SAP HANA Archiテキスト:データベースの概要
⚡ スマートサマリー
SAP HANA Archiテクチュア、ランドスケープ、サイジングは、SUSE Linux 上に構築されたインメモリ データ プラットフォームの基盤を形成します。 C++この記事では、インデックスサーバー、ストレージエンジン、行ストアと列ストア、デルタマージ、およびハードウェアサイジングの方法について説明します。

何ですか SAP HANAデータベース?
SAP HANAはメインメモリ中心のデータ管理プラットフォームです。データベースはSUSE Linux Enterprise Server(SLES)上で動作し、 Red Hat Enterprise Linux (RHEL)で書かれており、 C++非常に大規模なワークロードの場合、複数のマシンにスケールアウトして対応できます。
主な利点 SAP ハナ:
- すべてのデータがメモリにロードされるため、クリティカルパスから低速なディスクI/Oが排除され、クエリパフォーマンスが非常に高速になります。
- 同一データベース上でOLAP(オンライン分析処理)とOLTP(オンライン取引処理)を混在させることで、データ環境を簡素化する。
SAP HANAデータベースは、一連のインメモリ処理エンジンで構成されています。計算エンジンが主要なエンジンであり、リレーショナルエンジン(行ストアと列ストア)、OLAPエンジン、テキストエンジン、グラフエンジンなどの他のエンジンと連携します。リレーショナルテーブルは行ストアまたは列ストアに格納され、メモリが利用可能な場合は、追加のエンジンがテキストデータとグラフデータを処理します。
SAP HANA Archi構造
カラムストア内のデータは、辞書エンコーディング、ランレングスエンコーディング、スパースエンコーディング、クラスタエンコーディング、間接エンコーディングなどの手法を用いて圧縮されます。メインメモリの上限に達すると、使用されていないデータベースオブジェクト(テーブル、ビューなど)は自動的にディスクにアンロードされ、再度要求された際に再ロードされます。
管理者は、テーブルを右クリックして、個々のテーブルを手動でロードまたはアンロードすることもできます。 SAP ハナスタジオ 選択 アンロード or 負荷.
SAP HANAサーバーは以下で構成されます。
- インデックスサーバー
- プリプロセッササーバー
- ネームサーバ
- 統計サーバー
- XSエンジン
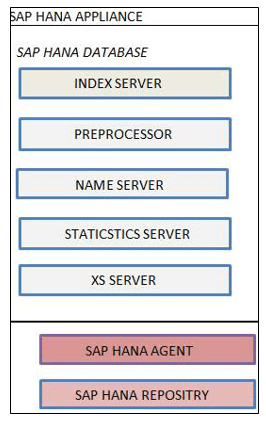
1. SAP HANA インデックス サーバー
インデックスサーバーはメインです SAP HANAデータベースコンポーネント:
- それは SAP HANAデータベースエンジン。
- そこには、実際のデータストアと、データを処理するエンジンが含まれています。
- 受信したSQL文とMDX文を実行します。
インデックスサーバーのアーキテクチャを以下に示します。

SAP HANA インデックス サーバーの概要
- セッションおよびトランザクションマネージャー: セッションコンポーネントは、データベースへの接続とセッションを管理します。トランザクションマネージャは、すべてのトランザクションを調整および制御します。
- SQL および MDX プロセッサ: SQLプロセッサは、クエリを適切なエンジン(SQL、SQLスクリプト、R、計算エンジン)に送信します。MDXプロセッサは、多次元クエリ(例えば、分析ビューに対するクエリ)を処理します。
- SQL / SQL スクリプト / R / 計算エンジン: データに対してSQL、SQLスクリプト、R、および計算モデルを実行します。
- リポジトリ: バージョン管理を維持します SAP HANAメタデータオブジェクトには、属性ビュー、分析ビュー、ストアドプロシージャなどがあります。
- 永続化レイヤー: ディスク上のデータボリュームにセーブポイントとログを書き込むことで、組み込みの災害復旧機能を提供します。
2. プリプロセッササーバー
テキスト分析ではプリプロセッササーバーが使用されます。trac検索機能が呼び出されたときに、テキストコンテンツからデータを準備します。
3. ネームサーバー
ネームサーバーはシステム全体の状況に関する情報を保持します。分散展開では、 tracksは、実行中のすべてのコンポーネントとノード全体にわたるデータの位置を把握し、クエリを適切なサーバーにルーティングできるようにします。
4. 統計サーバー
統計サーバーは、 SAP HANAシステム。注:HANA SPS 7以降では、組み込み統計サービスはスタンドアロンプロセスとしてではなく、インデックスサーバー内で実行されます。
5. XSサーバー
XSサーバーはXSエンジンをホストし、外部アプリケーションや開発者がそれを利用できるようにします。 SAP HTTP経由のHANAデータベース。XS Engine自体が軽量HTTPサーバーとして機能し、ブラウザベースのクライアントやRESTクライアントがHANAと直接通信できるようにします。
SAP HANA 風景
「HANA」は 高性能分析アプライアンス そして、ハードウェアとソフトウェアを組み合わせたプラットフォームとして提供されます。
- 最新のハードウェアは、従来のデータベースサーバーが設計時に想定していたよりもはるかに多くのCPUコア、RAM、ストレージ帯域幅を提供している。
- SAP HANAはこれを利用しますping すべての作業データをメインメモリに格納することで、従来のデータベースを制限するディスクI/Oのボトルネックを解消します。
以下の図は、 SAP HANAのハードウェアおよびソフトウェアにおける革新。

