Samouczek Kerasa
⚡ Inteligentne podsumowanie
W samouczku Keras przedstawiono interfejs API sieci neuronowej wysokiego poziomu działający na bazie TensorFlow. LessW przewodniku omówiono, czym jest Keras, architekturę, modele, warstwy, instalację, szkolenie, ocenę i porównanie z TensorFlow w przypadku przepływów pracy głębokiego uczenia.

Co to jest Keras?
Keras to biblioteka sieci neuronowej typu open source napisana w Python Działa w oparciu o Theano lub Tensorflow. Jest modułowy, szybki i łatwy w użyciu. Został opracowany przez François Cholleta, Google inżynier. Keras nie obsługuje obliczeń niskiego poziomu. Zamiast tego wykorzystuje do tego celu inną bibliotekę, zwaną „Backend”.
Keras to opakowanie API wysokiego poziomu dla interfejsu API niskiego poziomu, które może działać na TensorFlow, CNTK lub Theano. Keras High-Level API obsługuje sposób, w jaki tworzymy modele, definiujemy warstwy lub konfigurujemy wiele modeli wejścia-wyjścia. Na tym poziomie Keras kompiluje również nasz model z funkcjami strat i optymalizatora, a proces uczenia z funkcją dopasowania. Keras w Python nie obsługuje interfejsu API niskiego poziomu, takiego jak tworzenie wykresu obliczeniowego, tworzenie tensorów lub innych zmiennych, ponieważ jest obsługiwane przez silnik „zaplecza”.
Co to jest backend?
Backend to termin w Keras, który wykonuje wszystkie obliczenia niskiego poziomu, takie jak iloczyny tensorowe, sploty i wiele innych rzeczy za pomocą innych bibliotek, takich jak Tensorflow lub Theano. Zatem „silnik zaplecza” wykona obliczenia i rozwój modeli. Domyślnym „silnikiem backendowym” jest Tensorflow, ale możemy to zmienić w konfiguracji.
Theano, Tensorflow i zaplecze CNTK

Theano to projekt typu open source opracowany przez grupę MILA na Uniwersytecie w Montrealu w Quebecu w Kanadzie. Był to pierwszy powszechnie używany framework. To jest Python biblioteka, która pomaga w wielowymiarowych tablicach dla operacji matematycznych przy użyciu Numpy lub Scipy. Theano może używać GPU do szybszych obliczeń, może również automatycznie budować grafy symboliczne do obliczania gradientów. Na swojej stronie internetowej Theano twierdzi, że może rozpoznawać wyrażenia niestabilne numerycznie i obliczać je za pomocą bardziej stabilnych algorytmów, co jest bardzo przydatne w przypadku naszych niestabilnych wyrażeń.

Z drugiej strony, Tensorflow to wschodząca gwiazda w dziedzinie frameworków do głębokiego uczenia. Opracowany przez GoogleZespół Brain to najpopularniejsze narzędzie do głębokiego uczenia. Oferuje wiele funkcji, a naukowcy przyczyniają się do rozwoju tego frameworka do celów głębokiego uczenia.

