Apache Flume Tutorial: What is, Architecture & Hadoop Example
What is Apache Flume in Hadoop?
Apache Flume is a reliable and distributed system for collecting, aggregating and moving massive quantities of log data. It has a simple yet flexible architecture based on streaming data flows. Apache Flume is used to collect log data present in log files from web servers and aggregating it into HDFS for analysis.
Flume in Hadoop supports multiple sources like –
- ‘tail’ (which pipes data from a local file and write into HDFS via Flume, similar to Unix command ‘tail’)
- System logs
- Apache log4j (enable Java applications to write events to files in HDFS via Flume).
Flume Architecture
A Flume agent is a JVM process which has 3 components –Flume Source, Flume Channel and Flume Sink– through which events propagate after initiated at an external source.
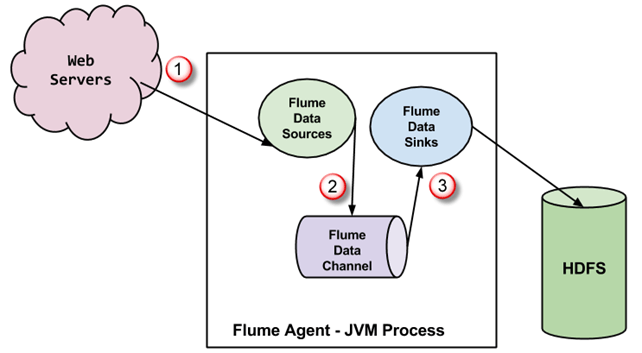
- In the above diagram, the events generated by external source (WebServer) are consumed by Flume Data Source. The external source sends events to Flume source in a format that is recognized by the target source.
- Flume Source receives an event and stores it into one or more channels. The channel acts as a store which keeps the event until it is consumed by the flume sink. This channel may use a local file system in order to store these events.
- Flume sink removes the event from a channel and stores it into an external repository like e.g., HDFS. There could be multiple flume agents, in which case flume sink forwards the event to the flume source of next flume agent in the flow.
Some Important features of FLUME
- Flume has a flexible design based upon streaming data flows. It is fault tolerant and robust with multiple failovers and recovery mechanisms. Flume Big data has different levels of reliability to offer which includes ‘best-effort delivery’ and an ‘end-to-end delivery’. Best-effort delivery does not tolerate any Flume node failure whereas ‘end-to-end delivery’ mode guarantees delivery even in the event of multiple node failures.
- Flume carries data between sources and sinks. This gathering of data can either be scheduled or event-driven. Flume has its own query processing engine which makes it easy to transform each new batch of data before it is moved to the intended sink.
- Possible Flume sinks include HDFS and HBase. Flume Hadoop can also be used to transport event data including but not limited to network traffic data, data generated by social media websites and email messages.
Flume, library and source code setup
Before we start with the actual process, ensure you have Hadoop installed. Change user to ‘hduser’ (id used while Hadoop configuration, you can switch to the userid used during your Hadoop config)

Step 1) Create a new directory with the name ‘FlumeTutorial’
sudo mkdir FlumeTutorial
- Give a read, write and execute permissions
sudo chmod -R 777 FlumeTutorial
- Copy files MyTwitterSource.java and MyTwitterSourceForFlume.java in this directory.
Download Input Files From Here
Check the file permissions of all these files and if ‘read’ permissions are missing then grant the same-

Step 2) Download ‘Apache Flume’ from a site- https://flume.apache.org/download.html
Apache Flume 1.4.0 has been used in this Flume tutorial.

Next Click

Step 3) Copy the downloaded tarball in the directory of your choice and extract contents using the following command
sudo tar -xvf apache-flume-1.4.0-bin.tar.gz

This command will create a new directory named apache-flume-1.4.0-bin and extract files into it. This directory will be referred to as <Installation Directory of Flume> in rest of the article.
Step 4) Flume library setup
Copy twitter4j-core-4.0.1.jar, flume-ng-configuration-1.4.0.jar, flume-ng-core-1.4.0.jar, flume-ng-sdk-1.4.0.jar to
<Installation Directory of Flume>/lib/
It is possible that either or all of the copied JAR will have to execute permission. This may cause an issue with the compilation of code. So, revoke execute permission on such JAR.
In my case, twitter4j-core-4.0.1.jar was having to execute permission. I revoked it as below-
sudo chmod -x twitter4j-core-4.0.1.jar

