Data Warehouse Architecture, Components & Diagram Concepts
⚡ Smart Summary
Data Warehouse Architecture defines how historical and cumulative data from many sources is organized into tiered layers and connected components, enabling reliable reporting, analysis, and a single version of truth for organizational decision making and forecasting.

Data Warehouse Concepts
A data warehouse exists to give a company a single version of the truth for decision making and forecasting. It is an information system that holds historical and cumulative data drawn from one or many sources.
By organizing that data for analysis rather than transactions, a data warehouse simplifies the reporting and analysis work of an entire organization.
Characteristics of Data Warehouse
A data warehouse has four defining characteristics that set it apart from a routine operational database:
- Subject-Oriented
- Integrated
- Time-Variant
- Non-volatile
Subject-Oriented
A data warehouse is subject-oriented because it delivers information about a theme rather than a company’s ongoing operations. Typical subjects include sales, marketing, and distribution.
Instead of day-to-day processing, the warehouse emphasizes modeling and analysis for decision making. It offers a simple, concise view of each subject and leaves out data that does not support the decision process.
Integrated
Integration is closely tied to subject orientation. In a data warehouse, integration means establishing a common unit of measure for all similar data drawn from dissimilar databases, and storing that data in a common, universally acceptable manner.
A data warehouse is built by integrating data from varied sources such as a mainframe, relational databases, and flat files. It must also keep consistent naming conventions, formats, and coding.
This consistency in naming, attribute measures, and encoding structure is what makes effective analysis possible. Consider the following example:
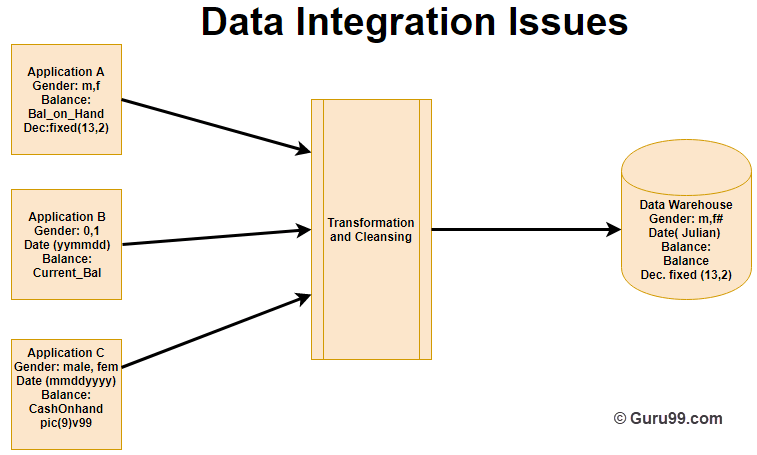
In the example above, three applications labeled A, B, and C each store Gender, Date, and Balance information, but every application stores it in a different way:
- Application A stores the gender field as logical values such as M or F.
- Application B stores the gender field as a numerical value.
- Application C stores the gender field as a character value.
- The same variation applies to the Date and Balance fields.
After the transformation and cleaning process, all of this data is stored in a common format inside the data warehouse.
Time-Variant
The time horizon of a data warehouse is far broader than that of an operational system. The data is recognized with a particular period and offers a historical point of view, so it always carries an element of time, either explicitly or implicitly.
One place this time variance appears is in the structure of the record key. Every primary key in the warehouse should carry an element of time, such as the day, week, or month.
Another aspect of time variance is that once data is inserted into the warehouse, it cannot be updated or changed.
Non-volatile
A data warehouse is also non-volatile, which means earlier data is not erased when new data arrives. The data is read-only and refreshed periodically, which helps analysts study historical data and understand what happened and when.
Because it does not need transaction processing, recovery, or concurrency control, a warehouse omits the delete, update, and insert activities common in an operational application. Only two data operations are performed in data warehousing:
- Data loading
- Data access
The table below highlights some major differences between an operational application and a data warehouse:
| Operational Application | Data Warehouse |
|---|---|
| Complex program must be coded to make sure that data upgrade processes maintain high integrity of the final product. | This kind of issue does not happen because data update is not performed. |
| Data is placed in a normalized form to ensure minimal redundancy. | Data is not stored in normalized form. |
| Technology needed to support issues of transactions, data recovery, rollback, and deadlock resolution is quite complex. | It offers relative simplicity in technology. |
Data Warehouse Architecture
Data Warehouse Architecture is complex because the system stores historical and cumulative data from multiple sources. There are three approaches to constructing the warehouse layers: single-tier, two-tier, and three-tier.
