Tutorial de Scikit-Learn: Cómo instalar y ejemplos de Scikit-Learn
⚡ Resumen inteligente
Scikit-learn es una plataforma de código abierto. Python Biblioteca que abarca el preprocesamiento, la clasificación, la regresión, la agrupación y la selección de modelos detrás de una única interfaz de estimador consistente, lo que mantiene un flujo de trabajo completo de aprendizaje automático breve, legible y reproducible, desde los datos brutos hasta las predicciones puntuadas.

¿Qué es Scikit-learn?
Scikit-learn es un código abierto Python biblioteca para aprendizaje automático. Admite algoritmos bien establecidos como KNN, potenciación de gradiente, bosque aleatorio y SVM, y está construido sobre NumPy y SciPy. Scikit-learn se utiliza ampliamente en competiciones de Kaggle, así como en importantes empresas tecnológicas. Abarca el preprocesamiento, la reducción de dimensionalidad, la clasificación, la regresión, la agrupación y la selección de modelos.
Scikit-learn tiene una de las mejores documentaciones de cualquier biblioteca de código abierto. Incluso proporciona un gráfico de estimación interactivo, Elegir el estimador adecuadoque te guía desde el tamaño de tu conjunto de datos hasta una lista reducida de algoritmos que vale la pena probar.
La siguiente figura ilustra cómo funciona Scikit-learn.
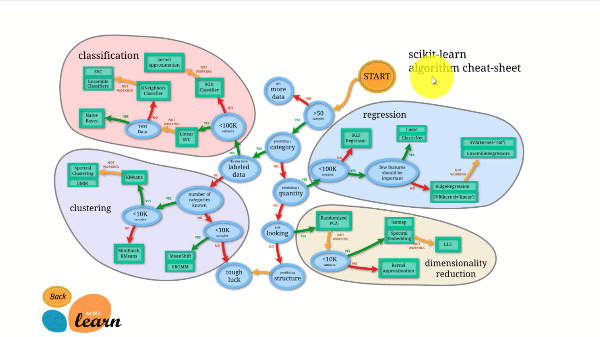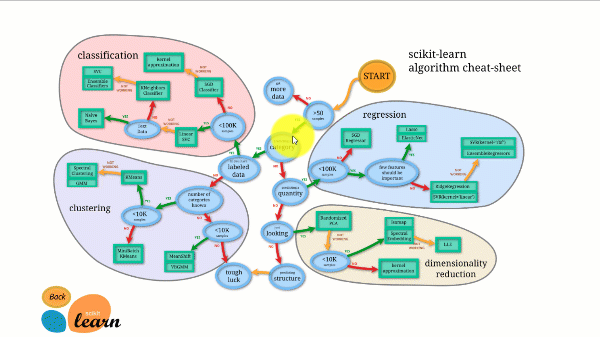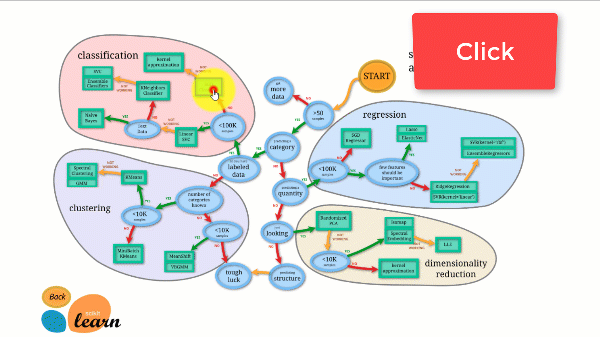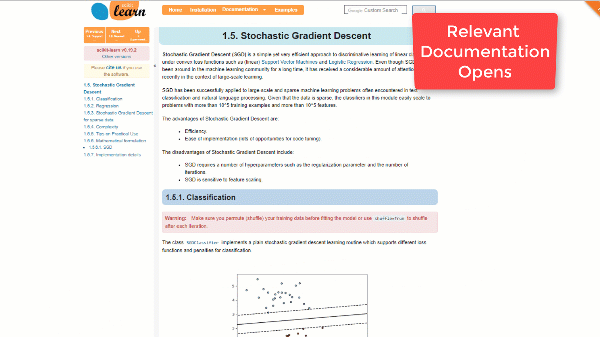
Scikit-learn no es difícil de usar y ofrece excelentes resultados. Sin embargo, entrena en la CPU: el trabajo se paraleliza en los núcleos con el argumento n_jobs en lugar de en una GPU. Ejecutar un algoritmo de aprendizaje profundo con él es posible, pero rara vez óptimo, especialmente si ya sabes cómo usarlo. TensorFlow.
Cómo descargar e instalar Scikit-learn
Ahora en esto Python En este tutorial de Scikit-learn, aprenderás cómo descargar e instalar Scikit-learn:
Opción 1: AWS
Scikit-learn se puede usar en AWS. Una imagen de Docker con scikit-learn preinstalado ahorra por completo el trabajo de configuración.
