Матрица корреляций Пирсона и Спирмена в R с примером
⚡ Умное резюме
Корреляция Пирсона и Спирмена в R измеряет, насколько сильно две переменные взаимосвязаны, используя функцию cor() для одной пары и корреляционную матрицу для множества пар. В этом пошаговом руководстве добавлена проверка значимости с помощью Hmisc и визуализация результатов с помощью тепловых карт GGally.

Двумерная корреляция в R
Двумерная связь описывает связь или корреляцию между двумя переменными в R. В этом уроке мы обсудим концепцию корреляции и покажем, как ее можно использовать для измерения взаимосвязи между любыми двумя переменными в R.
Корреляция в программировании на R
Существует два основных метода вычисления корреляции между двумя переменными в программировании на R:
- Pearson: Параметрическая корреляция
- копьеносец: Непараметрическая корреляция
Матрица корреляции Пирсона в R
Метод корреляции Пирсона обычно используется в качестве первичной проверки связи между двумя переменными.
коэффициент корреляции, обозначаемая буквой r, измеряет силу линейный Взаимосвязь между двумя переменными x и y вычисляется следующим образом:
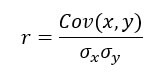
с
 является стандартным отклонением x
является стандартным отклонением x — это стандартное отклонение y.
— это стандартное отклонение y.
Корреляция находится в диапазоне от -1 до 1.
- Значение r, близкое к 0 или равное ему, означает слабую или полное отсутствие линейной зависимости между x и y.
- Чем ближе r к 1 или -1, тем сильнее линейная зависимость.
Проверить, отличается ли r от нуля, можно с помощью приведенной ниже t-статистики, сравнив ее с распределением Стьюдента с n – 2 степенями свободы:
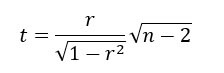
Ранговая корреляция Спирмена в R
Ранговая корреляция сортирует наблюдения по рангу и вычисляет степень сходства между рангами. Преимущество ранговой корреляции заключается в её устойчивости к выбросам и отсутствии зависимости от распределения данных. Ранговая корреляция также является оптимальным выбором для порядковых переменных.
Коэффициент ранговой корреляции Спирмена, обозначаемый как ро, также изменяется от -1 до 1, и значения, близкие к любому из крайних значений, указывают на сильную монотонную зависимость. Он вычисляется следующим образом:
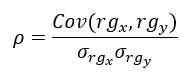
В числителе представлена ковариация между рангами x и y, а в знаменателе — произведение их стандартных отклонений.
В R оба параметра вычисляются с помощью функции cor(), которая принимает три аргумента: x, y и method.
cor(x, y, method)
аргументы:
- x: Первый вектор
- y: Второй вектор
- метод: формула, используемая для расчета корреляции. Три строковых значения:
- «груша»
- «Кендалл»
- «копейщик»
Можно добавить необязательный аргумент, если векторы содержат пропущенное значение: use = «complete.obs»
Мы будем использовать набор данных BudgetUK. В этом наборе данных показано распределение бюджетов британских домохозяйств в период с 1980 по 1982 год. Имеется 1519 наблюдений с десятью характеристиками, среди которых:
- еда: поделиться едой, поделиться расходами
- wтопливо: поделиться расходом топлива
- ткань: доля бюджета на расходы на одежду
- ходить: поделиться расходами на алкоголь
- втранс: разделить расходы на транспорт
- вопрос: доля расходов на другие товары
- тотэксп: общие расходы домохозяйства в фунтах
- доход: общий чистый доход домохозяйства
- возраст: возраст семьи
- дети: Число детей
Пример
library(dplyr) PATH <- "https://raw.githubusercontent.com/guru99-edu/R-Programming/master/british_household.csv" data <- read.csv(PATH) %>% filter(income < 500) %>% mutate(log_income = log(income), log_totexp = log(totexp), children_fac = factor(children, order = TRUE, labels = c("No", "Yes"))) %>% select(-c(X, X.1, children, totexp, income)) glimpse(data)
Code объяснение
- Сначала мы импортируем данные и проверяем их с помощью функции проблеска() из библиотеки dplyr.
