NLTK Tokenize : Tokenizer de mots et de phrases avec exemple
⚡ Résumé intelligent
NLTK Tokenize segmente les textes volumineux en unités plus petites appelées tokens, une étape fondamentale du traitement automatique du langage naturel. La boîte à outils propose word_tokenize pour découper les phrases en mots et sent_tokenize pour diviser le texte en phrases individuelles.

Qu'est-ce que la tokenisation?
tokenization est le processus par lequel une grande quantité de texte est divisée en parties plus petites appelées jetons. Ces jetons sont très utiles pour trouver des modèles et sont considérés comme une étape de base pour la recherche de racines et la lemmatisation. La tokenisation permet également de remplacer les éléments de données sensibles par des éléments de données non sensibles.
Le traitement du langage naturel est utilisé pour créer des applications telles que la classification de texte, chatbot intelligent, analyse sentimentale, traduction linguistique, etc. Il devient essentiel de comprendre le modèle du texte pour atteindre l’objectif indiqué ci-dessus.
Pour le moment, ne vous inquiétez pas de la radicalisation et de la lemmatisation, mais traitez-les comme des étapes de nettoyage des données textuelles à l'aide du NLP (Traitement du langage naturel). Nous discuterons de la radicalisation et de la lemmatisation plus tard dans le didacticiel. Des tâches telles que Classification de texte ou filtrage anti-spam utilise le NLP avec des bibliothèques d'apprentissage en profondeur telles que Keras et Tensorflow.
La boîte à outils de langage naturel contient un module NLTK très important tokenize phrases qui comprennent en outre des sous-modules
- mot tokeniser
- phrase tokeniser
Tokenisation des mots
Nous utilisons la méthode mot_tokenize() diviser une phrase en mots. Le résultat de la tokenisation de mots peut être converti en Data Frame pour une meilleure compréhension du texte dans les applications d'apprentissage automatique. Il peut également être fourni comme entrée pour d'autres étapes de nettoyage de texte telles que la suppression de la ponctuation, la suppression des caractères numériques ou la recherche de radicaux. Les modèles d'apprentissage automatique ont besoin de données numériques pour être entraînés et effectuer une prédiction. La tokenisation des mots devient une partie cruciale de la conversion du texte (chaîne) en données numériques. Veuillez lire à propos de Sac de mots ou CountVectorizer. Veuillez vous référer à l'exemple de tokenisation de mots NLTK ci-dessous pour mieux comprendre la théorie.
from nltk.tokenize import word_tokenize text = "God is Great! I won a lottery." print(word_tokenize(text)) Output: ['God', 'is', 'Great', '!', 'I', 'won', 'a', 'lottery', '.']
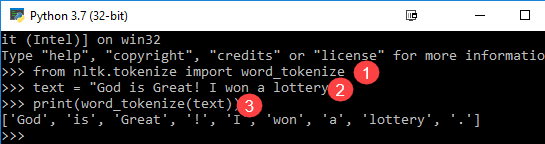
Code Explication
- Le module word_tokenize est importé de la bibliothèque NLTK.
- Une variable « texte » est initialisée avec deux phrases.
- La variable texte est transmise dans le module word_tokenize et affiche le résultat. Ce module divise chaque mot avec une ponctuation que vous pouvez voir dans la sortie.
Tokenisation des phrases
Le sous-module disponible pour ce qui précède est sent_tokenize. Une question évidente dans votre esprit serait pourquoi la tokenisation des phrases est nécessaire alors que nous avons la possibilité de tokeniser les mots. Imaginez que vous deviez compter la moyenne des mots par phrase, comment allez-vous calculer ? Pour accomplir une telle tâche, vous avez besoin à la fois d'un tokenizer de phrases NLTK et d'un tokenizer de mots NLTK pour calculer le rapport. Une telle sortie constitue une fonctionnalité importante pour la formation des machines, car la réponse serait numérique.
Consultez l'exemple de tokeniseur NLTK ci-dessous pour savoir en quoi la tokenisation des phrases est différente de la tokenisation des mots.
from nltk.tokenize import sent_tokenize text = "God is Great! I won a lottery." print(sent_tokenize(text)) Output: ['God is Great!', 'I won a lottery ']
Nous avons 12 mots et deux phrases pour la même entrée.
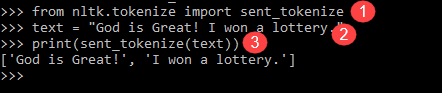
Explication du programme
- Dans une ligne comme le programme précédent, importé le module sent_tokenize.
- Nous avons repris la même phrase. Un autre tokenizer de phrases dans le module NLTK a analysé ces phrases et affiché la sortie. Il est clair que cette fonction casse chaque phrase.
Au-dessus du tokenizer de mots Python des exemples sont de bonnes pierres de réglage pour comprendre les mécanismes de tokenisation des mots et des phrases.