Para instalar la versión de desarrollador, ejecute el siguiente comando dentro Jupyter:
import sys !{sys.executable} -m pip install git+git://github.com/scikit-learn/scikit-learn.git
Opción 2: Mac o Windows usando anaconda
Para obtener información sobre la instalación de Anaconda, consulte Cómo descargar e instalar TensorFlow.
En el momento en que se escribió este tutorial, los desarrolladores de scikit habían lanzado una versión de desarrollo que solucionaba los problemas presentes en la versión actual, por lo que los pasos a continuación utilizan esa compilación de desarrollo. En una máquina nueva hoy, la versión estable actual ya contiene todos los transformadores utilizados aquí, y pip install -U scikit-learn es suficiente.
Cómo instalar scikit-learn con Conda Environment
Si instalaste scikit-learn con el entorno conda, sigue los pasos a continuación para actualizar a la versión 0.20.
Paso 1) Activar el entorno de TensorFlow
source activate hello-tf
Paso 2) Elimine scikit-learn usando el comando conda.
conda remove scikit-learn
Paso 3) Instalar la versión para desarrolladores
Instala la versión para desarrolladores de scikit-learn junto con las bibliotecas necesarias.
conda install -c anaconda git
pip install Cython
pip install h5py
pip install git+git://github.com/scikit-learn/scikit-learn.git
NOTA: Windows Los usuarios necesitan Microsoft Visual C++ 14. Puedes conseguirlo aquí.
Ejemplo de Scikit-Learn con aprendizaje automático
Este tutorial de Scikit se divide en dos partes:
- Aprendizaje automático con scikit-learn
- Cómo confiar en tu modelo con LIME
La primera parte detalla cómo construir una canalización, crear un modelo y ajustar los hiperparámetros, mientras que la segunda parte trata sobre la interpretación del modelo.
Paso 1) Importar los datos
Durante este tutorial de Scikit-learn, utilizarás el conjunto de datos del censo de adultos.
El archivo se lee directamente del repositorio de aprendizaje automático de la UCI en el código siguiente, por lo que no es necesario descargarlo manualmente. Si le interesan las estadísticas descriptivas, vale la pena echar un vistazo a las herramientas Dive y Overview. Consulte este tutorial Para obtener más información sobre Dive y la descripción general.
Importa el conjunto de datos con pandas. Ten en cuenta que debes convertir las variables continuas a formato de punto flotante.
Este conjunto de datos incluye ocho variables categóricas, enumeradas en CATE_FEATURES:
- clase de trabajo
- educación
- marital
- Ocupación.
- relación
- raza
- vie
- patria
También incluye seis variables continuas, enumeradas en CONTI_FEATURES:
- edad
- fnlwgt
- núm_educación
- ganancia capital
- perdida de capital
- horas_semana
Aquí las listas se completan manualmente para que tenga una idea más clara de qué columnas están en juego. Una forma más rápida de crear una lista de columnas categóricas o continuas es:
## List Categorical CATE_FEATURES = df_train.iloc[:,:-1].select_dtypes('object').columns print(CATE_FEATURES) ## List continuous CONTI_FEATURES = df_train._get_numeric_data() print(CONTI_FEATURES)
Aquí está el código para importar los datos:
# Import dataset import pandas as pd ## Define path data COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country', 'label'] ### Define continuous list CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week'] ### Define categorical list CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country'] ## Prepare the data features = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data" df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False) df_train[CONTI_FEATURES] =df_train[CONTI_FEATURES].astype('float64') df_train.describe()
Al llamar a la función describe() en el marco, se obtienen las estadísticas descriptivas de las seis columnas continuas:
| edad | fnlwgt | núm_educación | ganancia capital | perdida de capital | horas_semana | |
|---|---|---|---|---|---|---|
| contar | 32561.000000 | 3.256100e + 04 | 32561.000000 | 32561.000000 | 32561.000000 | 32561.000000 |
| mean | 38.581647 | 1.897784e + 05 | 10.080679 | 1077.648844 | 87.303830 | 40.437456 |
| enfermedades de transmisión sexual | 13.640433 | 1.055500e + 05 | 2.572720 | 7385.292085 | 402.960219 | 12.347429 |
| min | 17.000000 | 1.228500e + 04 | 1.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 28.000000 | 1.178270e + 05 | 9.000000 | 0.000000 | 0.000000 | 40.000000 |
| 50% | 37.000000 | 1.783560e + 05 | 10.000000 | 0.000000 | 0.000000 | 40.000000 |
| 75% | 48.000000 | 2.370510e + 05 | 12.000000 | 0.000000 | 0.000000 | 45.000000 |
| max | 90.000000 | 1.484705e + 06 | 16.000000 | 99999.000000 | 4356.000000 | 99.000000 |
Puedes comprobar el número de valores únicos de la característica native_country. Solo un hogar proviene de Holanda-Países Bajos. Ese hogar no aporta información y generará un error durante el entrenamiento.
