Samouczek Scikit-Learn: Jak zainstalować i przykłady Scikit-Learn
⚡ Inteligentne podsumowanie
Scikit-learn jest oprogramowaniem typu open source Python biblioteka obejmująca przetwarzanie wstępne, klasyfikację, regresję, klastrowanie i wybór modelu za pomocą jednego spójnego interfejsu estymatora, dzięki czemu kompletny proces uczenia maszynowego jest krótki, czytelny i powtarzalny, od surowych danych po punktowane prognozy.

Czym jest Scikit-learn?
Nauka scikitu jest open-source Python biblioteka dla uczenie maszynoweObsługuje dobrze znane algorytmy, takie jak KNN, gradient boosting, losowy las i SVM, i jest zbudowany na bazie numpy i SciPy. Scikit-learn jest szeroko wykorzystywany w konkursach Kaggle, a także w czołowych firmach technologicznych. Obejmuje on przetwarzanie wstępne, redukcję wymiarowości, klasyfikację, regresję, klasteryzację i selekcję modeli.
Scikit-learn ma jedną z najlepszych dokumentacji spośród wszystkich bibliotek open source. Zawiera nawet interaktywny wykres estymatora, Wybór właściwego rzeczoznawcy, który przeprowadzi Cię od rozmiaru Twojego zbioru danych do krótkiej listy algorytmów wartych wypróbowania.
Poniższy rysunek ilustruje sposób działania Scikit-learn.
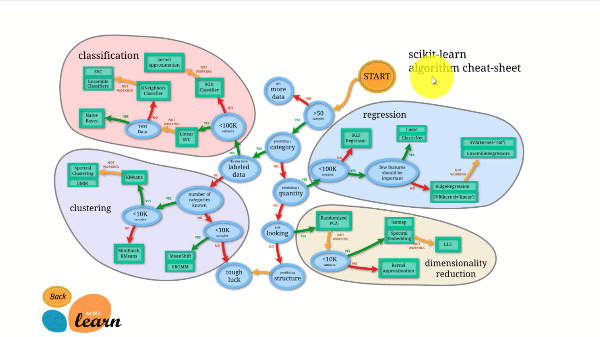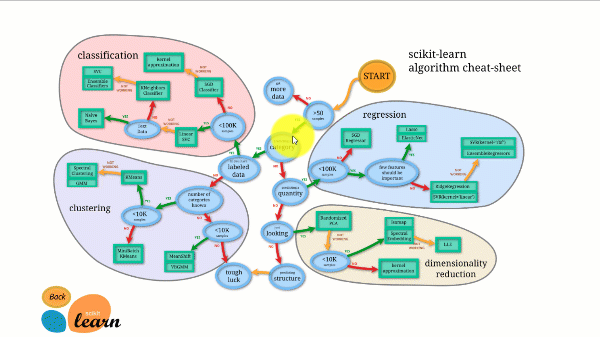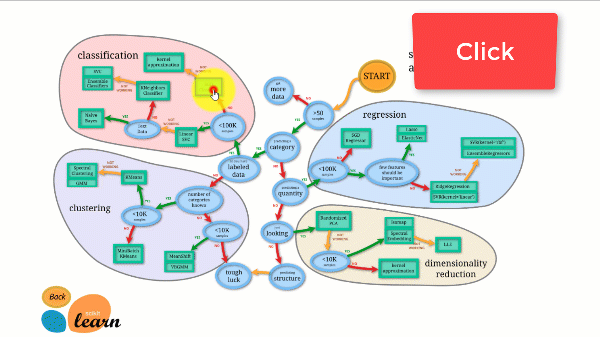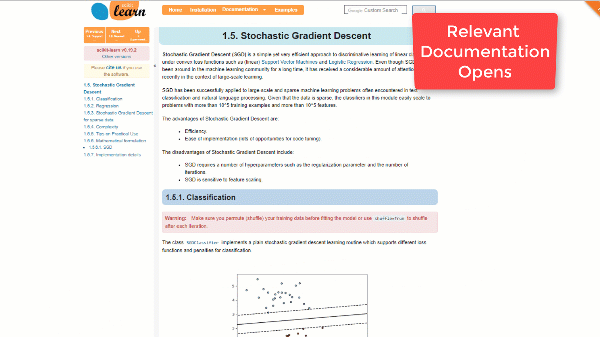
Scikit-learn nie jest trudny w użyciu i daje doskonałe rezultaty. Uczy się jednak na procesorze: praca jest paralelizowana na rdzeniach z argumentem n_jobs, a nie na GPU. Uruchomienie algorytmu głębokiego uczenia z jego użyciem jest możliwe, ale rzadko optymalne, zwłaszcza jeśli wiesz już, jak go używać. TensorFlow.
Jak pobrać i zainstalować Scikit-learn
Teraz w tym Python Samouczek Scikit-learn, w którym dowiesz się, jak pobrać i zainstalować Scikit-learn:
Opcja 1: AWS
Scikit-learn można używać w AWS. Obraz Dockera z preinstalowanym scikit-learn całkowicie oszczędza czas konfiguracji.
Aby zainstalować wersję dla programistów, uruchom poniższe polecenie w Jupyter:
import sys !{sys.executable} -m pip install git+git://github.com/scikit-learn/scikit-learn.git
Opcja 2: Mac lub Windows za pomocą Anacondy
Aby dowiedzieć się więcej o instalacji Anacondy, zapoznaj się z jak pobrać i zainstalować TensorFlow.