Kolejnym silnikiem backendowym dla Keras jest The Microsoft Zestaw narzędzi poznawczych lub CNTK. Jest to platforma głębokiego uczenia się o otwartym kodzie źródłowym, która została opracowana przez Microsoft Zespół. Może działać na wielu procesorach graficznych lub na wielu maszynach w celu szkolenia modelu głębokiego uczenia się na masową skalę. W niektórych przypadkach CNTK było zgłaszane szybciej niż inne frameworki, takie jak Tensorflow lub Theano. W dalszej części tego samouczka Keras CNN porównamy backendy Theano, TensorFlow i CNTK.
Porównanie backendów
Musimy zrobić test porównawczy, aby poznać porównanie między tymi dwoma backendami. Jak widać w Punkt odniesienia dla Jeong-Yoon Lee, porównywana jest wydajność 3 różnych backendów na różnym sprzęcie. W wyniku tego Theano jest wolniejsze niż drugi backend 50 czasy wolniej, ale dokładność jest zbliżona.
Inne test porównawczy jest wykonywany przez Jasmeeta Bhatię. Poinformował, że w pewnym teście Theano jest wolniejszy niż Tensorflow. Jednak ogólna dokładność jest prawie taka sama dla każdej testowanej sieci.
Zatem pomiędzy Theano, Tensorflow i CTK jest oczywiste, że TensorFlow jest lepszy niż Theano. Dzięki TensorFlow czas obliczeń jest znacznie krótszy, a CNN jest lepszy od innych.
Następny w tym Kerasie Python tutorialu, dowiemy się czym różni się Keras od TensorFlow (Keras kontra Tensorflow).
Keras kontra Tensorflow
| Parametry | Keras | Tensorflow |
|---|---|---|
| Typ | Opakowanie API wysokiego poziomu | API niskiego poziomu |
| Złożoność | Łatwy w użyciu, jeśli Python język | Musisz poznać składnię korzystania z niektórych funkcji Tensorflow |
| Cel | Szybkie wdrożenie do tworzenia modelu ze standardowymi warstwami | Umożliwia utworzenie dowolnego wykresu obliczeniowego lub warstw modelu |
| Narzędzia | Używa innego narzędzia do debugowania API, takiego jak TFDBG | Możesz skorzystać z narzędzi do wizualizacji Tensorboard |
| Społeczność | Duże aktywne społeczności | Duże aktywne społeczności i szeroko udostępniane zasoby |
Zalety Kerasa
Szybkie wdrożenie i łatwe do zrozumienia
Keras bardzo szybko tworzy model sieci. Jeśli chcesz stworzyć prosty model sieci z kilkoma liniami, Python Keras może Ci w tym pomóc. Spójrz na przykład Kerasa poniżej:
from keras.models import Sequential from keras.layers import Dense, Activation model = Sequential() model.add(Dense(64, activation='relu', input_dim=50)) #input shape of 50 model.add(Dense(28, activation='relu')) #input shape of 50 model.add(Dense(10, activation='softmax'))
Dzięki przyjaznemu API możemy łatwo zrozumieć proces. Pisanie kodu za pomocą prostej funkcji i braku konieczności ustawiania wielu parametrów.
Duże wsparcie społeczności
Istnieje wiele społeczności AI, które używają Keras w swoim środowisku głębokiego uczenia się. Wiele z nich publikuje swoje kody i tutoriale dla ogółu społeczeństwa.
Miej wiele backendów
Możesz wybrać Tensorflow, CNTK i Theano jako swój backend w Keras. Możesz wybrać inny backend dla różnych projektów w zależności od potrzeb. Każdy backend ma swoją unikalną zaletę.
Wieloplatformowe i łatwe wdrażanie modelu
Dzięki różnym obsługiwanym urządzeniom i platformom możesz wdrożyć Keras na dowolnym urządzeniu
- iOS z CoreML
- Android z Tensorflowem Android,
- Przeglądarka internetowa z obsługą .js
- Silnik chmury
- Raspberry Pi
Obsługa wielu procesorów graficznych
Możesz trenować Keras na jednym procesorze graficznym lub używać wielu procesorów graficznych jednocześnie. Ponieważ Keras ma wbudowaną obsługę równoległości danych, dzięki czemu może przetwarzać duże ilości danych i przyspieszać czas potrzebny na ich uczenie.
Wady Kerasa
Nie można obsłużyć interfejsu API niskiego poziomu
Keras obsługuje tylko API wysokiego poziomu, które działa na platformie innej platformy lub silnika backendowego, takiego jak Tensorflow, Theano czy CNTK. Dlatego nie jest zbyt przydatny, jeśli chcesz tworzyć własne aplikacje.tracNie używaj tej warstwy do celów badawczych, ponieważ Keras ma już wstępnie skonfigurowane warstwy.
Instalacja Kerasa
W tej sekcji przyjrzymy się różnym dostępnym metodom instalacji Keras
Instalacja bezpośrednia lub środowisko wirtualne
Który jest lepszy? Zainstaluj bezpośrednio w bieżącym Pythonie lub użyj środowiska wirtualnego? Sugeruję korzystanie ze środowiska wirtualnego, jeśli masz wiele projektów. Chcesz wiedzieć dlaczego? Dzieje się tak dlatego, że różne projekty mogą używać innej wersji biblioteki keras.
Na przykład mam projekt, który wymaga Python 3.5 przy użyciu OpenCV 3.3 ze starszym backendem Keras-Theano, ale w innym projekcie muszę używać Keras z najnowszą wersją i Tensorflow jako backendem Python Wsparcie 3.6.6
Nie chcemy, aby biblioteka Keras kolidowała ze sobą, prawda? Używamy więc środowiska wirtualnego do lokalizowania projektu za pomocą określonego typu biblioteki lub możemy użyć innej platformy, takiej jak usługa w chmurze, aby wykonać za nas obliczenia, np. Amazon Serwis internetowy.
Instalowanie Keras na Amazon Usługa internetowa (AWS)
Amazon Web Service to platforma oferująca usługi i produkty Cloud Computing dla badaczy lub do innych celów. AWS wynajmuje swój sprzęt, sieć, bazę danych itp., abyśmy mogli z niego korzystać bezpośrednio z Internetu. Jedną z popularnych usług AWS do celów głębokiego uczenia się jest Amazon Usługa głębokiego uczenia się obrazu maszyny lub DL
Aby uzyskać szczegółowe instrukcje dotyczące korzystania z AWS, zobacz this Tutorial
Uwaga dotycząca AMI: Dostępne będą następujące dane AMI
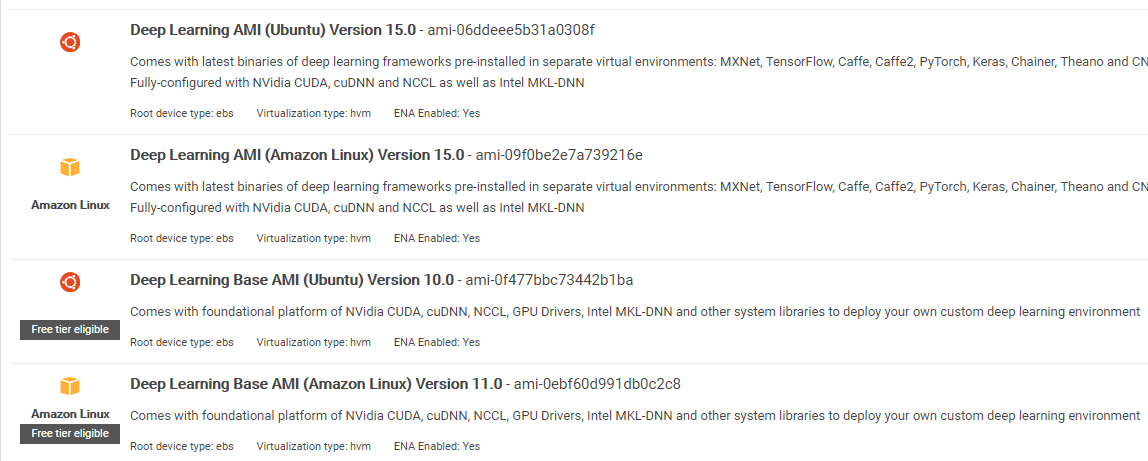
AWS Deep Learning AMI to wirtualne środowisko w usłudze AWS EC2, które pomaga badaczom i praktykom w pracy z Deep Learning. DLAMI oferuje silniki od małych procesorów po silniki z wieloma procesorami graficznymi o dużej mocy ze wstępnie skonfigurowaną CUDA, cuDNN i jest wyposażone w różnorodne platformy głębokiego uczenia się.
Jeśli chcesz z niego korzystać natychmiast, powinieneś wybrać Deep Learning AMI, ponieważ jest on wyposażony w preinstalowane popularne frameworki do głębokiego uczenia się.
Jeśli jednak chcesz wypróbować niestandardową platformę głębokiego uczenia się do celów badawczych, powinieneś zainstalować platformę Deep Learning Base AMI, ponieważ zawiera ona podstawowe biblioteki, takie jak CUDA, cuDNN, sterowniki procesorów graficznych i inne biblioteki potrzebne do działania w środowisku głębokiego uczenia się.
Jak zainstalować Keras na Amazon SageMaker
Amazon SageMaker to platforma do głębokiego uczenia się, która pomaga w szkoleniu i wdrażaniu sieci głębokiego uczenia się za pomocą najlepszego algorytmu.
Dla początkującego jest to zdecydowanie najłatwiejsza metoda korzystania z Keras. Poniżej znajduje się proces instalacji Keras na Amazon SageMaker:
Krok 1) Otwórz Amazon SageMaker
W pierwszym kroku otwórz plik Amazon Strzelec konsoli i kliknij opcję Utwórz instancję notatnika.