df_train.native_country.value_counts()
United-States 29170 Mexico 643 ? 583 Philippines 198 Germany 137 Canada 121 Puerto-Rico 114 El-Salvador 106 India 100 Cuba 95 England 90 Jamaica 81 South 80 China 75 Italy 73 Dominican-Republic 70 Vietnam 67 Guatemala 64 Japan 62 Poland 60 Columbia 59 Taiwan 51 Haiti 44 Iran 43 Portugal 37 Nicaragua 34 Peru 31 France 29 Greece 29 Ecuador 28 Ireland 24 Hong 20 Cambodia 19 Trinadad&Tobago 19 Thailand 18 Laos 18 Yugoslavia 16 Outlying-US(Guam-USVI-etc) 14 Honduras 13 Hungary 13 Scotland 12 Holand-Netherlands 1 Name: native_country, dtype: int64
Puedes excluir esta fila poco informativa del conjunto de datos:
## Drop Netherland, because only one row df_train = df_train[df_train.native_country != "Holand-Netherlands"]
A continuación, almacena la posición de las entidades continuas en una lista. Lo necesitará en el siguiente paso para construir la tubería.
El código que aparece a continuación recorre todos los nombres de columna en CONTI_FEATURES, lee cada ubicación (es decir, su número de columna) y la agrega a una lista llamada conti_features.
## Get the column index of the categorical features conti_features = [] for i in CONTI_FEATURES: position = df_train.columns.get_loc(i) conti_features.append(position) print(conti_features)
[0, 2, 10, 4, 11, 12]
El siguiente bloque realiza la misma función para las variables categóricas.
## Get the column index of the categorical features categorical_features = [] for i in CATE_FEATURES: position = df_train.columns.get_loc(i) categorical_features.append(position) print(categorical_features)
[1, 3, 5, 6, 7, 8, 9, 13]
Ahora veamos el conjunto de datos en sí. Cada característica categórica es una cadena de texto, y a un modelo no se le puede proporcionar un valor de cadena, por lo que el conjunto de datos debe transformarse con variables ficticias.
df_train.head(5)
De hecho, necesitas una columna por cada grupo en cada característica. Primero, ejecuta el código a continuación para calcular el número total de columnas necesarias.
print(df_train[CATE_FEATURES].nunique(), 'There are',sum(df_train[CATE_FEATURES].nunique()), 'groups in the whole dataset')
workclass 9
education 16
marital 7
occupation 15
relationship 6
race 5
sex 2
native_country 41
dtype: int64 There are 101 groups in the whole dataset
El conjunto de datos completo contiene 101 grupos, como se muestra arriba. La característica "clase de trabajo" por sí sola tiene nueve grupos. Puede listar los nombres de los grupos con el siguiente código; `unique()` devuelve los valores distintos de cada característica categórica.
for i in CATE_FEATURES: print(df_train[i].unique())
['State-gov' 'Self-emp-not-inc' 'Private' 'Federal-gov' 'Local-gov' '?' 'Self-emp-inc' 'Without-pay' 'Never-worked'] ['Bachelors' 'HS-grad' '11th' 'Masters' '9th' 'Some-college' 'Assoc-acdm' 'Assoc-voc' '7th-8th' 'Doctorate' 'Prof-school' '5th-6th' '10th' '1st-4th' 'Preschool' '12th'] ['Never-married' 'Married-civ-spouse' 'Divorced' 'Married-spouse-absent' 'Separated' 'Married-AF-spouse' 'Widowed'] ['Adm-clerical' 'Exec-managerial' 'Handlers-cleaners' 'Prof-specialty' 'Other-service' 'Sales' 'Craft-repair' 'Transport-moving' 'Farming-fishing' 'Machine-op-inspct' 'Tech-support' '?' 'Protective-serv' 'Armed-Forces' 'Priv-house-serv'] ['Not-in-family' 'Husband' 'Wife' 'Own-child' 'Unmarried' 'Other-relative'] ['White' 'Black' 'Asian-Pac-Islander' 'Amer-Indian-Eskimo' 'Other'] ['Male' 'Female'] ['United-States' 'Cuba' 'Jamaica' 'India' '?' 'Mexico' 'South' 'Puerto-Rico' 'Honduras' 'England' 'Canada' 'Germany' 'Iran' 'Philippines' 'Italy' 'Poland' 'Columbia' 'Cambodia' 'Thailand' 'Ecuador' 'Laos' 'Taiwan' 'Haiti' 'Portugal' 'Dominican-Republic' 'El-Salvador' 'France' 'Guatemala' 'China' 'Japan' 'Yugoslavia' 'Peru' 'Outlying-US(Guam-USVI-etc)' 'Scotland' 'Trinadad&Tobago' 'Greece' 'Nicaragua' 'Vietnam' 'Hong' 'Ireland' 'Hungary']
Por lo tanto, el conjunto de datos de entrenamiento contendrá 101 + 6 columnas: los grupos one-hot más las seis características continuas.