W momencie pisania tego poradnika twórcy scikit wydali wersję rozwojową, która rozwiązała problemy występujące w ówczesnej wersji, dlatego poniższe kroki wykorzystują tę kompilację deweloperską. Na nowszej maszynie obecna wersja stabilna zawiera już wszystkie użyte tu transformatory, a pip install -U scikit-learn wystarczy.
Jak zainstalować scikit-learn w środowisku Conda
Jeśli zainstalowałeś scikit-learn przy użyciu środowiska conda, wykonaj poniższe kroki, aby dokonać aktualizacji do wersji 0.20.
Krok 1) Aktywuj środowisko tensorflow
source activate hello-tf
Krok 2) Usuń scikit-learn za pomocą polecenia conda
conda remove scikit-learn
Krok 3) Zainstaluj wersję dla programistów
Zainstaluj wersję deweloperską scikit-learn wraz z niezbędnymi bibliotekami.
conda install -c anaconda git
pip install Cython
pip install h5py
pip install git+git://github.com/scikit-learn/scikit-learn.git
UWAGA: Windows użytkownicy potrzebują Microsoft Wizualny C++ 14. Możesz to zdobyć w tym miejscu.
Przykład Scikit-Learn z uczeniem maszynowym
Ten samouczek Scikit jest podzielony na dwie części:
- Uczenie maszynowe za pomocą scikit-learn
- Jak zaufać swojemu modelowi z LIME
W pierwszej części szczegółowo opisano, jak zbudować potok, utworzyć model i dostroić hiperparametry, natomiast w drugiej omówiono interpretację modelu.
Krok 1) Zaimportuj dane
W tym samouczku Scikit Learn będziesz korzystać ze zbioru danych spisu powszechnego dla dorosłych.
Plik jest odczytywany bezpośrednio z repozytorium uczenia maszynowego UCI w poniższym kodzie, więc nie jest wymagane ręczne pobieranie. Jeśli interesują Cię statystyki opisowe, warto zapoznać się z narzędziami Dive i Overview. Więcej informacji można znaleźć tutaj. ten poradnik aby dowiedzieć się więcej o nurkowaniu i jego przeglądzie.
Importujesz zbiór danych za pomocą Pandas. Pamiętaj, że musisz przekonwertować zmienne ciągłe na format zmiennoprzecinkowy.
Ten zbiór danych obejmuje osiem zmiennych kategorycznych wymienionych w CATE_FEATURES:
- klasa pracy
- Edukacja
- małżeński
- zawód
- związek
- wyścig
- seks
- ojczyźnie
Zawiera również sześć zmiennych ciągłych wymienionych w CONTI_FEATURES:
- wiek
- fnlwgt
- edukacja_num
- zysk kapitałowy
- strata_kapitału
- godziny_tydzień
Listy są tutaj wypełniane ręcznie, dzięki czemu masz jaśniejszy obraz tego, które kolumny są używane. Szybciej można utworzyć listę kolumn kategorycznych lub ciągłych:
## List Categorical CATE_FEATURES = df_train.iloc[:,:-1].select_dtypes('object').columns print(CATE_FEATURES) ## List continuous CONTI_FEATURES = df_train._get_numeric_data() print(CONTI_FEATURES)
Oto kod do importowania danych:
# Import dataset import pandas as pd ## Define path data COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country', 'label'] ### Define continuous list CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week'] ### Define categorical list CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country'] ## Prepare the data features = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data" df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False) df_train[CONTI_FEATURES] =df_train[CONTI_FEATURES].astype('float64') df_train.describe()
Wywołanie describe() na ramce zwraca statystyki podsumowujące dla sześciu ciągłych kolumn:
| wiek | fnlwgt | edukacja_num | zysk kapitałowy | strata_kapitału | godziny_tydzień | |
|---|---|---|---|---|---|---|
| liczyć | 32561.000000 | 3.256100e + 04 | 32561.000000 | 32561.000000 | 32561.000000 | 32561.000000 |
| oznaczać | 38.581647 | 1.897784e + 05 | 10.080679 | 1077.648844 | 87.303830 | 40.437456 |
| std | 13.640433 | 1.055500e + 05 | 2.572720 | 7385.292085 | 402.960219 | 12.347429 |
| min | 17.000000 | 1.228500e + 04 | 1.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 28.000000 | 1.178270e + 05 | 9.000000 | 0.000000 | 0.000000 | 40.000000 |
| 50% | 37.000000 | 1.783560e + 05 | 10.000000 | 0.000000 | 0.000000 | 40.000000 |
| 75% | 48.000000 | 2.370510e + 05 | 12.000000 | 0.000000 | 0.000000 | 45.000000 |
| max | 90.000000 | 1.484705e + 06 | 16.000000 | 99999.000000 | 4356.000000 | 99.000000 |
Możesz sprawdzić liczbę unikalnych wartości cechy native_country. Tylko jedno gospodarstwo domowe pochodzi z Holandii. To gospodarstwo domowe nie dostarcza żadnych informacji i zgłosi błąd podczas trenowania.
