Intégration de mots et Word2Vec avec exemple
⚡ Résumé intelligent
Word Embedding et Word2Vec transforment le texte en vecteurs numériques denses, permettant ainsi aux modèles d'apprentissage automatique de reconnaître les mots de sens similaire. Cette ressource explique la technique, ses architectures CBOW et Skip-Gram, ses fonctions d'activation et propose une implémentation complète dans Gensim pour des applications concrètes.
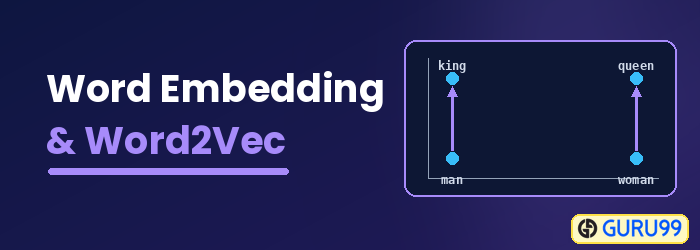
Qu’est-ce que l’intégration de mots ?
Incorporation de mots est un type de représentation de mots qui permet aux algorithmes d'apprentissage automatique de comprendre les mots ayant des significations similaires. Il s'agit d'une technique de modélisation du langage et d'apprentissage de caractéristiques permettant de transformer les mots en vecteurs de nombres réels à l'aide de réseaux neuronaux, de modèles probabilistes ou de la réduction de dimension sur la matrice de cooccurrence des mots. Parmi les modèles d'intégration de mots, on trouve Word2vec (Google), GloVe (Stanford) et fastText (Facebook).
L'intégration de mots est également appelée modèle sémantique distribué, modèle de représentation distribué, espace vectoriel sémantique ou modèle vectoriel. En lisant ces noms, vous rencontrez le mot sémantiqueCela consiste à regrouper les mots similaires. Par exemple, les fruits comme la pomme, la mangue et la banane seront placés côte à côte, tandis que les livres seront éloignés de ces mots. Plus généralement, l'intégration de mots crée un vecteur de fruits éloigné de la représentation vectorielle des livres.
Où l’intégration de mots est-elle utilisée ?
L'intégration de mots facilite la génération de caractéristiques, le regroupement de documents, la classification de textes et le traitement automatique du langage naturel. Examinons ces applications et détaillons-les.
- Calculez des mots similaires : L'intégration de mots permet de suggérer des mots similaires au mot soumis au modèle de prédiction. Elle suggère également des mots différents, ainsi que les mots les plus fréquents.
- Créez un groupe de mots apparentés : Il est utilisé pour les groupes sémantiquesping, qui regroupe les éléments ayant des caractéristiques similaires et éloigne les éléments dissemblables.
- Fonctionnalité de classification de texte : Le texte est transformé en tableaux de vecteurs qui servent à l'entraînement et à la prédiction du modèle. Les modèles de classification textuelle ne peuvent pas être entraînés sur des chaînes de caractères ; cette méthode convertit donc le texte en un format exploitable par la machine. Ses fonctionnalités de construction sémantique facilitent la classification textuelle.
- Regroupement de documents : Voici une autre application où l'intégration de mots et Word2vec sont largement utilisés.
- Traitement du langage naturel: Il existe de nombreuses applications où l'intégration de mots est utile et surpasse l'extraction de caractéristiques.tracphases de tion, telles que l'étiquetage morphosyntaxique, l'analyse des sentiments et l'analyse syntaxique.
Maintenant que vous comprenez où s'applique l'intégration de mots, examinons le modèle le plus populaire utilisé pour créer ces intégrations.
Qu’est-ce que Word2vec ?
Mot2vec Il s'agit d'une technique ou d'un modèle qui produit des plongements lexicaux pour une meilleure représentation des mots. C'est une méthode de traitement automatique du langage naturel qui capture un grand nombre de relations syntaxiques et sémantiques précises entre les mots. C'est un réseau neuronal superficiel à deux couches qui, une fois entraîné, peut détecter les synonymes et suggérer des mots supplémentaires pour compléter des phrases incomplètes.
