What is Hadoop? Architecture, Ecosystem & Components
⚡ Smart Summary
Apache Hadoop is an open-source framework that stores huge datasets across clusters of commodity machines and moves the processing logic to the data, so analysis scales by adding cheap nodes rather than bigger servers.

What is Hadoop?
Apache Hadoop is an open source software framework used to develop data processing applications which are executed in a distributed computing environment.
Applications built using Hadoop are run on large data sets distributed across clusters of commodity computers. Commodity computers are cheap and widely available. These are mainly useful for achieving greater computational power at low cost.
Similar to data residing in a local file system of a personal computer system, in Hadoop, data resides in a distributed file system which is called the Hadoop Distributed File System. The processing model is based on the ‘Data Locality’ concept, wherein computational logic is sent to the cluster nodes (servers) containing the data. This computational logic is simply a compiled version of a program written in a high-level language such as Java. Such a program processes data stored in Hadoop HDFS.
Do you know? A computer cluster consists of a set of multiple processing units (storage disk + processor) which are connected to each other and act as a single system.
Version 3.5.0, published on 2 April 2026, is the current stable release; the 3.4 line still receives maintenance updates.
Hadoop Ecosystem and Components
The diagram below shows the various components in the Hadoop ecosystem, grouped by the job each one does — storage, processing, and the query, ingestion and coordination tools around them.

Apache Hadoop consists of two sub-projects –
- Hadoop MapReduce: MapReduce is a computational model and software framework for writing applications which are run on Hadoop. These MapReduce programs are capable of processing enormous data in parallel on large clusters of computation nodes.
- HDFS (Hadoop Distributed File System): HDFS takes care of the storage part of Hadoop applications. MapReduce applications consume data from HDFS. HDFS creates multiple replicas of data blocks and distributes them on compute nodes in a cluster. This distribution enables reliable and extremely rapid computations.
Current releases ship two further core modules. Hadoop YARN, added in Hadoop 2.x, schedules work on the cluster, and Hadoop Common holds the shared Java libraries every module depends on. YARN is what lets engines such as Spark, Tez and Flink run alongside MapReduce.
Although Hadoop is best known for MapReduce and its distributed file system HDFS, the term is also used for a family of related projects that fall under the umbrella of distributed computing and large-scale data processing. Other Hadoop-related projects at Apache include Hive, HBase, Mahout, Sqoop, Flume, and ZooKeeper.
Hadoop Architecture
Hadoop has a master-slave architecture for data storage and distributed data processing using MapReduce and HDFS methods. The diagram below places those roles side by side, with the storage layer on one side and the processing layer on the other.
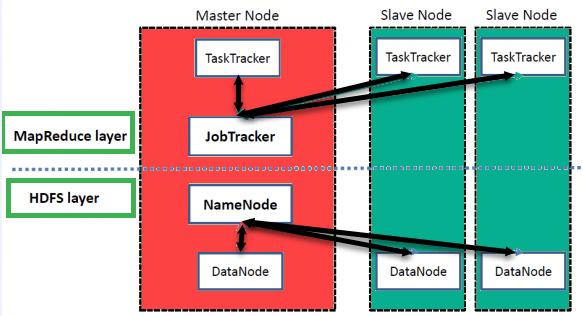
High Level Hadoop Architecture
NameNode
The NameNode stores the metadata for every file and directory used in the namespace, including which blocks make up each file and where those blocks live.
DataNode
A DataNode manages the state of an HDFS node and lets you interact with the blocks it stores, reporting back to the NameNode with periodic block reports and heartbeats.
MasterNode
The master node allows you to conduct parallel processing of data using Hadoop MapReduce.
Slave Node
The slave nodes are the additional machines in the Hadoop cluster that let you store data and run complex calculations. Moreover, every slave node runs a TaskTracker and a DataNode. This allows you to synchronise the processes with the NameNode and the JobTracker respectively.
In Hadoop, master or slave systems can be set up in the cloud or on-premise.
One naming note: JobTracker and TaskTracker belong to the first-generation MapReduce runtime (MRv1). From Hadoop 2.x onward, YARN splits their duties between a cluster-wide ResourceManager, a NodeManager per worker, and one ApplicationMaster per job. NameNode and DataNode are unchanged.
Features of Hadoop
Suitable for Big Data Analysis
As Big Data tends to be distributed and unstructured in nature, Hadoop clusters are best suited for the analysis of Big Data. Since it is the processing logic (not the actual data) that flows to the computing nodes, less network bandwidth is consumed. This is called the data locality concept, and it helps increase the efficiency of Hadoop-based applications.
Scalability
Hadoop clusters can easily be scaled to any extent by adding additional cluster nodes, and thus allow for the growth of Big Data. Also, scaling does not require modifications to application logic.
Fault Tolerance
The Hadoop ecosystem has a provision to replicate the input data on to other cluster nodes. That way, in the event of a cluster node failure, data processing can still proceed by using data stored on another cluster node. HDFS keeps three copies of every block by default, a value set by the dfs.replication property, and the NameNode re-replicates any block that drops below that count.
Network Topology in Hadoop
The topology (arrangement) of the network affects the performance of the Hadoop cluster as the size of the cluster grows. In addition to performance, one also needs to care about high availability and the handling of failures. To achieve this, Hadoop cluster formation makes use of network topology.
The tree below shows how that arrangement is modelled, from the data centre down to the nodes inside each rack.

Typically, network bandwidth is an important factor to consider while forming any network. However, as measuring bandwidth can be difficult, in Hadoop a network is represented as a tree, and the distance between nodes of this tree (the number of hops) is considered an important factor in the formation of a Hadoop cluster. Here, the distance between two nodes is equal to the sum of their distances to their closest common ancestor.
A Hadoop cluster consists of a data center, the rack and the node which actually executes jobs. Here, the data center consists of racks and a rack consists of nodes. Network bandwidth available to processes varies depending upon the location of the processes. That is, the bandwidth available becomes lesser as we go away from-
- Processes on the same node
- Different nodes on the same rack
- Nodes on different racks of the same data center
- Nodes in different data centers
Rack awareness uses the same tree: HDFS places replicas on more than one rack, so losing a rack switch does not take every copy of the data with it.