Single-tier architecture aims to minimize the amount of data stored by removing redundancy. It is rarely used in practice.
Two-tier architecture separates the physically available sources from the data warehouse. It is not easily expandable, supports fewer end-users, and can hit connectivity problems because of network limitations.
Three-tier architecture is the most widely used design of a data warehouse.
It consists of the top, middle, and bottom tiers:
- Bottom Tier: The database of the warehouse serves as the bottom tier. It is usually a relational database system, and data is cleansed, transformed, and loaded into this layer using back-end tools.
- Middle Tier: The middle tier is an OLAP server implemented using either the ROLAP or MOLAP model. It presents an abstracted view of the database and acts as a mediator between the end-user and the database.
- Top Tier: The top tier is a front-end client layer. It holds the tools and APIs used to connect and pull data out of the warehouse, such as query tools, reporting tools, managed query tools, analysis tools, and data mining tools.
Datawarehouse Components
The components and overall architecture of a data warehouse work together as shown in the diagram below.
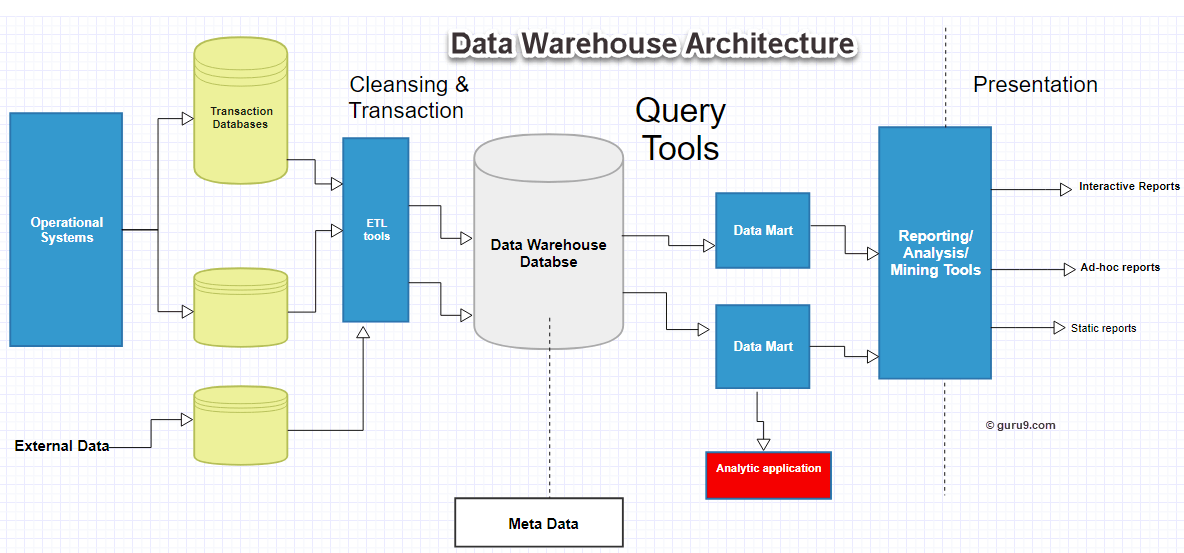
The data warehouse is based on an RDBMS server, a central information repository surrounded by key components that keep the whole environment functional, manageable, and accessible.
A data warehouse has five main components, described below.
Data Warehouse Database
The central database is the foundation of the warehousing environment and is implemented on RDBMS technology. Because a traditional RDBMS is tuned for transaction processing rather than warehousing, resource-intensive operations such as ad-hoc queries, multi-table joins, and aggregates can slow it down.
For that reason, alternative database approaches are used:
- Relational databases are deployed in parallel to allow for scalability, using shared-memory or shared-nothing models on various multiprocessor or massively parallel configurations.
- New index structures are used to bypass relational table scans and improve speed.
- Multidimensional databases (MDDBs) are used to overcome the limitations of relational warehouse models. An example is Essbase from Oracle.