Avant d'aller plus loin, veuillez consulter la différence entre un réseau neuronal superficiel et un réseau neuronal profond, comme illustré dans l'exemple de diagramme d'intégration de mots ci-dessous :
Un réseau de neurones superficiel ne comporte qu'une seule couche cachée entre l'entrée et la sortie, tandis qu'un réseau de neurones profond en contient plusieurs. L'entrée est traitée par des nœuds, tandis que la couche cachée, ainsi que la couche de sortie, contiennent des neurones.
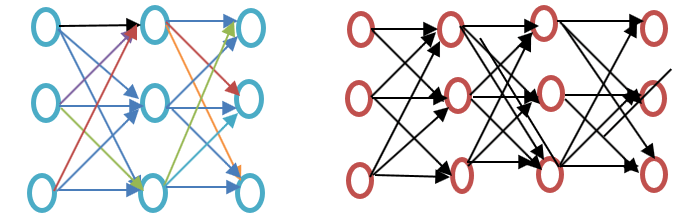
Word2vec est un réseau à deux couches comprenant une couche d'entrée, une couche cachée et une couche de sortie.
Word2vec a été développé par un groupe de chercheurs dirigé par Tomas Mikolov à GoogleWord2vec est meilleur et plus efficace que le modèle d'analyse sémantique latente.
Pourquoi Word2vec ?
Word2vec représente les mots dans un espace vectoriel. Les mots sont représentés sous forme de vecteurs, et leur placement est effectué de telle sorte que les mots de sens similaire apparaissent ensemble et que les mots de sens différent soient éloignés. On parle alors de relation sémantique. Les réseaux de neurones ne comprennent pas le texte ; ils ne comprennent que les nombres. L’intégration de mots permet de convertir un texte en un vecteur numérique.
Word2vec reconstruit le contexte linguistique des mots. Avant d'aller plus loin, comprenons ce qu'est le contexte linguistique. De manière générale, lorsque nous parlons ou écrivons pour communiquer, nos interlocuteurs cherchent à déduire l'objectif de la phrase. Par exemple : « Quelle est la température en Inde ? » Ici, le contexte indique que l'utilisateur souhaite connaître la « température de l'Inde ». En bref, l'objectif principal d'une phrase est son contexte. Les mots ou les phrases qui entourent le langage parlé ou écrit contribuent à déterminer le sens du contexte. Word2vec apprend la représentation vectorielle des mots grâce à ces contextes.
Que fait Word2vec ?
Avant l'intégration de mots
Il est important de connaître l'approche utilisée avant l'intégration de mots et ses limites. Nous verrons ensuite comment l'intégration de mots, grâce à l'approche Word2vec, permet de surmonter ces limitations. Enfin, nous expliquerons le fonctionnement de Word2vec, car il est essentiel de le comprendre.
Approche pour l'analyse sémantique latente
Cette approche, antérieure aux plongements lexicaux, repose sur le concept de « sac de mots », où les mots sont représentés par des vecteurs encodés. Il s'agit d'une représentation vectorielle creuse dont la dimension est égale à la taille du vocabulaire. Si le mot figure dans le dictionnaire, il est comptabilisé ; sinon, il est ignoré. Pour en savoir plus, veuillez consulter le programme ci-dessous.
Exemple Word2vec

from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() data_corpus = ["guru99 is the best site for online tutorials. I love to visit guru99."] vocabulary = vectorizer.fit(data_corpus) X = vectorizer.transform(data_corpus) print(X.toarray()) print(vectorizer.get_feature_names_out())
Sortie :
[[1 2 1 1 1 1 1 1 1 1]] [u'best', u'guru99', u'is', u'love', u'online', u'sitefor', u'the', u'to', u'tutorials', u'visit']
Code Explication
- CountVectorizer est le module utilisé pour stocker le vocabulaire en fonction de l'adéquation des mots à celui-ci. Il est importé de scikit-learn.
- Créez l'objet en utilisant la classe CountVectorizer.
- Saisissez les données de la liste qui doivent être intégrées au CountVectorizer.
