SAP HANA Architecture: Database Overview
⚡ Smart Summary
SAP HANA Architecture, Landscape, and Sizing form the foundation of an in-memory data platform built on SUSE Linux and C++. This article explains the index server, storage engines, row and column stores, delta merge, and hardware sizing methods.

What is SAP HANA Database?
SAP HANA is a main-memory-centric data management platform. The database runs on SUSE Linux Enterprise Server (SLES) and Red Hat Enterprise Linux (RHEL) and is written in C++. It can scale-out across multiple machines for very large workloads.
Key advantages of SAP HANA:
- Extremely fast query performance because all data is loaded in memory, removing slow disk I/O from the critical path.
- Mixed OLAP (Online Analytical Processing) and OLTP (Online Transaction Processing) on the same database, simplifying the data landscape.
SAP HANA Database is built from a set of in-memory processing engines. The Calculation Engine is the main one and interacts with other engines such as the Relational Engine (Row and Column store), the OLAP Engine, the Text Engine, and the Graph Engine. A relational table lives either in the row store or the column store, and additional engines handle text and graph data while memory is available.
SAP HANA Architecture
Data in the column store is compressed using techniques such as dictionary encoding, run-length encoding, sparse encoding, cluster encoding, and indirect encoding. When the main memory limit is reached, database objects that are not in use (tables, views, etc.) are unloaded to disk automatically and reloaded when requested again.
Administrators can also load or unload an individual table manually by right-clicking the table in SAP HANA Studio and choosing Unload or Load.
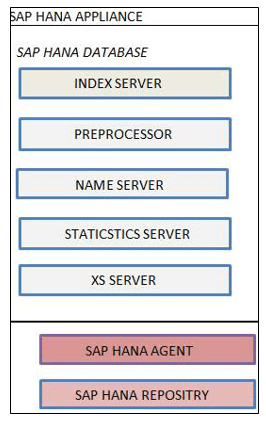
SAP HANA Server consists of:
- Index Server
- Preprocessor Server
- Name Server
- Statistics Server
- XS Engine
1. SAP HANA Index Server
The Index Server is the main SAP HANA database component:
- It is the heart of the SAP HANA database engine.
- It contains the actual data stores and the engines that process the data.
- It executes incoming SQL and MDX statements.
The Index Server architecture is shown below.

SAP HANA Index Server overview
- Session and Transaction Manager: The Session component manages connections and sessions for the database. The Transaction Manager coordinates and controls all transactions.
- SQL and MDX Processor: The SQL Processor sends queries to the appropriate engine (SQL / SQL Script / R / Calc Engine). The MDX Processor handles multidimensional queries (for example, against an Analytic View).
- SQL / SQL Script / R / Calc Engine: Executes SQL, SQL Script, R, and calculation models against the data.
- Repository: Maintains versioning for SAP HANA metadata objects such as Attribute Views, Analytic Views, and Stored Procedures.
- Persistence Layer: Provides the built-in disaster-recovery capability by writing savepoints and logs to the data volume on disk.
2. Preprocessor Server
The Preprocessor Server is used by Text Analysis. It extracts and prepares data from textual content when the search function is invoked.
3. Name Server
The Name Server holds information about the entire system landscape. In a distributed deployment it tracks every running component and the location of data across nodes, so queries can be routed to the correct server.
4. Statistics Server
The Statistics Server collects status, resource allocation, consumption, and performance data for the SAP HANA system. Note: in HANA SPS 7 and later, the embedded statistics service runs inside the index server rather than as a stand-alone process.
5. XS Server
The XS Server hosts the XS Engine, which lets external applications and developers consume the SAP HANA database over HTTP. The XS Engine itself acts as a lightweight HTTP server, enabling browser-based and REST clients to talk directly to HANA.
SAP HANA Landscape
“HANA” stands for High Performance Analytic Appliance and is delivered as a combined hardware and software platform.
- Modern hardware offers far more CPU cores, RAM, and storage bandwidth than legacy database servers were designed to use.
- SAP HANA exploits this by keeping all working data in main memory, eliminating the disk I/O bottleneck that limits traditional databases.
The diagram below summarises the SAP HANA hardware and software innovations.

SAP HANA supports two relational data stores: Row Store and Column Store.
Row Store
Row Store behaves like a traditional database (Oracle, SQL Server). The key difference is that all rows live in main memory in SAP HANA, whereas a traditional database keeps them primarily on disk.
Column Store
Column Store keeps data in columnar form in memory. Column tables are stored here and the engine balances good write performance with optimised read performance. The diagram below shows the two structures that achieve this balance.

Main Storage
Main Storage holds the bulk of the data. Compression methods such as dictionary encoding, cluster encoding, sparse encoding, and run-length encoding are applied to save memory and accelerate searches.
- Modifying compressed data directly in main storage is expensive, so writes do not target main storage.
- Instead, every change is written to a separate area called Delta Storage. Reads can hit either main or delta storage.
Data can be loaded or unloaded manually using the Load into Memory and Unload from Memory options shown below.

Delta Storage
Delta Storage is optimised for writes and uses lighter compression. All uncommitted changes to a column table are kept here. When changes need to be merged back into Main Storage, run the Delta Merge operation from SAP HANA Studio.

- The delta merge moves the changes collected in delta storage into main storage.
- After the merge, the new main storage content is persisted to disk and compression is recalculated.
How Data Moves from Delta to Main Storage

A row-organised buffer called L1-Delta sits in front of every column table, which is why a column table can absorb high-throughput writes.
- The user runs an UPDATE or INSERT against the table.
- Data first lands in L1-Delta (uncommitted data).
- Once committed, data is moved into the column-oriented L2-Delta buffer.
- When L2-Delta is full or the merge runs, data is written to Main Storage.
Column storage is therefore both write-optimised (through L1 and L2 delta) and read-optimised (through main storage). After processing, data is persisted by the Persistence Layer to disk.
Example of a row-based table:

The same logical table is stored on disk differently depending on the store type. In Row Store, rows are written contiguously:

In Column Store, values from the same column are stored together:

Because column values share data type and often repeat, the column layout compresses extremely well — which is the main memory advantage of the column store.

SAP HANA Sizing
Sizing is the process of determining the hardware resources — RAM, disk, and CPU — required for a SAP HANA system. Memory is the most important factor, CPU is second, and disk is derived from the first two.
In a SAP HANA implementation, selecting the right server size for the business workload is one of the most critical tasks. Compared with a traditional DBMS, HANA sizing differs in three areas:
- Main memory: driven by metadata plus the volume of transactional and analytical data held in memory.
- CPU: estimated rather than measured, based on forecast query and load patterns.
- Disk: sized for data persistence and log volumes, not for online query data.
Application server CPU and memory remain unchanged compared with the previous database, because HANA only replaces the database tier.
SAP provides several methods to calculate the correct size:
- Sizing using an ABAP report (transaction code ST03 data and report /SDF/HDB_SIZING).
- Sizing using a database script for non-ABAP systems.
- Sizing using the SAP Quick Sizer tool on the SAP Service Marketplace.
When the Quick Sizer tool is used, the requirement is displayed in the format below.
