Functions in R Programming with Example
⚡ Smart Summary
Functions in R package a set of instructions under one name, so a repeated task runs from a single call. Built-in maths and statistics helpers, user-defined functions, environment scoping, and conditional arguments are covered here with worked examples.

What is a Function in R?
A function, in a programming environment, is a set of instructions. A programmer builds a function to avoid repeating the same task, or reduce complexity.
A function should be
- written to carry out a specified task
- may or may not include arguments
- contain a body
- may or may not return one or more values.
A general approach to a function is to use the argument part as inputs, feed the body part and finally return an output. The Syntax of a function is the following:
function (arglist) { #Function body }
R important built-in functions
There are a lot of built-in functions in R. R matches your input parameters with its function arguments, either by value or by position, then executes the function body. Function arguments can have default values: if you do not specify these arguments, R will take the default value.
Note:
It is possible to see the source code of a function by running the name of the function itself in the console.
Typing a function name without brackets prints its source, as the console below shows.

We will see three groups of function in action
- General function
- Maths function
- Statistical function
General functions
We are already familiar with general functions like cbind(), rbind(), range(), sort(), and order(). Each of these functions has a specific task, takes arguments to return an output. Following are important functions one must know-
diff() function
If you work on time series, you need to stationary the series by taking their lag values. A stationary process allows constant mean, variance and autocorrelation over time. This mainly improves the prediction of a time series. This can be done with the diff() function. We can build a random time-series data with a trend and then use the function diff() to stationary the series. The diff() function accepts one argument, a vector, and return suitable lagged and iterated difference.
Note: We often need to create random data, but for learning and comparison we want the numbers to be identical across machines. To ensure we all generate the same data, we use the set.seed() function with arbitrary values of 123. set.seed() fixes the starting point of the pseudorandom number generator, so every machine produces the same sequence. Without set.seed(), each run returns a different sequence.
set.seed(123) ## Create the data x = rnorm(1000) ts <- cumsum(x) ## Stationary the serie diff_ts <- diff(ts) par(mfrow=c(1,2)) ## Plot the series plot(ts, type='l') plot(diff(ts), type='l')
The two panels below place the original cumulative series next to the differenced series, which now fluctuates around a constant mean.

length() function
In many cases, we want to know the length of a vector for computation or to be used in a for loop. The length() function counts the number of rows in vector x. The following codes import the cars dataset and return the number of rows.
Note: length() returns the number of elements in a vector. If the function is passed into a matrix or a data frame, the number of columns is returned.
dt <- cars
## number columns
length(dt)
Output:
## [1] 1
## number rows
length(dt[,1])
Output:
## [1] 50
Math functions
Beyond the general helpers, R has an array of mathematical functions that operate element by element on a vector.
| Operator | Description |
|---|---|
| abs(x) | Takes the absolute value of x |
| log(x,base=y) | Takes the logarithm of x with base y; if base is not specified, returns the natural logarithm |
| exp(x) | Returns the exponential of x |
| sqrt(x) | Returns the square root of x |
| factorial(x) | Returns the factorial of x (x!) |
# sequence of number from 44 to 55 both including incremented by 1 x_vector <- seq(45,55, by = 1) #logarithm log(x_vector)
Output:
## [1] 3.806662 3.828641 3.850148 3.871201 3.891820 3.912023 3.931826 ## [8] 3.951244 3.970292 3.988984 4.007333
#exponential
exp(x_vector)
#squared root
sqrt(x_vector)
Output:
## [1] 6.708204 6.782330 6.855655 6.928203 7.000000 7.071068 7.141428 ## [8] 7.211103 7.280110 7.348469 7.416198
#factorial
factorial(x_vector)
Output:
## [1] 1.196222e+56 5.502622e+57 2.586232e+59 1.241392e+61 6.082819e+62 ## [6] 3.041409e+64 1.551119e+66 8.065818e+67 4.274883e+69 2.308437e+71 ## [11] 1.269640e+73
Statistical functions
Where the maths functions transform values, the statistical functions summarise them. R standard installation contains wide range of statistical functions. In this tutorial, we will briefly look at the most important ones.
