Boundary Value Analysis and Equivalence Partitioning
⚡ Smart Summary
Equivalence Partitioning and Boundary Value Analysis are black-box testing techniques that compress large input ranges into equivalence classes and test partition edges, delivering strong defect detection with efficient coverage across valid and invalid inputs.

Exhaustive testing is rarely feasible due to time and combinatorial limits. Equivalence Partitioning and Boundary Value Analysis solve this by grouping similar inputs and targeting their edges for stronger coverage with fewer cases.
What is Equivalence Partitioning?
Equivalence Partitioning (also called Equivalence Class Partitioning or ECP) is a black-box technique that divides input data into groups of equivalent values. The tester picks one representative per class, assuming the software behaves the same for every member.
- Splits the input domain into valid and invalid equivalence classes.
- Applies at all levels of testing—unit, integration, system, and acceptance.
What is Boundary Value Analysis?
Boundary Value Analysis (BVA), also called range checking, validates the extreme ends of each equivalence class. Because defects cluster at range limits, BVA targets five key points:
- Minimum
- Just above the minimum
- A nominal value
- Just below the maximum
- Maximum

BVA complements Equivalence Partitioning: once classes are defined, their boundary values surface off-by-one and edge bugs.
Why Use Equivalence Partitioning and Boundary Value Analysis?
Intelligent test selection is essential when combinations are too large to test exhaustively. These techniques offer three benefits:
- Compress large test case volumes into manageable chunks.
- Provide clear rules for choosing test data without sacrificing effectiveness.
- Suit calculation-intensive apps with many numeric variables.
How to Perform Equivalence Partitioning (Example)
- Consider the Order Pizza text box below.
- Quantities 1–10 are valid; a success message appears.
- Quantities 11–99 are invalid, triggering “Only 10 Pizza can be ordered”.
Test Conditions:
- Any number above 10 is invalid.
- Any number below 1 is invalid.
- Numbers 1–10 are valid.
- Any three-digit number like -100 is invalid.
Testing every value produces 100+ cases. Equivalence Partitioning groups the domain into classes with identical behavior.
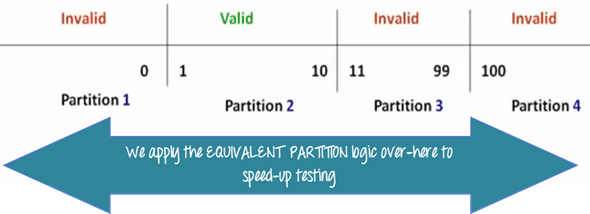
These groups are called Equivalence Classes. Pick one value per class—if it passes, all others pass; if it fails, the whole class fails.
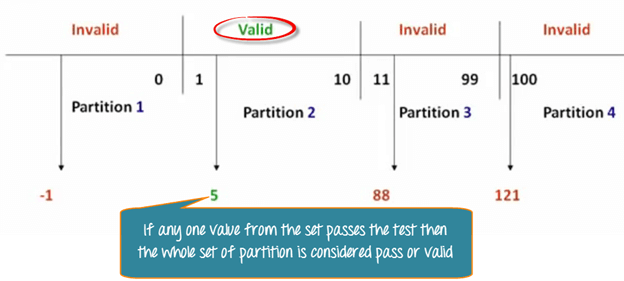
How to Perform Boundary Value Analysis (Example)
Using the same Pizza field, BVA checks partition edges rather than nominal values. Testers evaluate 0, 1, 10, and 11—covering valid and invalid boundaries.
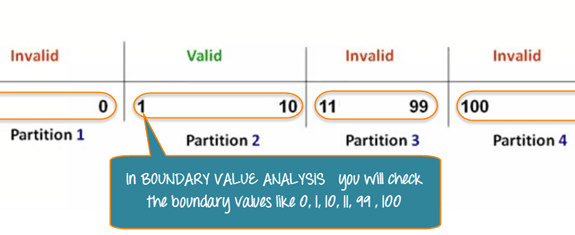
For an input accepting 1 to 10, boundary test cases are:
| Test Scenario Description | Expected Outcome |
|---|---|
| Boundary Value = 0 | System should NOT accept |
| Boundary Value = 1 | System should accept |
| Boundary Value = 2 | System should accept |
| Boundary Value = 9 | System should accept |
| Boundary Value = 10 | System should accept |
| Boundary Value = 11 | System should NOT accept |
Equivalence Partitioning vs Boundary Value Analysis
Both reduce test volume but differ in focus and timing.
| Aspect | Equivalence Partitioning | Boundary Value Analysis |
|---|---|---|
| Focus | Groups of equivalent inputs | Edges of each group |
| Data selection | One value per class | Min, near-min, nominal, near-max, max |
| Best for | Reducing redundant cases | Catching off-by-one defects |
| Order | Applied first | Applied next |
Example: Password Field Validation
A password field accepting 6 to 10 characters forms three partitions—0-5, 6-10, and 11-14—with equivalent results within each.
| # | Test Scenario | Expected Outcome |
|---|---|---|
| 1 | Enter 0 to 5 characters | System should not accept |
| 2 | Enter 6 to 10 characters | System should accept |
| 3 | Enter 11 to 14 characters | System should not accept |
Best Practices for Equivalence Partitioning and BVA
Follow these practices to keep coverage strong while controlling test counts:
- Map every domain: List valid, invalid, and special-case partitions first.
- Test both sides of each limit: Include values just inside and outside to catch off-by-one errors.
- Combine techniques: Pair with decision tables or state-transition testing for complex logic.
- Automate edge cases: Parameterize boundary values so regression suites run consistently.
Key Takeaways
- Equivalence Partitioning groups similar inputs; one value per class is enough.
- Boundary Value Analysis validates partition limits and valid/invalid edges.
- Both are black-box techniques for numeric or range-based fields.
- Combining them cuts test volume without losing defect-detection quality.
Boundary Value Analysis and Equivalence Partitioning Testing Video
Click here if the video is not accessible