50 SQL Interview Questions and Answers for 2026
SQL Interview Questions for Freshers
1. What is DBMS?
A Database Management System (DBMS) is a program that controls creation, maintenance and use of a database. DBMS can be termed as File Manager that manages data in a database rather than saving it in file systems.
👉 Free PDF Download: SQL Interview Questions & Answers >>
2. What is RDBMS?
RDBMS stands for Relational Database Management System. RDBMS store the data into the collection of tables, which is related by common fields between the columns of the table. It also provides relational operators to manipulate the data stored into the tables.
Example: SQL Server.
3. What is SQL?
SQL stands for Structured Query Language , and it is used to communicate with the Database. This is a standard language used to perform tasks such as retrieval, updation, insertion and deletion of data from a database.
Standard SQL Commands are Select.
4. What is a Database?
Database is nothing but an organized form of data for easy access, storing, retrieval and managing of data. This is also known as structured form of data which can be accessed in many ways.
Example: School Management Database, Bank Management Database.
5. What are tables and Fields?
A table is a set of data that are organized in a model with Columns and Rows. Columns can be categorized as vertical, and Rows are horizontal. A table has specified number of column called fields but can have any number of rows which is called record.
Example:.
Table: Employee.
Field: Emp ID, Emp Name, Date of Birth.
Data: 201456, David, 11/15/1960.
6. What is a primary key?
A primary key is a combination of fields which uniquely specify a row. This is a special kind of unique key, and it has implicit NOT NULL constraint. It means, Primary key values cannot be NULL.
7. What is a unique key?
A Unique key constraint uniquely identified each record in the database. This provides uniqueness for the column or set of columns.
A Primary key constraint has automatic unique constraint defined on it. But not, in the case of Unique Key.
There can be many unique constraint defined per table, but only one Primary key constraint defined per table.
8. What is a foreign key?
A foreign key is one table which can be related to the primary key of another table. Relationship needs to be created between two tables by referencing foreign key with the primary key of another table.
9. What is a join?
This is a keyword used to query data from more tables based on the relationship between the fields of the tables. Keys play a major role when JOINs are used.
10. What are the types of join and explain each?
There are various types of join which can be used to retrieve data and it depends on the relationship between tables.
- Inner Join.
Inner join return rows when there is at least one match of rows between the tables.
- Right Join.
Right join return rows which are common between the tables and all rows of Right hand side table. Simply, it returns all the rows from the right hand side table even though there are no matches in the left hand side table.
- Left Join.
Left join return rows which are common between the tables and all rows of Left hand side table. Simply, it returns all the rows from Left hand side table even though there are no matches in the Right hand side table.
- Full Join.
Full join return rows when there are matching rows in any one of the tables. This means, it returns all the rows from the left hand side table and all the rows from the right hand side table.
SQL Interview Questions for 3 Years Experience
11. What is normalization?
Normalization is the process of minimizing redundancy and dependency by organizing fields and table of a database. The main aim of Normalization is to add, delete or modify field that can be made in a single table.
12. What is Denormalization?
DeNormalization is a technique used to access the data from higher to lower normal forms of database. It is also process of introducing redundancy into a table by incorporating data from the related tables.
13. What are all the different normalizations?
Database Normalization can be easily understood with the help of a case study. The normal forms can be divided into 6 forms, and they are explained below -.
.png)
- First Normal Form (1NF):.
This should remove all the duplicate columns from the table. Creation of tables for the related data and identification of unique columns.
- Second Normal Form (2NF):.
Meeting all requirements of the first normal form. Placing the subsets of data in separate tables and Creation of relationships between the tables using primary keys.
- Third Normal Form (3NF):.
This should meet all requirements of 2NF. Removing the columns which are not dependent on primary key constraints.
- Fourth Normal Form (4NF):.
If no database table instance contains two or more, independent and multivalued data describing the relevant entity, then it is in 4th Normal Form.
- Fifth Normal Form (5NF):.
A table is in 5th Normal Form only if it is in 4NF and it cannot be decomposed into any number of smaller tables without loss of data.
- Sixth Normal Form (6NF):.
6th Normal Form is not standardized, yet however, it is being discussed by database experts for some time. Hopefully, we would have a clear & standardized definition for 6th Normal Form in the near future…
14. What is a View?
A view is a virtual table which consists of a subset of data contained in a table. Views are not virtually present, and it takes less space to store. View can have data of one or more tables combined, and it is depending on the relationship.
15. What is an Index?
An index is performance tuning method of allowing faster retrieval of records from the table. An index creates an entry for each value and it will be faster to retrieve data.
16. What are all the different types of indexes?
There are three types of indexes -.