df_train.native_country.value_counts()
United-States 29170 Mexico 643 ? 583 Philippines 198 Germany 137 Canada 121 Puerto-Rico 114 El-Salvador 106 India 100 Cuba 95 England 90 Jamaica 81 South 80 China 75 Italy 73 Dominican-Republic 70 Vietnam 67 Guatemala 64 Japan 62 Poland 60 Columbia 59 Taiwan 51 Haiti 44 Iran 43 Portugal 37 Nicaragua 34 Peru 31 France 29 Greece 29 Ecuador 28 Ireland 24 Hong 20 Cambodia 19 Trinadad&Tobago 19 Thailand 18 Laos 18 Yugoslavia 16 Outlying-US(Guam-USVI-etc) 14 Honduras 13 Hungary 13 Scotland 12 Holand-Netherlands 1 Name: native_country, dtype: int64
Możesz wykluczyć ten nieinformatywny wiersz ze zbioru danych:
## Drop Netherland, because only one row df_train = df_train[df_train.native_country != "Holand-Netherlands"]
Następnie przechowujesz położenie obiektów ciągłych na liście. Będziesz go potrzebować w następnym kroku do zbudowania rurociągu.
Poniższy kod przechodzi przez wszystkie nazwy kolumn w CONTI_FEATURES, odczytuje każdą lokalizację (czyli numer kolumny) i dołącza ją do listy o nazwie conti_features.
## Get the column index of the categorical features conti_features = [] for i in CONTI_FEATURES: position = df_train.columns.get_loc(i) conti_features.append(position) print(conti_features)
[0, 2, 10, 4, 11, 12]
Następny blok wykonuje to samo zadanie dla zmiennych kategorycznych.
## Get the column index of the categorical features categorical_features = [] for i in CATE_FEATURES: position = df_train.columns.get_loc(i) categorical_features.append(position) print(categorical_features)
[1, 3, 5, 6, 7, 8, 9, 13]
Przyjrzyjmy się teraz samemu zbiorowi danych. Każda cecha kategoryczna jest ciągiem znaków, a modelowi nie można podać wartości ciągu znaków, więc zbiór danych musi zostać przekształcony za pomocą zmiennych pozornych.
df_train.head(5)
W rzeczywistości potrzebujesz jednej kolumny dla każdej grupy w każdej funkcji. Najpierw uruchom poniższy kod, aby obliczyć całkowitą liczbę potrzebnych kolumn.
print(df_train[CATE_FEATURES].nunique(), 'There are',sum(df_train[CATE_FEATURES].nunique()), 'groups in the whole dataset')
workclass 9
education 16
marital 7
occupation 15
relationship 6
race 5
sex 2
native_country 41
dtype: int64 There are 101 groups in the whole dataset
Cały zbiór danych zawiera 101 grup, jak pokazano powyżej. Sama cecha klasy roboczej ma dziewięć grup. Możesz wyświetlić nazwy grup za pomocą poniższego kodu; funkcja unique() zwraca odrębne wartości każdej cechy kategorycznej.
for i in CATE_FEATURES: print(df_train[i].unique())
['State-gov' 'Self-emp-not-inc' 'Private' 'Federal-gov' 'Local-gov' '?' 'Self-emp-inc' 'Without-pay' 'Never-worked'] ['Bachelors' 'HS-grad' '11th' 'Masters' '9th' 'Some-college' 'Assoc-acdm' 'Assoc-voc' '7th-8th' 'Doctorate' 'Prof-school' '5th-6th' '10th' '1st-4th' 'Preschool' '12th'] ['Never-married' 'Married-civ-spouse' 'Divorced' 'Married-spouse-absent' 'Separated' 'Married-AF-spouse' 'Widowed'] ['Adm-clerical' 'Exec-managerial' 'Handlers-cleaners' 'Prof-specialty' 'Other-service' 'Sales' 'Craft-repair' 'Transport-moving' 'Farming-fishing' 'Machine-op-inspct' 'Tech-support' '?' 'Protective-serv' 'Armed-Forces' 'Priv-house-serv'] ['Not-in-family' 'Husband' 'Wife' 'Own-child' 'Unmarried' 'Other-relative'] ['White' 'Black' 'Asian-Pac-Islander' 'Amer-Indian-Eskimo' 'Other'] ['Male' 'Female'] ['United-States' 'Cuba' 'Jamaica' 'India' '?' 'Mexico' 'South' 'Puerto-Rico' 'Honduras' 'England' 'Canada' 'Germany' 'Iran' 'Philippines' 'Italy' 'Poland' 'Columbia' 'Cambodia' 'Thailand' 'Ecuador' 'Laos' 'Taiwan' 'Haiti' 'Portugal' 'Dominican-Republic' 'El-Salvador' 'France' 'Guatemala' 'China' 'Japan' 'Yugoslavia' 'Peru' 'Outlying-US(Guam-USVI-etc)' 'Scotland' 'Trinadad&Tobago' 'Greece' 'Nicaragua' 'Vietnam' 'Hong' 'Ireland' 'Hungary']
Zbiór danych szkoleniowych będzie zatem zawierał 101 + 6 kolumn: grupy „one-hot” i sześć ciągłych cech.
Scikit-learn może wykonać konwersję w dwóch krokach:
- Zamień ciąg na ID. State-gov staje się ID 1, Self-emp-not-inc staje się ID 2 itd. LabelEncoder zrobi to za Ciebie.