Krok 2) Wprowadź szczegóły
- Wpisz nazwę swojego notatnika.
- Utwórz rolę uprawnień. Spowoduje to utworzenie roli AMI Amazon Rola IAM w formacie AmazonSageMaker-Rola wykonawcza-RRRRMMDD|GGmmSS.
- Na koniec wybierz opcję Utwórz instancję notatnika. Po kilku chwilach, Amazon Sagemaker uruchamia instancję notatnika.

Note: Jeśli chcesz uzyskać dostęp do zasobów z VPC, ustaw bezpośredni dostęp do Internetu jako włączony. W przeciwnym razie ta instancja notebooka nie będzie miała dostępu do Internetu, więc nie będzie można trenować ani hostować modeli
Krok 3) Uruchom instancję
Kliknij Otwórz, aby uruchomić instancję

Krok 4) Rozpocznij kodowanie
In Jupyter, Kliknij Nowy> conda_tensorflow_p36 i jesteś gotowy do kodowania

Zainstaluj Keras w systemie Linux
Aby włączyć Keras z Tensorflow jako silnikiem zaplecza, musimy najpierw zainstalować Tensorflow. Uruchom to polecenie, aby zainstalować tensorflow z procesorem (bez procesora graficznego)
pip install --upgrade tensorflow
jeśli chcesz włączyć obsługę GPU dla tensorflow, możesz użyć tego polecenia
pip install --upgrade tensorflow-gpu

meldujmy się Python aby sprawdzić, czy nasza instalacja przebiegła pomyślnieping
user@user:~$ python Python 3.6.4 (default, Mar 20 2018, 11:10:20) [GCC 5.4.0 20160609] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import tensorflow >>>
jeśli nie pojawi się żaden komunikat o błędzie, proces instalacji przebiegł pomyślnie
Zainstaluj Kerasa
Po zainstalowaniu Tensorflow zacznijmy instalować keras. Wpisz to polecenie w terminalu
pip install keras
rozpocznie się instalacja Keras i wszystkich jego zależności. Powinieneś zobaczyć coś takiego:

