Wort-Embedding und Word2Vec mit Beispiel
⚡ Intelligente Zusammenfassung
Word Embedding und Word2Vec wandeln Text in dichte numerische Vektoren um, sodass Modelle des maschinellen Lernens Wörter mit ähnlicher Bedeutung erkennen können. Diese Ressource erläutert die Technik, ihre CBOW- und Skip-Gram-Architekturen, Aktivierungsfunktionen und eine vollständige Gensim-Implementierung für praktische Anwendungen.
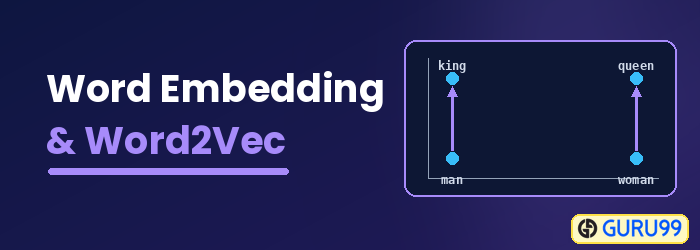
Was ist Worteinbettung?
Word-Einbettung Word Embedding ist eine Wortrepräsentationsart, die es Algorithmen des maschinellen Lernens ermöglicht, Wörter mit ähnlicher Bedeutung zu verstehen. Es handelt sich um eine Technik des Sprachmodellierens und Merkmalslernens, um Wörter mithilfe neuronaler Netze, probabilistischer Modelle oder Dimensionsreduktion der Wort-Kookkurrenzmatrix in Vektoren reeller Zahlen abzubilden. Einige Word-Embedding-Modelle sind Word2vec (Google), GloVe (Stanford) und fastText (Facebook).
Word Embedding wird auch als verteiltes semantisches Modell, verteiltes Repräsentationsmodell, semantischer Vektorraum oder Vektorraummodell bezeichnet. Beim Lesen dieser Bezeichnungen stößt man auf das Wort semantischDas bedeutet, ähnliche Wörter zusammenzufassen. Beispielsweise sollten Früchte wie Apfel, Mango und Banane nahe beieinander liegen, während Bücher weit von diesen Wörtern entfernt platziert werden. Im weiteren Sinne erzeugt Word Embedding einen Vektor für Früchte, der weit von der Vektordarstellung der Bücher entfernt ist.
Wo wird Worteinbettung eingesetzt?
Wort-Embedding ist hilfreich bei der Merkmalsgenerierung, dem Dokumenten-Clustering, der Textklassifizierung und Aufgaben der natürlichen Sprachverarbeitung. Im Folgenden werden diese Anwendungen aufgelistet und erläutert.
- Berechnen Sie ähnliche Wörter: Mithilfe von Word Embedding werden ähnliche Wörter zu dem Wort vorgeschlagen, das dem Vorhersagemodell unterzogen wird. Darüber hinaus werden auch unähnliche Wörter sowie die häufigsten Wörter vorgeschlagen.
- Erstellen Sie eine Gruppe verwandter Wörter: Es wird für semantische Gruppen verwendet.ping, wodurch Dinge mit ähnlichen Eigenschaften gruppiert und unähnliche Dinge weit voneinander entfernt werden.
- Funktion zur Textklassifizierung: Text wird in Vektorarrays umgewandelt, die dem Modell sowohl zum Training als auch zur Vorhersage zugeführt werden. Da textbasierte Klassifikatormodelle nicht mit Zeichenketten trainiert werden können, wird der Text hierdurch in eine maschinenlesbare Form gebracht. Die semantischen Analysefunktionen tragen zusätzlich zur textbasierten Klassifizierung bei.
- Dokumenten-Clustering: Dies ist eine weitere Anwendung, bei der Word Embedding und Word2vec weit verbreitet sind.
- Verarbeitung natürlicher Sprache: Es gibt viele Anwendungsbereiche, in denen Word Embedding nützlich ist und Feature-Extensions überlegen ist.tracAnalysephasen wie Wortartenbestimmung, Stimmungsanalyse und Syntaxanalyse.
Nachdem Sie nun wissen, wo Wort-Embedding Anwendung findet, wollen wir uns das beliebteste Modell zur Erstellung dieser Embeddings ansehen.
Was ist Word2vec?
Word2vec Es handelt sich um eine Technik bzw. ein Modell zur Erzeugung von Wortvektoren für eine verbesserte Wortdarstellung. Diese Methode der natürlichen Sprachverarbeitung erfasst eine Vielzahl präziser syntaktischer und semantischer Wortbeziehungen. Es ist ein flaches, zweischichtiges neuronales Netzwerk, das nach dem Training Synonyme erkennen und zusätzliche Wörter für unvollständige Sätze vorschlagen kann.
