Apache Solr Tutorial: What is Solr? Architecture
⚡ Smart Summary
Apache Solr is an open-source, Java-based search server built on Apache Lucene. It indexes large volumes of text-centric data and returns relevant results via REST APIs, offering full-text search, faceting, scalability, and both standalone and SolrCloud deployment modes.

What is Apache Solr?
Apache Solr is an open-source search server platform written in Java language by Apache software foundation. It is highly scalable and ready to deploy search engine to handle a large volume of text-centric data. The purpose of using Apache Solr is to index and search large amount of web content and give relevant content based on search query.
Apache Solr is a REST-API based HTTP wrapper around the full-text search engine called Apache Lucene. An inverted index is a list of words where each word-entry links to the documents it is stored in. That way getting all documents for the search query “guru99” with simple ‘get’ operation.
History of Apache Solr
- 1999: Doug Cutting published Lucene
- 2004: Solr was developed at CNET by Yonik Seeley as a part company in-house project
- 2006: CNET publish the source code by donating it to the Apache Software Foundation
- 2008: Solr 1.3 was released with enhanced search capabilities and performance enhancements
- 2010: Merger of Lucene and Solr
- 2012: Solr version 4.0 was released, with new Solr Cloud feature
- 2016: Solr 6.0, was released which offers support for the execution of parallel SQL queries
- 2017: Solr 7.0 was released, adding an autoscaling framework and the JSON Facet API
- 2019: Solr 8.0 was released with nested document support and improved streaming expressions
- 2021: Lucene and Solr separated again, and Solr became an independent Apache top-level project
- 2022: Solr 9.0 was released as the first version independent from Lucene, adding vector search and Kubernetes support
- 2026: Solr 10.0 was released as the latest major version
Features of Apache Solr
Here are Important features of Apache Solr:
- Automatic Load Balancing
- Standards-Based Open Interfaces – XML, JSON, and HTTP
- Recommendations & Spell Suggestions are supported
- Support for Auto-Completion and Geo-Spatial Search
- Built-in Security for Authentication and Authorization
- Allows you to perform a multilingual Keyword search
- Autocomplete/Type-ahead Prediction
- Batch and Streaming processing
- Building machine-learning models are easy
- Specially optimized for high volume web Traffic
- Comprehensive HTML Admiration Interfaces
- Supports both Schema and Schemaless configuration
- Faceted Search and Filtering
- Central Configuration For Entire Cluster
Key Terms used in Apache Solr
Now in this Solr search engine tutorial, we will learn about key terms used in Apache Solr:
| Key Term | Description |
|---|---|
| Solr Core | Solr Core can be defined as an index of texts and fields derived from all the documents. One Solr Instance may have single or multiple Solr Cores. Core = an instance of Lucene Index + Solr configuration |
| Solr Instance | Solr Instance is an instance a Solr running in the Java Virtual Machine (JVM). In Standalone mode, it only offers one instance whereas in cloud mode you can have one or more instances. |
| Indexing | Indexing is a method for adding document’s content to Solr Index. Apache Solr uses Apache Lucene Inverted Index technique. |
| Document | It is a group of fields and their values. A document is a basic unit of data stored in Apache Core. One Apache core may contain one or more Documents. |
| Field | The field is a key-value pair that stores the actual data in a Document. Key specifies the field name and value contains that Field data. A document may have a one or multiple fields. It is used by Apache Solr to index the document content. |
| Restful APIs | To communicate with Solr, it is not necessary to have used Java programming. Instead, Apache Solr provides restful services to communicate with it. You can send documents and receive results in various file formats like JSON, XML, and CSV. |
| Full-text search | Solr offers features for full-text search such as tokens, phrases, spell checking, auto-complete, wildcard, etc. |
| Admin Interface | Solr offers an easy-to-use, user-friendly, feature powered, user interface. Using the interface you can perform tasks like managing logs, add, delete, update and search documents. |
| Text-Centric and Sorted by Relevance | Apache Solr is used to search text documents, and the results are delivered according to the user’s query. |
| Node | In Solr cloud, every single instance is known as a node. |
| Cluster | A cluster is a collection of nodes. |
| Collection | A cluster has a logical index which is also called a collection. |
| Shard | It is a small area of the collection which offers single or multiple replicas of the index. |
| Replica | A replica is a copy of shard which runs in a node. |
| Leader | It is a replica of the shard, which sends the requests of the Solr Cloud for the rest of replicas. |
Apache Solr Architecture
Now in this Solr search tutorial, let’s learn about Apache Solr Architecture:

