(3551, 256) (gru): GRU(256, 512) ) Decoder( (embedding): Embedding(4253, 256) (gru): GRU(256, 512) (out): Linear(in_features=512, out_features=4253, bias=True) (softmax): LogSoftmax() ) 5000 4.0906 10000 3.9129 15000 3.8171 20000 3.8369 25000 3.8199 30000 3.7957 75000 3.7044