- Les données sont adaptées à l'objet créé à partir de la classe CountVectorizer.
- Utilisez une approche de type « sac de mots » pour compter les mots dans les données à l'aide du vocabulaire. Si un mot ou un jeton n'est pas présent dans le vocabulaire, son index est mis à zéro.
- La variable x de la ligne 5 est convertie en tableau (une méthode disponible pour x). Cela permet de compter les occurrences de chaque élément dans la phrase ou la liste fournie à la ligne 3.
- Ceci montre les caractéristiques qui font partie du vocabulaire lorsqu'il est ajusté à l'aide des données de la ligne 4.
Dans l'approche sémantique latente, chaque ligne représente un mot unique, tandis que chaque colonne représente le nombre d'occurrences de ce mot dans le document. Il s'agit d'une représentation des mots sous forme de matrice de document. La méthode TF-IDF (Term Frequency-Inverse Document Frequency) permet de calculer la fréquence d'un mot dans le document ; elle correspond à la fréquence du terme dans le document divisée par sa fréquence dans l'ensemble du corpus.
Lacune de la méthode Bag of Words
- Il ignore l'ordre des mots ; par exemple, c'est mauvais = C'est mauvais..
- Cette méthode ignore le contexte des mots. Prenons l'exemple de la phrase « Il aimait les livres. L'éducation se trouve principalement dans les livres. » Elle créerait deux vecteurs : un pour « Il aimait les livres » et un autre pour « L'éducation se trouve principalement dans les livres ». Elle les traiterait comme orthogonaux, donc indépendants, alors qu'en réalité, ils sont liés.
Pour surmonter ces limitations, l'intégration de mots a été développée, et Word2vec est une des approches utilisées pour la mettre en œuvre.
Comment fonctionne Word2vec ?
Word2vec apprend un mot en prédisant son contexte. Prenons par exemple le mot « Il ». aime Football."
Nous voulons calculer le Word2vec du mot : aime.
Supposer:
loves = Vin. P(Vout / Vin) is calculated where, Vin is the input word. P is the probability of likelihood. Vout is the output word.
Le mot aime Le système parcourt chaque mot du corpus. Les relations syntaxiques et sémantiques entre les mots sont encodées, ce qui facilite la recherche de mots similaires et analogues.
Toutes les caractéristiques aléatoires du mot aime sont calculées. Ces caractéristiques sont modifiées ou mises à jour en fonction des mots voisins ou du contexte à l'aide d'un Rétropropagation méthode.
Une autre façon d'apprendre consiste à considérer que si le contexte de deux mots est similaire, ou si deux mots présentent des caractéristiques similaires, alors ces mots sont liés.
Mot2vec Architecture
Il existe deux architectures utilisées par Word2vec :
- Sac continu de mots (CBOW)
- Skip-gramme
Avant d'aller plus loin, examinons l'importance de ces architectures ou modèles du point de vue de la représentation des mots. L'apprentissage de la représentation des mots est essentiellement non supervisé, mais des cibles/étiquettes sont nécessaires pour entraîner le modèle. Skip-gram et CBOW transforment la représentation non supervisée en une forme supervisée pour l'entraînement du modèle.
Dans CBOW, le mot actuel est prédit à l'aide de la fenêtre des fenêtres contextuelles environnantes. Par exemple, si wi-1wi-2wi + 1wi + 2 reçoivent des mots ou un contexte, ce modèle fournira wi.
Skip-Gram fonctionne à l'inverse de CBOW, c'est-à-dire qu'il prédit la séquence ou le contexte donné à partir du mot. Vous pouvez inverser l'exemple pour mieux le comprendre. Si wi est donné, cela prédira le contexte, ou wi-1wi-2wi + 1wi + 2.
Word2vec offre la possibilité de choisir entre CBOW (Continuous Bag of Words) et skip-gram. Ces paramètres sont définis lors de l'entraînement du modèle. Il est possible d'utiliser un échantillonnage négatif ou une couche softmax hiérarchique.