Basic statistic functions
| Operator | Description |
|---|---|
| mean(x) | Mean of x |
| median(x) | Median of x |
| var(x) | Variance of x |
| sd(x) | Standard deviation of x |
| scale(x) | Standard scores (z-scores) of x |
| quantile(x) | The quartiles of x |
| summary(x) | Summary of x: mean, min, max etc.. |
speed <- dt$speed
speed
# Mean speed of cars dataset
mean(speed)
Output:
## [1] 15.4
# Median speed of cars dataset
median(speed)
Output:
## [1] 15
# Variance speed of cars dataset
var(speed)
Output:
## [1] 27.95918
# Standard deviation speed of cars dataset
sd(speed)
Output:
## [1] 5.287644
# Standardize vector speed of cars dataset
head(scale(speed), 5)
Output:
## [,1] ## [1,] -2.155969 ## [2,] -2.155969 ## [3,] -1.588609 ## [4,] -1.588609 ## [5,] -1.399489
# Quantile speed of cars dataset
quantile(speed)
Output:
## 0% 25% 50% 75% 100% ## 4 12 15 19 25
# Summary speed of cars dataset
summary(speed)
Output:
## Min. 1st Qu. Median Mean 3rd Qu. Max. ## 4.0 12.0 15.0 15.4 19.0 25.0
Up to this point, we have learned a lot of R built-in functions.
Note: Be careful with the class of the argument, i.e. numeric, Boolean or string. For instance, if we need to pass a string value, we need to enclose the string in quotation mark: “ABC” .
Write function in R
On some occasions, we need to write our own function because we have to accomplish a particular task and no ready-made function exists. A user-defined function involves a name, arguments and a body.
function.name <- function(arguments) { computations on the arguments some other code }
Note: A good practice is to name a user-defined function different from a built-in function. It avoids confusion.
One argument function
In the next snippet, we define a simple square function. The function accepts a value and returns the square of the value.
square_function<- function(n) { # compute the square of integer `n` n^2 } # calling the function and passing value 4 square_function(4)
Code Explanation
- The function is named square_function; it can be called whatever we want.
- It receives an argument “n”. We didn’t specify the type of variable so that the user can pass an integer, a vector or a matrix
- The function takes the input “n” and returns the square of the input. When you are done using the function, we can remove it with the rm() function.
# after you create the function
rm(square_function) square_function
On the console, we can see an error message :Error: object ‘square_function’ not found telling the function does not exist.
Environment Scoping
In R, the environment is a collection of objects like functions, variables, data frame, etc.
R opens an environment each time RStudio is started.
The top-level environment available is the global environment, called R_GlobalEnv. And we have the local environment.
We can list the content of the current environment.
ls(environment())
Output
## [1] "diff_ts" "dt" "speed" "square_function" ## [5] "ts" "x" "x_vector"
You can see all the variables and function created in the R_GlobalEnv.
The above list will vary for you based on the historic code you execute in RStudio.
Note that n, the argument of the square_function function is not in this global environment.
A new environment is created for each function. In the above example, the function square_function() creates a new environment inside the global environment.
To clarify the difference between global and local environment, let’s study the following example
These function takes a value x as an argument and add it to y define outside and inside the function

The function f returns the output 15. This is because y is defined in the global environment. Any variable defined in the global environment can be used locally. The variable y has the value of 10 during all function calls and is accessible at any time.
Let’s see what happens if the variable y is defined inside the function.
We need to drop `y` prior to run this code using rm r
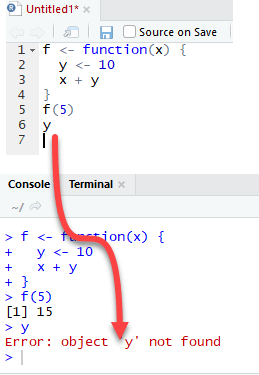
The output is also 15 when we call f(5) but returns an error when we try to print the value y. The variable y is not in the global environment.
Finally, R uses the most recent variable definition to pass inside the body of a function. Let’s consider the following example:

R ignores the y values defined outside the function because we explicitly created a y variable inside the body of the function.