Apache Solr compromises following components
Query
The query parser parses the queries which you need to pass to Solr. It verifies your query to check syntactical errors. After parsing the queries, it translates into a format which is known by Lucene.
Request Handler
The request sends to Apache Solr are processed by the request handler. The request can be a query request or index update requests. You need to select the request handler according to your requirement. To pass a request to Solr, you need to map the handler to a specific URL end-point.
Response Writer
A response writer will generate formatted outputs for input queries. It supports various formats like XML, JSON, CSV.etc. You may have different response writers for different type of requests.
Update Handler
When you send an update request to Apache Solr, it is run through a set of plugins, signature, logging, indexing. This process is known as update request processor. Update handler also responsible for modifications like adding or dropping filed, etc.
Apache Solr Applications
| Application | Usage |
|---|---|
| Intranet Portal |
|
| Federated Client |
|
| Instrument Datasets |
|
| Regulatory Documents |
|
| Embedded in PLM Application |
|
How to install Apache Solr?
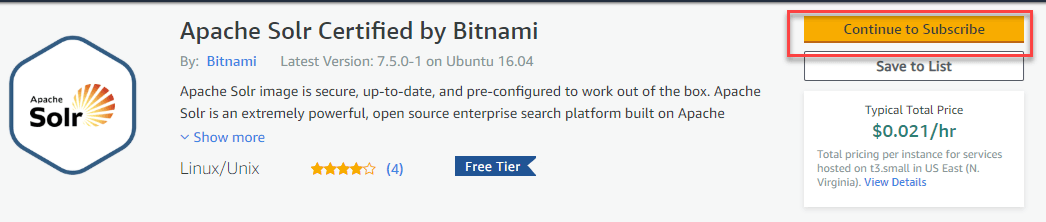
Step 1) Open website & Continue to Subscribe
Go to this link, Click “Continue to Subscribe.”
Step 2) Click on Accept Terms
On the next page, Click on Accept Terms.

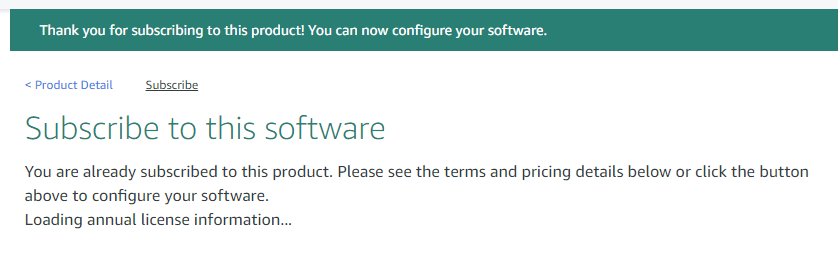
Step 3) Wait for some time
Next, Wait for some time and then, Request is accepted after some time.
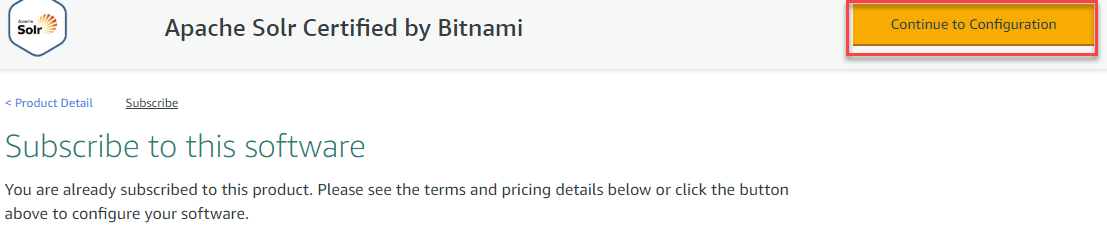
Step 4) Continue to Configuration
Refresh the page and, Click “Continue to Configuration”
Step 5) Continue to Launch
Keep the settings default and, Click “Continue to Launch.”