Scikit-learn puede encargarse de la conversión en dos pasos:
- Convierte la cadena en un ID. State-gov se convierte en ID 1, Self-emp-not-inc en ID 2, y así sucesivamente. LabelEncoder lo hace por ti.
- Transponga cada ID a una nueva columna. El conjunto de datos tiene 101 ID de grupo, por lo que habrá 101 columnas que capturarán cada grupo de características categóricas. Scikit-learn proporciona OneHotEncoder para esta operación.
Paso 2) Crear el conjunto de tren/prueba
Ahora que el conjunto de datos está listo, divídalo en una proporción de 80/20: el 80 por ciento para el conjunto de entrenamiento y el 20 por ciento para el conjunto de prueba.
Puedes usar train_test_split. El primer argumento es el dataframe de características y el segundo es la etiqueta. El tamaño del conjunto de prueba se define con test_size.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df_train[features], df_train.label, test_size = 0.2, random_state=0) X_train.head(5) print(X_train.shape, X_test.shape)
(26048, 14) (6512, 14)
Paso 3) Construya la tubería
El sistema facilita la alimentación del modelo con datos consistentes. La idea es procesar los datos brutos a través de un único objeto que realiza todas las operaciones en orden.
Con este conjunto de datos, es necesario estandarizar las variables continuas y convertir las categóricas. Cualquier operación puede realizarse dentro de una secuencia de procesamiento: los valores faltantes pueden reemplazarse con la media o la mediana, y se pueden crear nuevas variables.
Tienes dos opciones: codificar manualmente ambos procesos o crear una canalización. La codificación manual puede filtrar datos de prueba a las estadísticas ajustadas y generar inconsistencias con el tiempo, por lo que la canalización es la mejor opción.
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder from sklearn.compose import ColumnTransformer, make_column_transformer from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression
La tubería realiza dos operaciones antes de alimentar el clasificador logístico:
- Estandarizar la variable: StandardScaler()
- Convierta las características categóricas: OneHotEncoder(sparse=False)
Ambos pasos se realizan con make_column_transformer. Cuando se escribió este tutorial, la función no estaba en la versión publicada de scikit-learn (0.19), por lo que se utilizó la versión para desarrolladores; esta función se ha incluido en todas las versiones estables desde la 0.20.
make_column_transformer es sencillo: usted declara qué columnas transformar y qué transformación aplicar. Para estandarizar las características continuas que pasa:
- conti_features, StandardScaler() dentro de make_column_transformer
- conti_features: la lista de columnas continuas
- StandardScaler: estandariza esas columnas.
El objeto OneHotEncoder dentro de make_column_transformer codifica las etiquetas automáticamente.
preprocess = make_column_transformer(
(conti_features, StandardScaler()),
### Need to be numeric not string to specify columns name
(categorical_features, OneHotEncoder(sparse=False))
)
Nota de versión: Dos argumentos del bloque anterior han avanzado. Las versiones actuales esperan primero el transformador y luego las columnas, y escaso fue renombrado salida_espaciada en scikit-learn 1.2 y eliminado en 1.4, por lo que el código más reciente lee Codificador OneHot(salida_dispersa=Falso).
Puedes comprobar si el proceso funciona con fit_transform. La salida debería tener la forma 26048, 107.
preprocess.fit_transform(X_train).shape
(26048, 107)
El transformador de datos está listo. Crea la canalización con make_pipeline y, una vez transformados los datos, introdúcelos en la regresión logística.
model = make_pipeline(
preprocess,
LogisticRegression())
Entrenar un modelo con scikit-learn es muy sencillo: basta con llamar a fit en la canalización. Puedes imprimir la precisión con el método score.
model.fit(X_train, y_train) print("logistic regression score: %f" % model.score(X_test, y_test))
logistic regression score: 0.850891
Finalmente, puedes predecir las clases con predict_proba, que devuelve la probabilidad de cada clase. Ten en cuenta que la suma de ambas probabilidades es igual a uno.
model.predict_proba(X_test)
array([[0.83576663, 0.16423337],
[0.94582765, 0.05417235],
[0.64760587, 0.35239413],
...,
[0.99639252, 0.00360748],
[0.02072181, 0.97927819],
[0.56781353, 0.43218647]])
Paso 4) Usar nuestro pipeline en una búsqueda en grid
Ajustar los hiperparámetros, los valores que fijan la estructura del modelo, puede resultar tedioso y agotador.
Una forma de evaluar el modelo sería cambiar el tamaño del conjunto de entrenamiento y medir el rendimiento, repitiendo el ejercicio diez veces para observar la dispersión de la puntuación. Eso implica mucho trabajo manual.
En cambio, scikit-learn proporciona funciones que realizan el ajuste de parámetros y la validación cruzada por usted.