Teraz mamy Keras zainstalowany w naszym systemie!
Weryfikowanie
Zanim zaczniemy korzystać z Keras'a powinniśmy sprawdzić czy nasz Keras wykorzystuje jako backend Tensorflow otwierając plik konfiguracyjny:
gedit ~/.keras/keras.json
powinieneś zobaczyć coś takiego
{
"floatx": "float32",
"epsilon": 1e-07,
"backend": "tensorflow",
"image_data_format": "channels_last"
}
jak widać, „backend” wykorzystuje tensorflow. Oznacza to, że keras używają Tensorflow jako backendu, tak jak się spodziewaliśmy
i teraz uruchom to na terminalu przez typing
user@user:~$ python3 Python 3.6.4 (default, Mar 20 2018, 11:10:20) [GCC 5.4.0 20160609] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import keras Using TensorFlow backend. >>>
Jak zainstalować Keras na Windows
Zanim zainstalujemy Tensorflow i Keras, powinniśmy zainstalować Python, pip i virtualenv. Jeśli już zainstalowałeś te biblioteki, powinieneś przejść do następnego kroku, w przeciwnym razie wykonaj to:
Zainstalować Python 3, pobierając z tego link
Zainstaluj pip, uruchamiając to
Zainstaluj virtualenv za pomocą tego polecenia
pip3 install –U pip virtualenv
Zainstalować Microsoft Wizualny C++ Aktualizacja redystrybucyjna 2015 3
- Przejdź do witryny pobierania programu Visual Studio https://www.microsoft.com/en-us/download/details.aspx?id=53587
- Wybierz Elementy redystrybucyjne i Narzędzia do tworzenia
- Pobierz i zainstaluj Microsoft Wizualny C++ Aktualizacja redystrybucyjna 2015 3
Następnie uruchom ten skrypt
pip3 install virtualenv
Skonfiguruj środowisko wirtualne
Służy do izolowania systemu roboczego od systemu głównego.
virtualenv –-system-site-packages –p python3 ./venv
Aktywuj środowisko
.\venv\Scripts\activate
Po przygotowaniu środowiska instalacja Tensorflow i Keras pozostaje taka sama jak w Linuksie. W dalszej części tego samouczka dotyczącego głębokiego uczenia się z Keras poznamy podstawy Keras dotyczące głębokiego uczenia się.
Podstawy Kerasa dotyczące głębokiego uczenia się
Główną strukturą Keras jest Model, który definiuje pełny graf sieci. Możesz dodać więcej warstw do istniejącego modelu, aby zbudować niestandardowy model potrzebny do Twojego projektu.
Oto jak utworzyć model sekwencyjny i kilka powszechnie używanych warstw w głębokim uczeniu się
1. Model sekwencyjny
from keras.models import Sequential from keras.layers import Dense, Activation,Conv2D,MaxPooling2D,Flatten,Dropout model = Sequential()
2. Warstwa konwolucyjna
To jest Keras Python przykład warstwy splotowej jako warstwy wejściowej o kształcie wejściowym 320x320x3, z 48 filtrami o rozmiarze 3x3 i wykorzystaniem ReLU jako funkcji aktywacji.
input_shape=(320,320,3) #this is the input shape of an image 320x320x3 model.add(Conv2D(48, (3, 3), activation='relu', input_shape= input_shape))
inny typ to
model.add(Conv2D(48, (3, 3), activation='relu'))
3. MaksPooling Warstwa
Aby zmniejszyć reprezentację wejściową, użyj MaxPool2d i określ rozmiar jądra
model.add(MaxPooling2D(pool_size=(2, 2)))
4. Gęsta warstwa
dodanie w pełni połączonej warstwy z samym określeniem rozmiaru wyjściowego
model.add(Dense(256, activation='relu'))
5. Warstwa porzucenia
Dodanie warstwy porzucenia z prawdopodobieństwem 50%.
model.add(Dropout(0.5))
Kompilowanie, szkolenie i ocena
Po zdefiniowaniu naszego modelu zacznijmy go trenować. Należy najpierw skompilować sieć z funkcją straty i funkcją optymalizatora. Umożliwi to sieci zmianę wag i zminimalizuje straty.
model.compile(loss='mean_squared_error', optimizer='adam')
Aby rozpocząć szkolenie, użyj funkcji fit, aby wprowadzić do modelu dane szkoleniowe i walidacyjne. Umożliwi to uczenie sieci partiami i ustawianie epok.
model.fit(X_train, X_train, batch_size=32, epochs=10, validation_data=(x_val, y_val))
Ostatnim krokiem jest ocena modelu na podstawie danych testowych.
score = model.evaluate(x_test, y_test, batch_size=32)
Spróbujmy zastosować prostą regresję liniową
import keras from keras.models import Sequential from keras.layers import Dense, Activation import numpy as np import matplotlib.pyplot as plt x = data = np.linspace(1,2,200) y = x*4 + np.random.randn(*x.shape) * 0.3 model = Sequential() model.add(Dense(1, input_dim=1, activation='linear')) model.compile(optimizer='sgd', loss='mse', metrics=['mse']) weights = model.layers[0].get_weights() w_init = weights[0][0][0] b_init = weights[1][0] print('Linear regression model is initialized with weights w: %.2f, b: %.2f' % (w_init, b_init)) model.fit(x,y, batch_size=1, epochs=30, shuffle=False) weights = model.layers[0].get_weights() w_final = weights[0][0][0] b_final = weights[1][0] print('Linear regression model is trained to have weight w: %.2f, b: %.2f' % (w_final, b_final)) predict = model.predict(data) plt.plot(data, predict, 'b', data , y, 'k.') plt.show()
Po przeszkoleniu danych dane wyjściowe powinny wyglądać następująco
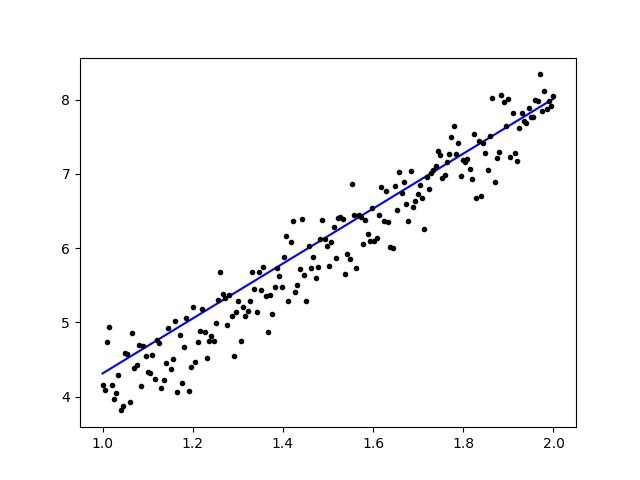
z początkową wagą
Linear regression model is initialized with weights w: 0.37, b: 0.00
i końcowa waga
Linear regression model is trained to have weight w: 3.70, b: 0.61
Dostosowywanie wstępnie wyszkolonych modeli w Keras i sposób ich używania
Dlaczego używamy modeli Fine Tune i kiedy z nich korzystamy
Dostrajanie to zadanie mające na celu ulepszenie wstępnie wytrenowanego modelu w taki sposób, aby parametry dostosowały się do nowego modelu. Gdy chcemy potrenować od podstaw na nowym modelu potrzebujemy dużej ilości danych, aby sieć mogła odnaleźć wszystkie parametry. Ale w tym przypadku użyjemy wstępnie wytrenowanego modelu, więc parametry są już wyuczone i mają wagę.
Na przykład, jeśli chcemy wytrenować własny model Kerasa, aby rozwiązać problem klasyfikacji, ale mamy tylko niewielką ilość danych, możemy to rozwiązać za pomocą Przenieś naukę + Metoda dostrajania.
Używając wstępnie wytrenowanej sieci i ciężarków, nie musimy trenować całej sieci. Musimy tylko przeszkolić ostatnią warstwę używaną do rozwiązania naszego zadania, co nazywamy metodą dostrajania.
Przygotowanie modelu sieci
Do modelu wstępnie wytrenowanego możemy załadować różne modele, które Keras ma już w swojej bibliotece takie jak:
- VGG16
- PoczątekV3
- ResNet
- Sieć komórkowa
- Przyjęcie
- IncepcjaResNetV2
Jednak w tym procesie użyjemy modelu sieci VGG16 i imageNet jako wagi modelu. Dostosujemy sieć, aby sklasyfikować 8 różnych typów klas za pomocą obrazów z Zestaw danych obrazów naturalnych Kaggle
Architektura modelu VGG16

Przesyłanie naszych danych do Bucket AWS S3
W naszym procesie szkoleniowym użyjemy naturalnych obrazów z 8 różnych klas, takich jak samoloty, samochód, kot, pies, kwiat, owoc, motocykl i osoba. Najpierw musimy przesłać nasze dane do Amazon Wiadro S3.
Amazon Wiadro S3
Krok 1) Po zalogowaniu się na konto S3 utwórzmy wiadro poprzez rejestrację Utwórz wiadro