Bevor wir fortfahren, sehen Sie sich bitte den Unterschied zwischen einem flachen und einem tiefen neuronalen Netzwerk an, wie er im folgenden Beispieldiagramm für Word Embeddings dargestellt ist:
Ein flaches neuronales Netzwerk besteht nur aus einer verborgenen Schicht zwischen Eingabe und Ausgabe, während ein tiefes neuronales Netzwerk mehrere verborgene Schichten zwischen Eingabe und Ausgabe aufweist. Die Eingabe erfolgt über Knoten, während sowohl die verborgene Schicht als auch die Ausgabeschicht Neuronen enthalten.
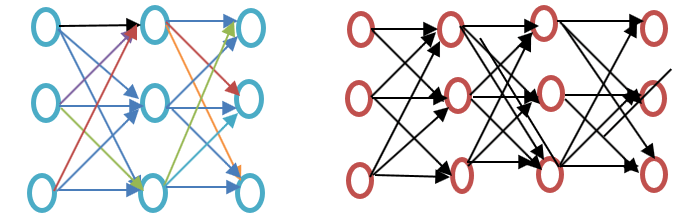
Word2vec ist ein zweischichtiges Netzwerk mit einem Eingang, einer verborgenen Schicht und einem Ausgang.
Word2vec wurde von einer Forschergruppe unter der Leitung von Tomas Mikolov entwickelt. GoogleWord2vec ist besser und effizienter als das Modell der latenten semantischen Analyse.
Warum Word2vec?
Word2vec stellt Wörter in einer Vektorraumdarstellung dar. Wörter werden als Vektoren abgebildet, wobei Wörter mit ähnlicher Bedeutung zusammen und unähnliche Wörter weit voneinander entfernt angeordnet sind. Dies wird auch als semantische Beziehung bezeichnet. Neuronale Netze verstehen keinen Text, sondern nur Zahlen. Word Embedding ermöglicht es, Text in einen numerischen Vektor umzuwandeln.
Word2vec rekonstruiert den linguistischen Kontext von Wörtern. Doch was genau versteht man unter linguistischem Kontext? Wenn wir sprechen oder schreiben, um zu kommunizieren, versuchen andere, den Sinn des Satzes zu erschließen. Zum Beispiel: „Wie hoch ist die Temperatur in Indien?“ Hier möchte der Nutzer die „Temperatur in Indien“ wissen. Kurz gesagt: Der Hauptzweck eines Satzes ist der Kontext. Die Wörter oder Sätze, die den gesprochenen oder geschriebenen Text umgeben, helfen dabei, die Bedeutung des Kontextes zu bestimmen. Word2vec lernt die Vektordarstellung von Wörtern anhand dieser Kontexte.
Was macht Word2vec?
Vor der Worteinbettung
Es ist wichtig zu wissen, welcher Ansatz vor dem Word Embedding verwendet wurde und welche Nachteile er hat. Anschließend werden wir sehen, wie diese Nachteile durch Word Embedding mithilfe des Word2vec-Ansatzes überwunden werden. Abschließend werden wir die Funktionsweise von Word2vec erläutern, da es wichtig ist, diese zu verstehen.
Ansatz zur latenten semantischen Analyse
Dies ist der Ansatz, der vor Wortvektoren verwendet wurde. Er basiert auf dem Konzept des Bag-of-Words, bei dem Wörter als kodierte Vektoren dargestellt werden. Es handelt sich um eine dünnbesetzte Vektordarstellung, deren Dimension der Größe des Vokabulars entspricht. Wörter, die im Wörterbuch vorkommen, werden gezählt; andernfalls nicht. Weitere Informationen finden Sie im untenstehenden Programm.
Word2vec-Beispiel

from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() data_corpus = ["guru99 is the best site for online tutorials. I love to visit guru99."] vocabulary = vectorizer.fit(data_corpus) X = vectorizer.transform(data_corpus) print(X.toarray()) print(vectorizer.get_feature_names_out())
Ausgang:
[[1 2 1 1 1 1 1 1 1 1]] [u'best', u'guru99', u'is', u'love', u'online', u'sitefor', u'the', u'to', u'tutorials', u'visit']
Code Erläuterung
- CountVectorizer ist das Modul, das zum Speichern des Vokabulars anhand der darin enthaltenen Wörter verwendet wird. Es wird aus sklearn importiert.
- Erstellen Sie das Objekt mit der Klasse CountVectorizer.