- Unique Index.
This indexing does not allow the field to have duplicate values if the column is unique indexed. Unique index can be applied automatically when primary key is defined.
- Clustered Index.
This type of index reorders the physical order of the table and search based on the key values. Each table can have only one clustered index.
- NonClustered Index.
NonClustered Index does not alter the physical order of the table and maintains logical order of data. Each table can have 999 nonclustered indexes.
17. What is a Cursor?
A database Cursor is a control which enables traversal over the rows or records in the table. This can be viewed as a pointer to one row in a set of rows. Cursor is very much useful for traversing such as retrieval, addition and removal of database records.
18. What is a relationship and what are they?
Database Relationship is defined as the connection between the tables in a database. There are various data basing relationships, and they are as follows:.
- One to One Relationship.
- One to Many Relationship.
- Many to One Relationship.
- Self-Referencing Relationship.
19. What is a query?
A DB query is a code written in order to get the information back from the database. Query can be designed in such a way that it matched with our expectation of the result set. Simply, a question to the Database.
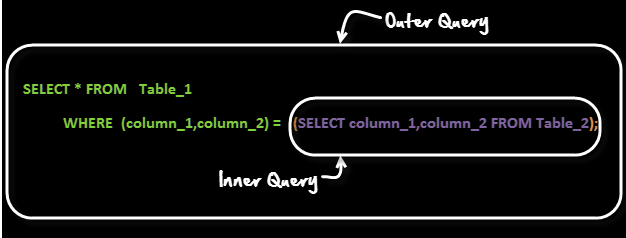
20. What is subquery?
A subquery is a query within another query. The outer query is called as main query, and inner query is called subquery. SubQuery is always executed first, and the result of subquery is passed on to the main query.
Let’s look into the sub query syntax –
A common customer complaint at the MyFlix Video Library is the low number of movie titles. The management wants to buy movies for a category which has least number of titles.
You can use a query like
SELECT category_name FROM categories WHERE category_id =( SELECT MIN(category_id) from movies);
SQL Interview Questions for 5 Years Experience
21. What are the types of subquery?
There are two types of subquery – Correlated and Non-Correlated.
A correlated subquery cannot be considered as independent query, but it can refer the column in a table listed in the FROM the list of the main query.
A Non-Correlated sub query can be considered as independent query and the output of subquery are substituted in the main query.
22. What is a stored procedure?
Stored Procedure is a function consists of many SQL statement to access the database system. Several SQL statements are consolidated into a stored procedure and execute them whenever and wherever required.
23. What is a trigger?
A DB trigger is a code or programs that automatically execute with response to some event on a table or view in a database. Mainly, trigger helps to maintain the integrity of the database.
Example: When a new student is added to the student database, new records should be created in the related tables like Exam, Score and Attendance tables.
24. What is the difference between DELETE and TRUNCATE commands?
DELETE command is used to remove rows from the table, and WHERE clause can be used for conditional set of parameters. Commit and Rollback can be performed after delete statement.
TRUNCATE removes all rows from the table. Truncate operation cannot be rolled back.
25. What are local and global variables and their differences?
Local variables are the variables which can be used or exist inside the function. They are not known to the other functions and those variables cannot be referred or used. Variables can be created whenever that function is called.
Global variables are the variables which can be used or exist throughout the program. Same variable declared in global cannot be used in functions. Global variables cannot be created whenever that function is called.
26. What is a constraint?
Constraint can be used to specify the limit on the data type of table. Constraint can be specified while creating or altering the table statement. Sample of constraint are.
- NOT NULL.
- CHECK.
- DEFAULT.
- UNIQUE.
- PRIMARY KEY.
- FOREIGN KEY.
27. What is data Integrity?
Data Integrity defines the accuracy and consistency of data stored in a database. It can also define integrity constraints to enforce business rules on the data when it is entered into the application or database.
28. What is Auto Increment?
Auto increment keyword allows the user to create a unique number to be generated when a new record is inserted into the table. AUTO INCREMENT keyword can be used in Oracle and IDENTITY keyword can be used in SQL SERVER.
Mostly this keyword can be used whenever PRIMARY KEY is used.
29. What is the difference between Cluster and Non-Cluster Index?
Clustered index is used for easy retrieval of data from the database by altering the way that the records are stored. Database sorts out rows by the column which is set to be clustered index.
A nonclustered index does not alter the way it was stored but creates a complete separate object within the table. It point back to the original table rows after searching.
30. What is Datawarehouse?
Datawarehouse is a central repository of data from multiple sources of information. Those data are consolidated, transformed and made available for the mining and online processing. Warehouse data have a subset of data called Data Marts.