After this command gives ‘read’ permission on twitter4j-core-4.0.1.jar to all.
sudo chmod +rrr /usr/local/apache-flume-1.4.0-bin/lib/twitter4j-core-4.0.1.jar
Please note that I have downloaded-
– twitter4j-core-4.0.1.jar from https://mvnrepository.com/artifact/org.twitter4j/twitter4j-core
– All flame JARs i.e., flume-ng-*-1.4.0.jar from http://mvnrepository.com/artifact/org.apache.flume
Load data from Twitter using Flume
Step 1) Go to the directory containing source code files in it.
Step 2) Set CLASSPATH to contain <Flume Installation Dir>/lib/* and ~/FlumeTutorial/flume/mytwittersource/*
export CLASSPATH="/usr/local/apache-flume-1.4.0-bin/lib/*:~/FlumeTutorial/flume/mytwittersource/*"

Step 3) Compile source code using the command-
javac -d . MyTwitterSourceForFlume.java MyTwitterSource.java

Step 4)Create a jar
First, create Manifest.txt file using a text editor of your choice and add below line in it-
Main-Class: flume.mytwittersource.MyTwitterSourceForFlume
.. here flume.mytwittersource.MyTwitterSourceForFlume is the name of the main class. Please note that you have to hit enter key at end of this line.

Now, create JAR ‘MyTwitterSourceForFlume.jar’ as-
jar cfm MyTwitterSourceForFlume.jar Manifest.txt flume/mytwittersource/*.class

Step 5) Copy this jar to <Flume Installation Directory>/lib/
sudo cp MyTwitterSourceForFlume.jar <Flume Installation Directory>/lib/

Step 6) Go to the configuration directory of Flume, <Flume Installation Directory>/conf
If flume.conf does not exist, then copy flume-conf.properties.template and rename it to flume.conf
sudo cp flume-conf.properties.template flume.conf

If flume-env.sh does not exist, then copy flume-env.sh.template and rename it to flume-env.sh
sudo cp flume-env.sh.template flume-env.sh

Creating a Twitter Application
Step 1) Create a Twitter application by signing in to https://developer.twitter.com/


Step 2) Go to ‘My applications’ (This option gets dropped down when ‘Egg’ button at the top right corner is clicked)

Step 3) Create a new application by clicking ‘Create New App’
Step 4) Fill up application details by specifying the name of application, description, and website. You may refer to the notes given underneath each input box.
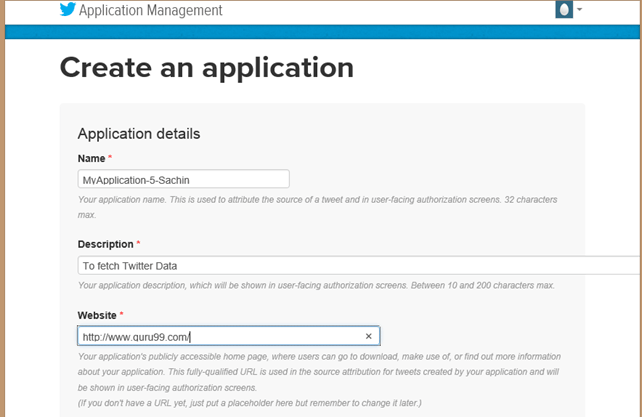
Step 5) Scroll down the page and accept terms by marking ‘Yes, I agree’ and click on button‘Create your Twitter application’

Step 6) On the window of a newly created application, go to the tab, ‘API Keys’ scroll down the page and click button ‘Create my access token’


Step 7) Refresh the page.
Step 8) Click on ‘Test OAuth’. This will display ‘OAuth’ settings of the application.

Step 9) Modify ‘flume.conf’ using these OAuth settings. Steps to modify ‘flume.conf’ are given below.