- Przenieś każdy identyfikator do nowej kolumny. Zbiór danych ma 101 identyfikatorów grup, więc każda grupa cech kategorycznych będzie miała 101 kolumn. Scikit-learn udostępnia OneHotEncoder do tej operacji.
Krok 2) Utwórz zestaw pociągowy/testowy
Teraz, gdy zbiór danych jest już gotowy, podziel go w proporcji 80/20: 80 procent na zbiór treningowy i 20 procent na zbiór testowy.
Możesz użyć train_test_split. Pierwszy argument to ramka danych cech, a drugi to etykieta. Rozmiar zestawu testowego ustawiasz za pomocą test_size.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df_train[features], df_train.label, test_size = 0.2, random_state=0) X_train.head(5) print(X_train.shape, X_test.shape)
(26048, 14) (6512, 14)
Krok 3) Zbuduj rurociąg
Pipeline ułatwia zasilanie modelu spójnymi danymi. Chodzi o to, aby surowe dane przechodziły przez jeden obiekt, który wykonuje każdą operację po kolei.
W tym zbiorze danych konieczna jest standaryzacja zmiennych ciągłych i konwersja zmiennych kategorycznych. Każda operacja może odbywać się w ramach potoku: brakujące wartości można zastąpić średnią lub medianą, a także tworzyć nowe zmienne.
Masz wybór: zakodować na stałe oba procesy lub zbudować potok. Zakodowanie na stałe może spowodować wyciek danych testowych do dopasowanych statystyk i z czasem prowadzić do niespójności, dlatego potok jest lepszym rozwiązaniem.
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder from sklearn.compose import ColumnTransformer, make_column_transformer from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression
Przed podaniem danych do klasyfikatora logistycznego rurociąg wykonuje dwie operacje:
- Standaryzuj zmienną: StandardScaler()
- Konwertuj cechy kategoryczne: OneHotEncoder(sparse=False)
Oba kroki wykonujesz za pomocą make_column_transformer. W momencie pisania tego poradnika funkcja ta nie znajdowała się w wydanej wersji scikit-learn (0.19), dlatego użyto kompilacji deweloperskiej; jest ona dostępna w każdej stabilnej wersji od 0.20.
Funkcja make_column_transformer jest prosta: deklarujesz, które kolumny mają zostać przekształcone i jaką transformację zastosować. Aby ujednolicić przekazywane funkcje ciągłe:
- conti_features, StandardScaler() wewnątrz make_column_transformer
- conti_features: lista ciągłych kolumn
- StandardScaler: standaryzuje te kolumny
Obiekt OneHotEncoder wewnątrz make_column_transformer automatycznie koduje etykiety.
preprocess = make_column_transformer(
(conti_features, StandardScaler()),
### Need to be numeric not string to specify columns name
(categorical_features, OneHotEncoder(sparse=False))
)
Uwaga dotycząca wersji: Dwa argumenty w powyższym bloku zostały przeniesione. Obecne wersje oczekują najpierw transformatora, a następnie kolumn. rzadki Został zmieniony rzadkie_wyjście w scikit-learn 1.2 i usunięto w 1.4, więc nowszy kod odczytuje OneHotEncoder(sparse_output=False).
Możesz sprawdzić, czy potok działa za pomocą fit_transform. Wynik powinien mieć kształt 26048, 107.
preprocess.fit_transform(X_train).shape
(26048, 107)
Transformator danych jest gotowy. Tworzysz potok za pomocą make_pipeline, a po transformacji danych wprowadzasz regresję logistyczną.
model = make_pipeline(
preprocess,
LogisticRegression())
Trenowanie modelu za pomocą scikit-learn jest wtedy banalnie proste: wywołaj fit w potoku. Możesz wydrukować dokładność za pomocą metody score.
model.fit(X_train, y_train) print("logistic regression score: %f" % model.score(X_test, y_test))
logistic regression score: 0.850891
Na koniec możesz przewidzieć klasy za pomocą funkcji predict_proba, która zwraca prawdopodobieństwo każdej klasy. Zauważ, że suma tych dwóch prawdopodobieństw wynosi jeden.
model.predict_proba(X_test)
array([[0.83576663, 0.16423337],
[0.94582765, 0.05417235],
[0.64760587, 0.35239413],
...,
[0.99639252, 0.00360748],
[0.02072181, 0.97927819],
[0.56781353, 0.43218647]])
Krok 4) Korzystanie z naszego potoku w wyszukiwaniu siatki
Dostrajanie hiperparametrów, czyli wartości ustalających strukturę modelu, może być żmudne i wyczerpujące.
Jednym ze sposobów oceny modelu byłaby zmiana rozmiaru zestawu treningowego i zmierzenie wydajności, powtarzając ćwiczenie dziesięć razy, aby zobaczyć rozrzut wyników. To dużo pracy ręcznej.
Zamiast tego scikit-learn udostępnia funkcje, które wykonują za Ciebie dostrajanie parametrów i walidację krzyżową.
Walidacja krzyżowa
Walidacja krzyżowa oznacza, że podczas treningu zbiór treningowy jest dzielony n razy na rzędy, a model jest oceniany n razy. Jeśli cv jest ustawione na 10, model jest trenowany i oceniany dziesięć razy. W każdej rundzie klasyfikator trenuje na dziewięciu losowo wybranych rzędach, a dziesiąty rzęd pozostaje do oceny.