Krok 2) Teraz wybierz nazwę segmentu i region zgodnie ze swoim kontem. Upewnij się, że nazwa zasobnika jest dostępna. Następnie kliknij Utwórz.
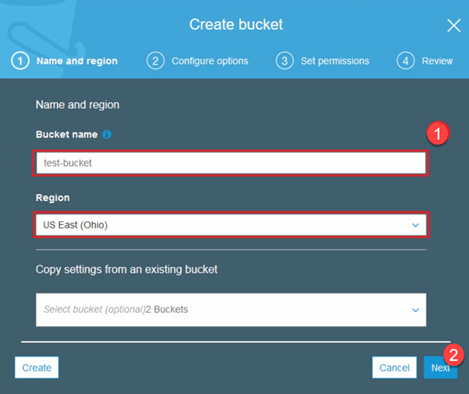
Krok 3) Jak widać, Wiadro jest gotowe do użycia. Ale jak widzisz, dostęp nie jest publiczny, dobrze jest dla ciebie, jeśli chcesz zachować go dla siebie. Możesz zmienić dostęp publiczny tego zasobnika we właściwościach zasobnika

Krok 4) Teraz możesz rozpocząć przesyłanie danych treningowych do swojego Bucketa. Tutaj prześlę plik tar.gz, który składa się ze zdjęć do celów szkoleniowych i testowych.

Krok 5) Teraz kliknij swój plik i skopiuj go Połączyć abyśmy mogli go pobrać.

Przygotowywanie danych
Musimy wygenerować nasze dane szkoleniowe przy użyciu Keras ImageDataGenerator.
Najpierw musisz pobrać za pomocą wget z linkiem do swojego pliku z S3 Bucket.
!wget https://s3.us-east-2.amazonaws.com/naturalimages02/images.tar.gz
!tar -xzf images.tar.gz
Po pobraniu danych rozpocznijmy proces szkolenia.
from keras.preprocessing.image import ImageDataGenerator import numpy as np import matplotlib.pyplot as plt train_path = 'images/train/' test_path = 'images/test/' batch_size = 16 image_size = 224 num_class = 8 train_datagen = ImageDataGenerator(validation_split=0.3, shear_range=0.2, zoom_range=0.2, horizontal_flip=True) train_generator = train_datagen.flow_from_directory( directory=train_path, target_size=(image_size,image_size), batch_size=batch_size, class_mode='categorical', color_mode='rgb', shuffle=True)
Dane obrazuGenerator utworzy dane X_training z katalogu. Podkatalog w tym katalogu będzie używany jako klasa dla każdego obiektu. Obraz zostanie załadowany w trybie kolorów RGB, z trybem klasy kategorycznej dla danych Y_training, z partią o rozmiarze 16. Na koniec przetasuj dane.
Zobaczmy nasze obrazy losowo, wykreślając je za pomocą matplotlib
x_batch, y_batch = train_generator.next() fig=plt.figure() columns = 4 rows = 4 for i in range(1, columns*rows): num = np.random.randint(batch_size) image = x_batch[num].astype(np.int) fig.add_subplot(rows, columns, i) plt.imshow(image) plt.show()

Następnie utwórzmy nasz model sieci z VGG16 z wstępnie wytrenowaną wagą imageNet. Zamrozimy te warstwy, aby nie było możliwości ich trenowania, co pomoże nam skrócić czas obliczeń.
Tworzenie naszego modelu z VGG16
import keras from keras.models import Model, load_model from keras.layers import Activation, Dropout, Flatten, Dense from keras.preprocessing.image import ImageDataGenerator from keras.applications.vgg16 import VGG16 #Load the VGG model base_model = VGG16(weights='imagenet', include_top=False, input_shape=(image_size, image_size, 3)) print(base_model.summary()) # Freeze the layers for layer in base_model.layers: layer.trainable = False # # Create the model model = keras.models.Sequential() # # Add the vgg convolutional base model model.add(base_model) # # Add new layers model.add(Flatten()) model.add(Dense(1024, activation='relu')) model.add(Dense(1024, activation='relu')) model.add(Dense(num_class, activation='softmax')) # # Show a summary of the model. Check the number of trainable parameters print(model.summary())
Jak widać poniżej, podsumowanie naszego modelu sieciowego. Na podstawie danych wejściowych z warstw VGG16 dodajemy 2 w pełni połączone warstwy, które wygenerujątract 1024 funkcje i warstwa wyjściowa, która będzie obliczać 8 klas z aktywacją softmax.
Layer (type) Output Shape Param # ================================================================= vgg16 (Model) (None, 7, 7, 512) 14714688 _________________________________________________________________ flatten_1 (Flatten) (None, 25088) 0 _________________________________________________________________ dense_1 (Dense) (None, 1024) 25691136 _________________________________________________________________ dense_2 (Dense) (None, 1024) 1049600 _________________________________________________________________ dense_3 (Dense) (None, 8) 8200 ================================================================= Total params: 41,463,624 Trainable params: 26,748,936 Non-trainable params: 14,714,688
Szkolenia
# # Compile the model from keras.optimizers import SGD model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=1e-3), metrics=['accuracy']) # # Start the training process # model.fit(x_train, y_train, validation_split=0.30, batch_size=32, epochs=50, verbose=2) # # #save the model # model.save('catdog.h5') history = model.fit_generator( train_generator, steps_per_epoch=train_generator.n/batch_size, epochs=10) model.save('fine_tune.h5') # summarize history for accuracy import matplotlib.pyplot as plt plt.plot(history.history['loss']) plt.title('loss') plt.ylabel('loss') plt.xlabel('epoch') plt.legend(['loss'], loc='upper left') plt.show()
Efekty
Epoch 1/10 432/431 [==============================] - 53s 123ms/step - loss: 0.5524 - acc: 0.9474 Epoch 2/10 432/431 [==============================] - 52s 119ms/step - loss: 0.1571 - acc: 0.9831 Epoch 3/10 432/431 [==============================] - 51s 119ms/step - loss: 0.1087 - acc: 0.9871 Epoch 4/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0624 - acc: 0.9926 Epoch 5/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0591 - acc: 0.9938 Epoch 6/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0498 - acc: 0.9936 Epoch 7/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0403 - acc: 0.9958 Epoch 8/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0248 - acc: 0.9959 Epoch 9/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0466 - acc: 0.9942 Epoch 10/10 432/431 [==============================] - 52s 120ms/step - loss: 0.0338 - acc: 0.9947