Sac continu de mots
Dessinons un exemple simple de diagramme Word2vec pour comprendre l'architecture continue du sac de mots.

Calculons les équations mathématiquement. Supposons que V soit la taille du vocabulaire et N soit la taille de la couche cachée. L'entrée est définie comme {xi-1, Xi-2, Xi + 1, Xi + 2 On obtient la matrice de pondération en multipliant V par N. Une autre matrice est obtenue en multipliant le vecteur d'entrée par la matrice de pondération. Ceci peut également être compris grâce à l'équation suivante.
h = xitW
où xit et W sont respectivement le vecteur d'entrée et la matrice de poids.
Pour calculer la correspondance entre le contexte et le mot suivant, veuillez vous référer à l'équation ci-dessous.
u = représentation prédite * h
où la représentation prédite est obtenue à partir du modèle de l'équation ci-dessus.
Modèle Skip-Gram
L'approche Skip-Gram permet de prédire une phrase à partir d'un mot donné. Pour mieux la comprendre, prenons l'exemple du diagramme présenté dans l'exemple Word2vec ci-dessous.

On peut le considérer comme l'inverse du modèle « sac de mots continu », où l'entrée est le mot et le modèle fournit le contexte ou la séquence. On peut également conclure que la cible est fournie en entrée, et que la couche de sortie est dupliquée plusieurs fois pour prendre en charge le nombre de mots de contexte choisi. Le vecteur d'erreur de toutes les couches de sortie est additionné pour ajuster les poids par rétropropagation.
Quel modèle choisir ?
CBOW est plusieurs fois plus rapide que skip-gram et offre une meilleure fréquence pour les mots fréquents, tandis que skip-gram nécessite peu de données d'entraînement et représente même les mots ou expressions rares. Le tableau ci-dessous compare les deux architectures en un coup d'œil.
| Aspect | CBOW | Sauter le gramme |
|---|---|---|
| Prédiction | Prédit le mot cible à partir du contexte | Prédit le contexte à partir du mot cible |
| Vitesse d'entraînement | plus rapide | Ralentissez |
| Mots fréquents | Plus grande précision | Précision inférieure |
| Mots rares | Représentation plus faible | Une représentation plus forte |
| Données d'entraînement | Il faut plus de données | Fonctionne avec moins de données |
La relation entre Word2vec et NLTK
NLTK est le naturel Language ToolLe kit Word2vec est utilisé pour le prétraitement de texte. Il permet d'effectuer diverses opérations telles que l'étiquetage morphosyntaxique, la lemmatisation, la racinisation, la suppression des mots vides et des mots rares ou peu fréquents. Il contribue au nettoyage du texte et à l'extraction de caractéristiques à partir des mots pertinents. Word2vec, quant à lui, est utilisé pour la correspondance sémantique (regroupement d'éléments étroitement liés) et syntaxique (séquence). Grâce à Word2vec, il est possible de trouver des mots similaires et dissemblables, de réduire la dimensionnalité, et bien plus encore. Une autre fonctionnalité importante de Word2vec est la conversion de la représentation multidimensionnelle du texte en vecteurs de dimension inférieure.
Où utiliser NLTK et Word2vec ?
Si l'on doit accomplir des tâches générales comme mentionnées ci-dessus, telles que la tokenisation, l'étiquetage morphosyntaxique et l'analyse syntaxique, il faut opter pour NLTK, tandis que pour prédire les mots en fonction du contexte, la modélisation thématique ou la similarité des documents, il faut utiliser Word2vec.