Wyszukiwanie w siatce
Każdy klasyfikator ma hiperparametry do dostrojenia. Można testować wartości pojedynczo lub ustawić siatkę parametrów. Dokumentacja scikit-learn zawiera listę wszystkich parametrów akceptowanych przez klasyfikator logistyczny. Aby przyspieszyć proces uczenia, ten przykład dostraja tylko parametr C, który kontroluje regularyzację. Musi on być dodatni, a mała wartość nadaje regularyzatorowi większą wagę.
Używasz obiektu GridSearchCV, który pobiera słownik hiperparametrów do dostrojenia. Wypisz każdy hiperparametr, a następnie wartości, które chcesz wypróbować. Aby dostroić C, piszesz:
- 'logisticregression__C': [0.001, 0.01, 0.1, 1.0] — nazwa parametru jest poprzedzona nazwą klasyfikatora pisaną małymi literami i dwoma znakami podkreślenia.
Model wypróbuje cztery różne wartości: 0.001, 0.01, 0.1 i 1. Jest trenowany 10-krotnie, czyli cv=10.
from sklearn.model_selection import GridSearchCV # Construct the parameter grid param_grid = { 'logisticregression__C': [0.001, 0.01,0.1, 1.0], }
Teraz możesz trenować model za pomocą GridSearchCV z parametrami grid i cv.
# Train the model grid_clf = GridSearchCV(model, param_grid, cv=10, iid=False) grid_clf.fit(X_train, y_train)
Wyjście:
GridSearchCV(cv=10, error_score='raise-deprecating', estimator=Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...ty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False))]), fit_params=None, iid=False, n_jobs=1, param_grid={'logisticregression__C': [0.001, 0.01, 0.1, 1.0]}, pre_dispatch='2*n_jobs', refit=True, return_train_score='warn', scoring=None, verbose=0)
Uwaga dotycząca wersji: dotychczasowy nie wiem argument widoczny w tym wyniku został uznany za przestarzały w wersji scikit-learn 0.22 i usunięty w wersji 0.24, więc należy go po prostu usunąć z wywołania GridSearchCV w bieżących wersjach.
Aby uzyskać dostęp do najlepszych parametrów, należy użyć best_params_.
grid_clf.best_params_
Wyjście:
{'logisticregression__C': 1.0}
Po wytrenowaniu modelu przy użyciu czterech różnych wartości regularyzacji optymalny parametr wynosi:
print("best logistic regression from grid search: %f" % grid_clf.best_estimator_.score(X_test, y_test))
najlepsza regresja logistyczna z wyszukiwania w siatce: 0.850891
Aby uzyskać dostęp do przewidywanych prawdopodobieństw:
grid_clf.best_estimator_.predict_proba(X_test)
array([[0.83576677, 0.16423323],
[0.9458291 , 0.0541709 ],
[0.64760416, 0.35239584],
...,
[0.99639224, 0.00360776],
[0.02072033, 0.97927967],
[0.56782222, 0.43217778]])
Model XGBoost z nauką scikit
Teraz wypróbuj jeden z najsilniejszych klasyfikatorów na rynku. XGBoost to udoskonalenie lasu losowego, które zwiększa gradient. Jego podstawy teoretyczne wykraczają poza zakres tego artykułu. Python Samouczek Scikit, ale pamiętaj, że XGBoost wygrał wiele konkursów Kaggle. Na zbiorze danych średniej wielkości może działać równie dobrze, jak algorytm głębokiego uczenia, a nawet lepiej.
Klasyfikator jest trudny do wytrenowania, ponieważ udostępnia dużą liczbę parametrów. Możesz oczywiście użyć GridSearchCV, aby je wybrać za siebie.
Lepszym rozwiązaniem jest RandomizedSearchCV. GridSearchCV staje się wolniejszy, gdy siatka jest duża, ponieważ przestrzeń wyszukiwania rośnie z każdym dodanym parametrem. RandomizedSearchCV losowo losuje wartości każdego hiperparametru w każdej iteracji, więc 1,000 iteracji oblicza 1,000 kombinacji. Poza tym działa podobnie jak GridSearchCV.
Musisz zaimportować xgboost. Jeśli biblioteka nie jest zainstalowana, uruchom pip3 install xgboost lub zainstaluj ją z poziomu Jupyter notatnik z:
use import sys
!{sys.executable} -m pip install xgboost
Następnie zaimportuj klasyfikator i dwa pomocniki wyszukiwania:
import xgboost from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import StratifiedKFold
Następny krok w tym Scikicie Python Celem samouczka jest określenie parametrów do dostrojenia. Oficjalna dokumentacja XGBoost zawiera ich listę. Na potrzeby tego Python W samouczku Sklearn wybierasz tylko dwa hiperparametry, każdy z dwiema wartościami, ponieważ trenowanie XGBoost zajmuje dużo czasu, a każdy dodatkowy punkt siatki wydłuża czas oczekiwania.
params = {
'xgbclassifier__gamma': [0.5, 1],
'xgbclassifier__max_depth': [3, 4]
}
Następnie konstruujesz nowy potok z klasyfikatorem XGBoost i 600 estymatorami. Zmienna n_estimators jest sama w sobie dostrajalna, a wysoka wartość może prowadzić do przeuczenia. Możesz wypróbować inne wartości, ale pamiętaj, że może to zająć kilka godzin. Wszystkie pozostałe parametry zachowują wartości domyślne.