Jak widać nasze straty są znacznie zmniejszone, a dokładność wynosi prawie 100%. Aby przetestować nasz model, losowo wybraliśmy obrazy z Internetu i umieściliśmy je w folderze testowym z inną klasą do przetestowania
Testowanie naszego modelu
model = load_model('fine_tune.h5') test_datagen = ImageDataGenerator() train_generator = train_datagen.flow_from_directory( directory=train_path, target_size=(image_size,image_size), batch_size=batch_size, class_mode='categorical', color_mode='rgb', shuffle=True) test_generator = test_datagen.flow_from_directory( directory=test_path, target_size=(image_size, image_size), color_mode='rgb', shuffle=False, class_mode='categorical', batch_size=1) filenames = test_generator.filenames nb_samples = len(filenames) fig=plt.figure() columns = 4 rows = 4 for i in range(1, columns*rows -1): x_batch, y_batch = test_generator.next() name = model.predict(x_batch) name = np.argmax(name, axis=-1) true_name = y_batch true_name = np.argmax(true_name, axis=-1) label_map = (test_generator.class_indices) label_map = dict((v,k) for k,v in label_map.items()) #flip k,v predictions = [label_map[k] for k in name] true_value = [label_map[k] for k in true_name] image = x_batch[0].astype(np.int) fig.add_subplot(rows, columns, i) plt.title(str(predictions[0]) + ':' + str(true_value[0])) plt.imshow(image) plt.show()
A nasz test jest taki, jak podano poniżej! Tylko 1 obraz jest przewidywany błędnie na podstawie testu 14 obrazów!

Sieć neuronowa rozpoznawania twarzy z Keras
Dlaczego potrzebujemy uznania
Potrzebujemy rozpoznawania, aby ułatwić nam rozpoznanie lub identyfikację twarzy osoby, rodzaju obiektów, szacowanego wieku osoby na podstawie jej twarzy, a nawet poznanie wyrazu twarzy tej osoby.

Być może zdajesz sobie sprawę, że za każdym razem, gdy próbujesz oznaczyć twarz znajomego na zdjęciu, funkcja Facebooka zrobiła to za Ciebie, czyli oznacza twarz znajomego bez konieczności wcześniejszego zaznaczania jej. Jest to funkcja rozpoznawania twarzy stosowana przez Facebooka, aby ułatwić nam oznaczanie znajomych.
Jak to działa? Za każdym razem, gdy zaznaczymy twarz naszego znajomego, AI Facebooka będzie się tego uczyć i będzie próbowała to przewidzieć, aż uzyska odpowiedni wynik. Tego samego systemu użyjemy do stworzenia własnego rozpoznawania twarzy. Zacznijmy tworzyć własne rozpoznawanie twarzy za pomocą głębokiego uczenia się
Model sieciowy
Będziemy używać modelu sieciowego VGG16, ale z wagą VGGFace.
Architektura modelu VGG16