Relation entre NLTK et Word2vec à l'aide du code
NLTK et Word2vec peuvent être utilisés conjointement pour trouver des représentations de mots similaires ou des correspondances syntaxiques. L'outil NLTK permet de charger de nombreux modules fournis avec NLTK, et un modèle peut être créé à l'aide de Word2vec. Ce modèle peut ensuite être testé sur des mots réels. Voyons comment les combiner dans le code suivant. Avant de poursuivre, veuillez consulter les corpus fournis par NLTK. Vous pouvez les télécharger à l'aide de la commande :
nltk(nltk.download('all'))

Veuillez consulter la capture d'écran pour le code.
import nltk import gensim from nltk.corpus import abc model = gensim.models.Word2Vec(abc.sents()) X = list(model.wv.vocab) data = model.most_similar('science') print(data)

Sortie :
[('law', 0.9415997266769409), ('practice', 0.9276568293571472), ('discussion', 0.9259148836135864), ('agriculture', 0.9257254004478455), ('media', 0.9232194423675537), ('policy', 0.922248125076294), ('general', 0.9166069030761719), ('undertaking', 0.916458249092102), ('tight', 0.9129181504249573), ('board', 0.9107444286346436)]
Explication de Code
- La bibliothèque nltk est importée ; vous pouvez ensuite télécharger le corpus abc que nous utiliserons à l'étape suivante.
- Gensim a été importé. Si Gensim Word2vec n'est pas installé, veuillez l'installer à l'aide de la commande « pip3 install gensim ». Voir la capture d'écran ci-dessous.

- Importez le corpus abc, qui a été téléchargé à l'aide de nltk.download('abc').
- Transmettez les fichiers au modèle Word2vec, qui est importé à l'aide de Gensim, sous forme de phrases.
- Le vocabulaire est stocké sous forme de variable.
- Le modèle est testé sur le mot d'exemple science, car ces fichiers sont liés à la science.
- Ici, le modèle prédit le mot similaire de « science ».
Activateurs et Word2Vec
La fonction d'activation d'un neurone définit sa sortie en fonction d'un ensemble d'entrées. Elle s'inspire biologiquement de l'activité cérébrale, où différents neurones sont activés par différents stimuli. Illustrons la fonction d'activation à l'aide du schéma suivant.

Ici, x1, x2, … x4 sont les nœuds du réseau neuronal.
w1, w2, w3 sont les poids des nœuds.
La somme (Σ) de tous les poids et valeurs de nœuds fonctionne comme fonction d'activation.
Pourquoi la fonction d'activation ?
Si aucune fonction d'activation n'est utilisée, la sortie serait linéaire, mais les fonctionnalités d'une fonction linéaire sont limitées. Pour obtenir des fonctionnalités complexes telles que la détection d'objets, la classification d'images, etc., il est nécessaire d'utiliser une fonction d'activation.ping Pour la synthèse vocale et de nombreuses autres sorties non linéaires, une fonction d'activation est nécessaire.
Comment la couche d'activation est calculée dans l'intégration de mots (Word2vec)
La couche Softmax (fonction exponentielle normalisée) est la fonction de la couche de sortie qui active chaque nœud. Une autre approche utilisée est la couche Softmax hiérarchique, dont la complexité est de O(log)2V), tandis que pour softmax, la complexité est O(V), où V représente la taille du vocabulaire. La différence réside dans la réduction de la complexité grâce à la couche softmax hiérarchique. Pour comprendre son fonctionnement, veuillez consulter l'exemple d'intégration de mots ci-dessous :

Supposons que nous voulions calculer la probabilité d'observer le mot love Dans un contexte donné, le flux de la racine vers la feuille passera d'abord par le nœud 2, puis par le nœud 5. Ainsi, avec un vocabulaire de 8 mots, seuls trois calculs sont nécessaires. Cela permet de décomposer le calcul de la probabilité d'un mot (love).
Quelles autres options sont disponibles autres que Hierarchical Softmax ?
De manière générale, les options d'intégration de mots disponibles sont : Softmax différencié, CNN-Softmax, échantillonnage d'importance, échantillonnage d'importance adaptatif, estimation contrastive du bruit, échantillonnage négatif, auto-normalisation et normalisation peu fréquente.
Concernant plus précisément Word2vec, nous disposons d'échantillons négatifs.
L'échantillonnage négatif est une méthode d'échantillonnage des données d'entraînement. Il s'apparente à la descente de gradient stochastique, mais avec quelques différences. L'échantillonnage négatif ne recherche que des exemples d'entraînement négatifs. Il repose sur l'estimation contrastive du bruit et sélectionne aléatoirement des mots hors contexte. C'est une méthode d'entraînement rapide qui choisit le contexte de manière aléatoire. Si le mot prédit apparaît dans le contexte choisi aléatoirement, les deux vecteurs sont proches.