Validación cruzada
La validación cruzada implica que, durante el entrenamiento, el conjunto de entrenamiento se divide n veces en subconjuntos y el modelo se evalúa n veces. Si se establece cv en 10, el modelo se entrena y evalúa diez veces. En cada ronda, el clasificador se entrena con nueve subconjuntos elegidos al azar y el décimo se reserva para la evaluación.
búsqueda de cuadrícula
Cada clasificador tiene hiperparámetros que se pueden ajustar. Puedes probar valores uno a uno o configurar una cuadrícula de parámetros. La documentación de scikit-learn enumera todos los parámetros que acepta el clasificador logístico. Para agilizar el entrenamiento, este ejemplo ajusta únicamente el parámetro C, que controla la regularización. Debe ser positivo, y un valor pequeño otorga mayor peso al regularizador.
Se utiliza el objeto GridSearchCV, que acepta un diccionario con los hiperparámetros a ajustar. Enumere cada hiperparámetro seguido de los valores que desea probar. Para ajustar C, escriba:
- 'logisticregression__C': [0.001, 0.01, 0.1, 1.0] — el nombre del parámetro está precedido por el nombre del clasificador en minúsculas y dos guiones bajos.
El modelo probará cuatro valores diferentes: 0.001, 0.01, 0.1 y 1. Se entrena con 10 pliegues, es decir, cv=10.
from sklearn.model_selection import GridSearchCV # Construct the parameter grid param_grid = { 'logisticregression__C': [0.001, 0.01,0.1, 1.0], }
Ahora puede entrenar el modelo utilizando GridSearchCV con los parámetros grid y cv.
# Train the model grid_clf = GridSearchCV(model, param_grid, cv=10, iid=False) grid_clf.fit(X_train, y_train)
Salida:
GridSearchCV(cv=10, error_score='raise-deprecating', estimator=Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...ty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False))]), fit_params=None, iid=False, n_jobs=1, param_grid={'logisticregression__C': [0.001, 0.01, 0.1, 1.0]}, pre_dispatch='2*n_jobs', refit=True, return_train_score='warn', scoring=None, verbose=0)
Nota de versión: <font dir="auto" style="vertical-align: inherit;">las </font> identificación El argumento visible en esta salida quedó obsoleto en scikit-learn 0.22 y se eliminó en la versión 0.24, por lo que simplemente debería eliminarse de la llamada a GridSearchCV en las versiones actuales.
Para acceder a los mejores parámetros, utilice best_params_.
grid_clf.best_params_
Salida:
{'logisticregression__C': 1.0}
Tras entrenar el modelo con cuatro valores de regularización diferentes, el parámetro óptimo es el siguiente:
print("best logistic regression from grid search: %f" % grid_clf.best_estimator_.score(X_test, y_test))
mejor regresión logística de búsqueda en cuadrícula: 0.850891
Para acceder a las probabilidades previstas:
grid_clf.best_estimator_.predict_proba(X_test)
array([[0.83576677, 0.16423323],
[0.9458291 , 0.0541709 ],
[0.64760416, 0.35239584],
...,
[0.99639224, 0.00360776],
[0.02072033, 0.97927967],
[0.56782222, 0.43217778]])
Modelo XGBoost con scikit-learn
Ahora prueba uno de los clasificadores más potentes del mercado. XGBoost es una mejora del algoritmo de potenciación de gradiente basada en el bosque aleatorio. Su fundamento teórico está fuera del alcance de este análisis. Python Puedes consultar el tutorial de Scikit-learn, pero ten en cuenta que XGBoost ha ganado muchísimas competiciones de Kaggle. En un conjunto de datos de tamaño medio, puede tener un rendimiento igual o superior al de un algoritmo de aprendizaje profundo.
El clasificador es difícil de entrenar porque presenta una gran cantidad de parámetros. Por supuesto, puedes usar GridSearchCV para seleccionarlos automáticamente.
Una mejor opción es RandomizedSearchCV. GridSearchCV se vuelve lento cuando la cuadrícula es grande, ya que el espacio de búsqueda crece con cada parámetro añadido. En cambio, RandomizedSearchCV muestrea aleatoriamente los valores de cada hiperparámetro en cada iteración, por lo que 1,000 iteraciones evalúan 1,000 combinaciones. Por lo demás, funciona de forma muy similar a GridSearchCV.
Necesitas importar xgboost. Si la biblioteca no está instalada, ejecuta pip3 install xgboost, o instálala desde dentro de un Jupyter cuaderno con:
use import sys
!{sys.executable} -m pip install xgboost
A continuación, importa el clasificador y las dos funciones auxiliares de búsqueda:
import xgboost from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import StratifiedKFold
El siguiente paso en este Scikit Python El tutorial consiste en especificar los parámetros a ajustar. La documentación oficial de XGBoost los enumera todos. Para este propósito, Python En el tutorial de Sklearn, solo debes elegir dos hiperparámetros con dos valores cada uno, porque XGBoost tarda mucho tiempo en entrenarse y cada punto adicional de la cuadrícula aumenta el tiempo de espera.
params = {
'xgbclassifier__gamma': [0.5, 1],
'xgbclassifier__max_depth': [3, 4]
}
A continuación, se crea una nueva canalización con el clasificador XGBoost y 600 estimadores. El parámetro n_estimators es ajustable, y un valor elevado puede provocar sobreajuste. Se pueden probar otros valores, pero tenga en cuenta que esto puede llevar horas. El resto de los parámetros mantienen su valor predeterminado.