- Schreiben Sie die Daten in die Liste, die in den CountVectorizer eingefügt werden sollen.
- Die Daten werden in das aus der Klasse CountVectorizer erstellte Objekt eingepasst.
- Wenden Sie einen Bag-of-Words-Ansatz an, um die Wörter in den Daten mithilfe des Vokabulars zu zählen. Wenn ein Wort oder Token im Vokabular nicht vorhanden ist, wird die entsprechende Indexposition auf null gesetzt.
- Die Variable x in Zeile 5 wird in ein Array umgewandelt (eine für x verfügbare Methode). Dadurch wird die Anzahl jedes Tokens im Satz oder in der Liste aus Zeile 3 ermittelt.
- Hier werden die Merkmale angezeigt, die Teil des Vokabulars sind, wenn es anhand der Daten in Zeile 4 angepasst wird.
Im Ansatz der latenten Semantik repräsentiert jede Zeile die Anzahl der eindeutigen Wörter, während jede Spalte die Häufigkeit des jeweiligen Wortes im Dokument angibt. Es handelt sich um eine Wortdarstellung in Form einer Dokumentmatrix. Die Termfrequenz-Inverse Dokumentfrequenz (TF-IDF) dient zur Berechnung der Worthäufigkeit im Dokument. Sie ergibt sich aus der Häufigkeit des Begriffs im Dokument dividiert durch seine Häufigkeit im gesamten Korpus.
Mangel der Bag of Words-Methode
- Die Wortreihenfolge wird dabei ignoriert; zum Beispiel das ist schlecht = Ist das schlecht?.
- Es ignoriert den Kontext der Wörter. Nehmen wir an, wir schreiben den Satz „Er liebte Bücher. Bildung findet man am besten in Büchern.“ Es würden zwei Vektoren erzeugt: einer für „Er liebte Bücher“ und ein weiterer für „Bildung findet man am besten in Büchern“. Beide würden als orthogonal behandelt, was sie unabhängig erscheinen lässt, aber in Wirklichkeit hängen sie miteinander zusammen.
Um diese Einschränkungen zu überwinden, wurde das Word Embedding entwickelt, und Word2vec ist ein Ansatz, der zu dessen Implementierung verwendet wird.
Wie funktioniert Word2vec?
Word2vec lernt ein Wort, indem es seinen Kontext vorhersagt. Nehmen wir zum Beispiel das Wort „Er“. liebt Fußball."
Wir möchten den Word2vec-Wert für das Wort berechnen: liebt.
Annehmen:
loves = Vin. P(Vout / Vin) is calculated where, Vin is the input word. P is the probability of likelihood. Vout is the output word.
Das Wort liebt Die Software durchläuft jedes Wort im Korpus. Dabei werden sowohl syntaktische als auch semantische Beziehungen zwischen den Wörtern kodiert. Dies erleichtert das Auffinden ähnlicher und analoger Wörter.
Alle zufälligen Merkmale des Wortes liebt werden berechnet. Diese Merkmale werden mithilfe von benachbarten oder Kontextwörtern geändert oder aktualisiert. Rückwärtsausbreitung Methode.
Eine andere Lernmethode besteht darin, dass Wörter, deren Kontext ähnlich ist oder die ähnliche Merkmale aufweisen, miteinander verwandt sind.
Word2vec Architektur
Word2vec verwendet zwei Architekturen:
- Kontinuierliche Worttüte (CBOW)
- Skip-Gramm
Bevor wir fortfahren, wollen wir erörtern, warum diese Architekturen bzw. Modelle aus Sicht der Wortrepräsentation wichtig sind. Das Erlernen von Wortrepräsentationen erfolgt im Wesentlichen unüberwacht, jedoch werden Zielwerte/Labels benötigt, um das Modell zu trainieren. Skip-Gram und CBOW wandeln die unüberwachte Repräsentation in eine überwachte Form für das Modelltraining um.
In CBOW wird das aktuelle Wort anhand des Fensters der umgebenden Kontextfenster vorhergesagt. Wenn beispielsweise wi-1, Wi-2, Wi + 1, Wi + 2 Werden Wörter oder Kontext angegeben, liefert dieses Modell wi.
Skip-Gram macht das Gegenteil von CBOW, was bedeutet, dass es die gegebene Sequenz oder den Kontext anhand des Wortes vorhersagt. Man kann das Beispiel umkehren, um es zu verstehen. Wenn wi Wenn dies gegeben ist, wird der Kontext vorhergesagt, oder wi-1, Wi-2, Wi + 1, Wi + 2.