- Три домохозяйства сообщают о доходе в 500 или более, поэтому фильтр (доход < 500) удаляет их, и количество строк сокращается с 1,519 до 1,516.
- Обычной практикой является преобразование денежной переменной в логарифм. Это помогает уменьшить влияние выбросов и уменьшает асимметрию набора данных.
Выход:
## Observations: 1,516 ## Variables: 10 ## $ wfood <dbl> 0.4272, 0.3739, 0.1941, 0.4438, 0.3331, 0.3752, 0... ## $ wfuel <dbl> 0.1342, 0.1686, 0.4056, 0.1258, 0.0824, 0.0481, 0... ## $ wcloth <dbl> 0.0000, 0.0091, 0.0012, 0.0539, 0.0399, 0.1170, 0... ## $ walc <dbl> 0.0106, 0.0825, 0.0513, 0.0397, 0.1571, 0.0210, 0... ## $ wtrans <dbl> 0.1458, 0.1215, 0.2063, 0.0652, 0.2403, 0.0955, 0... ## $ wother <dbl> 0.2822, 0.2444, 0.1415, 0.2716, 0.1473, 0.3431, 0... ## $ age <int> 25, 39, 47, 33, 31, 24, 46, 25, 30, 41, 48, 24, 2... ## $ log_income <dbl> 4.867534, 5.010635, 5.438079, 4.605170, 4.605170,... ## $ log_totexp <dbl> 3.912023, 4.499810, 5.192957, 4.382027, 4.499810,... ## $ children_fac <ord> Yes, Yes, Yes, Yes, No, No, No, No, No, No, Yes, ...
Мы можем вычислить коэффициент корреляции между переменными дохода и питания с помощью методов «Пирсона» и «Спирмена».
cor(data$log_income, data$wfood, method = "pearson")
Выход:
## [1] -0.2466986
cor(data$log_income, data$wfood, method = "spearman")
Выход:
## [1] -0.2501252
Прежде чем распространять это на каждую пару переменных, стоит уточнить, как следует интерпретировать отдельный коэффициент.
Как интерпретировать коэффициент корреляции
Коэффициент полезен только тогда, когда можно объяснить, что он означает. Приведенные ниже полосы представляют собой общепринятые значения, а знак считывается отдельно от интенсивности.
| Абсолютное значение r | Прочность отношений |
|---|---|
| 0.00 - 0.19 | Очень слабое или полное отсутствие |
| 0.20 - 0.39 | Слабый |
| 0.40 - 0.59 | Средняя |
| 0.60 - 0.79 | сильный |
| 0.80 - 1.00 | Очень сильный |
Таким образом, вычисленное ранее значение -0.2467 между log_income и wfood указывает на слабую отрицательную взаимосвязь: более обеспеченные домохозяйства тратят на продукты питания несколько меньшую долю своего бюджета.
К каждому коэффициенту следует отнестись с осторожностью в трех случаях.
- Корреляция - это не причинная связь. Высокий коэффициент корреляции r указывает на то, что две переменные движутся синхронно, но никогда не на то, что одна является причиной другой. Третья, неизмеренная переменная часто влияет на обе переменные.
- Пирсон видит только прямые линии. Идеальная U-образная зависимость дает коэффициент корреляции r, близкий к нулю. Всегда стройте график данных, прежде чем доверять полученным значениям.
- Размер важнее значимости. При наличии 1,516 наблюдений коэффициент 0.06 может быть статистически значимым, но при этом практически бессмысленным.
Как проверить значимость корреляции с помощью функции cor.test()
Функция cor() возвращает коэффициент и ничего больше. Для одной пары значений cor.test() суммирует p-значение и доверительный интервал за один вызов.
cor.test(data$log_income, data$wfood, method = "pearson")
Данный документ состоит из четырех частей, которые стоит прочитать.