Czym jest VGGFace? jest to implementacja Deep Face Recognition w Keras wprowadzona przez Parkhi, Omkar M. i in. „Deep Face Recognition”. BMVC (2015). Struktura wykorzystuje VGG16 jako architekturę sieciową.
Możesz pobrać VGGFace z GitHub
from keras.applications.vgg16 import VGG16 from keras_vggface.vggface import VGGFace face_model = VGGFace(model='vgg16', weights='vggface', input_shape=(224,224,3)) face_model.summary()
Jak widać podsumowanie sieci
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ conv1_1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ conv1_2 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ pool1 (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ conv2_1 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ conv2_2 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ pool2 (MaxPooling2D) (None, 56, 56, 128) 0 _________________________________________________________________ conv3_1 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ conv3_2 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ conv3_3 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ pool3 (MaxPooling2D) (None, 28, 28, 256) 0 _________________________________________________________________ conv4_1 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ conv4_2 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ conv4_3 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ pool4 (MaxPooling2D) (None, 14, 14, 512) 0 _________________________________________________________________ conv5_1 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ conv5_2 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ conv5_3 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ pool5 (MaxPooling2D) (None, 7, 7, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 25088) 0 _________________________________________________________________ fc6 (Dense) (None, 4096) 102764544 _________________________________________________________________ fc6/relu (Activation) (None, 4096) 0 _________________________________________________________________ fc7 (Dense) (None, 4096) 16781312 _________________________________________________________________ fc7/relu (Activation) (None, 4096) 0 _________________________________________________________________ fc8 (Dense) (None, 2622) 10742334 _________________________________________________________________ fc8/softmax (Activation) (None, 2622) 0 ================================================================= Total params: 145,002,878 Trainable params: 145,002,878 Non-trainable params: 0 _________________________________________________________________ Traceback (most recent call last):
zrobimy A Przenieś naukę + Dostosowanie, aby przyspieszyć szkolenie przy małych zestawach danych. Najpierw zamrozimy warstwy podstawowe, aby nie dało się ich trenować.
for layer in face_model.layers: layer.trainable = False
następnie dodajemy własną warstwę, aby rozpoznać nasze twarze testowe. Dodamy 2 w pełni połączone warstwy i warstwę wyjściową z 5 osobami do wykrycia.
from keras.models import Model, Sequential from keras.layers import Input, Convolution2D, ZeroPadding2D, MaxPooling2D, Flatten, Dense, Dropout, Activation person_count = 5 last_layer = face_model.get_layer('pool5').output x = Flatten(name='flatten')(last_layer) x = Dense(1024, activation='relu', name='fc6')(x) x = Dense(1024, activation='relu', name='fc7')(x) out = Dense(person_count, activation='softmax', name='fc8')(x) custom_face = Model(face_model.input, out)
Zobaczmy podsumowanie naszej sieci
Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ conv1_1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ conv1_2 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ pool1 (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ conv2_1 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ conv2_2 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ pool2 (MaxPooling2D) (None, 56, 56, 128) 0 _________________________________________________________________ conv3_1 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ conv3_2 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ conv3_3 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ pool3 (MaxPooling2D) (None, 28, 28, 256) 0 _________________________________________________________________ conv4_1 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ conv4_2 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ conv4_3 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ pool4 (MaxPooling2D) (None, 14, 14, 512) 0 _________________________________________________________________ conv5_1 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ conv5_2 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ conv5_3 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ pool5 (MaxPooling2D) (None, 7, 7, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 25088) 0 _________________________________________________________________ fc6 (Dense) (None, 1024) 25691136 _________________________________________________________________ fc7 (Dense) (None, 1024) 1049600 _________________________________________________________________ fc8 (Dense) (None, 5) 5125 ================================================================= Total params: 41,460,549 Trainable params: 26,745,861 Non-trainable params: 14,714,688
Jak widać powyżej, po warstwie Pool5 zostanie ona spłaszczona do pojedynczego wektora cech, który zostanie wykorzystany przez gęstą warstwę do ostatecznego rozpoznania.
Przygotowanie naszych twarzy
Teraz przygotujmy nasze twarze. Zrobiłem katalog składający się z 5 znanych osób
- Jack Ma
- Jason Statham
- Johnny Depp
- Robert Downey Jr.
- Rowan Atkinson
Każdy folder zawiera 10 zdjęć, przedstawiających każdy proces szkolenia i ewaluacji. To bardzo mała ilość danych, ale to jest wyzwanie, prawda?
Do przygotowania danych wykorzystamy narzędzie Keras. Ta funkcja wykona iterację w folderze zestawu danych, a następnie przygotuje go do użycia w szkoleniu.
from keras.preprocessing.image import ImageDataGenerator batch_size = 5 train_path = 'data/' eval_path = 'eval/' train_datagen = ImageDataGenerator(rescale=1./255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True) valid_datagen = ImageDataGenerator(rescale=1./255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True) train_generator = train_datagen.flow_from_directory( train_path, target_size=(image_size,image_size), batch_size=batch_size, class_mode='sparse', color_mode='rgb') valid_generator = valid_datagen.flow_from_directory( directory=eval_path, target_size=(224, 224), color_mode='rgb', batch_size=batch_size, class_mode='sparse', shuffle=True, )
Trenowanie naszego modelu
Rozpocznijmy proces uczenia od skompilowania naszej sieci z funkcją straty i optymalizatorem. Tutaj używamy sparse_categorical_crossentropy jako naszej funkcji straty, przy pomocy SGD jako naszego optymalizatora uczenia się.
from keras.optimizers import SGD custom_face.compile(loss='sparse_categorical_crossentropy', optimizer=SGD(lr=1e-4, momentum=0.9), metrics=['accuracy']) history = custom_face.fit_generator( train_generator, validation_data=valid_generator, steps_per_epoch=49/batch_size, validation_steps=valid_generator.n, epochs=50) custom_face.evaluate_generator(generator=valid_generator) custom_face.save('vgg_face.h5') Epoch 25/50 10/9 [==============================] - 60s 6s/step - loss: 1.4882 - acc: 0.8998 - val_loss: 1.5659 - val_acc: 0.5851 Epoch 26/50 10/9 [==============================] - 59s 6s/step - loss: 1.4882 - acc: 0.8998 - val_loss: 1.5638 - val_acc: 0.5809 Epoch 27/50 10/9 [==============================] - 60s 6s/step - loss: 1.4779 - acc: 0.8597 - val_loss: 1.5613 - val_acc: 0.5477 Epoch 28/50 10/9 [==============================] - 60s 6s/step - loss: 1.4755 - acc: 0.9199 - val_loss: 1.5576 - val_acc: 0.5809 Epoch 29/50 10/9 [==============================] - 60s 6s/step - loss: 1.4794 - acc: 0.9153 - val_loss: 1.5531 - val_acc: 0.5892 Epoch 30/50 10/9 [==============================] - 60s 6s/step - loss: 1.4714 - acc: 0.8953 - val_loss: 1.5510 - val_acc: 0.6017 Epoch 31/50 10/9 [==============================] - 60s 6s/step - loss: 1.4552 - acc: 0.9199 - val_loss: 1.5509 - val_acc: 0.5809 Epoch 32/50 10/9 [==============================] - 60s 6s/step - loss: 1.4504 - acc: 0.9199 - val_loss: 1.5492 - val_acc: 0.5975 Epoch 33/50 10/9 [==============================] - 60s 6s/step - loss: 1.4497 - acc: 0.8998 - val_loss: 1.5490 - val_acc: 0.5851 Epoch 34/50 10/9 [==============================] - 60s 6s/step - loss: 1.4453 - acc: 0.9399 - val_loss: 1.5529 - val_acc: 0.5643 Epoch 35/50 10/9 [==============================] - 60s 6s/step - loss: 1.4399 - acc: 0.9599 - val_loss: 1.5451 - val_acc: 0.5768 Epoch 36/50 10/9 [==============================] - 60s 6s/step - loss: 1.4373 - acc: 0.8998 - val_loss: 1.5424 - val_acc: 0.5768 Epoch 37/50 10/9 [==============================] - 60s 6s/step - loss: 1.4231 - acc: 0.9199 - val_loss: 1.5389 - val_acc: 0.6183 Epoch 38/50 10/9 [==============================] - 59s 6s/step - loss: 1.4247 - acc: 0.9199 - val_loss: 1.5372 - val_acc: 0.5934 Epoch 39/50 10/9 [==============================] - 60s 6s/step - loss: 1.4153 - acc: 0.9399 - val_loss: 1.5406 - val_acc: 0.5560 Epoch 40/50 10/9 [==============================] - 60s 6s/step - loss: 1.4074 - acc: 0.9800 - val_loss: 1.5327 - val_acc: 0.6224 Epoch 41/50 10/9 [==============================] - 60s 6s/step - loss: 1.4023 - acc: 0.9800 - val_loss: 1.5305 - val_acc: 0.6100 Epoch 42/50 10/9 [==============================] - 59s 6s/step - loss: 1.3938 - acc: 0.9800 - val_loss: 1.5269 - val_acc: 0.5975 Epoch 43/50 10/9 [==============================] - 60s 6s/step - loss: 1.3897 - acc: 0.9599 - val_loss: 1.5234 - val_acc: 0.6432 Epoch 44/50 10/9 [==============================] - 60s 6s/step - loss: 1.3828 - acc: 0.9800 - val_loss: 1.5210 - val_acc: 0.6556 Epoch 45/50 10/9 [==============================] - 59s 6s/step - loss: 1.3848 - acc: 0.9599 - val_loss: 1.5234 - val_acc: 0.5975 Epoch 46/50 10/9 [==============================] - 60s 6s/step - loss: 1.3716 - acc: 0.9800 - val_loss: 1.5216 - val_acc: 0.6432 Epoch 47/50 10/9 [==============================] - 60s 6s/step - loss: 1.3721 - acc: 0.9800 - val_loss: 1.5195 - val_acc: 0.6266 Epoch 48/50 10/9 [==============================] - 60s 6s/step - loss: 1.3622 - acc: 0.9599 - val_loss: 1.5108 - val_acc: 0.6141 Epoch 49/50 10/9 [==============================] - 60s 6s/step - loss: 1.3452 - acc: 0.9399 - val_loss: 1.5140 - val_acc: 0.6432 Epoch 50/50 10/9 [==============================] - 60s 6s/step - loss: 1.3387 - acc: 0.9599 - val_loss: 1.5100 - val_acc: 0.6266
Jak widać dokładność naszej walidacji sięga 64%, jest to dobry wynik jak na niewielką ilość danych treningowych. Możemy to poprawić, dodając więcej warstw lub dodając więcej obrazów treningowych, aby nasz model mógł dowiedzieć się więcej o twarzach i osiągnąć większą dokładność.
Przetestujmy nasz model na zdjęciu testowym