Step 6) Keep the settings default
On the next page, Keep the settings default
- Ensure you have the pem file of the key
- Click “Launch”

You will see this success message

Step 7) Note the public DNS
In EC2 console, Note the public DNS of your instance

Step 8) Open below URL
To access Solr, Simply use the URL
http://publicdns:8983
in our case it becomes
http://ec2-18-221-175-53.us-east-2.compute.amazonaws.com:8983
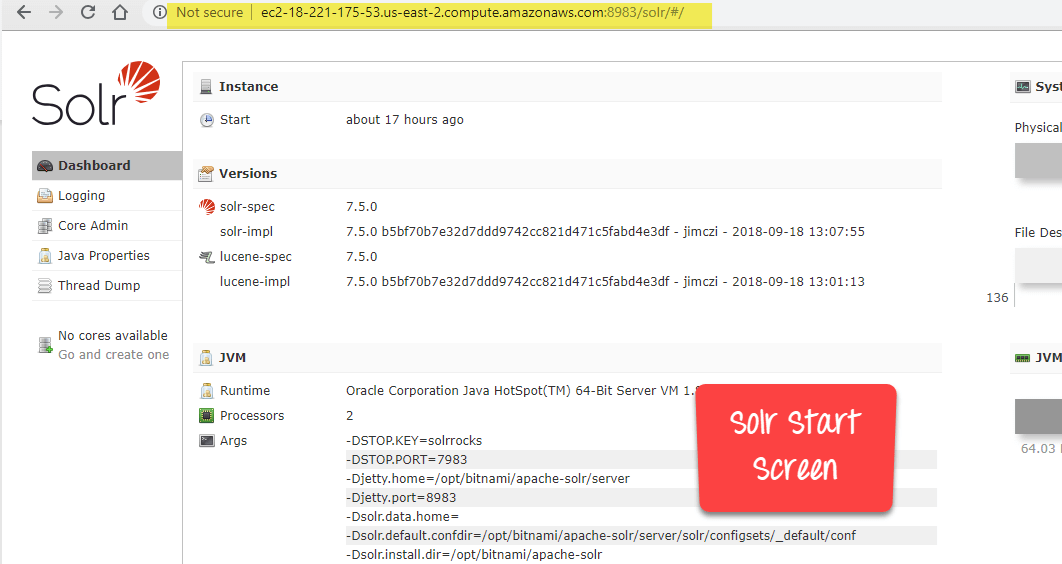
Note: If you have trouble accessing the instance, change inbound and outbound rules in your instance to allow all traffic as shown in the below Solr query example:

Elasticsearch Vs. Apache Solr
| Parameters | Apache Solr | Elastic Search |
|---|---|---|
| Nature | It is an open source project. | Not an open-sourced project. |
| Static status | Static in shema.xml | Static in elasticsearch.yml |
| Format | XML, CSV, JSON | Only JSON |
| Index | Can be reloaded during runtime with collection/core reload | Defined during index/type creation with a REST call |
| Documentation | It is well documented. | It is badly documented. |
| Splitting Shards | Possible | Not possible |
Advantages of Apache Solr
- Helps you to reduce the amount of time taken to locate Information
- It is fast, simple, powerful and flexible search engine
- Helps you to make your products and services more accessible
- Increase customer spend on a web application
- Helps you to improve user experience on the web application to increase revenue and profit
- Comprehensive HTML based Administration Interface
- Flexible and Adaptable with XML configuration
- Extensible Plugin Architecture
- Highly Scalable, robust, fault-tolerant search engine
- Supports Distributed, Shading, Replication, Clustering and Multi-Node Architecture
Disadvantages of Apache Solr
- It is not an ACID compliant Data Store
- It is not useful as a primary data store. Only useful as Secondary Data Store
- Not offers support for transactions and distributed transactions
- Not support Joins and Complex Queries
- Not optimal for Normalized Data