Word2vec bietet die Möglichkeit, zwischen CBOW (Continuous Bag of Words) und Skip-Gram zu wählen. Diese Parameter werden während des Modelltrainings angegeben. Optional kann Negative Sampling oder eine hierarchische Softmax-Schicht verwendet werden.
Kontinuierliche Tasche von Wörtern
Um die Architektur des kontinuierlichen Bag-of-Words zu verstehen, zeichnen wir ein einfaches Word2vec-Beispieldiagramm.

Lassen Sie uns die Gleichungen mathematisch berechnen. Angenommen, V ist die Vokabulargröße und N die Größe der verborgenen Ebene. Die Eingabe ist definiert als { xi-1, Xi-2, Xi + 1, Xi + 2 Die Gewichtsmatrix erhalten wir durch Multiplikation von V * N. Eine weitere Matrix ergibt sich durch Multiplikation des Eingangsvektors mit der Gewichtsmatrix. Dies lässt sich auch anhand der folgenden Gleichung veranschaulichen.
h = xitW
wo xit und W sind der Eingangsvektor bzw. die Gewichtsmatrix.
Zur Berechnung der Übereinstimmung zwischen Kontext und nächstem Wort beachten Sie bitte die unten stehende Gleichung.
u = vorhergesagte Darstellung * h
wobei die vorhergesagte Darstellung aus dem Modell in der obigen Gleichung gewonnen wird.
Skip-Gram-Modell
Der Skip-Gram-Ansatz dient dazu, einen Satz anhand eines eingegebenen Wortes vorherzusagen. Um ihn besser zu verstehen, betrachten wir das Diagramm im folgenden Word2vec-Beispiel.

Man kann es als Umkehrung des Continuous Bag of Words-Modells betrachten, bei dem die Eingabe das Wort ist und das Modell den Kontext oder die Wortfolge liefert. Daraus lässt sich schließen, dass das Zielwort als Eingabe dient und die Ausgabeschicht mehrfach repliziert wird, um die gewählte Anzahl an Kontextwörtern zu verarbeiten. Der Fehlervektor aller Ausgabeschichten wird summiert, um die Gewichte mittels Backpropagation anzupassen.
Welches Modell soll man wählen?
CBOW ist um ein Vielfaches schneller als Skip-Gram und liefert eine höhere Frequenzgenauigkeit für häufige Wörter, während Skip-Gram nur wenige Trainingsdaten benötigt und selbst seltene Wörter oder Phrasen korrekt erfasst. Die folgende Tabelle vergleicht beide Architekturen auf einen Blick.
| Aspekt | CBOW | Skip-Gramm |
|---|---|---|
| Prognose | Sagt das Zielwort aus dem Kontext voraus. | Sagt den Kontext anhand des Zielworts voraus |
| Trainingsgeschwindigkeit | Schneller | Langsamer |
| Häufige Wörter | Höhere Genauigkeit | Geringere Genauigkeit |
| Seltene Wörter | Schwächere Repräsentation | Stärkere Vertretung |
| Trainingsdaten | Es werden mehr Daten benötigt. | Funktioniert auch mit weniger Daten |
Die Beziehung zwischen Word2vec und NLTK
NLTK ist das Natürliche Language ToolDas Kit dient der Textvorverarbeitung. Es ermöglicht verschiedene Operationen wie Wortartenbestimmung, Lemmatisierung, Stemming, das Entfernen von Stoppwörtern und seltenen oder wenig verwendeten Wörtern. Es hilft, den Text zu bereinigen und Merkmale aus den relevanten Wörtern zu extrahieren. Word2vec hingegen wird für semantische (zugehörige Elemente) und syntaktische (Sequenz-) Abgleiche verwendet. Mit Word2vec lassen sich ähnliche und unähnliche Wörter finden, die Dimensionalität reduzieren und vieles mehr. Ein weiteres wichtiges Merkmal von Word2vec ist die Umwandlung der höherdimensionalen Textdarstellung in niedrigdimensionale Vektoren.
Wo werden NLTK und Word2vec verwendet?
Wenn man allgemeine Aufgaben wie Tokenisierung, POS-Tagging und Parsing erledigen muss, sollte man NLTK verwenden, während man für die Vorhersage von Wörtern anhand eines Kontextes, Topic Modeling oder Dokumentähnlichkeit Word2vec verwenden sollte.