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1)
)
Puedes mejorar la validación cruzada con el validador cruzado estratificado K-Folds. Aquí solo se utilizan tres pliegues para acelerar el cálculo, aunque esto conlleva cierta pérdida de calidad; para obtener mejores resultados, aumenta este número a 5 o 10 en tu propio equipo. El modelo se entrena durante cuatro iteraciones.
skf = StratifiedKFold(n_splits=3,
shuffle = True,
random_state = 1001)
random_search = RandomizedSearchCV(model_xgb,
param_distributions=params,
n_iter=4,
scoring='accuracy',
n_jobs=4,
cv=skf.split(X_train, y_train),
verbose=3,
random_state=1001)
La búsqueda aleatoria está lista, así que puedes entrenar el modelo.
#grid_xgb = GridSearchCV(model_xgb, params, cv=10, iid=False)
random_search.fit(X_train, y_train)
Fitting 3 folds for each of 4 candidates, totalling 12 fits
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8759645283888057, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8729701715996775, total= 1.0min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8706519235199263, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8735460094437406, total= 1.3min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8722791661868018, total= 57.7s
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8753886905447426, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8697304768486523, total= 1.3min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8740066797189912, total= 1.4min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8707671043538355, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8729701715996775, total= 1.2min
[Parallel(n_jobs=4)]: Done 10 out of 12 | elapsed: 3.6min remaining: 43.5s
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8736611770125533, total= 1.2min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8692697535130154, total= 1.2min
[Parallel(n_jobs=4)]: Done 12 out of 12 | elapsed: 3.6min finished /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/model_selection/_search.py:737: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal. DeprecationWarning)
RandomizedSearchCV(cv=<generator object _BaseKFold.split at 0x1101eb830>,
error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))]),
fit_params=None, iid='warn', n_iter=4, n_jobs=4,
param_distributions={'xgbclassifier__gamma': [0.5, 1], 'xgbclassifier__max_depth': [3, 4]},
pre_dispatch='2*n_jobs', random_state=1001, refit=True,
return_train_score='warn', scoring='accuracy', verbose=3)
Como puede verse, XGBoost obtiene mejores resultados que la regresión logística anterior.
print("Mejores parameter", random_search.best_params_) print("best logistic regression from grid search: %f" % random_search.best_estimator_.score(X_test, y_test))
Mejores parameter {'xgbclassifier__max_depth': 3, 'xgbclassifier__gamma': 0.5}
best logistic regression from grid search: 0.873157
random_search.best_estimator_.predict(X_test)
array(['<=50K', '<=50K', '<=50K', ..., '<=50K', '>50K', '<=50K'], dtype=object)
Cree DNN con MLPClassifier en scikit-learn
Finalmente, puedes entrenar una red neuronal con scikit-learn. El método es el mismo que para cualquier otro clasificador, y el estimador es MLPClassifier.
from sklearn.neural_network import MLPClassifier
La red que se muestra a continuación se define con:
- Adán solucionador
- Función de activación ReLU
- Alfa = 0.0001
- Tamaño del lote: 150
- Dos capas ocultas con 200 y 100 neuronas respectivamente
model_dnn = make_pipeline(
preprocess,
MLPClassifier(solver='adam',
alpha=0.0001,
activation='relu',
batch_size=150,
hidden_layer_sizes=(200, 100),
random_state=1))
Puedes cambiar el número de capas para mejorar el modelo.
model_dnn.fit(X_train, y_train) print("DNN regression score: %f" % model_dnn.score(X_test, y_test))
Puntuación de regresión DNN: 0.821253
LIME: Confía en tu modelo
Ahora que tienes un buen modelo, necesitas una forma de confiar en él. Los algoritmos de aprendizaje automático, especialmente los bosques aleatorios y las redes neuronales, se conocen como modelos de caja negra: funcionan, pero nadie puede ver por qué.
Tres investigadores crearon una herramienta que muestra cómo la computadora llega a una predicción. Su artículo es “¿Por qué debería confiar en ti?”y el algoritmo que publicaron se llama Explicaciones Locales Interpretables e Independientes del Modelo (LIME, por sus siglas en inglés).
Pongamos un ejemplo. A veces, no se sabe si una predicción de aprendizaje automático es fiable. Un médico no puede aceptar un diagnóstico simplemente porque lo haya generado un ordenador, y es necesario saber si un modelo es fiable antes de implementarlo.