We need to copy Consumer key, Consumer secret, Access token and Access token secret to updating ‘flume.conf’.
Note: These values belong to the user and hence are confidential, so should not be shared.
Modify ‘flume.conf’ File
Step 1) Open ‘flume.conf’ in write mode and set values for below parameters-
sudo gedit flume.conf
Copy below contents-
MyTwitAgent.sources = Twitter MyTwitAgent.channels = MemChannel MyTwitAgent.sinks = HDFS MyTwitAgent.sources.Twitter.type = flume.mytwittersource.MyTwitterSourceForFlume MyTwitAgent.sources.Twitter.channels = MemChannel MyTwitAgent.sources.Twitter.consumerKey = <Copy consumer key value from Twitter App> MyTwitAgent.sources.Twitter.consumerSecret = <Copy consumer secret value from Twitter App> MyTwitAgent.sources.Twitter.accessToken = <Copy access token value from Twitter App> MyTwitAgent.sources.Twitter.accessTokenSecret = <Copy access token secret value from Twitter App> MyTwitAgent.sources.Twitter.keywords = guru99 MyTwitAgent.sinks.HDFS.channel = MemChannel MyTwitAgent.sinks.HDFS.type = hdfs MyTwitAgent.sinks.HDFS.hdfs.path = hdfs://localhost:54310/user/hduser/flume/tweets/ MyTwitAgent.sinks.HDFS.hdfs.fileType = DataStream MyTwitAgent.sinks.HDFS.hdfs.writeFormat = Text MyTwitAgent.sinks.HDFS.hdfs.batchSize = 1000 MyTwitAgent.sinks.HDFS.hdfs.rollSize = 0 MyTwitAgent.sinks.HDFS.hdfs.rollCount = 10000 MyTwitAgent.channels.MemChannel.type = memory MyTwitAgent.channels.MemChannel.capacity = 10000 MyTwitAgent.channels.MemChannel.transactionCapacity = 1000

Step 2) Also, set TwitterAgent.sinks.HDFS.hdfs.path as below,
TwitterAgent.sinks.HDFS.hdfs.path = hdfs://<Host Name>:<Port Number>/<HDFS Home Directory>/flume/tweets/

To know <Host Name>, <Port Number> and <HDFS Home Directory> , see value of parameter ‘fs.defaultFS’ set in $HADOOP_HOME/etc/hadoop/core-site.xml

Step 3) In order to flush the data to HDFS, as an when it comes, delete below entry if it exists,
TwitterAgent.sinks.HDFS.hdfs.rollInterval = 600
Example: Streaming Twitter Data using Flume
Step 1) Open ‘flume-env.sh’ in write mode and set values for below parameters,
JAVA_HOME=<Installation directory of Java>
FLUME_CLASSPATH="<Flume Installation Directory>/lib/MyTwitterSourceForFlume.jar"

Step 2) Start Hadoop
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
Step 3) Two of the JAR files from the Flume tarball are not compatible with Hadoop 2.2.0. So, we will need to follow below steps in this Apache Flume example to make Flume compatible with Hadoop 2.2.0.
a. Move protobuf-java-2.4.1.jar out of ‘<Flume Installation Directory>/lib’.
Go to ‘<Flume Installation Directory>/lib’
cd <Flume Installation Directory>/lib
sudo mv protobuf-java-2.4.1.jar ~/

b. Find for JAR file ‘guava’ as below
find . -name "guava*"

Move guava-10.0.1.jar out of ‘<Flume Installation Directory>/lib’.
sudo mv guava-10.0.1.jar ~/

c. Download guava-17.0.jar from http://mvnrepository.com/artifact/com.google.guava/guava/17.0

Now, copy this downloaded jar file to ‘<Flume Installation Directory>/lib’
Step 4) Go to ‘<Flume Installation Directory>/bin’ and start Flume as-
./flume-ng agent -n MyTwitAgent -c conf -f <Flume Installation Directory>/conf/flume.conf

Command prompt window where flume is fetching Tweets-

From command window message we can see that the output is written to /user/hduser/flume/tweets/ directory.
Now, open this directory using a web browser.
Step 5) To see the result of data load, using a browser open http://localhost:50070/ and browse the file system, then go to the directory where data has been loaded, that is-
<HDFS Home Directory>/flume/tweets/