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1)
)
Możesz usprawnić walidację krzyżową za pomocą walidatora krzyżowego Stratified K-Folds. W tym przypadku użyto tylko trzech walidacji, aby przyspieszyć obliczenia, kosztem jakości; zwiększ tę liczbę do 5 lub 10 na własnym komputerze, aby uzyskać lepsze wyniki. Model jest trenowany w czterech iteracjach.
skf = StratifiedKFold(n_splits=3,
shuffle = True,
random_state = 1001)
random_search = RandomizedSearchCV(model_xgb,
param_distributions=params,
n_iter=4,
scoring='accuracy',
n_jobs=4,
cv=skf.split(X_train, y_train),
verbose=3,
random_state=1001)
Wyszukiwanie losowe jest już gotowe, możesz więc trenować model.
#grid_xgb = GridSearchCV(model_xgb, params, cv=10, iid=False)
random_search.fit(X_train, y_train)
Fitting 3 folds for each of 4 candidates, totalling 12 fits
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8759645283888057, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8729701715996775, total= 1.0min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8706519235199263, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8735460094437406, total= 1.3min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8722791661868018, total= 57.7s
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8753886905447426, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8697304768486523, total= 1.3min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8740066797189912, total= 1.4min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8707671043538355, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8729701715996775, total= 1.2min
[Parallel(n_jobs=4)]: Done 10 out of 12 | elapsed: 3.6min remaining: 43.5s
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8736611770125533, total= 1.2min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8692697535130154, total= 1.2min
[Parallel(n_jobs=4)]: Done 12 out of 12 | elapsed: 3.6min finished /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/model_selection/_search.py:737: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal. DeprecationWarning)
RandomizedSearchCV(cv=<generator object _BaseKFold.split at 0x1101eb830>,
error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))]),
fit_params=None, iid='warn', n_iter=4, n_jobs=4,
param_distributions={'xgbclassifier__gamma': [0.5, 1], 'xgbclassifier__max_depth': [3, 4]},
pre_dispatch='2*n_jobs', random_state=1001, refit=True,
return_train_score='warn', scoring='accuracy', verbose=3)
Jak widać, XGBoost daje lepsze wyniki niż wcześniejsza regresja logistyczna.
print("Best parameter", random_search.best_params_) print("best logistic regression from grid search: %f" % random_search.best_estimator_.score(X_test, y_test))
Best parameter {'xgbclassifier__max_depth': 3, 'xgbclassifier__gamma': 0.5}
best logistic regression from grid search: 0.873157
random_search.best_estimator_.predict(X_test)
array(['<=50K', '<=50K', '<=50K', ..., '<=50K', '>50K', '<=50K'], dtype=object)
Utwórz DNN za pomocą MLPClassifier w scikit-learn
Wreszcie, możesz wytrenować sieć neuronową za pomocą samego scikit-learn. Metoda jest taka sama jak w przypadku każdego innego klasyfikatora, a estymatorem jest MLPClassifier.
from sklearn.neural_network import MLPClassifier
Sieć poniżej jest zdefiniowana za pomocą:
- Adam Rozwiązujący
- Funkcja aktywacji ReLU
- Alfa = 0.0001
- Wielkość partii 150 sztuk
- Dwie ukryte warstwy zawierające odpowiednio 200 i 100 neuronów
model_dnn = make_pipeline(
preprocess,
MLPClassifier(solver='adam',
alpha=0.0001,
activation='relu',
batch_size=150,
hidden_layer_sizes=(200, 100),
random_state=1))
Aby ulepszyć model, możesz zmienić liczbę warstw.
model_dnn.fit(X_train, y_train) print("DNN regression score: %f" % model_dnn.score(X_test, y_test))
Wynik regresji DNN: 0.821253
LIME: Zaufaj swojemu modelowi
Skoro masz już dobry model, musisz mu zaufać. Algorytmy uczenia maszynowego, zwłaszcza lasy losowe i sieci neuronowe, nazywane są modelami czarnej skrzynki: działają, ale nikt nie wie, dlaczego.
Trzech badaczy stworzyło narzędzie, które pokazuje, jak komputer osiąga prognozę. Ich artykuł nosi tytuł „Dlaczego miałbym Ci zaufać?”, a opublikowany przez nich algorytm nosi nazwę Local Interpretable Model-Agnostic Explanations (LIME).
Weźmy na przykład. Czasami nie wiadomo, czy prognozie uczenia maszynowego można zaufać. Lekarz nie może zaakceptować diagnozy tylko dlatego, że wystawił ją komputer, a Ty musisz wiedzieć, czy model jest wiarygodny, zanim wdrożysz go do produkcji.
Wyobraź sobie, że możesz zrozumieć, dlaczego dowolny klasyfikator dokonał predykcji, nawet w przypadku modeli tak skomplikowanych, jak sieci neuronowe, lasy losowe czy SVM z dowolnym jądrem. Znacznie łatwiej jest zaufać predykcji, gdy przyczyny jej powstania są widoczne, i równie łatwo jest zdecydować, kiedy modelowi nie należy ufać. LIME informuje, które cechy wpłynęły na decyzję klasyfikatora.