Beziehung von NLTK und Word2vec mit Hilfe von Code
NLTK und Word2vec können gemeinsam verwendet werden, um ähnliche Wortrepräsentationen oder syntaktische Übereinstimmungen zu finden. Mit dem NLTK-Toolkit lassen sich viele der mit NLTK mitgelieferten Pakete laden, und mit Word2vec kann ein Modell erstellt werden. Dieses kann anschließend mit Echtzeitwörtern getestet werden. Die Kombination beider Tools wird im folgenden Codebeispiel veranschaulicht. Bevor wir fortfahren, werfen Sie bitte einen Blick auf die von NLTK bereitgestellten Korpora. Sie können diese mit folgendem Befehl herunterladen:
nltk(nltk.download('all'))

Den Code finden Sie im Screenshot.
import nltk import gensim from nltk.corpus import abc model = gensim.models.Word2Vec(abc.sents()) X = list(model.wv.vocab) data = model.most_similar('science') print(data)

Ausgang:
[('law', 0.9415997266769409), ('practice', 0.9276568293571472), ('discussion', 0.9259148836135864), ('agriculture', 0.9257254004478455), ('media', 0.9232194423675537), ('policy', 0.922248125076294), ('general', 0.9166069030761719), ('undertaking', 0.916458249092102), ('tight', 0.9129181504249573), ('board', 0.9107444286346436)]
Erklärung von Code
- Die nltk-Bibliothek wird importiert; von dort können Sie den abc-Korpus herunterladen, den wir im nächsten Schritt verwenden werden.
- Gensim wurde importiert. Falls Gensim Word2vec nicht installiert ist, installieren Sie es bitte mit dem Befehl „pip3 install gensim“. Siehe dazu den folgenden Screenshot.

- Importieren Sie den abc-Korpus, der mit nltk.download('abc') heruntergeladen wurde.
- Übergeben Sie die Dateien als Sätze an das Word2vec-Modell, das mit Gensim importiert wird.
- Der Wortschatz wird in Form einer Variablen gespeichert.
- Das Modell wird anhand des Beispielwortes getestet. Wissenschaftda diese Dateien mit Wissenschaft in Zusammenhang stehen.
- Hier wird das ähnliche Wort „Wissenschaft“ vom Modell vorhergesagt.
Aktivatoren und Word2Vec
Die Aktivierungsfunktion eines Neurons definiert dessen Ausgabe bei gegebenen Eingangssignalen. Sie ist biologisch von der Aktivität in unserem Gehirn inspiriert, wo verschiedene Neuronen durch unterschiedliche Reize aktiviert werden. Das folgende Diagramm veranschaulicht die Aktivierungsfunktion.

Hierbei sind x1, x2, … x4 die Knoten des neuronalen Netzes.
w1, w2, w3 sind die Gewichte der Knoten.
Die Summe (Σ) aller Gewichte und Knotenwerte dient als Aktivierungsfunktion.
Warum Aktivierungsfunktion?
Wird keine Aktivierungsfunktion verwendet, ist der Output linear, die Funktionalität einer linearen Funktion ist jedoch begrenzt. Um komplexe Funktionalitäten wie Objekterkennung, Bildklassifizierung usw. zu erreichen, …ping Für die Textverarbeitung mittels Sprache und viele andere nichtlineare Ausgaben wird eine Aktivierungsfunktion benötigt.
Wie die Aktivierungsschicht bei der Worteinbettung berechnet wird (Word2vec)
Die Softmax-Schicht (normalisierte Exponentialfunktion) ist die Ausgabeschichtfunktion, die jeden Knoten aktiviert. Ein anderer Ansatz ist die hierarchische Softmax-Funktion, deren Komplexität mit O(log) berechnet wird.2Bei Softmax ist die Komplexität O(V), wobei V die Vokabulargröße ist. Der Unterschied liegt in der reduzierten Komplexität der hierarchischen Softmax-Schicht. Um die Funktionsweise zu verstehen, betrachten Sie bitte das folgende Beispiel für Word Embedding:

Angenommen, wir möchten die Wahrscheinlichkeit der Beobachtung des Wortes berechnen liebe Bei einem bestimmten Kontext verläuft der Datenfluss von der Wurzel zum Blattknoten zuerst zu Knoten 2 und dann zu Knoten 5. Bei einer Vokabulargröße von 8 sind also nur drei Berechnungen erforderlich. Dies ermöglicht die Zerlegung der Wahrscheinlichkeitsberechnung für ein einzelnes Wort.liebe).
Welche anderen Optionen stehen außer Hierarchical Softmax zur Verfügung?
Im Allgemeinen stehen folgende Wort-Embedding-Optionen zur Verfügung: Differentiated Softmax, CNN-Softmax, Importance Sampling, Adaptive Importance Sampling, Noise Contrastive Estimation, Negative Sampling, Self-Normalization und Infrequent Normalization.
Um es speziell mit Word2vec zu sagen: Wir haben negatives Sampling zur Verfügung.