Imagina poder ver por qué un clasificador hizo una predicción, incluso en modelos tan complejos como redes neuronales, bosques aleatorios o máquinas de vectores de soporte (SVM) con un núcleo arbitrario. Resulta mucho más fácil confiar en una predicción cuando se conocen las razones que la justifican, y también es más fácil decidir cuándo no se debe confiar en un modelo. LIME te indica qué características influyeron en la decisión del clasificador.
Preparación de datos
Hay un par de cosas que debes cambiar para ejecutar LIME con Python. Primero, instala lime en la terminal con pip install lime.
Lime utiliza un objeto LimeTabularExplainer para aproximar el modelo localmente. Este objeto requiere:
- un conjunto de datos en NumPy formato
- El nombre de las funciones: feature_names
- El nombre de las clases: class_names
- El índice de la columna de características categóricas: categorical_features
- El nombre del grupo para cada característica categórica: nombres_categóricos
Crea el conjunto de trenes NumPy
Puedes copiar y convertir df_train de pandas a NumPy muy fácilmente.
df_train.head(5)
# Create numpy data
df_lime = df_train
df_lime.head(3)
Obtener el nombre de la clase
Se puede acceder a la etiqueta a través de unique(). Debería ver:
- '<= 50 K'
- '> 50K'
# Get the class name
class_names = df_lime.label.unique()
class_names
array(['<=50K', '>50K'], dtype=object)
Indexar las columnas de características categóricas
Utiliza el método que aprendiste anteriormente para obtener el nombre de cada grupo. Codifica la etiqueta con LabelEncoder y repite la operación en cada característica categórica.
## import sklearn.preprocessing as preprocessing categorical_names = {} for feature in CATE_FEATURES: le = preprocessing.LabelEncoder() le.fit(df_lime[feature]) df_lime[feature] = le.transform(df_lime[feature]) categorical_names[feature] = le.classes_ print(categorical_names)
{'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
df_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 label object dtype: object
Ahora que el conjunto de datos está listo, puede crear los diferentes conjuntos de datos que se muestran en los ejemplos de Scikit-learn a continuación. Los datos se transforman fuera del proceso para evitar errores con LIME: el conjunto de entrenamiento que se pasa a LimeTabularExplainer debe ser una matriz NumPy sin cadenas de texto, y el método anterior ya ha generado una.
from sklearn.model_selection import train_test_split X_train_lime, X_test_lime, y_train_lime, y_test_lime = train_test_split(df_lime[features], df_lime.label, test_size = 0.2, random_state=0) X_train_lime.head(5)
Puedes crear la canalización con los parámetros óptimos encontrados por XGBoost.
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(max_depth = 3,
gamma = 0.5,
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1))
model_xgb.fit(X_train_lime, y_train_lime)
/Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py:351: FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values. If you want the future behavior and silence this warning, you can specify "categories='auto'."In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly. warnings.warn(msg, FutureWarning)
Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,... reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None, silent=True, subsample=1))])
Recibirás una advertencia. Explica que no necesitas crear un codificador de etiquetas antes del pipeline. Si no usas LIME, el método de la primera parte de este tutorial de Aprendizaje Automático con Scikit-learn es válido. De lo contrario, mantén este enfoque: primero crea un conjunto de datos codificado y luego aplica el codificador one-hot dentro del pipeline.
print("best logistic regression from grid search: %f" % model_xgb.score(X_test_lime, y_test_lime))
best logistic regression from grid search: 0.873157
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
Antes de usar LIME, crea una matriz NumPy con las características de las filas clasificadas erróneamente. Puedes usar esa lista más adelante para comprender qué indujo al error del clasificador.
temp = pd.concat([X_test_lime, y_test_lime], axis= 1) temp['predicted'] = model_xgb.predict(X_test_lime) temp['wrong']= temp['label'] != temp['predicted'] temp = temp.query('wrong==True').drop('wrong', axis=1) temp= temp.sort_values(by=['label']) temp.shape
(826, 16)
A continuación, creas una función lambda que recupera la predicción del modelo para los nuevos datos. La necesitarás pronto.
predict_fn = lambda x: model_xgb.predict_proba(x).astype(float)
X_test_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 dtype: object
predict_fn(X_test_lime)
array([[7.96461046e-01, 2.03538969e-01],
[9.51730132e-01, 4.82698716e-02],
[7.93448269e-01, 2.06551731e-01],
...,
[9.90314305e-01, 9.68566816e-03],
[6.45816326e-04, 9.99354184e-01],
[9.71042812e-01, 2.89571714e-02]])
Conviertes el dataframe de pandas en un array de NumPy.
