初心者向けの DataStage チュートリアル: IBM ETLツール
⚡ スマートサマリー
DataStageから IBM InfoSphere extracDB2は、エンタープライズデータを大規模に処理、変換、ロードします。このページでは、実用的なDB2小売業の例を用いて、アーキテクチャ、コンポーネント、並列処理、SQLレプリケーションの設定、プロジェクトの作成、ジョブのコンパイル、統合テストについて説明します。

データステージとは何ですか?
DataStage ETLツールは、tracデータステージは、ソースからターゲット宛先へデータを変換、ロード、転送します。データのソースには、シーケンシャルファイル、インデックス付きファイル、リレーショナルデータベース、外部データソース、アーカイブ、エンタープライズアプリケーションなどが含まれます。DataStageは、ビジネスインテリジェンスの獲得に役立つ高品質なデータを提供することで、ビジネス分析を容易にします。
DataStage ETLツールは、大規模組織において異なるシステム間のインターフェースとして使用されます。tracソースからターゲット宛先へのデータの変換、翻訳、ロード。90年代半ばにVMarkによって初めてリリースされました。 IBM 2005 年に DataStage を買収し、名前が変更されました。 IBM WebSphere DataStage以降 IBM インフォスフィア。
これまでに市場で入手可能な Datastage のさまざまなバージョンは、Enterprise Edition (PX)、Server Edition、MVS Edition、DataStage for PeopleSoft などでした。最新版は IBM InfoSphere DataStage。
IBM 情報サーバーには以下の製品が含まれます。
- IBM InfoSphere DataStage
- IBM InfoSphere QualityStage
- IBM InfoSphere 情報サービス・ディレクター
- IBM InfoSphere 情報アナライザー
- IBM 情報サーバー高速Track
- IBM InfoSphere ビジネス用語集
定義が確定したので、次のセクションでは、製品が実際に内部で何ができるかを見ていきます。 データウェアハウジング 環境。
データステージの概要
Datastage には次の機能があります。
- 幅広いエンタープライズおよび外部データ ソースからのデータを統合できます。
- データ検証ルールを実装します
- 大量のデータの処理と変換に役立ちます
- スケーラブルな並列処理アプローチを使用します
- 複雑な変換を処理し、複数の統合プロセスを管理できます。
- エンタープライズ アプリケーションへの直接接続をソースまたはターゲットとして活用
- メタデータを分析とメンテナンスに活用する
- Operaバッチ、リアルタイム、または Web サービスとしてのテスト
このDataStageチュートリアルの次のセクションでは、以下の側面について簡単に説明します。 IBM InfoSphere DataStage:
- データ変換
- 求人
- 並列処理
InfoSphere DataStage and QualityStage は、以下のようなエンタープライズ・アプリケーションおよびデータ・ソース内のデータにアクセスできます。
- リレーショナルデータベース
- メインフレームデータベース
- ビジネスおよび分析アプリケーション
- エンタープライズリソースプランニング(ERP) または顧客関係管理 (CRM) データベース
- オンライン分析処理(OLAP) またはパフォーマンス管理データベース
処理ステージの種類
IBM infosphere ジョブは、相互にリンクされた個別のステージで構成されます。データ ソースからデータ ターゲットへのデータの流れを説明します。通常、ステージには少なくとも XNUMX つのデータ入力および/または XNUMX つのデータ出力があります。ただし、一部のステージでは複数のデータ入力を受け入れ、複数のステージに出力できます。
ジョブ設計では、次のようなさまざまなステージを使用できます。
- トランスフォームステージ
- フィルターステージ
- アグリゲーターステージ
- 重複ステージの削除
- 参加ステージ
- ルックアップステージ
- コピーステージ
- ソートステージ
- コンテナ
データ統合にDataStageを使用する理由とは?
