Artificial Neural Network Tutorial with TensorFlow ANN Examples
What is Artificial Neural Network?
An Artificial Neural Network (ANN) is a computer system inspired by biological neural networks for creating artificial brains based on the collection of connected units called artificial neurons. It is designed to analyse and process information as humans. Artificial Neural Network has self-learning capabilities to produce better results as more data is available.

An Artificial Neural Network (ANN) is composed of four principal objects:
- Layers: all the learning occurs in the layers. There are 3 layers 1) Input 2) Hidden and 3) Output
- Feature and label: Input data to the network (features) and output from the network (labels)
- Loss function: Metric used to estimate the performance of the learning phase
- Optimizer: Improve the learning by updating the knowledge in the network
A neural network will take the input data and push them into an ensemble of layers. The network needs to evaluate its performance with a loss function. The loss function gives to the network an idea of the path it needs to take before it masters the knowledge. The network needs to improve its knowledge with the help of an optimizer.
If you take a look at the figure above, you will understand the underlying mechanism.
The program takes some input values and pushes them into two fully connected layers. Imagine you have a math problem, the first thing you do is to read the corresponding chapter to solve the problem. You apply your new knowledge to solve the problem. There is a high chance you will not score very well. It is the same for a network. The first time it sees the data and makes a prediction, it will not match perfectly with the actual data.
To improve its knowledge, the network uses an optimizer. In our analogy, an optimizer can be thought of as rereading the chapter. You gain new insights/lesson by reading again. Similarly, the network uses the optimizer, updates its knowledge, and tests its new knowledge to check how much it still needs to learn. The program will repeat this step until it makes the lowest error possible.
In our math problem analogy, it means you read the textbook chapter many times until you thoroughly understand the course content. Even after reading multiple times, if you keep making an error, it means you reached the knowledge capacity with the current material. You need to use different textbook or test different method to improve your score. For a neural network, it is the same process. If the error is far from 100%, but the curve is flat, it means with the current architecture; it cannot learn anything else. The network has to be better optimized to improve the knowledge.
Neural Network Architecture
The Artificial Neural Network Architecture consists of following components:
- Layers
- Activation function
- Loss function
- Optimizer
Layers
A layer is where all the learning takes place. Inside a layer, there are an infinite amount of weights (neurons). A typical neural network is often processed by densely connected layers (also called fully connected layers). It means all the inputs are connected to the output.
A typical neural network takes a vector of input and a scalar that contains the labels. The most comfortable set up is a binary classification with only two classes: 0 and 1.
The network takes an input, sends it to all connected nodes and computes the signal with an activation function.
The figure above plots this idea. The first layer is the input values for the second layer, called the hidden layer, receives the weighted input from the previous layer
- The first node is the input values
- The neuron is decomposed into the input part and the activation function. The left part receives all the input from the previous layer. The right part is the sum of the input passes into an activation function.
- Output value computed from the hidden layers and used to make a prediction. For classification, it is equal to the number of class. For regression, only one value is predicted.
Activation function
The activation function of a node defines the output given a set of inputs. You need an activation function to allow the network to learn non-linear pattern. A common activation function is a Relu, Rectified linear unit. The function gives a zero for all negative values.
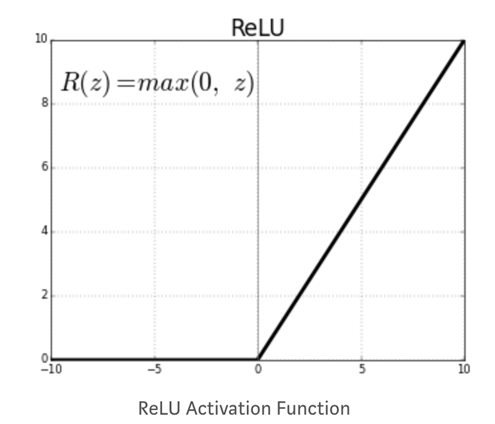
The other activation functions are:
- Piecewise Linear
- Sigmoid
- Tanh
- Leaky Relu
The critical decision to make when building a neural network is:
- How many layers in the neural network
- How many hidden units for each layer
Neural network with lots of layers and hidden units can learn a complex representation of the data, but it makes the network’s computation very expensive.
Loss function
After you have defined the hidden layers and the activation function, you need to specify the loss function and the optimizer.
For binary classification, it is common practice to use a binary cross entropy loss function. In the linear regression, you use the mean square error.
The loss function is an important metric to estimate the performance of the optimizer. During the training, this metric will be minimized. You need to select this quantity carefully depending on the type of problem you are dealing with.
Optimizer
The loss function is a measure of the model’s performance. The optimizer will help improve the weights of the network in order to decrease the loss. There are different optimizers available, but the most common one is the Stochastic Gradient Descent.