X_train_lime = X_train_lime.values X_test_lime = X_test_lime.values X_test_lime
array([[4.00000e+01, 5.00000e+00, 1.93524e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.70000e+01, 4.00000e+00, 2.16481e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.50000e+01, 4.00000e+00, 2.56263e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
...,
[2.80000e+01, 6.00000e+00, 2.11032e+05, ..., 0.00000e+00,
4.00000e+01, 2.50000e+01],
[4.40000e+01, 4.00000e+00, 1.67005e+05, ..., 0.00000e+00,
6.00000e+01, 3.80000e+01],
[5.30000e+01, 4.00000e+00, 2.57940e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01]])
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
print(features,
class_names,
categorical_features,
categorical_names)
['age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] ['<=50K' '>50K'] [1, 3, 5, 6, 7, 8, 9, 13] {'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private', 'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'], dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th', 'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad', 'Masters', 'Preschool', 'Prof-school', 'Some-college'], dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse', 'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'], dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair', 'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners', 'Machine-op-inspct', 'Other-service', 'Priv-house-serv', 'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support', 'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child', 'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other', 'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba', 'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England', 'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras', 'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica', 'Japan', 'Laos', 'Mexico', 'Nicaragua', 'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland', 'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan', 'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam', 'Yugoslavia'], dtype=object)}
import lime import lime.lime_tabular ### Train should be label encoded not one hot encoded explainer = lime.lime_tabular.LimeTabularExplainer(X_train_lime , feature_names = features, class_names=class_names, categorical_features=categorical_features, categorical_names=categorical_names, kernel_width=3)
Ahora, elige un hogar al azar del conjunto de prueba y observa tanto la predicción como el método que utilizó el ordenador para llegar a ella.
import numpy as np np.random.seed(1) i = 100 print(y_test_lime.iloc[i]) >50K
X_test_lime[i]
array([4.20000e+01, 4.00000e+00, 1.76286e+05, 7.00000e+00, 1.20000e+01,
2.00000e+00, 4.00000e+00, 0.00000e+00, 4.00000e+00, 1.00000e+00,
0.00000e+00, 0.00000e+00, 4.00000e+01, 3.80000e+01])
Puedes usar el explicador con explain_instance para examinar el razonamiento detrás del modelo. El gráfico que genera se muestra a continuación.
exp = explainer.explain_instance(X_test_lime[i], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

El clasificador predijo correctamente que este hogar tiene ingresos superiores a 50.
Lo primero que cabe destacar es que el clasificador no es muy fiable. Predice un ingreso superior a 50.000 con una probabilidad del 64%, porcentaje que se ve influenciado por las ganancias de capital y el estado civil. El color azul contribuye negativamente a la categoría positiva, mientras que la línea naranja lo hace positivamente.
El clasificador duda porque la plusvalía de este hogar es cero, mientras que la plusvalía suele ser un buen indicador de riqueza. Además, el hogar trabaja menos de 40 horas semanales. La edad, la ocupación y el sexo influyen positivamente.
Si el estado civil fuera soltero, el clasificador habría predicho un ingreso inferior a 50 (0.64 – 0.18 = 0.46).
Ahora pruebe con otro hogar, uno que haya sido clasificado erróneamente. La tabla explicativa se encuentra después del código.
temp.head(3) temp.iloc[1,:-2]
age 58 workclass 4 fnlwgt 68624 education 11 education_num 9 marital 2 occupation 4 relationship 0 race 4 sex 1 capital_gain 0 capital_loss 0 hours_week 45 native_country 38 Name: 20931, dtype: object
i = 1 print('This observation is', temp.iloc[i,-2:])
This observation is label <=50K
predicted >50K
Name: 20931, dtype: object
exp = explainer.explain_instance(temp.iloc[1,:-2], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

El clasificador predijo un ingreso inferior a 50, lo cual es erróneo. Este hogar es inusual: no tiene ni ganancias ni pérdidas de capital, la persona está divorciada, tiene cerca de 60 años y un nivel educativo superior a 12. Siguiendo el patrón general, el clasificador situó el ingreso del hogar por debajo de 50.
Prueba LIME tú mismo y notarás muchos errores garrafales del clasificador. El repositorio de GitHub del autor de la biblioteca contiene documentación adicional para la clasificación de imágenes y texto.
Referencia de comandos de Scikit-learn
A continuación se muestra una lista de comandos útiles que se aplican a la versión 0.20 de scikit-learn y posteriores.
| Task | Función o clase |
|---|---|
| Crear el conjunto de datos de entrenamiento/prueba | tren_prueba_dividir |
| construir una tubería | |
| Seleccione las columnas y aplique la transformación. | crear_transformador_de_columnas |
| Tipo de transformación | |
| Estandarizar | Escalador estándar |
| Escala mínima-máxima | Escalador MínMáx |
| Normalizar | Normalizador |
| Imputar valores faltantes | Computadora simple |
| Convertir categórico | OneHotEncoder |
| Ajustar y transformar los datos | encajar_transformar |
| hacer la tubería | hacer_tubería |
| Modelo basica | |
| Regresión logística | Regresión logística |
| XGBoost | Clasificador XGB |
| Red neuronal | Clasificador MLP |
| búsqueda de cuadrícula | CuadrículaBuscarCV |
| Búsqueda aleatoria | Búsqueda aleatoriaCV |