Przygotowywanie danych
Aby uruchomić LIME, musisz zmienić kilka rzeczy PythonNajpierw zainstaluj lime w terminalu za pomocą pip install lime.
Lime używa obiektu LimeTabularExplainer do lokalnej aproksymacji modelu. Ten obiekt wymaga:
- zbiór danych w numpy format
- Nazwa funkcji: nazwy_funkcji
- Nazwa klas: nazwy_klas
- Indeks kolumny cech kategorycznych: categorical_features
- Nazwa grupy dla każdej cechy kategorycznej: categorical_names
Utwórz zestaw pociągów NumPy
Możesz bardzo łatwo skopiować i przekonwertować df_train z pandas do NumPy.
df_train.head(5)
# Create numpy data
df_lime = df_train
df_lime.head(3)
Uzyskaj nazwę klasy
Dostęp do etykiety można uzyskać za pomocą funkcji unique(). Powinieneś zobaczyć:
- „<= 50 tys.”
- „> 50 tys.”
# Get the class name
class_names = df_lime.label.unique()
class_names
array(['<=50K', '>50K'], dtype=object)
Indeksuj kolumny cech kategorycznych
Użyj metody, której nauczyłeś się wcześniej, aby uzyskać nazwę każdej grupy. Kodujesz etykietę za pomocą LabelEncodera i powtarzasz operację dla każdej cechy kategorycznej.
## import sklearn.preprocessing as preprocessing categorical_names = {} for feature in CATE_FEATURES: le = preprocessing.LabelEncoder() le.fit(df_lime[feature]) df_lime[feature] = le.transform(df_lime[feature]) categorical_names[feature] = le.classes_ print(categorical_names)
{'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
df_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 label object dtype: object
Teraz, gdy zbiór danych jest gotowy, możesz zbudować różne zestawy danych pokazane w poniższych przykładach Scikit Learn. Dane są tutaj transformowane poza potokiem, aby uniknąć błędów w LIME: zbiór treningowy przekazywany do LimeTabularExplainer musi być tablicą NumPy bez ciągów znaków, a powyższa metoda już taką wygenerowała.
from sklearn.model_selection import train_test_split X_train_lime, X_test_lime, y_train_lime, y_test_lime = train_test_split(df_lime[features], df_lime.label, test_size = 0.2, random_state=0) X_train_lime.head(5)
Można utworzyć potok z optymalnymi parametrami znalezionymi przez XGBoost.
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(max_depth = 3,
gamma = 0.5,
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1))
model_xgb.fit(X_train_lime, y_train_lime)
/Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py:351: FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values. If you want the future behavior and silence this warning, you can specify "categories='auto'."In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly. warnings.warn(msg, FutureWarning)
Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,... reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None, silent=True, subsample=1))])
Pojawia się ostrzeżenie. Wyjaśnia ono, że nie trzeba tworzyć kodera etykiet przed uruchomieniem potoku. Jeśli nie używasz LIME, metoda z pierwszej części tego samouczka „Uczenie maszynowe ze Scikit-learn” będzie odpowiednia. W przeciwnym razie zachowaj to podejście: najpierw utwórz zakodowany zbiór danych, a następnie zastosuj koder one-hot w potoku.
print("best logistic regression from grid search: %f" % model_xgb.score(X_test_lime, y_test_lime))
best logistic regression from grid search: 0.873157
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
Zanim uruchomisz LIME, utwórz tablicę NumPy zawierającą cechy błędnie sklasyfikowanych wierszy. Możesz później użyć tej listy, aby dowiedzieć się, co wprowadziło klasyfikator w błąd.
temp = pd.concat([X_test_lime, y_test_lime], axis= 1) temp['predicted'] = model_xgb.predict(X_test_lime) temp['wrong']= temp['label'] != temp['predicted'] temp = temp.query('wrong==True').drop('wrong', axis=1) temp= temp.sort_values(by=['label']) temp.shape
(826, 16)
Następnie tworzysz funkcję lambda, która pobiera prognozę z modelu dla nowych danych. Będzie Ci ona wkrótce potrzebna.
predict_fn = lambda x: model_xgb.predict_proba(x).astype(float)
X_test_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 dtype: object
predict_fn(X_test_lime)
array([[7.96461046e-01, 2.03538969e-01],
[9.51730132e-01, 4.82698716e-02],
[7.93448269e-01, 2.06551731e-01],
...,
[9.90314305e-01, 9.68566816e-03],
[6.45816326e-04, 9.99354184e-01],
[9.71042812e-01, 2.89571714e-02]])
Konwertujesz ramkę danych pandas na tablicę NumPy.