- т и df: тестовая статистика и число степеней свободы, n – 2.
- р-значение: вероятность увидеть коэффициент такого большого значения, если истинная корреляция равна нулю.
- 95-процентный доверительный интервал: правдоподобный диапазон истинной корреляции. Если он исключает ноль, то взаимосвязь является значимой на этом уровне.
- примерная смета: сам коэффициент, идентичный тому, что возвращает функция cor().
Та же функция выполняет тесты на основе рангов, изменяя всего один аргумент:
# Spearman rank correlation with a p-value cor.test(data$log_income, data$wfood, method = "spearman") # One-sided test: is the correlation greater than zero? cor.test(data$log_income, data$wfood, alternative = "greater")
Когда какой метод использовать. Используйте cor.test() при анализе одной конкретной пары, поскольку она предоставляет доверительный интервал, который не учитывает rcorr(). Используйте rcorr() из Hmisc, показанную выше, когда вам нужны p-значения для всей матрицы сразу. Обратите внимание, что тестирование множества пар увеличивает частоту ложноположительных результатов, поэтому скорректируйте p-значения с помощью p.adjust(p_value, method = “BH”), прежде чем делать выводы на основе большой матрицы.
Корреляционная матрица в R
Двумерная корреляция — это хорошее начало, но многомерный анализ дает более широкую картину. корреляционная матрица Это квадратная таблица, содержащая попарные корреляции каждой переменной относительно каждой другой.
Функция cor() возвращает матрицу корреляции. Единственное отличие от двумерной корреляции заключается в том, что нам не нужно указывать, какие именно переменные. По умолчанию R вычисляет корреляцию между всеми переменными.
Корреляция для фактора вычисляется не может, поэтому удалите все категориальные столбцы перед передачей фрейма данных в функцию cor().
Матрица корреляции симметрична, что означает, что значения выше диагонали имеют те же значения, что и значения ниже. Нагляднее показать половину матрицы.
Функция children_fac исключена, поскольку функция cor() не может работать с фактором.
# the last column of data is a factor level. We don't include it in the code mat_1 <-as.dist(round(cor(data[,1:9]),2)) mat_1
Code объяснение
- cor(data[, 1:9])Вычислите корреляционную матрицу по девяти числовым столбцам.
- округление(…, 2)Округлите каждый коэффициент до двух знаков после запятой.
- as.dist(): Выведите только нижний треугольник, поскольку матрица симметрична.
Выход:
## wfood wfuel wcloth walc wtrans wother age log_income ## wfuel 0.11 ## wcloth -0.33 -0.25 ## walc -0.12 -0.13 -0.09 ## wtrans -0.34 -0.16 -0.19 -0.22 ## wother -0.35 -0.14 -0.22 -0.12 -0.29 ## age 0.02 -0.05 0.04 -0.14 0.03 0.02 ## log_income -0.25 -0.12 0.10 0.04 0.06 0.13 0.23 ## log_totexp -0.50 -0.36 0.34 0.12 0.15 0.15 0.21 0.49
Уровень значимости
Сам по себе коэффициент не говорит о том, является ли взаимосвязь статистически достоверной. Функция rcorr() из библиотеки Hmisc возвращает p-значение для каждой пары. Библиотеку можно скачать по ссылке: Conda и скопируйте код, чтобы вставить его в терминал:
conda install -c r r-hmisc
Функция rcorr() требует, чтобы фрейм данных был сохранен в виде матрицы. Мы можем преобразовать наши данные в матрицу, прежде чем вычислять корреляционную матрицу со значением p.
library("Hmisc") data_rcorr <-as.matrix(data[, 1: 9]) mat_2 <-rcorr(data_rcorr) # mat_2 <-rcorr(as.matrix(data)) returns the same output
Объект списка mat_2 содержит три элемента:
- r: Вывод корреляционной матрицы
- n: Количество наблюдений
- P: p-значение
Нас интересует третий элемент — значение p. Обычно корреляционную матрицу показывают со значением p вместо коэффициента корреляции.
p_value <-round(mat_2[["P"]], 3) p_value
Code объяснение
- mat_2[[“P”]]: значения p хранятся в элементе с именем P.