31. What is Self-Join?
Self-join is set to be query used to compare to itself. This is used to compare values in a column with other values in the same column in the same table. ALIAS ES can be used for the same table comparison.
32. What is Cross-Join?
Cross join defines as Cartesian product where number of rows in the first table multiplied by number of rows in the second table. If suppose, WHERE clause is used in cross join then the query will work like an INNER JOIN.
33. What is user defined functions?
User defined functions are the functions written to use that logic whenever required. It is not necessary to write the same logic several times. Instead, function can be called or executed whenever needed.
34. What are all types of user defined functions?
Three types of user defined functions are.
- Scalar Functions.
- Inline Table valued functions.
- Multi statement valued functions.
Scalar returns unit, variant defined the return clause. Other two types return table as a return.
35. What is collation?
Collation is defined as set of rules that determine how character data can be sorted and compared. This can be used to compare A and, other language characters and also depends on the width of the characters.
ASCII value can be used to compare these character data.
36. What are all different types of collation sensitivity?
Following are different types of collation sensitivity -.
- Case Sensitivity – A and a and B and b.
- Accent Sensitivity.
- Kana Sensitivity – Japanese Kana characters.
- Width Sensitivity – Single byte character and double byte character.
37. Advantages and Disadvantages of Stored Procedure?
Stored procedure can be used as a modular programming – means create once, store and call for several times whenever required. This supports faster execution instead of executing multiple queries. This reduces network traffic and provides better security to the data.
Disadvantage is that it can be executed only in the Database and utilizes more memory in the database server.
38. What is Online Transaction Processing (OLTP)?
Online Transaction Processing (OLTP) manages transaction based applications which can be used for data entry, data retrieval and data processing. OLTP makes data management simple and efficient. Unlike OLAP systems goal of OLTP systems is serving real-time transactions.
Example – Bank Transactions on a daily basis.
39. What is CLAUSE?
SQL clause is defined to limit the result set by providing condition to the query. This usually filters some rows from the whole set of records.
Example – Query that has WHERE condition
Query that has HAVING condition.
40. What is recursive stored procedure?
A stored procedure which calls by itself until it reaches some boundary condition. This recursive function or procedure helps programmers to use the same set of code any number of times.
SQL Interview Questions for 10+ Years Experience
41. What is Union, minus and Interact commands?
UNION operator is used to combine the results of two tables, and it eliminates duplicate rows from the tables.
MINUS operator is used to return rows from the first query but not from the second query. Matching records of first and second query and other rows from the first query will be displayed as a result set.
INTERSECT operator is used to return rows returned by both the queries.
42. What is an ALIAS command?
ALIAS name can be given to a table or column. This alias name can be referred in WHERE clause to identify the table or column.
Example-.
Select st.StudentID, Ex.Result from student st, Exam as Ex where st.studentID = Ex. StudentID
Here, st refers to alias name for student table and Ex refers to alias name for exam table.
43. What is the difference between TRUNCATE and DROP statements?
TRUNCATE removes all the rows from the table, and it cannot be rolled back. DROP command removes a table from the database and operation cannot be rolled back.
44. What are aggregate and scalar functions?
Aggregate functions are used to evaluate mathematical calculation and return single values. This can be calculated from the columns in a table. Scalar functions return a single value based on the input value.
Example -.
Aggregate – max(), count – Calculated with respect to numeric.
Scalar – UCASE(), NOW() – Calculated with respect to strings.
45. How can you create an empty table from an existing table?
Example will be -.
Select * into studentcopy from student where 1=2
Here, we are copying student table to another table with the same structure with no rows copied.
46. How to fetch common records from two tables?
Common records result set can be achieved by -.
Select studentID from student INTERSECT Select StudentID from Exam
47. How to fetch alternate records from a table?
Records can be fetched for both Odd and Even row numbers -.
To display even numbers-.
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=0
To display odd numbers-.
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=1
from (Select rowno, studentId from student) where mod(rowno,2)=1.[/sql]
48. How to select unique records from a table?
Select unique records from a table by using DISTINCT keyword.
Select DISTINCT StudentID, StudentName from Student.
49. What is the command used to fetch first 5 characters of the string?
There are many ways to fetch first 5 characters of the string -.
Select SUBSTRING(StudentName,1,5) as studentname from student
Select LEFT(Studentname,5) as studentname from student
50. Which operator is used in query for pattern matching?
LIKE operator is used for pattern matching, and it can be used as -.
- % – Matches zero or more characters.
- _(Underscore) – Matching exactly one character.
Example -.
Select * from Student where studentname like 'a%'
Select * from Student where studentname like 'ami_'
These interview questions will also help in your viva(orals)