Quelle conclusion peut-on en tirer ?
Les activateurs stimulent les neurones de la même manière que nos neurones sont activés par des stimuli externes. La couche Softmax est l'une des fonctions de la couche de sortie qui active les neurones dans le cas des plongements lexicaux. Word2vec propose des options telles que le softmax hiérarchique et l'échantillonnage négatif. Grâce aux activateurs, il est possible de convertir une fonction linéaire en une fonction non linéaire, et ainsi implémenter un algorithme d'apprentissage automatique complexe.
Qu’est-ce que Gensim ?
Gensim est une boîte à outils open source de modélisation de sujets et de traitement du langage naturel implémentée dans Python et Cython. La boîte à outils Gensim permet aux utilisateurs d'importer des données Word2vec pour la modélisation thématique afin de découvrir la structure cachée du texte. Gensim propose une implémentation de Word2vec, mais aussi de Doc2vec et de FastText.
Cette section est consacrée à Word2vec, nous resterons donc sur le sujet actuel.
Comment implémenter Word2vec à l'aide de Gensim
Jusqu'à présent, nous avons abordé la définition de Word2vec, ses différentes architectures, les raisons du passage d'un sac de mots à Word2vec, la relation entre Word2vec et NLTK avec du code en direct et les fonctions d'activation.
Voici la méthode étape par étape pour implémenter Word2vec à l'aide de Gensim :
Étape 1) Collecte de données
La première étape pour mettre en œuvre un modèle d'apprentissage automatique ou un traitement du langage naturel consiste à collecter des données.
Veuillez observer les données pour créer un chatbot intelligent, comme indiqué dans l'exemple Gensim Word2vec ci-dessous.
[{"tag": "welcome",
"patterns": ["Hi", "How are you", "Is any one to talk?", "Hello", "hi are you available"],
"responses": ["Hello, thanks for contacting us", "Good to see you here", "Hi there, how may I assist you?"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "I will come back soon"],
"responses": ["See you later, thanks for visiting", "have a great day ahead", "Wish you Come back again soon."]
},
{"tag": "thankful",
"patterns": ["Thanks for helping me", "Thank your guidance", "That's helpful and kind from you"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "It is my duty to help you"]
},
{"tag": "hoursopening",
"patterns": ["What hours are you open?", "Tell your opening time?", "When are you open?", "Just your timing please"],
"responses": ["We're open every day 8am-7pm", "Our office hours are 8am-7pm every day", "We open office at 8 am and close at 7 pm"]
},
{"tag": "payments",
"patterns": ["Can I pay using credit card?", "Can I pay using Mastercard?", "Can I pay using cash only?"],
"responses": ["We accept VISA, Mastercard and credit card", "We accept credit card, debit cards and cash. Please don't worry"]
}
]
Voici ce que nous comprenons à partir des données :
- Ces données contiennent trois éléments : une étiquette, un modèle et des réponses. L’étiquette correspond à l’intention (le sujet de discussion).
- Les données sont au format JSON.
- Un modèle est une question que les utilisateurs poseront au bot.
- Les réponses sont les réponses que le chatbot fournira à la question/au modèle correspondant.
Étape 2) Prétraitement des données
Il est très important de traiter les données brutes. Si des données nettoyées sont transmises à la machine, le modèle répondra avec plus de précision et apprendra les données plus efficacement.
Cette étape consiste à supprimer les mots vides, à réduire les mots à leur racine, à éliminer les mots inutiles, etc. Avant de poursuivre, il est important de charger les données et de les convertir en un tableau de données. Veuillez consulter le code ci-dessous.
import json json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f)
Explication de Code:
- Les données étant au format JSON, le format JSON est importé.
- Le fichier est stocké dans la variable.
- Le fichier est ouvert et chargé dans la variable de données.