Multi arguments function
We can write a function with more than one argument. Consider the function called “times”. It is a straightforward function multiplying two variables.
times <- function(x,y) {
x*y
}
times(2,4)
Output:
## [1] 8
When should we write function?
Data scientists need to do many repetitive tasks. Most of the time, we copy and paste chunks of code repetitively. For example, normalization of a variable is highly recommended before we run a machine learning algorithm. The formula to normalize a variable is:

We already know how to use the min() and max() function in R. We use the tibble library to create the data frame. Tibble is so far the most convenient function to create a data set from scratch.
library(tibble) # Create a data frame data_frame <- tibble( c1 = rnorm(50, 5, 1.5), c2 = rnorm(50, 5, 1.5), c3 = rnorm(50, 5, 1.5), )
We will proceed in two steps to compute the function described above. In the first step, we will create a variable called c1_norm which is the rescaling of c1. In step two, we just copy and paste the code of c1_norm and change with c2 and c3.
Detail of the function with the column c1:
Nominator: : data_frame$c1 -min(data_frame$c1))
Denominator: max(data_frame$c1)-min(data_frame$c1))
Therefore, we can divide them to get the normalized value of column c1:
(data_frame$c1 -min(data_frame$c1))/(max(data_frame$c1)-min(data_frame$c1))
We can create c1_norm, c2_norm and c3_norm:
Create c1_norm: rescaling of c1
data_frame$c1_norm <- (data_frame$c1 -min(data_frame$c1))/(max(data_frame$c1)-min(data_frame$c1))
# show the first five values
head(data_frame$c1_norm, 5)
Output:
## [1] 0.3400113 0.4198788 0.8524394 0.4925860 0.5067991
It works. We can copy and paste
data_frame$c1_norm <- (data_frame$c1 -min(data_frame$c1))/(max(data_frame$c1)-min(data_frame$c1))
then change c1_norm to c2_norm and c1 to c2. We do the same to create c3_norm
data_frame$c2_norm <- (data_frame$c2 - min(data_frame$c2))/(max(data_frame$c2)-min(data_frame$c2)) data_frame$c3_norm <- (data_frame$c3 - min(data_frame$c3))/(max(data_frame$c3)-min(data_frame$c3))
We perfectly rescaled the variables c1, c2 and c3.
However, this method is prone to mistakes. We could copy and forget to change the column name after pasting. Therefore, a good practice is to write a function each time you need to paste same code more than twice. We can rearrange the code into a formula and call it whenever it is needed. To write our own function, we need to give:
- Name: normalize.
- the number of arguments: We only need one argument, which is the column we use in our computation.
- The body: this is simply the formula we want to return.
We will proceed step by step to create the function normalize.
Step 1) We create the nominator, which is x – min(x). In R, we can store the nominator in a variable like this:
nominator <- x-min(x)
Step 2) We compute the denominator: max(x) – min(x). We can replicate the idea of step 1 and store the computation in a variable:
denominator <- max(x)-min(x)
Step 3) We perform the division between the nominator and denominator.
normalize <- nominator/denominator
Step 4) To return value to calling function we need to pass normalize inside return() to get the output of the function.
return(normalize)
Step 5) We are ready to use the function by wrapping everything inside the bracket.
normalize <- function(x){ # step 1: create the nominator nominator <- x-min(x) # step 2: create the denominator denominator <- max(x)-min(x) # step 3: divide nominator by denominator normalize <- nominator/denominator # return the value return(normalize) }
Let’s test our function with the variable c1:
normalize(data_frame$c1)
It works perfectly. We created our first function.
A function is a more comprehensive way to perform a repetitive task. We can use the normalize formula over different columns, like below:
data_frame$c1_norm_function <- normalize (data_frame$c1) data_frame$c2_norm_function <- normalize (data_frame$c2) data_frame$c3_norm_function <- normalize (data_frame$c3)
Even though the example is simple, we can infer the power of a formula. The above code is easier to read and avoids the mistakes that come with pasting code.