The conventional optimizers are:
- Momentum optimization,
- Nesterov Accelerated Gradient,
- AdaGrad,
- Adam optimization
Limitations of Neural Network
Following are the limitations of Neural Network:
Overfitting
A common problem with the complex neural net is the difficulties in generalizing unseen data. A neural network with lots of weights can identify specific details in the train set very well but often leads to overfitting. If the data are unbalanced within groups (i.e., not enough data available in some groups), the network will learn very well during the training but will not have the ability to generalize such pattern to never-seen-before data.
There is a trade-off in machine learning between optimization and generalization.
Optimize a model requires to find the best parameters that minimize the loss of the training set.
Generalization, however, tells how the model behaves for unseen data.
To prevent the model from capturing specific details or unwanted patterns of the training data, you can use different techniques. The best method is to have a balanced dataset with sufficient amount of data. The art of reducing overfitting is called regularization. Let’s review some conventional techniques.
Network size
A neural network with too many layers and hidden units are known to be highly sophisticated. A straightforward way to reduce the complexity of the model is to reduce its size. There is no best practice to define the number of layers. You need to start with a small amount of layer and increases its size until you find the model overfit.
Weight Regularization
A standard technique to prevent overfitting is to add constraints to the weights of the network. The constraint forces the size of the network to take only small values. The constraint is added to the loss function of the error. There are two kinds of regularization:
L1: Lasso: Cost is proportional to the absolute value of the weight coefficients
L2: Ridge: Cost is proportional to the square of the value of the weight coefficients
Dropout
Dropout is an odd but useful technique. A network with dropout means that some weights will be randomly set to zero. Imagine you have an array of weights [0.1, 1.7, 0.7, -0.9]. If the neural network has a dropout, it will become [0.1, 0, 0, -0.9] with randomly distributed 0. The parameter that controls the dropout is the dropout rate. The rate defines how many weights to be set to zeroes. Having a rate between 0.2 and 0.5 is common.
Example of Neural Network in TensorFlow
Let’s see an Artificial Neural Network example in action on how a neural network works for a typical classification problem. There are two inputs, x1 and x2 with a random value. The output is a binary class. The objective is to classify the label based on the two features. To carry out this task, the neural network architecture is defined as following:
- Two hidden layers
- First layer has four fully connected neurons
- Second layer has two fully connected neurons
- The activation function is a Relu
- Add an L2 Regularization with a learning rate of 0.003

The network will optimize the weight during 180 epochs with a batch size of 10. In the ANN example video below, you can see how the weights evolve over and how the network improves the classification mapping.
First of all, the network assigns random values to all the weights.
- With the random weights, i.e., without optimization, the output loss is 0.453. The picture below represents the network with different colors.
- In general, the orange color represents negative values while the blue colors show the positive values.
- The data points have the same representation; the blue ones are the positive labels and the orange one the negative labels.

Inside the second hidden layer, the lines are colored following the sign of the weights. The orange lines assign negative weights and the blue one a positive weights
As you can see, in the output mapping, the network is making quite a lot of mistake. Let’s see how the network behaves after optimization.
The picture of ANN example below depicts the results of the optimized network. First of all, you notice the network has successfully learned how to classify the data point. You can see from the picture before; the initial weight was -0.43 while after optimization it results in a weight of -0.95.

The idea can be generalized for networks with more hidden layers and neurons. You can play around in the link.
How to Train a Neural Network with TensorFlow
Here is the step by step process on how to train a neural network with TensorFlow ANN using the API’s estimator DNNClassifier.
We will use the MNIST dataset to train your first neural network. Training a neural network with TensorFlow is not very complicated. The preprocessing step looks precisely the same as in the previous tutorials. You will proceed as follow:
- Step 1: Import the data
- Step 2: Transform the data
- Step 3: Construct the tensor
- Step 4: Build the model
- Step 5: Train and evaluate the model
- Step 6: Improve the model
Step 1) Import the data
First of all, you need to import the necessary library. You can import the MNIST dataset using scikit learn as shown in the TensorFlow Neural Network example below.
The MNIST dataset is the commonly used dataset to test new techniques or algorithms. This dataset is a collection of 28×28 pixel image with a handwritten digit from 0 to 9. Currently, the lowest error on the test is 0.27 percent with a committee of 7 convolutional neural networks.
import numpy as np import tensorflow as tf np.random.seed(1337)
You can download scikit learn temporarily at this address. Copy and paste the dataset in a convenient folder. To import the data to python, you can use fetch_mldata from scikit learn. Paste the file path inside fetch_mldata to fetch the data.