Les données sont maintenant importées ; il est temps de les convertir en un tableau de données. Veuillez consulter le code ci-dessous pour l’étape suivante.
import pandas as pd df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join)
Explication de Code:
1. Les données sont converties en un cadre de données à l'aide de pandas, qui a été importé ci-dessus.
2. Il convertit la liste des modèles de colonnes en une chaîne de caractères.
from nltk.corpus import stopwords from textblob import Word stop = stopwords.words('english') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
Code Explication:
1. Les mots vides anglais sont importés à l'aide du module de mots vides de la boîte à outils nltk.
2. Tous les mots du texte sont convertis en minuscules à l'aide d'une boucle « for » et d'une fonction lambda. Fonction Lambda est une fonction anonyme.
3. Toutes les lignes du texte dans le cadre de données sont vérifiées pour la ponctuation des chaînes de caractères, et celles-ci sont filtrées.
4. Les caractères tels que les chiffres ou les points sont supprimés à l'aide d'une expression régulière.
5. DigiLes ts sont supprimés du texte.
6. Les mots vides sont supprimés à ce stade.
7. Les mots sont maintenant filtrés, et les différentes formes d'un même mot sont supprimées par lemmatisation. Le prétraitement des données est ainsi terminé.
Sortie :
, patterns, responses, tag 0,hi one talk hello hi available,"['Hello, thanks for contacting us', 'Good to see you here', ' Hi there, how may I assist you?']",welcome 1,bye see later goodbye come back soon,"['See you later, thanks for visiting', 'have a great day ahead', 'Wish you Come back again soon.']",goodbye 2,thanks helping thank guidance thats helpful kind,"['Happy to help!', 'Any time!', 'My pleasure', 'It is my duty to help you']",thankful 3,hour open tell opening time open timing please,"[""We're open every day 8am-7pm"", 'Our office hours are 8am-7pm every day', 'We open office at 8 am and close at 7 pm']",hoursopening 4,pay using credit card pay using mastercard pay using cash,"['We accept VISA, Mastercard and credit card', 'We accept credit card, debit cards and cash. Please dont worry']",payments
Étape 3) Création d'un réseau neuronal à l'aide de Word2vec
Il est maintenant temps de créer un modèle à l'aide du module Word2vec de Gensim. Pour cela, nous devons importer Word2vec depuis Gensim. Procédons à cette opération, puis nous construirons le modèle. Enfin, nous le testerons sur des données en temps réel.
from gensim.models import Word2Vec
Nous pouvons maintenant construire le modèle avec succès à l'aide de Word2Vec. Veuillez vous référer à la ligne de code suivante pour découvrir comment créer le modèle avec Word2Vec. Le texte est fourni au modèle sous forme de liste ; nous allons donc convertir le texte du dataframe en liste à l'aide du code ci-dessous.
Bigger_list = [] for i in df['patterns']: li = list(i.split("")) Bigger_list.append(li) Model = Word2Vec(Bigger_list, min_count=1, size=300, workers=4)
Explication de Code:
1. Création de la liste plus grande (bigger_list) dans laquelle la liste interne est ajoutée. C'est le format qui est fourni au modèle Word2Vec.
2. Une boucle est implémentée, et chaque entrée de la colonne des motifs du cadre de données est itérée.
3. Chaque élément des modèles de colonnes est divisé et stocké dans la liste interne li.
4. La liste interne est complétée par la liste externe.
5. Cette liste est fournie au modèle Word2Vec. Examinons quelques-uns des paramètres qui y sont proposés.
Min_count : Il ignore tous les mots dont la fréquence totale est inférieure à cette valeur.
Dimensions Il indique la dimensionnalité des vecteurs de mots.
Travailleurs: Voici les fils de discussion pour entraîner le modèle.
D'autres options sont également disponibles, et certaines des plus importantes sont expliquées ci-dessous.
Fenêtre: Distance maximale entre le mot actuel et le mot prédit dans une phrase.
Sg : Il s'agit d'un algorithme d'apprentissage : 1 pour skip-gram et 0 pour un sac de mots continu. Nous les avons abordés en détail ci-dessus.
