Hive Join & SubQuery Tutorial with Examples
Join queries
Join queries can perform on two tables present in Hive. For understanding Join Concepts in clear here we are creating two tables overhere,
- Sample_joins( Related to Customers Details )
- Sample_joins1( Related to orders details done by Employees)
Step 1) Creation of table “sample_joins” with Column names ID, Name, Age, address and salary of the employees

Step 2) Loading and Displaying Data
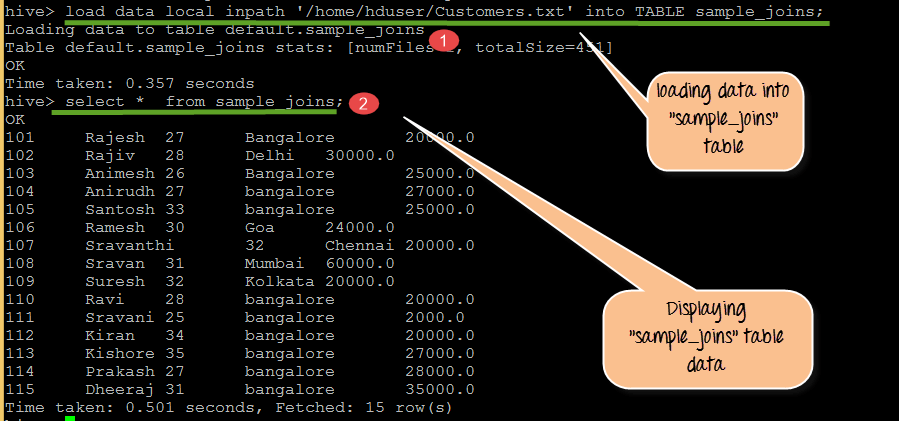
From the above screen shot
- Loading data into sample_joins from Customers.txt
- Displaying sample_joins table contents
Step 3) Creation of sample_joins1 table and loading, displaying data

From the above screenshot, we can observe the following
- Creation of table sample_joins1 with columns Orderid, Date1, Id, Amount
- Loading data into sample_joins1 from orders.txt
- Displaying records present in sample_joins1
Moving forward we will see different types of joins that can be performed on tables we have created but before that you have to consider following points for joins.
Some points to observe in Joins:
- Only Equality joins are allowed In Joins
- More than two tables can be joined in the same query
- LEFT, RIGHT, FULL OUTER joins exist in order to provide more control over ON Clause for which there is no match
- Joins are not Commutative
- Joins are left-associative irrespective of whether they are LEFT or RIGHT joins
Different type of joins
Joins are of 4 types, these are
- Inner join
- Left outer Join
- Right Outer Join
- Full Outer Join
Inner Join:
The Records common to the both tables will be retrieved by this Inner Join.

From the above screenshot, we can observe the following
- Here we are performing join query using JOIN keyword between the tables sample_joins and sample_joins1 with matching condition as (c.Id= o.Id).
- The output displaying common records present in both the table by checking the condition mentioned in the query
Query:
SELECT c.Id, c.Name, c.Age, o.Amount FROM sample_joins c JOIN sample_joins1 o ON(c.Id=o.Id);
Left Outer Join:
- Hive query language LEFT OUTER JOIN returns all the rows from the left table even though there are no matches in right table
- If ON Clause matches zero records in the right table, the joins still return a record in the result with NULL in each column from the right table

From the above screenshot, we can observe the following
- Here we are performing join query using “LEFT OUTER JOIN” keyword between the tables sample_joins and sample_joins1 with matching condition as (c.Id= o.Id).For example here we are using employee id as a reference, it checks whether id is common in right as well as left the table or not. It acts as matching condition.
- The output displaying common records present in both the table by checking the condition mentioned in the query.NULL values in the above output are columns with no values from Right table that is sample_joins1
Query:
SELECT c.Id, c.Name, o.Amount, o.Date1 FROM sample_joins c LEFT OUTER JOIN sample_joins1 o ON(c.Id=o.Id)
Right outer Join:
- Hive query language RIGHT OUTER JOIN returns all the rows from the Right table even though there are no matches in left table
- If ON Clause matches zero records in the left table, the joins still return a record in the result with NULL in each column from the left table
- RIGHT joins always return records from a Right table and matched records from the left table. If the left table is having no values corresponding to the column, it will return NULL values in that place.

From the above screenshot, we can observe the following
- Here we are performing join query using “RIGHT OUTER JOIN” keyword between the tables sample_joins and sample_joins1 with matching condition as (c.Id= o.Id).
- The output displaying common records present in both the table by checking the condition mentioned in the query
Query:
SELECT c.Id, c.Name, o.Amount, o.Date1 FROM sample_joins c RIGHT OUTER JOIN sample_joins1 o ON(c.Id=o.Id)
Full outer join:
It combines records of both the tables sample_joins and sample_joins1 based on the JOIN Condition given in query.
It returns all the records from both tables and fills in NULL Values for the columns missing values matched on either side.

From the above screen shot we can observe the following:
- Here we are performing join query using “FULL OUTER JOIN” keyword between the tables sample_joins and sample_joins1 with matching condition as (c.Id= o.Id).
- The output displaying all the records present in both the table by checking the condition mentioned in the query. Null values in output here indicates the missing values from the columns of both tables.
Query
SELECT c.Id, c.Name, o.Amount, o.Date1 FROM sample_joins c FULL OUTER JOIN sample_joins1 o ON(c.Id=o.Id)
Sub queries
A Query present within a Query is known as a sub query. The main query will depend on the values returned by the subqueries.
Subqueries can be classified into two types
- Subqueries in FROM clause
- Subqueries in WHERE clause
When to use:
- To get a particular value combined from two column values from different tables
- Dependency of one table values on other tables
- Comparative checking of one column values from other tables
Syntax:
Subquery in FROM clause SELECT <column names 1, 2…n>From (SubQuery) <TableName_Main > Subquery in WHERE clause SELECT <column names 1, 2…n> From<TableName_Main>WHERE col1 IN (SubQuery);
Example:
SELECT col1 FROM (SELECT a+b AS col1 FROM t1) t2
Here t1 and t2 are table names. The colored one is Subquery performed on table t1. Here a and b are columns that are added in a subquery and assigned to col1. Col1 is the column value present in Main table. This column “col1” present in the subquery is equivalent to the main table query in column col1.
Embedding custom scripts
Hive provides feasibility of writing user specific scripts for the client requirements. The users can able to write their own map and reduce scripts for the requirements. These are called Embedded Custom scripts. The coding logic is defined in the custom scripts and we can use that script in the ETL time.
When to choose Embedded Scripts:
- In client specific requirements developers has to write and deploy scripts in Hive
- Where Hive inbuilt functions are not going to work for specific domain requirements
For this in Hive it uses TRANSFORM clause to embedded both map and reducer scripts.
In this Embedded custom scripts, we have to observe the following points
- Columns will be transformed to string and delimited by TAB before giving it to the user script
- Standard output of the user script will be treated as TAB- separated string columns
Sample Embedded Script,
FROM ( FROM pv_users MAP pv_users.userid, pv_users.date USING 'map_script' AS dt, uid CLUSTER BY dt) map_output INSERT OVERWRITE TABLE pv_users_reduced REDUCE map_output.dt, map_output.uid USING 'reduce_script' AS date, count;
From the above script, we can observe the following
This is only the sample script for understanding
- pv_users is the users table which is having fields like userid and date as mentioned in map_script
- Reducer script defined on date and count of the pv_users tables