- раунд(mat_2[[“P”]], 3): округлить элементы с тремя цифрами
Выход:
wfood wfuel wcloth walc wtrans wother age log_income log_totexp wfood NA 0.000 0.000 0.000 0.000 0.000 0.365 0.000 0 wfuel 0.000 NA 0.000 0.000 0.000 0.000 0.076 0.000 0 wcloth 0.000 0.000 NA 0.001 0.000 0.000 0.160 0.000 0 walc 0.000 0.000 0.001 NA 0.000 0.000 0.000 0.105 0 wtrans 0.000 0.000 0.000 0.000 NA 0.000 0.259 0.020 0 wother 0.000 0.000 0.000 0.000 0.000 NA 0.355 0.000 0 age 0.365 0.076 0.160 0.000 0.259 0.355 NA 0.000 0 log_income 0.000 0.000 0.000 0.105 0.020 0.000 0.000 NA 0 log_totexp 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 NA
Визуализация корреляционной матрицы в R
Тепловая карта — ещё один способ анализа корреляционной матрицы. Библиотека GGally расширяет ggplot2 и устанавливается из CRAN, а не из conda:
install.packages("GGally")

Библиотека включает в себя различные функции для отображения сводной статистики, такой как корреляция и распределение всех переменных в таблице. матрица.
Функция ggcorr() имеет множество аргументов. Мы представим только те аргументы, которые будем использовать в уроке:
Функция ggcorr
ggcorr(df, method = c("pairwise", "pearson"), nbreaks = NULL, digits = 2, low = "#3B9AB2", mid = "#EEEEEE", high = "#F21A00", geom = "tile", label = FALSE, label_alpha = FALSE)
Аргументы:
- df: используемый набор данных
- метод: Формула для расчета корреляции. По умолчанию вычисляются попарно и по Пирсону.
- нбрейки: Возвращает категориальный диапазон окраски коэффициентов. По умолчанию разрывов нет, градиент цвета непрерывный.
- цифры: округлить коэффициент корреляции. По умолчанию установлено 2
- низкокачественными: Контролируйте нижний уровень окраски.
- в середине: Контролируйте средний уровень окраски.
- высокая: Контролируйте интенсивность цвета.
- геом: Управляйте формой геометрического аргумента. По умолчанию «плитка»
- этикетка: логическое значение. Отображать или нет метку. По умолчанию установлено значение FALSE.
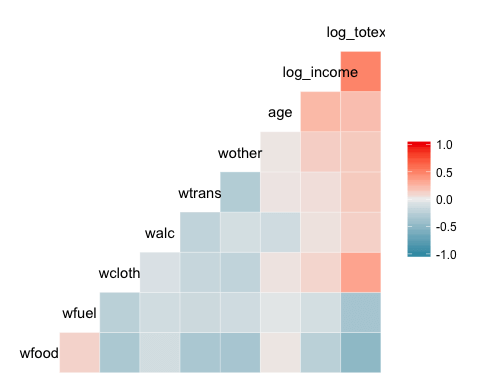
Базовая тепловая карта
Самый основной график пакета — это тепловая карта. Легенда графика показывает градиентный цвет от – 1 до 1, причем горячий цвет указывает на сильную положительную корреляцию, а холодный цвет – на отрицательную корреляцию.
library(GGally) ggcorr(data)
Code объяснение
- ggcorr(данные): необходим только один аргумент — имя фрейма данных. Переменные уровня фактора не включены в график.