Functions with condition
The normalize() function always does the same thing. Sometimes, we need to include conditions into a function to allow the code to return different outputs.
In Machine Learning tasks, we need to split the dataset between a train set and a test set. The train set allows the algorithm to learn from the data. In order to test the performance of our model, we can use the test set to return the performance measure. R does not have a function to create two datasets. We can write our own function to do that. Our function takes two arguments and is called split_data(). The idea behind is simple, we multiply the length of dataset (i.e. number of observations) with 0.8. For instance, if we want to split the dataset 80/20, and our dataset contains 100 rows, then our function will multiply 0.8*100 = 80. 80 rows will be selected to become our training data.
We will use the airquality dataset to test our user-defined function. The airquality dataset has 153 rows. We can see it with the code below:
nrow(airquality)
Output:
## [1] 153
We will proceed as follow:
split_data <- function(df, train = TRUE) Arguments: -df: Define the dataset -train: Specify if the function returns the train set or test set. By default, set to TRUE
Our function has two arguments. The arguments train is a Boolean parameter. If it is set to TRUE, our function creates the train dataset, otherwise, it creates the test dataset.
We can proceed as we did with the normalize() function. We write the code as if it was only one-time code and then wrap everything with the condition into the body to create the function.
Step 1:
We need to compute the length of the dataset. This is done with the function nrow(). Nrow returns the total number of rows in the dataset. We call the variable length.
length<- nrow(airquality) length
Output:
## [1] 153
Step 2:
We multiply the length by 0.8. It will return the number of rows to select. It should be 153*0.8 = 122.4
total_row <- length*0.8 total_row
Output:
## [1] 122.4
We want to select 122 rows among the 153 rows in the airquality dataset. We create a list containing values from 1 to total_row. We store the result in the variable called split
split <- 1:total_row split[1:5]
Output:
## [1] 1 2 3 4 5
split chooses the first 122 rows from the dataset. For instance, we can see that our variable split gathers the values 1, 2, 3, 4, 5 and so on. These values will be the index when we will select the rows to return.
Step 3:
We need to select the rows in the airquality dataset based on the values stored in the split variable. This is done like this:
train_df <- airquality[split, ] head(train_df)
Output:
##[1] Ozone Solar.R Wind Temp Month Day ##[2] 51 13 137 10.3 76 6 20 ##[3] 15 18 65 13.2 58 5 15 ##[4] 64 32 236 9.2 81 7 3 ##[5] 27 NA NA 8.0 57 5 27 ##[6] 58 NA 47 10.3 73 6 27 ##[7] 44 23 148 8.0 82 6 13
Step 4:
We can create the test dataset by using the remaining rows, 123:153. This is done by using – in front of split.
test_df <- airquality[-split, ] head(test_df)
Output:
##[1] Ozone Solar.R Wind Temp Month Day ##[2] 123 85 188 6.3 94 8 31 ##[3] 124 96 167 6.9 91 9 1 ##[4] 125 78 197 5.1 92 9 2 ##[5] 126 73 183 2.8 93 9 3 ##[6] 127 91 189 4.6 93 9 4 ##[7] 128 47 95 7.4 87 9 5
Step 5:
We can create the condition inside the body of the function. Remember, we have an argument train that is a Boolean set to TRUE by default to return the train set. To create the condition, we use the if syntax:
if (train ==TRUE){ train_df <- airquality[split, ] return(train) } else { test_df <- airquality[-split, ] return(test) }
This is it, we can write the function. We only need to change airquality to df because we want to try our function to any data frame, not only airquality:
split_data <- function(df, train = TRUE){ length<- nrow(df) total_row <- length *0.8 split <- 1:total_row if (train ==TRUE){ train_df <- df[split, ] return(train_df) } else { test_df <- df[-split, ] return(test_df) } }
Let’s try our function on the airquality dataset. We should have one train set with 122 rows and a test set with 31 rows.
train <- split_data(airquality, train = TRUE)
dim(train)
Output:
## [1] 122 6
test <- split_data(airquality, train = FALSE)
dim(test)
Output:
## [1] 31 6