DISTINCT in PostgreSQL: Select, Order By & Limit (Examples)
⚡ Smart Summary
DISTINCT in PostgreSQL is used with a SELECT statement to remove duplicate rows and return only unique values. It covers the SELECT syntax, the SQL Shell and pgAdmin, DISTINCT on single and multiple columns, and DISTINCT versus GROUP BY.

You can retrieve data from the table using a SELECT statement.
Syntax:
SELECT [column names] FROM [table_name]
Here,
- column names: Name of the columns whose value you want to retrieve.
- FROM: The FROM clause defines one or more source tables for the SELECT.
- table_name: The name of an existing table that you want to query.
What is DISTINCT in PostgreSQL?
The DISTINCT clause in PostgreSQL is used with a SELECT statement to remove duplicate rows from the result set. When a column contains repeated values, SELECT DISTINCT returns only the unique values, keeping a single row for each group of duplicates. This is useful when you want a list of distinct entries, such as unique customer cities or product categories, without repetition.
DISTINCT evaluates all the columns listed in the SELECT statement to decide whether a row is unique. PostgreSQL also provides DISTINCT ON, which returns the first row for each distinct value of a specified expression. You can combine DISTINCT with ORDER BY to control which rows appear and with LIMIT to cap the number of results.
PostgreSQL Select Statement in SQL Shell
Step 1) We have a table “tutorials” with 2 columns, “id” and “tutorial_name”. Let us query it. Use the following query to list data in the table:
SELECT id,tutorial_name FROM tutorials;

NOTE: Use the command \c to connect to the database that contains the table you want to query. In our case, we are connected to database guru99.
Step 2) If you want to view all the columns in a particular table, we can use the asterisk (*) wildcard character. This means it checks every possibility and, as a result, it will return every column.
SELECT * FROM tutorials;

It displays all the records of the tutorials table.
Step 3) You can use the ORDER clause to sort data in a table based on a particular column. The ORDER clause organizes data in A to Z order.
SELECT * FROM tutorials ORDER BY id;

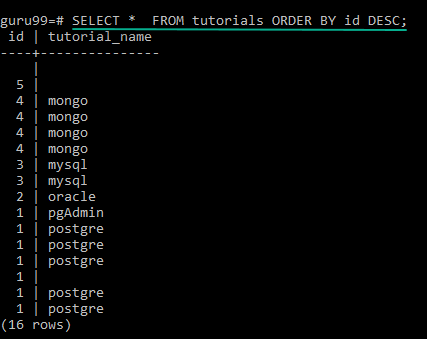
You can sort from Z to A using “DESC” after the “ORDER BY” statement.
SELECT * FROM tutorials ORDER BY id DESC;
Step 4) The SELECT DISTINCT in PostgreSQL clause can be used to remove duplicate rows from the result. It keeps one row for each group of duplicates.
Syntax: SELECT DISTINCT column_1 FROM table_name;
Let us query Postgres Select Distinct id values from our table tutorials using distinct queries in PostgreSQL:
SELECT DISTINCT(id) FROM tutorials;

Step 5) You can use the PostgreSQL LIMIT clause to restrict the number of records returned by the SELECT query.
SELECT * FROM tutorials LIMIT 4;

PostgreSQL Select Statement in pgAdmin
Step 1) In the Object Tree:
- Right click on the Table.
- Select Scripts.
- Click on SELECT SCRIPT.

Step 2) In the panel on the right:
- Edit the SELECT query if required.
- Click the Lightning icon.
- Observe the output.

DISTINCT on Multiple Columns
The SELECT DISTINCT clause can also apply to more than one column. When you list multiple columns after DISTINCT, PostgreSQL treats the combination of those columns as a unit and removes rows where that whole combination is duplicated.
Syntax: SELECT DISTINCT column_1, column_2 FROM table_name;
For example, to return the unique combinations of tutorial_name and id from the tutorials table:
SELECT DISTINCT tutorial_name, id FROM tutorials;
In this case, a row is removed only when both tutorial_name and id match another row. If two rows share the same tutorial_name but have different id values, both are kept, because the combination is still unique. This behaviour is important to remember: DISTINCT does not de-duplicate a single column when several columns are selected; it de-duplicates the full set of selected columns together.
DISTINCT vs GROUP BY in PostgreSQL
Both DISTINCT and GROUP BY can remove duplicate values, but they serve different purposes:
- DISTINCT simply returns unique rows from the result and is best when you only need a de-duplicated list.
- GROUP BY groups rows that share a value so you can apply aggregate functions such as COUNT, SUM, or AVG to each group.
For example, the two queries below both return the unique id values:
SELECT DISTINCT id FROM tutorials; SELECT id FROM tutorials GROUP BY id;
Use DISTINCT for a plain list of unique values, and use GROUP BY when you also need a calculation per group, such as counting how many tutorials share each id. On simple queries the planner often produces similar performance for both, but GROUP BY is required whenever aggregation is involved.
Cheat Sheet
SELECT [column names] FROM [table_name] [clause]
Here are the various parameters:
- column names: Name of the columns whose value you want to retrieve.
- FROM: The FROM clause defines one or more source tables for the SELECT.
- table_name: The name of an existing table that you want to query.
Various clauses are:
| Commands | Description |
|---|---|
| * | Fetches records for all the rows in the table. |
| DISTINCT | DISTINCT in PostgreSQL helps you to remove duplicates from the result. |
| ORDER BY | Sorts rows based on a column. Default sort order is ascending. Use the keyword DESC to sort in descending order. |
| LIMIT | LIMIT in PostgreSQL restricts the number of records returned by the query. |