Выход:
Добавление контроля к тепловой карте
Мы можем добавить на график больше элементов управления:
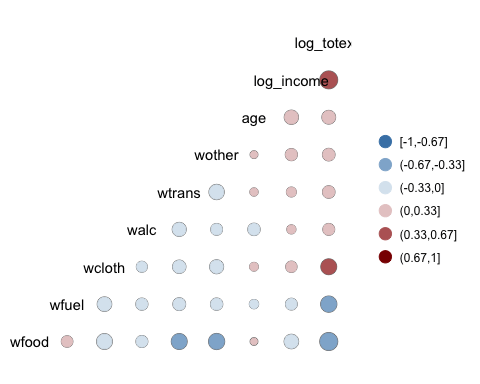
ggcorr(data, nbreaks = 6, low = "steelblue", mid = "white", high = "darkred", geom = "circle")
Code объяснение
- nbreaks=6: разбить легенду с 6 рангами.
- низкий = «стальной синий»: используйте более светлые цвета для отрицательной корреляции.
- середина = «белый»: Используйте белые цвета для корреляции средних диапазонов.
- высокий = «темно-красный»: используйте темные цвета для положительной корреляции.
- геом = «круг»: использовать круг в качестве формы окон на тепловой карте. Размер круга пропорционален абсолютному значению корреляции.
Выход:
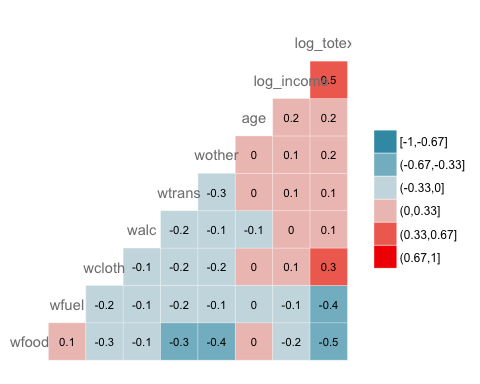
Добавление метки на тепловую карту
GGally позволяет нам добавлять метки внутри окон:
ggcorr(data, nbreaks = 6, label = TRUE, label_size = 3, color = "grey50")
Code объяснение
- метка = ИСТИНА: добавьте значения коэффициентов корреляции внутри тепловой карты.
- цвет = «серый50»: выберите цвет, например серый.
- label_size = 3: Установите размер метки равным 3
Выход:
Функция ggpairs
Библиотека GGally также предоставляет функцию ggpairs(), которая возвращает матрицу графиков. Для k выбранных переменных результатом является сетка размером ak на k: диагональ показывает распределение каждой переменной, а панели выше и ниже диагонали могут содержать разные вычисления. Синтаксис следующий:
ggpairs(df, columns = 1:ncol(df), title = NULL, upper = list(continuous = "cor"), lower = list(continuous = "smooth"), mapping = NULL)
Аргументы:
- df: используемый набор данных
- столбцы: выберите столбцы для построения графика.
- название: Включить заголовок
- верхний: Управление блоками над диагональю графика. Необходимо указать тип вычислений или графика для возврата. Если continuous = “cor”, мы просим R вычислить корреляцию. Обратите внимание, что аргумент должен быть списком. Доступны и другие аргументы; см. Документация GGally чтобы получить больше информации.
- ниже: Управляйте квадратами под диагональю.
- картаping: указывает на эстетику графика. Например, мы можем вычислить график для разных групп.
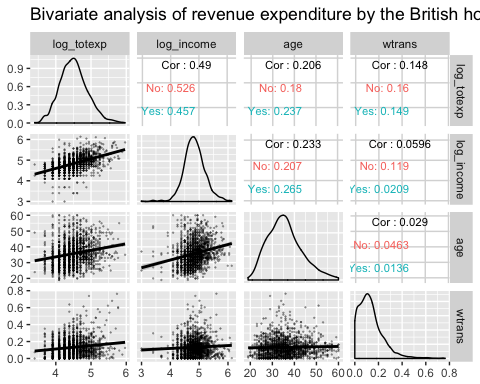
Двумерный анализ с использованием ggpair с группойping
На следующем графике представлены три информации:
- Матрица корреляции между переменными log_totexp, log_income, age и wtrans, сгруппированной по тому, есть ли в семье ребенок или нет.