SAP HANAは2つのリレーショナルデータストアをサポートしています。 ロウストア and 列ストア.
ロウストア
行ストアは従来のデータベースのように動作します(Oracle(SQL Server)。主な違いは、すべての行がメインメモリに存在することです。 SAP HANAは、従来のデータベースが主にディスク上にデータを保存するのに対し、従来のデータベースはデータをディスク上に保存します。
列ストア
カラムストアは、データをカラム形式でメモリに保持します。カラムテーブルはここに格納され、エンジンは書き込みパフォーマンスと読み取りパフォーマンスのバランスを最適化します。下の図は、このバランスを実現する2つの構造を示しています。

メインストレージ
メインストレージにはデータの大部分が格納されます。メモリを節約し、検索を高速化するために、辞書エンコーディング、クラスタエンコーディング、スパースエンコーディング、ランレングスエンコーディングなどの圧縮手法が適用されます。
- 圧縮データをメインストレージ内で直接変更するのはコストがかかるため、書き込みはメインストレージを対象としません。
- 代わりに、すべての変更は、 Delta Storage読み取りは、メインストレージまたはデルタストレージのどちらにもアクセスできます。
データは、以下の方法で手動でロードまたはアンロードできます。 メモリにロードする and メモリからアンロード 以下に選択肢を示します。

Delta Storage
Delta ストレージは書き込み用に最適化されており、圧縮率も低くなっています。カラム テーブルへのコミットされていない変更はすべてここに保存されます。変更をメイン ストレージにマージする必要がある場合は、 Delta マージ からの操作 SAP HANAスタジオ。

- デルタマージは、デルタストレージに収集された変更をメインストレージに移動します。
- マージ後、新しいメインストレージの内容がディスクに永続化され、圧縮が再計算されます。
データがどのように移動するか Delta メインストレージへ

行編成バッファ L1-Delta はすべてのカラムテーブルの前に配置されるため、カラムテーブルは高スループットの書き込みを吸収できます。
- ユーザーはテーブルに対してUPDATEまたはINSERTを実行します。
- データはまずL1-に到着しますDelta (未確定データ)
- 一度コミットされると、データは列指向のL2-Delta バッファ。
- L2-Delta ストレージがいっぱいか、マージが実行されると、データはメインストレージに書き込まれます。
したがって、カラムストレージは、書き込み最適化(L1およびL2デルタによる)と読み出し最適化(メインストレージによる)の両方の最適化が施されています。処理後、データは永続化レイヤーによってディスクに永続化されます。
行ベースのテーブルの例:

同じ論理テーブルでも、ストアの種類によってディスクへの格納方法が異なります。行ストアでは、行は連続して書き込まれます。

カラムストアでは、同じ列の値がまとめて保存されます。

列の値はデータ型を共有し、しばしば繰り返されるため、列のレイアウトは非常に効率的に圧縮されます。これが列ストアの主なメモリ上の利点です。

SAP HANAのサイズ設定
サイジングとは、システムに必要なハードウェアリソース(RAM、ディスク、CPU)を決定するプロセスです。 SAP HANAシステムにおいて、最も重要な要素はメモリであり、次にCPU、そしてディスクは最初の2つの要素から派生する要素である。
で SAP HANAの実装において、ビジネスワークロードに適したサーバーサイズを選択することは、最も重要なタスクの1つです。従来のDBMSと比較して、HANAのサイジングは次の3つの点で異なります。
- メインメモリ: メタデータに加え、メモリに保持されるトランザクションデータと分析データの量によって駆動される。
- CPU: 予測クエリと負荷パターンに基づいて、測定値ではなく推定値として算出されます。
- ディスク: データ永続性とログ容量に合わせて設計されており、オンラインクエリデータには対応していません。
HANAはデータベース層のみを置き換えるため、アプリケーションサーバーのCPUとメモリは以前のデータベースと比べて変更されません。
SAP 正しいサイズを計算するためのいくつかの方法を提供します。
- ABAPレポートを使用したサイジング(トランザクションコード) ST03 データとレポート /SDF/HDB_SIZING).
- ABAP以外のシステム向けに、データベーススクリプトを使用してサイジングを行う。
- サイズ選びには SAP クイックサイザー 上のツール SAP サービスマーケットプレイス。
クイックサイザーツールを使用すると、要求事項は以下の形式で表示されます。