HS : Si cette valeur est 1, alors nous utilisons la fonction softmax hiérarchique pour l'entraînement, et si elle est 0, alors un échantillonnage négatif est utilisé.
Alpha: Taux d'apprentissage initial.
Affichons le code final ci-dessous :
# list of libraries used by the code import string from gensim.models import Word2Vec import logging from nltk.corpus import stopwords from textblob import Word import json import pandas as pd # data in json format json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f) # displaying the list of stopwords stop = stopwords.words('english') # dataframe df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join) # cleaning the data using the NLP approach print(df) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()])) # taking the outer list bigger_list = [] for i in df['patterns']: li = list(i.split(" ")) bigger_list.append(li) # structure of data to be taken by the model.word2vec print("Data format for the overall list:", bigger_list) # custom data is fed to machine for further processing model = Word2Vec(bigger_list, min_count=1, size=300, workers=4)
Étape 4) Sauvegarde du modèle
Le modèle peut être enregistré au format binaire (.bin). Veuillez suivre les instructions ci-dessous pour enregistrer le modèle.
model.save("word2vec.model") model.save("model.bin")
Explication du code ci-dessus
1. Le modèle est enregistré sous la forme d'un fichier .model.
2. Le modèle est enregistré sous la forme d'un fichier .bin.
Nous utiliserons ce modèle pour effectuer des tests en temps réel, notamment sur les mots similaires, les mots différents et les mots les plus courants.
Étape 5) Chargement du modèle et réalisation de tests en temps réel
Le modèle est chargé à l'aide du code ci-dessous :
model = Word2Vec.load('model.bin')
Si vous souhaitez imprimer le vocabulaire, utilisez la commande suivante :
vocab = list(model.wv.vocab)
Veuillez voir le résultat :
['see', 'thank', 'back', 'thanks', 'soon', 'open', 'mastercard', 'card', 'time', 'pay', 'talk', 'cash', 'one', 'please', 'goodbye', 'thats', 'helpful', 'hour', 'credit', 'hi', 'later', 'guidance', 'opening', 'timing', 'hello', 'helping', 'bye', 'tell', 'come', 'using', 'kind', 'available']
Étape 6) Vérification des mots les plus similaires
Mettons les choses en pratique :
similar_words = model.most_similar('thanks') print(similar_words)
Veuillez voir le résultat :
[('kind', 0.16104359924793243), ('using', 0.1352398842573166), ('come', 0.11500970274209976), ('later', 0.09989878535270691), ('helping', 0.04855936020612717), ('credit', 0.04659383371472359), ('pay', 0.0329081267118454), ('thank', 0.02484947443008423), ('hour', 0.0202352125197649), ('opening', 0.018177658319473267)]
Étape 7) Le mot ne correspond pas aux mots fournis
dissimlar_words = model.doesnt_match('See you later, thanks for visiting'.split()) print(dissimlar_words)
Nous avons fourni les mots « À plus tard, merci de votre visite. »Ce code affiche le mot le plus différent parmi ceux proposés. Exécutons-le pour observer le résultat.
Le résultat après exécution du code ci-dessus :
Thanks
Étape 8) Trouver la similitude entre deux mots
Ce résultat est exprimé en termes de probabilité de similarité entre deux mots. Veuillez consulter le code ci-dessous pour savoir comment exécuter cette section.
similarity_two_words = model.similarity('please', 'see') print("Please provide the similarity between these two words:") print(similarity_two_words)
Le résultat du code ci-dessus est le suivant :
0.13706
Vous pouvez trouver d'autres mots similaires en exécutant le code ci-dessous :
similar = model.similar_by_word('kind') print(similar)
Résultat du code ci-dessus :
[('credit', 0.11764447391033173), ('cash', 0.11440904438495636), ('one', 0.11151769757270813), ('hour', 0.0944807156920433), ('using', 0.0705675333738327), ('thats', 0.05206916481256485), ('later', 0.04502468928694725), ('bye', 0.03960943967103958), ('back', 0.03837274760007858), ('thank', 0.0380823090672493)]