Negatives Sampling ist eine Methode zur Stichprobenentnahme aus den Trainingsdaten. Es ähnelt dem stochastischen Gradientenabstieg, weist aber einige Unterschiede auf. Negatives Sampling sucht ausschließlich nach negativen Trainingsbeispielen. Es basiert auf kontrastiver Rauschschätzung und wählt zufällig Wörter aus, die nicht im Kontext vorkommen. Es ist eine schnelle Trainingsmethode und wählt den Kontext zufällig. Wenn das vorhergesagte Wort im zufällig gewählten Kontext vorkommt, liegen die beiden Vektoren nahe beieinander.
Welche Schlussfolgerung lässt sich ziehen?
Aktivatoren regen Neuronen an, ähnlich wie unsere Neuronen durch externe Reize aktiviert werden. Die Softmax-Schicht ist eine der Ausgabeschichtfunktionen, die bei Wortvektoren die Neuronen aktiviert. In Word2vec stehen Optionen wie hierarchisches Softmax und Negative Sampling zur Verfügung. Mithilfe von Aktivatoren lässt sich eine lineare Funktion in eine nichtlineare Funktion umwandeln, und komplexe Algorithmen des maschinellen Lernens können mit solchen Funktionen implementiert werden.
Was ist Gensim?
Gensim ist ein Open-Source-Toolkit zur Themenmodellierung und Verarbeitung natürlicher Sprache, das in implementiert ist Python und Cython. Das Gensim-Toolkit ermöglicht es Benutzern, Word2vec für die Themenmodellierung zu importieren, um verborgene Strukturen im Textkörper aufzudecken. Gensim bietet neben einer Implementierung von Word2vec auch Doc2vec und FastText.
Dieser Abschnitt konzentriert sich auf Word2vec, daher bleiben wir beim Thema.
So implementieren Sie Word2vec mit Gensim
Bis jetzt haben wir besprochen, was Word2vec ist, seine verschiedenen Architekturen, warum es einen Wechsel von einem Bag-of-Words-Modell zu Word2vec gibt, die Beziehung zwischen Word2vec und NLTK mit Live-Code sowie Aktivierungsfunktionen.
Nachfolgend finden Sie die schrittweise Anleitung zur Implementierung von Word2vec mit Gensim:
Schritt 1) Datenerfassung
Der erste Schritt bei der Implementierung eines jeden Modells für maschinelles Lernen oder bei der Verarbeitung natürlicher Sprache ist die Datenerfassung.
Bitte beachten Sie die Daten, um einen intelligenten Chatbot zu erstellen, wie im folgenden Gensim Word2vec-Beispiel gezeigt.
[{"tag": "welcome",
"patterns": ["Hi", "How are you", "Is any one to talk?", "Hello", "hi are you available"],
"responses": ["Hello, thanks for contacting us", "Good to see you here", "Hi there, how may I assist you?"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "I will come back soon"],
"responses": ["See you later, thanks for visiting", "have a great day ahead", "Wish you Come back again soon."]
},
{"tag": "thankful",
"patterns": ["Thanks for helping me", "Thank your guidance", "That's helpful and kind from you"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "It is my duty to help you"]
},
{"tag": "hoursopening",
"patterns": ["What hours are you open?", "Tell your opening time?", "When are you open?", "Just your timing please"],
"responses": ["We're open every day 8am-7pm", "Our office hours are 8am-7pm every day", "We open office at 8 am and close at 7 pm"]
},
{"tag": "payments",
"patterns": ["Can I pay using credit card?", "Can I pay using Mastercard?", "Can I pay using cash only?"],
"responses": ["We accept VISA, Mastercard and credit card", "We accept credit card, debit cards and cash. Please don't worry"]
}
]
Folgendes lässt sich aus den Daten ableiten:
- Diese Daten enthalten drei Dinge: Tag, Muster und Antworten. Der Tag ist die Absicht (das Thema der Diskussion).
- Die Daten liegen im JSON-Format vor.
- Ein Muster ist eine Frage, die Benutzer dem Bot stellen.
- Antworten sind die Rückmeldungen, die der Chatbot auf die entsprechende Frage/das entsprechende Fragemuster gibt.
Schritt 2) Datenvorverarbeitung
Es ist sehr wichtig, die Rohdaten zu verarbeiten. Wenn der Maschine bereinigte Daten zugeführt werden, reagiert das Modell genauer und lernt die Daten effizienter.