Sourcing, Acquisition, Clean-up and Transformation Tools (ETL)
The data sourcing, transformation, and migration tools perform all the conversions, summarizations, and changes needed to turn data into a unified warehouse format. They are also called Extract, Transform, and Load (ETL) tools.
Their functionality includes the following:
- Anonymize data as per regulatory stipulations.
- Eliminate unwanted data from operational databases before loading into the warehouse.
- Search and replace common names and definitions for data arriving from different sources.
- Calculate summaries and derived data.
- Populate missing data with defaults.
- De-duplicate repeated data arriving from multiple sources.
These ETL tools may generate cron jobs, background jobs, Cobol programs, and shell scripts that regularly refresh the warehouse and help maintain the metadata.
Because they draw from many systems, ETL tools must also cope with database and data heterogeneity.
Metadata
Metadata may sound advanced, but it is simply data about data that defines the warehouse. It is used to build, maintain, and manage the warehouse.
Within the architecture, metadata specifies the source, usage, values, and features of the data and defines how the data can be changed and processed, so it stays closely connected to the warehouse.
For example, a line in a sales database may contain:
4030 KJ732 299.90
This is meaningless until the metadata explains that it represents a model number of 4030, a Sales Agent ID of KJ732, and a total sales amount of $299.90.
Metadata is therefore an essential ingredient in turning data into knowledge, and it helps answer questions such as:
- What tables, attributes, and keys does the warehouse contain?
- Where did the data come from?
- How many times is the data reloaded?
- What transformations and cleansing were applied?
Metadata falls into two categories:
- Technical Metadata: This describes the warehouse for the designers and administrators who build and run it.
- Business Metadata: This gives end-users an easy way to understand the information stored in the warehouse.
Query Tools
A primary goal of data warehousing is to give businesses the information they need to make strategic decisions, and query tools are how users interact with the system.
These tools fall into four categories:
- Query and reporting tools
- Application development tools
- Data mining tools
- OLAP tools
Query and Reporting Tools
Query and reporting tools divide into two groups: reporting tools and managed query tools.
Reporting tools split further into production reporting tools and desktop report writers:
- Report writers: These are designed for end-users who build their own analyses.
- Production reporting: These let organizations generate regular operational reports and support high-volume batch jobs such as printing and calculating. Popular examples include Brio, Business Objects, Oracle, PowerSoft, and SAS Institute.
Managed query tools help end-users by inserting a meta-layer between the user and the database, which hides the complexity of SQL and database structure.
Application Development Tools
When built-in graphical and analytical tools cannot meet an organization’s analytical needs, custom reports are built with application development tools.
Data Mining Tools
Data mining discovers meaningful new correlations, patterns, and trends inside large volumes of data, and data mining tools automate that discovery.
OLAP Tools
OLAP tools are built on a multidimensional database and let users analyze data through elaborate, multidimensional views.
Data Warehouse Bus Architecture
The data warehouse bus determines how data flows through the warehouse. That flow can be categorized as inflow, upflow, downflow, outflow, and meta-flow.
When designing the bus, you must account for the shared dimensions and facts that span data marts.
Data Marts
A data mart is an access layer used to deliver data to users. It suits large warehouses because it takes less time and money to build, although there is no single agreed definition of a data mart.
In simple terms, a data mart is a subsidiary of a data warehouse. It partitions data for a specific group of users and can live in the same database as the warehouse or on a physically separate one.
Data Warehouse Architecture Best Practices
To design a sound data warehouse architecture, follow the best practices below:
- Use data warehouse models that are optimized for information retrieval, whether a dimensional, denormalized, or hybrid approach.
- Choose an appropriate design approach, whether top-down or bottom-up.
- Make sure data is processed quickly and accurately while consolidating it into a single version of the truth.
- Carefully design the data acquisition and cleansing process for the warehouse.
- Design a metadata architecture that allows metadata to be shared between components of the warehouse.
- Consider an Operational Data Store (ODS) model when retrieval needs are near the bottom of the data-abstraction pyramid or when multiple operational sources must be accessed.
- Ensure the data model is integrated rather than merely consolidated; in that case, use a 3NF data model, which is also ideal when acquiring ETL and data-cleansing tools.