X_train_lime = X_train_lime.values X_test_lime = X_test_lime.values X_test_lime
array([[4.00000e+01, 5.00000e+00, 1.93524e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.70000e+01, 4.00000e+00, 2.16481e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.50000e+01, 4.00000e+00, 2.56263e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
...,
[2.80000e+01, 6.00000e+00, 2.11032e+05, ..., 0.00000e+00,
4.00000e+01, 2.50000e+01],
[4.40000e+01, 4.00000e+00, 1.67005e+05, ..., 0.00000e+00,
6.00000e+01, 3.80000e+01],
[5.30000e+01, 4.00000e+00, 2.57940e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01]])
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
print(features,
class_names,
categorical_features,
categorical_names)
['age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] ['<=50K' '>50K'] [1, 3, 5, 6, 7, 8, 9, 13] {'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private', 'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'], dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th', 'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad', 'Masters', 'Preschool', 'Prof-school', 'Some-college'], dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse', 'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'], dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair', 'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners', 'Machine-op-inspct', 'Other-service', 'Priv-house-serv', 'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support', 'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child', 'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other', 'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba', 'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England', 'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras', 'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica', 'Japan', 'Laos', 'Mexico', 'Nicaragua', 'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland', 'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan', 'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam', 'Yugoslavia'], dtype=object)}
import lime import lime.lime_tabular ### Train should be label encoded not one hot encoded explainer = lime.lime_tabular.LimeTabularExplainer(X_train_lime , feature_names = features, class_names=class_names, categorical_features=categorical_features, categorical_names=categorical_names, kernel_width=3)
Teraz wybierz losowo jedno gospodarstwo domowe ze zbioru testowego i zobacz prognozę oraz to, w jaki sposób komputer do niej doszedł.
import numpy as np np.random.seed(1) i = 100 print(y_test_lime.iloc[i]) >50K
X_test_lime[i]
array([4.20000e+01, 4.00000e+00, 1.76286e+05, 7.00000e+00, 1.20000e+01,
2.00000e+00, 4.00000e+00, 0.00000e+00, 4.00000e+00, 1.00000e+00,
0.00000e+00, 0.00000e+00, 4.00000e+01, 3.80000e+01])
Możesz użyć funkcji explainer z funkcją explain_instance, aby zbadać uzasadnienie modelu. Poniżej znajduje się wykres, który generuje.
exp = explainer.explain_instance(X_test_lime[i], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

Klasyfikator prawidłowo przewidział dochód tego gospodarstwa domowego: rzeczywiście przekracza on 50 tys.
Przede wszystkim należy zauważyć, że klasyfikator nie jest zbyt pewny siebie. Przewiduje dochód powyżej 50 tys. z prawdopodobieństwem 64%, a to 64% zależy od zysków kapitałowych i stanu cywilnego. Kolor niebieski negatywnie wpływa na klasę dodatnią, a linia pomarańczowa – na dodatnią.
Klasyfikator jest niepewny, ponieważ zysk kapitałowy tego gospodarstwa domowego wynosi zero, podczas gdy zysk kapitałowy jest zazwyczaj dobrym prognostykiem zamożności. Gospodarstwo domowe pracuje również mniej niż 40 godzin tygodniowo. Wiek, zawód i płeć mają pozytywny wpływ.
Gdyby stan cywilny był wolny, klasyfikator przewidziałby dochód poniżej 50 tys. (0.64 – 0.18 = 0.46).
Teraz spróbuj innego gospodarstwa domowego, które zostało błędnie sklasyfikowane. Tabela objaśniająca kod znajduje się poniżej.
temp.head(3) temp.iloc[1,:-2]
age 58 workclass 4 fnlwgt 68624 education 11 education_num 9 marital 2 occupation 4 relationship 0 race 4 sex 1 capital_gain 0 capital_loss 0 hours_week 45 native_country 38 Name: 20931, dtype: object
i = 1 print('This observation is', temp.iloc[i,-2:])
This observation is label <=50K
predicted >50K
Name: 20931, dtype: object
exp = explainer.explain_instance(temp.iloc[1,:-2], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

Klasyfikator przewidział dochód poniżej 50 tys., co jest błędne. To gospodarstwo domowe jest nietypowe: nie odnotowało ani zysku, ani straty kapitałowej, osoba jest rozwiedziona, ma około 60 lat i jest wykształcona, czyli education_num > 12. Zgodnie z ogólnym schematem, klasyfikator umieścił gospodarstwo domowe poniżej 50 tys.
Poeksperymentuj z LIME sam, a zauważysz mnóstwo oczywistych błędów ze strony klasyfikatora. Repozytorium GitHub autora biblioteki zawiera dodatkową dokumentację dotyczącą klasyfikacji obrazów i tekstu.
Odwołanie do poleceń Scikit-learn
Poniżej znajduje się lista przydatnych poleceń, które mają zastosowanie w pakiecie scikit-learn w wersji 0.20 i nowszych.
| Zadanie | Funkcja lub klasa |
|---|---|
| Utwórz zbiór danych szkoleniowych/testowych | Train_test_split |
| Zbuduj rurociąg | |
| Wybierz kolumny i zastosuj transformację | utwórz_transformator_kolumnowy |
| Rodzaj transformacji | |
| Ujednolicić | Skaler standardowy |
| Skalowanie min-max | MinMax Skaler |
| Normalizować | Normalizer |
| Przypisz brakujące wartości | ProstyImputer |
| Konwertuj kategoryczne | JedenHotEncoder |
| Dopasuj i przekształć dane | dopasowanie_transformacji |
| Zrób rurociąg | make_pipeline |
| Model podstawowy | |
| Regresja logistyczna | Regresja logistyczna |
| XGBoost | Klasyfikator XGB |
| Sieć neuronowa | Klasyfikator MLP |
| Wyszukiwanie w siatce | GridSearchCV |
| Wyszukiwanie losowe | Wyszukiwanie losoweCV |