Dieser Schritt umfasst das Entfernen von Stoppwörtern, Stemming, unnötigen Wörtern usw. Bevor Sie fortfahren, ist es wichtig, die Daten zu laden und in einen Dataframe umzuwandeln. Den entsprechenden Code finden Sie unten.
import json json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f)
Erklärung von Code:
- Da die Daten im JSON-Format vorliegen, wird JSON importiert.
- Die Datei ist in der Variablen gespeichert.
- Die Datei wird geöffnet und in die Datenvariable geladen.
Die Daten sind nun importiert und müssen in einen Dataframe umgewandelt werden. Den nächsten Schritt finden Sie im folgenden Code.
import pandas as pd df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join)
Erklärung von Code:
1. Die Daten werden mithilfe von pandas, das oben importiert wurde, in einen Dataframe umgewandelt.
2. Es wandelt die Liste in den Spaltenmustern in eine Zeichenkette um.
from nltk.corpus import stopwords from textblob import Word stop = stopwords.words('english') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
Code Erläuterung:
1. Englische Stoppwörter werden mithilfe des Stoppwortmoduls aus dem NLTK-Toolkit importiert.
2. Alle Wörter des Textes werden mithilfe einer for-Schleife und einer Lambda-Funktion in Kleinbuchstaben umgewandelt. Lambda-Funktion ist eine anonyme Funktion.
3. Alle Zeilen des Textes im Datenrahmen werden auf Zeichenketten-Interpunktion überprüft und diese werden herausgefiltert.
4. Zeichen wie Zahlen oder Punkte werden mithilfe eines regulären Ausdrucks entfernt.
5. Digits werden aus dem Text entfernt.
6. Stoppwörter werden zu diesem Zeitpunkt entfernt.
7. Nun werden die Wörter gefiltert und verschiedene Formen desselben Wortes mithilfe der Lemmatisierung entfernt. Damit ist die Datenvorverarbeitung abgeschlossen.
Ausgang:
, patterns, responses, tag 0,hi one talk hello hi available,"['Hello, thanks for contacting us', 'Good to see you here', ' Hi there, how may I assist you?']",welcome 1,bye see later goodbye come back soon,"['See you later, thanks for visiting', 'have a great day ahead', 'Wish you Come back again soon.']",goodbye 2,thanks helping thank guidance thats helpful kind,"['Happy to help!', 'Any time!', 'My pleasure', 'It is my duty to help you']",thankful 3,hour open tell opening time open timing please,"[""We're open every day 8am-7pm"", 'Our office hours are 8am-7pm every day', 'We open office at 8 am and close at 7 pm']",hoursopening 4,pay using credit card pay using mastercard pay using cash,"['We accept VISA, Mastercard and credit card', 'We accept credit card, debit cards and cash. Please dont worry']",payments
Schritt 3) Aufbau eines neuronalen Netzwerks mit Word2vec
Jetzt ist es an der Zeit, ein Modell mit dem Gensim-Modul Word2vec zu erstellen. Dazu müssen wir Word2vec aus Gensim importieren. Tun wir das, erstellen wir das Modell und überprüfen es abschließend anhand von Echtzeitdaten.
from gensim.models import Word2Vec
Nun können wir das Modell erfolgreich mit Word2Vec erstellen. Die nächste Codezeile zeigt, wie das geht. Da der Text dem Modell als Liste übergeben wird, konvertieren wir ihn mithilfe des folgenden Codes aus dem Dataframe in eine Liste.
Bigger_list = [] for i in df['patterns']: li = list(i.split("")) Bigger_list.append(li) Model = Word2Vec(Bigger_list, min_count=1, size=300, workers=4)
Erklärung von Code:
1. Es wurde die Liste „bigger_list“ erstellt, an die die innere Liste angehängt wird. Dies ist das Format, das dem Modell Word2Vec übergeben wird.
2. Es wird eine Schleife implementiert, und jeder Eintrag der Spalte „patterns“ des Datenrahmens wird durchlaufen.
3. Jedes Element der Spaltenmuster wird aufgeteilt und in der inneren Liste li gespeichert.
4. Die innere Liste wird an die äußere Liste angehängt.
5. Diese Liste wird dem Word2Vec-Modell bereitgestellt. Lassen Sie uns einige der hier angegebenen Parameter erläutern.
Min_count: Es ignoriert alle Wörter, deren Gesamthäufigkeit darunter liegt.
Größe Es gibt die Dimensionalität der Wortvektoren an.
Arbeitskräfte: Dies sind die Threads, um das Modell zu trainieren.
Es stehen auch andere Optionen zur Verfügung, von denen einige wichtige im Folgenden erläutert werden.
Fenster: Maximaler Abstand zwischen dem aktuellen und dem vorhergesagten Wort innerhalb eines Satzes.