機能一覧を知ることと、ツールがライセンス費用に見合う価値を発揮するタイミングを知ることは全く別のことです。DataStageは、データ量、ガバナンス、および多様なデータソースによって、手書きのスクリプトでは管理が困難なワークロードにおいて選ばれています。
最も明確な理由はスループットです。エンジンはデータをノード間で分割し、ステージ間で同時にレコードをストリーミングするため、ハードウェアを追加するとスループットがほぼ直線的に向上します。2ノードの開発環境で設計されたジョブは、8ノードの本番クラスタでも変更なく実行できます。
その他の理由は、技術的な問題というよりは組織的な問題である。
- 共有メタデータ: テーブル定義、接続、およびビジネス用語はリポジトリに一度保存され、すべてのジョブで再利用されるため、各開発者がソースを個別に定義する際に発生するずれが解消されます。
- 組み込みのデータ品質: QualityStageは、ETLフローと並行して調査、標準化、マッチング、およびサバイバルチェックを実行するため、データクレンジングに別の製品は必要ありません。
- 幅広い接続性: ネイティブコネクタは DB2 に到達し、 OracleTeradata、メインフレームVSAM、 SAPSalesforce、およびクラウドオブジェクトストレージをカスタムコードなしで利用できます。
- Opera国家統制: Directorは、実行履歴、行数、警告、および再開ポイントを提供し、監査人はこれらを管理されたデータパイプラインの証拠として受け入れます。
- 再利用性: 共有コンテナとパラメータセットを使用することで、テスト済みの変換処理を各ジョブにコピーするのではなく、複数のジョブで利用できるようになります。
これらの利点は、製品の組み立て方法に直接関係しており、次のセクションでそれについて説明します。
DataStage コンポーネントと Archi構造
DataStage には XNUMX つの主要コンポーネントがあります。
- 管理者: 管理タスクに使用されます。 これには、DataStage ユーザーの設定、パージ基準の設定、プロジェクトの作成と移動が含まれます。
- マネージャー: ETL DataStage のリポジトリのメイン インターフェイスです。 再利用可能なメタデータの保存と管理に使用されます。 DataStage マネージャーを通じて、リポジトリの内容を表示および編集できます。
- デザイナー: DataStage アプリケーションまたはジョブを作成するために使用されるデザイン インターフェイス。 データ ソース、必要な変換、およびデータの宛先を指定します。 ジョブはコンパイルされて、ディレクターによってスケジュールされ、サーバーによって実行される実行可能ファイルを作成します。
- 取締役: これは、DataStage サーバー ジョブと並列ジョブの検証、スケジュール、実行、監視に使用されます。

上の画像はその方法を説明しています IBM Infosphere DataStage は、Infosphere DataStage の他の要素と対話します。 IBM 情報サーバー プラットフォーム。 DataStage は XNUMX つのセクションに分かれています。 共有コンポーネントとランタイム Archi構造以下の表は、これら2つのセクションがそれぞれどのような貢献をしているかを詳しく説明しています。
|
共有 |
統一されたユーザーインターフェース |
|
|
共通サービス |
|
|
|
共通の並列処理 |
|
|
|
ランタイム Archi構造 |
労働安全衛生スクリプト |
|
DataStageにおける並列処理の仕組み
上記のアーキテクチャ表では、共通並列処理を共有サービスとして示しています。このセクションでは、そのサービスが実際にどのようにジョブを実行するのかを説明します。これは概要で説明した概念であり、ジョブの完了速度を決定するからです。
並列ジョブは2つのメカニズムを同時に使用し、どちらも手動でコーディングするのではなく、実行時に自動的に適用されます。
1. パイプラインの並列処理。 ジョブの各ステージは、前のステージの終了を待つことなく、同時に開始されます。ソースステージは行の読み込みを開始し、それらをインメモリパイプラインにプッシュします。トランスフォーマーは最初の行が到着するとすぐに開始し、その出力を2番目のパイプラインにプッシュします。ターゲットコネクタはその後すぐに書き込みを開始します。中間ランディングファイルは作成されないため、3ステージジョブでは、読み込み、変換、書き込みが順番に実行されるのではなく、オーバーラップして実行されます。
2. パーティション並列処理。 行は個別のパーティションに分割され、ステージロジックの完全なコピーが各パーティションに対してそれぞれのノードで実行されます。8つのパーティションは、8つのTransformerインスタンスが同時に実行されることを意味します。フローの最後に、パーティションはターゲット向けに単一のストリームに集約されます。
適切なパーティショニング方法を選択することは、開発者が行う主要なチューニング決定事項です。
- オート: デフォルト設定。エンジンはステージのニーズに基づいてメソッドを選択します。
- ハッシュ: 同じキー値を持つ行を同じノードに送信します。一致するキーが一致するように、Join、Aggregator、およびRemove Duplicatesを実行する前に必要です。
- ラウンドロビン: 行を1つずつ均等に処理します。キーグループが重要なフラットファイルの読み込みに最適です。ping 重要ではない。
- 全体: データセット全体をすべてのノードにコピーします。ルックアップステージの小さな参照テーブルに使用されます。
- 同じ: 既存のパーティショニングをそのまま維持することで、2つのステージ間での不要な再パーティショニングを回避します。
- 範囲とモジュラス: 均等な分布が必要な場合は、値の範囲または数値キーの余りに基づいて行を分配します。
