What is Dimensional Modeling in Data Warehouse? Learn Types
Dimensional Modeling
Dimensional Modeling (DM) is a data structure technique optimized for data storage in a Data warehouse. The purpose of dimensional modeling is to optimize the database for faster retrieval of data. The concept of Dimensional Modelling was developed by Ralph Kimball and consists of “fact” and “dimension” tables.
A dimensional model in data warehouse is designed to read, summarize, analyze numeric information like values, balances, counts, weights, etc. in a data warehouse. In contrast, relation models are optimized for addition, updating and deletion of data in a real-time Online Transaction System.
These dimensional and relational models have their unique way of data storage that has specific advantages.
For instance, in the relational mode, normalization and ER models reduce redundancy in data. On the contrary, dimensional model in data warehouse arranges data in such a way that it is easier to retrieve information and generate reports.
Hence, Dimensional models are used in data warehouse systems and not a good fit for relational systems.
Elements of Dimensional Data Model
Fact
Facts are the measurements/metrics or facts from your business process. For a Sales business process, a measurement would be quarterly sales number
Dimension
Dimension provides the context surrounding a business process event. In simple terms, they give who, what, where of a fact. In the Sales business process, for the fact quarterly sales number, dimensions would be
- Who – Customer Names
- Where – Location
- What – Product Name
In other words, a dimension is a window to view information in the facts.
Attributes
The Attributes are the various characteristics of the dimension in dimensional data modeling.
In the Location dimension, the attributes can be
- State
- Country
- Zipcode etc.
Attributes are used to search, filter, or classify facts. Dimension Tables contain Attributes
Fact Table
A fact table is a primary table in dimension modelling.
A Fact Table contains
- Measurements/facts
- Foreign key to dimension table
Dimension Table
- A dimension table contains dimensions of a fact.
- They are joined to fact table via a foreign key.
- Dimension tables are de-normalized tables.
- The Dimension Attributes are the various columns in a dimension table
- Dimensions offers descriptive characteristics of the facts with the help of their attributes
- No set limit set for given for number of dimensions
- The dimension can also contain one or more hierarchical relationships
Types of Dimensions in Data Warehouse
Following are the Types of Dimensions in Data Warehouse:
- Conformed Dimension
- Outrigger Dimension
- Shrunken Dimension
- Role-playing Dimension
- Dimension to Dimension Table
- Junk Dimension
- Degenerate Dimension
- Swappable Dimension
- Step Dimension
Steps of Dimensional Modelling
The accuracy in creating your Dimensional modeling determines the success of your data warehouse implementation. Here are the steps to create Dimension Model
- Identify Business Process
- Identify Grain (level of detail)
- Identify Dimensions
- Identify Facts
- Build Star
The model should describe the Why, How much, When/Where/Who and What of your business process
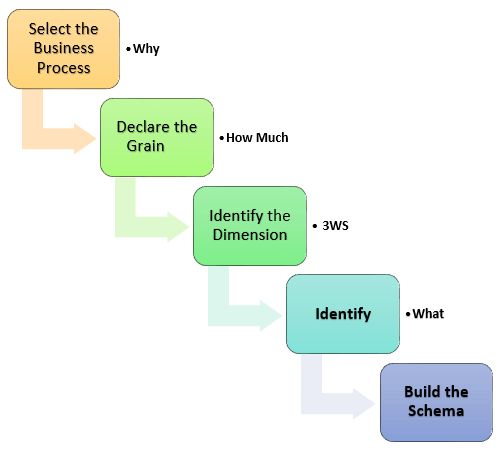
Step 1) Identify the Business Process
Identifying the actual business process a datarehouse should cover. This could be Marketing, Sales, HR, etc. as per the data analysis needs of the organization. The selection of the Business process also depends on the quality of data available for that process. It is the most important step of the Data Modelling process, and a failure here would have cascading and irreparable defects.
To describe the business process, you can use plain text or use basic Business Process Modelling Notation (BPMN) or Unified Modelling Language (UML).
Step 2) Identify the Grain
The Grain describes the level of detail for the business problem/solution. It is the process of identifying the lowest level of information for any table in your data warehouse. If a table contains sales data for every day, then it should be daily granularity. If a table contains total sales data for each month, then it has monthly granularity.