- Постройте распределение каждой переменной по группам
- Отображение диаграммы рассеяния с тенденцией по группам
library(ggplot2) ggpairs(data, columns = c("log_totexp", "log_income", "age", "wtrans"), title = "Bivariate analysis of revenue expenditure by the British household", upper = list(continuous = wrap("cor", size = 3)), lower = list(continuous = wrap("smooth", alpha = 0.3, size = 0.1)), mapping = aes(color = children_fac))
Code объяснение
- столбцы = c («log_totexp», «log_income», «возраст», «wtrans»): выберите переменные для отображения на графике.
- title = «Двумерный анализ доходов и расходов британской семьи»: Добавить заголовок
- верхний = список(): Управление верхней частью графика. Т.е. выше диагонали
- непрерывный = обертка («кор», размер = 3)): Вычислить коэффициент корреляции. Мы помещаем аргумент Continuous в функцию Wrap(), чтобы контролировать эстетику графика (т.е. размер = 3). -lower = list(): Управляет нижней частью графика. Т.е. ниже диагонали.
- непрерывный = перенос («гладкий», альфа = 0.3, размер = 0.1): добавить диаграмму рассеяния с линейным трендом. Мы обертываем аргумент Continuous внутри функции Wrap(), чтобы контролировать эстетику графика (т. е. размер = 0.1, альфа = 0.3).
- картаping = aes(color = children_fac)Разделите каждую панель по фактору children_fac, который обозначается как «Нет» для домохозяйств без детей и «Да» для домохозяйств с детьми.
Выход:

Двумерный анализ с использованием ggpair с частичной группировкойping
График ниже немного отличается. Мы меняем положение карты.ping внутри верхнего аргумента.
ggpairs(data, columns = c("log_totexp", "log_income", "age", "wtrans"), title = "Bivariate analysis of revenue expenditure by the British household", upper = list(continuous = wrap("cor", size = 3), mapping = aes(color = children_fac)), lower = list( continuous = wrap("smooth", alpha = 0.3, size = 0.1)) )
Code объяснение
- Тот же код, что и в предыдущем примере, за исключением:
- картаping = aes(color = children_fac): Переместить список в верхнюю часть = list(). Нам нужно, чтобы вычисления, сгруппированные по группам, находились только в верхней части графика.
Выход:
Корреляция в R: основные выводы и справочник функций.
- Двумерное отношение описывает взаимосвязь или корреляцию между двумя переменными в R.
- Существует два основных метода вычисления корреляции между двумя переменными в R Программирование: Пирсон и Спирмен.
- Метод корреляции Пирсона обычно используется в качестве первичной проверки связи между двумя переменными.
- Ранговая корреляция сортирует наблюдения по рангу и вычисляет уровень сходства между рангами.
- Коэффициент ранговой корреляции Спирмена варьируется от -1 до 1, и значения, близкие к крайним значениям, указывают на сильную монотонную зависимость.
- Корреляционная матрица — это квадратная таблица, содержащая попарные корреляции каждой переменной.
- Значение p показывает, статистически ли отличается наблюдаемая корреляция от нуля.
Ниже перечислены все функции корреляции, использованные в этом руководстве:
| Библиотека | Цель | Способ доставки | Code |
|---|---|---|---|
| Система исчисления | Бивариантная корреляция | Pearson |
cor(dfx2, method = "pearson") |
| Система исчисления | Бивариантная корреляция | копьеносец |
cor(dfx2, method = "spearman") |
| Система исчисления | Многомерная корреляция | Pearson |
cor(df, method = "pearson") |
| Система исчисления | Многомерная корреляция | копьеносец |
cor(df, method = "spearman") |
| Hразное | Значение P | - |
rcorr(as.matrix(data[,1:9]))[["P"]] |
| ГГалли | Тепловая карта | - |
ggcorr(df)
|
| ГГалли | Матрица многомерных графиков | - |
ggpairs(df, columns = c("x1", "x2")) |