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata(' /Users/Thomas/Dropbox/Learning/Upwork/tuto_TF/data/mldata/MNIST original')
print(mnist.data.shape)
print(mnist.target.shape)
After that, you import the data and get the shape of both datasets.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(mnist.data, mnist.target, test_size=0.2, random_state=42) y_train = y_train.astype(int) y_test = y_test.astype(int) batch_size =len(X_train) print(X_train.shape, y_train.shape,y_test.shape )
Step 2) Transform the data
In the previous tutorial, you learnt that you need to transform the data to limit the effect of outliers. In this Neural Networks tutorial, you will transform the data using the min-max scaler. The formula is:
(X-min_x)/(max_x - min_x)
Scikit learns has already a function for that: MinMaxScaler()
## resclae from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() # Train X_train_scaled = scaler.fit_transform(X_train.astype(np.float64)) # test X_test_scaled = scaler.fit_transform(X_test.astype(np.float64))
Step 3) Construct the tensor
You are now familiar with the way to create tensor in Tensorflow. You can convert the train set to a numeric column.
feature_columns = [tf.feature_column.numeric_column('x', shape=X_train_scaled.shape[1:])]
Step 4) Build the model
The architecture of the neural network contains 2 hidden layers with 300 units for the first layer and 100 units for the second one. We use these value based on our own experience. You can tune theses values and see how it affects the accuracy of the network.
To build the model, you use the estimator DNNClassifier. You can add the number of layers to the feature_columns arguments. You need to set the number of classes to 10 as there are ten classes in the training set. You are already familiar with the syntax of the estimator object. The arguments features columns, number of classes and model_dir are precisely the same as in the previous tutorial. The new argument hidden_unit controls for the number of layers and how many nodes to connect to the neural network. In the code below, there are two hidden layers with a first one connecting 300 nodes and the second one with 100 nodes.
To build the estimator, use tf.estimator.DNNClassifier with the following parameters:
- feature_columns: Define the columns to use in the network
- hidden_units: Define the number of hidden neurons
- n_classes: Define the number of classes to predict
- model_dir: Define the path of TensorBoard
estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
hidden_units=[300, 100],
n_classes=10,
model_dir = '/train/DNN')
Step 5) Train and evaluate the model
You can use the numpy method to train the model and evaluate it
# Train the estimator
train_input = tf.estimator.inputs.numpy_input_fn(
x={"x": X_train_scaled},
y=y_train,
batch_size=50,
shuffle=False,
num_epochs=None)
estimator.train(input_fn = train_input,steps=1000)
eval_input = tf.estimator.inputs.numpy_input_fn(
x={"x": X_test_scaled},
y=y_test,
shuffle=False,
batch_size=X_test_scaled.shape[0],
num_epochs=1)
estimator.evaluate(eval_input,steps=None)
Output:
{'accuracy': 0.9637143,
'average_loss': 0.12014342,
'loss': 1682.0079,
'global_step': 1000}
The current architecture leads to an accuracy on the the evaluation set of 96 percent.
Step 6) Improve the model
You can try to improve the model by adding regularization parameters.
We will use an Adam optimizer with a dropout rate of 0.3, L1 of X and L2 of y. In TensorFlow Neural Network, you can control the optimizer using the object train following by the name of the optimizer. TensorFlow is a built-in API for the Proximal AdaGrad optimizer.
To add regularization to the deep neural network, you can use tf.train.ProximalAdagradOptimizer with the following parameter
- Learning rate: learning_rate
- L1 regularization: l1_regularization_strength
- L2 regularization: l2_regularization_strength
estimator_imp = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
hidden_units=[300, 100],
dropout=0.3,
n_classes = 10,
optimizer=tf.train.ProximalAdagradOptimizer(
learning_rate=0.01,
l1_regularization_strength=0.01,
l2_regularization_strength=0.01
),
model_dir = '/train/DNN1')
estimator_imp.train(input_fn = train_input,steps=1000)
estimator_imp.evaluate(eval_input,steps=None)
Output:
{'accuracy': 0.95057142,
'average_loss': 0.17318928,
'loss': 2424.6499,
'global_step': 2000}
The values chosen to reduce the over fitting did not improve the model accuracy. Your first model had an accuracy of 96% while the model with L2 regularizer has an accuracy of 95%. You can try with different values and see how it impacts the accuracy.
Summary
In this tutorial, you learn how to build a neural network. A neural network requires:
- Number of hidden layers
- Number of fully connected node
- Activation function
- Optimizer
- Number of classes
In TensorFlow ANN, you can train a neural network for classification problem with:
- tf.estimator.DNNClassifier
The estimator requires to specify:
- feature_columns=feature_columns,
- hidden_units=[300, 100]
- n_classes=10
- model_dir
You can improve the model by using different optimizers. In this tutorial, you learned how to use Adam Grad optimizer with a learning rate and add a control to prevent overfitting.