During this stage, you answer questions like
- Do we need to store all the available products or just a few types of products? This decision is based on the business processes selected for Datawarehouse
- Do we store the product sale information on a monthly, weekly, daily or hourly basis? This decision depends on the nature of reports requested by executives
- How do the above two choices affect the database size?
Example of Grain:
The CEO at an MNC wants to find the sales for specific products in different locations on a daily basis.
So, the grain is “product sale information by location by the day.”
Step 3) Identify the Dimensions
Dimensions are nouns like date, store, inventory, etc. These dimensions are where all the data should be stored. For example, the date dimension may contain data like a year, month and weekday.
Example of Dimensions:
The CEO at an MNC wants to find the sales for specific products in different locations on a daily basis.
Dimensions: Product, Location and Time
Attributes: For Product: Product key (Foreign Key), Name, Type, Specifications
Hierarchies: For Location: Country, State, City, Street Address, Name
Step 4) Identify the Fact
This step is co-associated with the business users of the system because this is where they get access to data stored in the data warehouse. Most of the fact table rows are numerical values like price or cost per unit, etc.
Example of Facts:
The CEO at an MNC wants to find the sales for specific products in different locations on a daily basis.
The fact here is Sum of Sales by product by location by time.
Step 5) Build Schema
In this step, you implement the Dimension Model. A schema is nothing but the database structure (arrangement of tables). There are two popular schemas
- Star Schema
The star schema architecture is easy to design. It is called a star schema because diagram resembles a star, with points radiating from a center. The center of the star consists of the fact table, and the points of the star is dimension tables.
The fact tables in a star schema which is third normal form whereas dimensional tables are de-normalized.
- Snowflake Schema
The snowflake schema is an extension of the star schema. In a snowflake schema, each dimension are normalized and connected to more dimension tables.
Also Check:- Star and Snowflake Schema in Data Warehouse with Model Examples
Rules for Dimensional Modelling
Following are the rules and principles of Dimensional Modeling:
- Load atomic data into dimensional structures.
- Build dimensional models around business processes.
- Need to ensure that every fact table has an associated date dimension table.
- Ensure that all facts in a single fact table are at the same grain or level of detail.
- It’s essential to store report labels and filter domain values in dimension tables
- Need to ensure that dimension tables use a surrogate key
- Continuously balance requirements and realities to deliver business solution to support their decision-making
Benefits of Dimensional Modeling
- Standardization of dimensions allows easy reporting across areas of the business.
- Dimension tables store the history of the dimensional information.
- It allows to introduce entirely new dimension without major disruptions to the fact table.
- Dimensional also to store data in such a fashion that it is easier to retrieve the information from the data once the data is stored in the database.
- Compared to the normalized model dimensional table are easier to understand.
- Information is grouped into clear and simple business categories.
- The dimensional model is very understandable by the business. This model is based on business terms, so that the business knows what each fact, dimension, or attribute means.
- Dimensional models are deformalized and optimized for fast data querying. Many relational database platforms recognize this model and optimize query execution plans to aid in performance.
- Dimensional modelling in data warehouse creates a schema which is optimized for high performance. It means fewer joins and helps with minimized data redundancy.
- The dimensional model also helps to boost query performance. It is more denormalized therefore it is optimized for querying.
- Dimensional models can comfortably accommodate change. Dimension tables can have more columns added to them without affecting existing business intelligence applications using these tables.
What is Multi-Dimensional Data Model in Data Warehouse?
Multidimensional data model in data warehouse is a model which represents data in the form of data cubes. It allows to model and view the data in multiple dimensions and it is defined by dimensions and facts. Multidimensional data model is generally categorized around a central theme and represented by a fact table.
Summary
- A dimensional model is a data structure technique optimized for Data warehousing tools.
- Facts are the measurements/metrics or facts from your business process.
- Dimension provides the context surrounding a business process event.
- Attributes are the various characteristics of the dimension modelling.
- A fact table is a primary table in a dimensional model.
- A dimension table contains dimensions of a fact.
- There are three types of facts 1. Additive 2. Non-additive 3. Semi- additive .
- Types of Dimensions are Conformed, Outrigger, Shrunken, Role-playing, Dimension to Dimension Table, Junk, Degenerate, Swappable and Step Dimensions.
- Five steps of Dimensional modeling are 1. Identify Business Process 2. Identify Grain (level of detail) 3. Identify Dimensions 4. Identify Facts 5. Build Star
- For Dimensional modelling in data warehouse, there is a need to ensure that every fact table has an associated date dimension table.