ETL (Extract, Transform, and Load) Process in a Data Warehouse
Smart Summary
ETL (Extract, Transform, and Load) Process in Data Warehouse describes the systematic flow of data movement from multiple heterogeneous sources into a centralized repository. It ensures consistency, accuracy, and readiness of data for analytics through structured extraction, transformation, and optimized loading mechanisms.

What is ETL?
ETL is a process that extracts the data from different source systems, then transforms the data (like applying calculations, concatenations, etc.), and finally loads the data into the data warehouse system. The full form of ETL is Extract, Transform, and Load.
It’s tempting to think that creating a Data Warehouse simply involves extracting data from multiple sources and loading it into a database. Still, in reality, it requires a complex ETL process. The ETL process requires active inputs from various stakeholders, including developers, analysts, testers, and top executives, and is technically challenging.
In order to maintain its value as a tool for decision-makers, the data warehouse system needs to change with business changes. ETL is a recurring activity (daily, weekly, or monthly) of a data warehouse system and needs to be agile, automated, and well-documented.
Why do you need ETL?
There are many reasons for adopting ETL in the organization:
- It helps companies to analyze their business data for making critical business decisions.
- Transactional databases cannot answer complex business questions that can be answered by an ETL example.
- A data warehouse provides a common data repository
- ETL provides a method of moving the data from various sources into a data warehouse.
- As data sources change, the data warehouse will automatically update.
- A well-designed and documented ETL system is almost essential to the success of a data warehouse project.
- Allow verification of data transformation, aggregation, and calculation rules.
- The ETL process allows sample data comparison between the source and the target system.
- The ETL process can perform complex transformations and requires an extra area to store the data.
- ETL helps migrate data into a Data Warehouse, converting different formats and types into one consistent system.
- ETL is a predefined process for accessing and manipulating source data into the target database.
- ETL in a data warehouse offers deep historical context for the business.
- It helps to improve productivity because it codifies and reuses without the need for technical skills.
With a clear understanding of ETL’s value, let’s dive into the three-step process that makes it all work.
ETL Process in data warehouses
ETL is a 3-step process
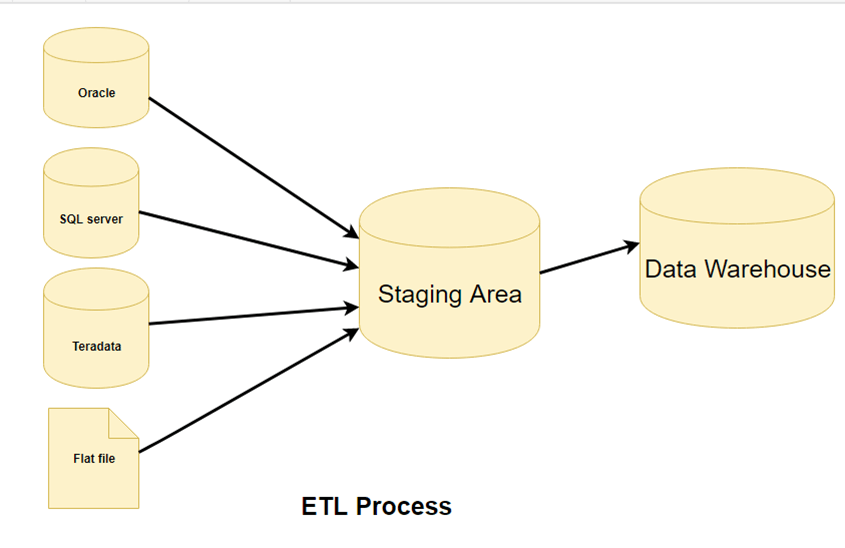
Step 1) Extraction
In this step of ETL architecture, data is extracted from the source system into the staging area. Transformations, if any, are done in the staging area so that the performance of the source system is not degraded. Also, if corrupted data is copied directly from the source into the data warehouse database, rollback will be a challenge. The staging area gives an opportunity to validate extracted data before it moves into the data warehouse.
The data warehouse needs to integrate systems that have different DBMS, Hardware, Operating Systems, and Communication Protocols. Sources could include legacy applications like Mainframes, customized applications, Point of contact devices like ATM, Call switches, text files, spreadsheets, ERP, data from vendors, and partners, among others.
Hence, one needs a logical data map before data is extracted and loaded physically. This data map describes the relationship between sources and target data.
Three Data Extraction methods:
- Full Extraction
- Partial Extraction- without update notification.
- Partial Extraction- with update notification
Irrespective of the method used, extraction should not affect the performance and response time of the source systems. These source systems are live production databases. Any slowdown or locking could affect the company’s bottom line.
Some validations are done during Extraction:
- Reconcile records with the source data
- Make sure that no spam/unwanted data is loaded
- Data type check
- Remove all types of duplicate/fragmented data
- Check whether all the keys are in place.
Step 2) Transformation
Data extracted from the source server is raw and not usable in its original form. Therefore, it needs to be cleansed, mapped, and transformed. In fact, this is the key step where the ETL process adds value and changes data such that insightful BI reports can be generated.
It is one of the important ETL concepts where you apply a set of functions on extracted data. Data that does not require any transformation is called direct move or pass-through data.
