Star Schema & Extended Star Schema in SAP BI/BW
⚡ Smart Summary
Star schema and extended star schema in SAP BW organize data into fact and dimension tables, where the extended model links dimensions to master data through SID tables, enabling far greater analysis depth and master data reuse.
What is a Schema?
In a database management system (DBMS), a schema represents the relational database. It defines the tables, the fields in each table, and the relationships between fields and tables. In other words, a schema is a collection of database objects, including tables, views, indexes, and synonyms. Schemas are generally stored in a data dictionary.
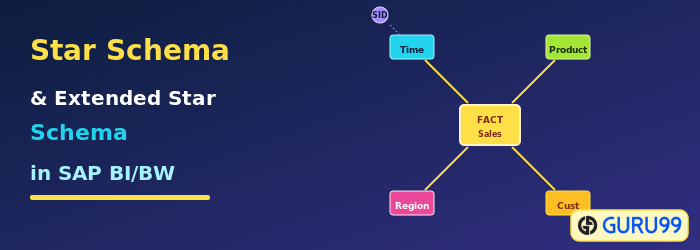
What is a Classical Star Schema?
A classical star schema is a multidimensional data model. It is based on a central fact table surrounded by several dimension tables in the shape of a star (hence the name).
An InfoCube consists of several InfoObjects (characteristics and key figures) and is structured according to the star schema. There is a large fact table with key figures for the InfoCube, surrounded by many dimension tables that form the star. A fact table can have a maximum of 16 dimensions.
The benefits of the star schema are easy slicing of data, easy understanding, and improved performance.

What is an Extended Star Schema?
In the extended star schema, the “fact table” and the “master data table” are connected through an SID (Surrogate ID) table. The fact table and dimension table sit inside the cube, while master data sits outside it. It has an analyzing capacity of 16 × 248 (SID tables). The fact table is small and the dimension table is large, contrary to the classical star schema. Under the extended star schema, the dimension table does not contain master data.

The different components of an extended star schema are:
- The attribute table holds the attributes of master data.
- The SID table creates a unique SID (Surrogate ID) for every master data record.
- The dimension table creates a DimID for every unique combination of SIDs (a maximum of 248 SID characteristics can be accommodated in a dimension table).
- The text table holds descriptions of master data.
- The fact table contains a unique combination of DimIDs and key figures (a maximum of 233 key figures can be accommodated in a fact table).

Below is an example of how a fact table of an InfoCube looks.

Below are the dimension and SID tables.

Below are the InfoObject master data and text tables.

InfoCube: Sample Extended Star Schema
The following is an example of an InfoCube showing the extended star schema.
Steps explaining the extended star schema of an InfoCube:
- The fact table of the InfoCube has a value of 3.
- The value of the fact table (“3”) is mapped in the dimension table.
- The Dimension ID “3” has an SID mapped in the SID table.
- The SID value is mapped with the text and master data tables.
