What is Recovery Testing? with Example
Recovery Testing
Recovery Testing is software testing technique which verifies software’s ability to recover from failures like software/hardware crashes, network failures etc. The purpose of Recovery Testing is to determine whether software operations can be continued after disaster or integrity loss. Recovery testing involves reverting back software to the point where integrity was known and reprocessing transactions to the failure point.
Recovery Testing Example
When an application is receiving data from the network, unplug the connecting cable.

- After some time, plug the cable back in and analyze the application’s ability to continue receiving data from the point at which the network connection was broken.
- Restart the system while a browser has a definite number of sessions open and check whether the browser is able to recover all of them or not
In Software Engineering, Recoverability Testing is a type of Non- Functional Testing. (Non- functional testing refers to aspects of the software that may not be related to a specific function or user action such as scalability or security.)
The time taken to recover depends upon:
- The number of restart points
- A volume of the applications
- Training and skills of people conducting recovery activities and tools available for recovery.
When there are a number of failures then instead of taking care of all failures, the recovery testing should be done in a structured fashion which means recovery testing should be carried out for one segment and then another.
It is done by professional testers. Before recovery testing, adequate backup data is kept in secure locations. This is done to ensure that the operation can be continued even after a disaster.
Life Cycle of Recovery Process
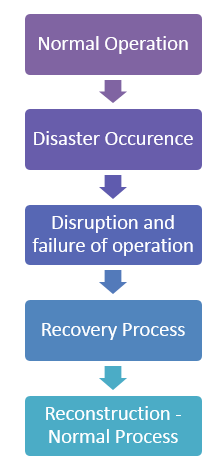
The life cycle of the recovery process can be classified into the following five steps:
- Normal operation
- Disaster occurrence
- Disruption and failure of the operation
- Disaster clearance through the recovery process
- Reconstruction of all processes and information to bring the whole system to move to normal operation
Let’s discuss these 5 steps in detail-
- A system consisting of hardware, software, and firmware integrated to achieve a common goal is made operational for carrying out a well-defined and stated goal. The system is called to perform the normal operation to carry out the designed job without any disruption within a stipulated period of time.
- A disruption may occur due to malfunction of the software, due to various reasons like input initiated malfunction, software crashing due to hardware failure, damaged due to fire, theft, and strike.
- Disruption phase is a most painful phase which leads to business losses, relation break, opportunity losses, man-hour losses and invariably financial and goodwill losses. Every sensible agency should have a plan for disaster recovery to enable the disruption phase to be minimal.
- If a backup plan and risk mitigation processes are at the right place before encountering disaster and disruption, then recovery can be done without much loss of time, effort and energy. A designated individual, along with his team with the assigned role of each of these persons should be defined to fix the responsibility and help the organization to save from long disruption period.
- Reconstruction may involve multiple sessions of operation to rebuild all folders along with configuration files. There should be proper documentation and process of reconstruction for correct recovery.
Restoration Strategy
The recovery team should have their unique strategy for retrieving the important code and data to bring the operation of the agency back to normalcy.
The strategy can be unique to each organization based on the criticality of the systems they are handling.
The possible strategy for critical systems can be visualized as follows:
- To have a single backup or more than one
- To have multiple back-ups at one place or different places
- To have an online backup or offline backup
- Can the backup is done automatically based on a policy or to have it manually?
- To have an independent restoration team or development team itself can be utilized for the work
Each of these strategies has cost factor associated with it and multiple resources required for multiple back-ups may consume more physical resources or may need an independent team.
Many companies may be affected due to their data and code dependency on the concerned developer agency. For instance, if Amazon AWS goes down its shuts 25 of the internet. Independent Restoration is crucial in such cases.
How to do Recovery Testing
While performing recovery testing following things should be considered.
- We must create a test bed as close to actual conditions of deployment as possible. Changes in interfacing, protocol, firmware, hardware, and software should be as close to the actual condition as possible if not the same condition.
- Through exhaustive testing may be time-consuming and a costly affair, identical configuration, and complete check should be performed.
- If possible, testing should be performed on the hardware we are finally going to restore. This is especially true if we are restoring to a different machine than the one that created the backup.
- Some backup systems expect the hard drive to be exactly the same size as the one the backup was taken from.
- Obsolescence should be managed as drive technology is advancing at a fast pace, and old drive may not be compatible with the new one. One way to handle the problem is to restore to a virtual machine. Virtualization software vendors like VMware Inc. can configure virtual machines to mimic existing hardware, including disk sizes and other configurations.
- Online backup systems are not an exception for testing. Most online backup service providers protect us from being directly exposed to media problems by the way they use fault-tolerant storage systems.
- While online backup systems are extremely reliable, we must test the restore side of the system to make sure there are no problems with the retrieval functionality, security or encryption.
Testing procedure after restoration
Most large corporations have independent auditors to perform recovery test exercises periodically.
The expense of maintaining and testing a comprehensive disaster recovery plan can be substantial, and it may be prohibitive for smaller businesses.
Smaller risks may rely on their data backups and off-site storage plans to save them in the case of a catastrophe.
After folders and files are restored, following checks can be done to assure that files are recovered properly:
- Rename the corrupted document folder
- Count the files in the restored folders and match with it with an existing folder.
- Open a few of the files and make sure they are accessible. Be sure to open them with the application that normally uses them. And make sure you can browse the data, update the data or whatever you normally do.
- It is best to open several files of different types, pictures, mp3s, documents and some large and some small.
- Most operating systems have utilities that you can use to compare files and directories.
Summary
In this tutorial, we have learned a various aspect of recovery testing that helps to understand whether the system or program meets its requirements after a failure.