from keras.models import load_model from keras.preprocessing.image import load_img, save_img, img_to_array from keras_vggface.utils import preprocess_input test_img = image.load_img('test.jpg', target_size=(224, 224)) img_test = image.img_to_array(test_img) img_test = np.expand_dims(img_test, axis=0) img_test = utils.preprocess_input(img_test) predictions = model.predict(img_test) predicted_class=np.argmax(predictions,axis=1) labels = (train_generator.class_indices) labels = dict((v,k) for k,v in labels.items()) predictions = [labels[k] for k in predicted_class] print(predictions) ['RobertDJr']
używając zdjęcia Roberta Downeya Jr. jako naszego zdjęcia testowego, pokazuje, że przewidywana twarz jest prawdziwa!
Przewidywanie za pomocą kamery na żywo!
A może sprawdzimy nasze umiejętności wdrażania go za pomocą sygnału z kamery internetowej? Używając OpenCV z kaskadą Haar Face do znalezienia naszej twarzy i za pomocą naszego modelu sieci możemy rozpoznać osobę.
Pierwszym krokiem jest przygotowanie twarzy Ciebie i Twoich znajomych. Im więcej mamy danych, tym lepszy wynik!
Przygotuj i wytrenuj swoją sieć jak w poprzednim kroku, po zakończeniu uczenia dodaj tę linię, aby uzyskać obraz wejściowy z kamery
#Load trained model from keras.models import load_model from keras_vggface import utils import cv2 image_size = 224 device_id = 0 #camera_device id model = load_model('my faces.h5') #make labels according to your dataset folder labels = dict(fisrtname=0,secondname=1) #and so on print(labels) cascade_classifier = cv2.CascadeClassifier('haarcascade_frontalface_default.xml') camera = cv2.VideoCapture(device_id) while camera.isOpened(): ok, cam_frame = camera.read() if not ok: break gray_img=cv2.cvtColor(cam_frame, cv2.COLOR_BGR2GRAY) faces= cascade_classifier.detectMultiScale(gray_img, minNeighbors=5) for (x,y,w,h) in faces: cv2.rectangle(cam_frame,(x,y),(x+w,y+h),(255,255,0),2) roi_color = cam_frame [y:y+h, x:x+w] roi color = cv2.cvtColor(roi_color, cv2.COLOR_BGR2RGB) roi_color = cv2.resize(roi_color, (image_size, image_size)) image = roi_color.astype(np.float32, copy=False) image = np.expand_dims(image, axis=0) image = preprocess_input(image, version=1) # or version=2 preds = model.predict(image) predicted_class=np.argmax(preds,axis=1) labels = dict((v,k) for k,v in labels.items()) name = [labels[k] for k in predicted_class] cv2.putText(cam_frame,str(name), (x + 10, y + 10), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,0,255), 2) cv2.imshow('video image', cam_frame) key = cv2.waitKey(30) if key == 27: # press 'ESC' to quit break camera.release() cv2.destroyAllWindows()
Który jest lepszy? Keras lub Tensorflow
Keras oferuje prostotę podczas pisania scenariusza. Możemy zacząć pisać i rozumieć się bezpośrednio z Kerasem, ponieważ nie jest to zbyt trudne do zrozumienia. Jest bardziej przyjazny dla użytkownika i łatwy w implementacji, nie ma potrzeby wprowadzania wielu zmiennych, aby uruchomić model. Nie musimy więc rozumieć wszystkich szczegółów procesu zaplecza.
Z drugiej strony Tensorflow to operacje niskiego poziomu, które oferują elastyczność i zaawansowane operacje, jeśli chcesz utworzyć dowolny graf obliczeniowy lub model. Tensorflow może również wizualizować proces za pomocą Tensorboard oraz specjalistyczne narzędzie debugujące.
Więc jeśli chcesz zacząć pracę z głębokim uczeniem się bez zbytniej złożoności, użyj Keras. Ponieważ Keras oferuje prostotę i jest przyjazny dla użytkownika w użyciu i łatwy do wdrożenia niż Tensorflow. Ale jeśli chcesz napisać własny algorytm w projekcie lub badaniu głębokiego uczenia się, powinieneś zamiast tego użyć Tensorflow.