Sg: Es handelt sich um einen Trainingsalgorithmus: 1 für Skip-Gram und 0 für einen kontinuierlichen Bag-of-Words-Ansatz. Wir haben dies oben ausführlich besprochen.
Hs: Ist der Wert 1, verwenden wir hierarchisches Softmax für das Training; ist er 0, wird Negative Sampling verwendet.
Alpha: Anfängliche Lernrate.
Lassen Sie uns den endgültigen Code unten anzeigen:
# list of libraries used by the code import string from gensim.models import Word2Vec import logging from nltk.corpus import stopwords from textblob import Word import json import pandas as pd # data in json format json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f) # displaying the list of stopwords stop = stopwords.words('english') # dataframe df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join) # cleaning the data using the NLP approach print(df) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()])) # taking the outer list bigger_list = [] for i in df['patterns']: li = list(i.split(" ")) bigger_list.append(li) # structure of data to be taken by the model.word2vec print("Data format for the overall list:", bigger_list) # custom data is fed to machine for further processing model = Word2Vec(bigger_list, min_count=1, size=300, workers=4)
Schritt 4) Modellspeicherung
Das Modell kann als Binärdatei und als Modelldatei gespeichert werden. Bin ist das Binärformat. Die folgenden Zeilen beschreiben, wie Sie das Modell speichern.
model.save("word2vec.model") model.save("model.bin")
Erläuterung des obigen Codes
1. Das Modell wird in Form einer .model-Datei gespeichert.
2. Das Modell wird in Form einer .bin-Datei gespeichert.
Wir werden dieses Modell für Echtzeittests verwenden, z. B. für ähnliche Wörter, unähnliche Wörter und die häufigsten Wörter.
Schritt 5) Modell laden und Echtzeittests durchführen
Das Modell wird mit dem folgenden Code geladen:
model = Word2Vec.load('model.bin')
Wenn Sie den Wortschatz daraus ausdrucken möchten, verwenden Sie dazu den folgenden Befehl:
vocab = list(model.wv.vocab)
Bitte sehen Sie sich das Ergebnis an:
['see', 'thank', 'back', 'thanks', 'soon', 'open', 'mastercard', 'card', 'time', 'pay', 'talk', 'cash', 'one', 'please', 'goodbye', 'thats', 'helpful', 'hour', 'credit', 'hi', 'later', 'guidance', 'opening', 'timing', 'hello', 'helping', 'bye', 'tell', 'come', 'using', 'kind', 'available']
Schritt 6) Überprüfung der ähnlichsten Wörter
Lassen Sie uns die Dinge praktisch umsetzen:
similar_words = model.most_similar('thanks') print(similar_words)
Bitte sehen Sie sich das Ergebnis an:
[('kind', 0.16104359924793243), ('using', 0.1352398842573166), ('come', 0.11500970274209976), ('later', 0.09989878535270691), ('helping', 0.04855936020612717), ('credit', 0.04659383371472359), ('pay', 0.0329081267118454), ('thank', 0.02484947443008423), ('hour', 0.0202352125197649), ('opening', 0.018177658319473267)]
Schritt 7) Entspricht keinem der angegebenen Wörter
dissimlar_words = model.doesnt_match('See you later, thanks for visiting'.split()) print(dissimlar_words)
Wir haben die Worte geliefert „Bis später, danke für Ihren Besuch.“Dieser Code gibt das unähnlichste Wort aus. Führen wir ihn aus und sehen wir uns das Ergebnis an.
Das Ergebnis nach Ausführung des obigen Codes:
Thanks
Schritt 8) Finden der Ähnlichkeit zwischen zwei Wörtern
Dies gibt das Ergebnis in Form der Ähnlichkeitswahrscheinlichkeit zwischen zwei Wörtern an. Im folgenden Codebeispiel wird die Ausführung dieses Abschnitts erläutert.
similarity_two_words = model.similarity('please', 'see') print("Please provide the similarity between these two words:") print(similarity_two_words)
Das Ergebnis des obigen Codes ist wie folgt:
0.13706
Sie können weitere ähnliche Wörter finden, indem Sie den folgenden Code ausführen:
similar = model.similar_by_word('kind') print(similar)
Ausgabe des obigen Codes:
[('credit', 0.11764447391033173), ('cash', 0.11440904438495636), ('one', 0.11151769757270813), ('hour', 0.0944807156920433), ('using', 0.0705675333738327), ('thats', 0.05206916481256485), ('later', 0.04502468928694725), ('bye', 0.03960943967103958), ('back', 0.03837274760007858), ('thank', 0.0380823090672493)]