In the transformation step, you can perform customized operations on data. For instance, if the user wants the sum of sales revenue that is not in the database. Or if the first name and the last name in a table are in different columns. It is possible to concatenate them before loading.

The following are Data Integrity Problems:
- Different spellings of the same person, like Jon, John, etc.
- There are multiple ways to denote a company name, like Google, Google Inc.
- Use of different names like Cleaveland and Cleveland.
- There may be a case where different account numbers are generated by various applications for the same customer.
- In some cases, the data required files remain blank
- Invalid product collected at POS, as manual entry can lead to mistakes.
Validations are done during this stage
- Filtering – Select only certain columns to load
- Using rules and lookup tables for Data standardization
- Character Set Conversion and encoding handling
- Conversion of Units of Measurement, like Date and Time conversions, currency conversions, numerical conversions, etc.
- Data threshold validation check. For example, age cannot be more than two digits.
- Data flow validation from the staging area to the intermediate tables.
- Required fields should not be left blank.
- Cleaning ( for example, mapping NULL to 0 or Gender Male to “M” and Female to “F”, etc.)
- Split a column into multiple columns and merge multiple columns into a single column.
- Transposing rows and columns,
- Use lookups to merge data
- Using any complex data validation (e.g., if the first two columns in a row are empty, then it automatically rejects the row from processing)
Step 3) Loading
Loading data into the target data warehouse database is the last step of the ETL process. In a typical data warehouse, a huge volume of data needs to be loaded in a relatively short period (nights). Hence, the load process should be optimized for performance.
In case of load failure, recovery mechanisms should be configured to restart from the point of failure without data integrity loss. Data warehouse admins need to monitor, resume, and cancel loads as per prevailing server performance.
Types of Loading:
- Initial Load — populating all the data warehouse tables
- Incremental Load — applying ongoing changes as needed periodically.
- Full Refresh —erasing the contents of one or more tables and reloading with fresh data.
Load verification
- Ensure that the key field data is neither missing nor null.
- Test modeling views based on the target tables.
- Check that the combined values and calculated measures.
- Data checks in the dimension table as well as the history table.
- Check the BI reports on the loaded fact and dimension table.
ETL Pipelining and Parallel Processing
ETL pipelining allows extraction, transformation, and loading to occur simultaneously instead of sequentially. As soon as a portion of data is extracted, it’s transformed and loaded while new data extraction continues. This parallel processing greatly improves performance, reduces downtime, and maximizes system resource utilization.
This parallel processing is essential for real-time analytics, large-scale data integration, and cloud-based ETL systems. By overlapping tasks, pipelined ETL ensures faster data movement, higher efficiency, and more consistent data delivery for modern enterprises.
How AI Enhances Modern ETL Pipelines?
Artificial Intelligence revolutionizes ETL by making data pipelines adaptive, intelligent, and self-optimizing. AI algorithms can automatically map schemas, detect anomalies, and predict transformation rules without manual configuration. This enables ETL workflows to handle evolving data structures effortlessly while maintaining data quality.
Modern AI-enhanced ETL platforms leverage technologies such as AutoML for automatic feature engineering, NLP-driven schema mapping that understands semantic relationships between fields, and anomaly detection algorithms that identify data quality issues in real-time. These capabilities significantly reduce the manual effort traditionally required in ETL development and maintenance.
Machine learning enhances performance tuning, ensuring faster, more accurate data integration. By introducing automation and predictive intelligence, AI-powered ETL delivers real-time insights and drives greater efficiency across cloud and hybrid data ecosystems.
To implement the concepts discussed above, organizations rely on specialized ETL tools. Here are some of the leading options available in the market.
ETL Tools
There are many ETL tools available in the market. Here are some of the most prominent ones:
1. MarkLogic:
MarkLogic is a data warehousing solution that makes data integration easier and faster using an array of enterprise features. It can query different types of data like documents, relationships, and metadata.
https://www.marklogic.com/product/getting-started/
2. Oracle:
Oracle is the industry-leading database. It offers a wide range of data warehouse solutions for both on-premises and in the cloud. It helps to optimize customer experiences by increasing operational efficiency.
https://www.oracle.com/index.html
3. Amazon RedShift:
Amazon Redshift is a data warehouse tool. It is a simple and cost-effective tool to analyze all types of data using standard SQL and existing BI tools. It also allows running complex queries against petabytes of structured data.
https://aws.amazon.com/redshift/?nc2=h_m1
Here is a complete list of useful data warehouse Tools.
Best practices for the ETL process
The following are the best practices for ETL Process steps:
- Never try to cleanse all the data:
Every organization would like to have all the data clean, but most of them are not ready to pay to wait, or are not ready to wait. To clean it all would simply take too long, so it is better not to try to cleanse all the data. - Balance cleansing with business priorities:
While you should avoid over-cleaning all data, ensure that critical and high-impact fields are cleansed for reliability. Focus cleansing efforts on data elements that directly affect business decisions and reporting accuracy - Determine the cost of cleansing the data:
Before cleansing all the dirty data, it is important for you to determine the cleansing cost for every dirty data element. - To speed up query processing, have auxiliary views and indexes:
To reduce storage costs, store summarized data into disk tapes. Also, the trade-off between the volume of data to be stored and its detailed usage is required. Trade-off at the level of granularity of data to decrease the storage costs.