設定ファイル(APT_CONFIG_FILE)には、存在するノードの数が格納されます。ノード数はジョブとは別に存在するため、同じコンパイル済みジョブを設計変更なしでラップトップから本番環境のグリッドまで拡張できます。
これらを試す前に、まず環境が整っていなければならない。
Datastage ツールの前提条件
DataStage の場合、次の設定が必要になります。
- 情報空間
- DataStage サーバー 9.1.2 以降
- Microsoft Visual Studio .NET 2010 エクスプレス エディション C++
- Oracle に接続する場合はクライアント (インスタント クライアントではなくフル クライアント) Oracle データベース
- DB2 クライアント (DB2 データベースに接続する場合)
この初心者向け DataStage チュートリアル シリーズでは、InfoSphere Information Server をダウンロードしてインストールする方法を学習します。
InfoSphere Information Server のダウンロードとインストール
DataStage にアクセスするには、最新バージョンの DataStage をダウンロードしてインストールします。 IBM インフォスフィアサーバー。サーバーは AIX、Linux、および Windows オペレーティング システム。要件に応じて選択できます。
InfoSphere の古いバージョンから新しいバージョンにデータを移行するには、資産交換ツールを使用します。
インストールファイル
Infosphere Datastage をインストールして構成するには、セットアップに次のファイルが必要です。
『Brooklyn Galaxy』のために、倪氏はブルックリン美術館のコレクションからXNUMX点の名品を選び、そのイメージを極めて詳細に描き込みました。これらの作品は、彼の作品とともに中国ギャラリーに展示されています。彼はXNUMX年にこの作品の制作を開始しましたが、最初の硬貨には、当館が所蔵する Windows,
- EtlDeploymentPackage-windows-oracle.pkg
- EtlDeploymentPackage-windows-db2.pkg
Linuxの場合
- EtlDeploymentPackage-linux-db2.pkg
- EtlDeploymentPackage-linux-oracle.pkg
サーバーがインストールされた状態で、このページの残りの部分にある実例で使用する変更データキャプチャ機能を利用するため、構築する前に変更データがどのように伝送されるかを確認しておくと役立ちます。
CDC トランザクション ステージ ジョブのデータ変更のプロセス フロー

上記の図 tracソースデータベースからターゲットデータベースへの単一の変更を、以下の順序で行います。
- データベースの「InfoSphere CDC」サービスは、ソース データベースからの変更を監視し、キャプチャします。
- 「InfoSphere CDC」はレプリケーション定義に従い、変更データを「InfoSphere CDC for InfoSphere DataStage」に転送します。
- 「InfoSphere CDC for InfoSphere DataStage」サーバーは、TCP/IP セッションを通じてデータを「CDC トランザクション ステージ」に送信します。 また、「InfoSphere CDC for InfoSphere DataStage」サーバーは、キャプチャされたログ内のトランザクション境界をマークするために COMMIT メッセージを (ブックマーク情報とともに) 送信します。
- 「InfoSphere CDC for InfoSphere DataStage」サーバーによって送信される COMMIT メッセージごとに、「CDC トランザクション ステージ」はウェーブ終了 (EOW) マーカーを作成します。 これらのマーカーは、すべての出力リンク上でターゲット データベース コネクタ ステージに送信されます。
- 「ターゲット データベース コネクタ ステージ」は、すべての入力リンクでウェーブ終了マーカーを受信すると、ブックマーク情報をブックマーク テーブルに書き込み、トランザクションをターゲット データベースにコミットします。
- 「InfoSphere CDC for InfoSphere DataStage」サーバーは、「ターゲット データベース」上のブックマーク テーブルにブックマーク情報を要求します。
- 「InfoSphere CDC for InfoSphere DataStage」サーバーはブックマーク情報を受信します。
この情報は次の目的で使用されます。
- レプリケーションの開始時に変更が読み取られるトランザクション ログの開始点を決定します。
- 既存のトランザクション ログをクリーンアップできるかどうかを判断するには
SQL レプリケーションのセットアップ
Datastage を始める前に、データベースをセットアップする必要があります。 2 つの DBXNUMX データベースを作成します。
- XNUMX つはレプリケーション ソースとして機能し、
- 目標としてはXNUMXつ。
また、XNUMX つのテーブル (Product と Inventory) を作成し、サンプル データを入力します。 次に、次の間の統合をテストできます。 SQL レプリケーションとデータステージ。
次に、以下を作成して SQL レプリケーションをセットアップします。 コントロールテーブル、サブスクリプションセット、登録およびサブスクリプションセットメンバーこれについては次のセクションで詳しく学びます。
ここでは、データベースとして小売販売品目の例を取り上げ、Inventory と Product という XNUMX つのテーブルを作成します。 これらのテーブルは、これらのセットを通じてソースからターゲットにデータをロードします。 (コントロールテーブル、サブスクリプションセット、登録、およびサブスクリプションセットメンバー.)
ステップ1) というソース データベースを作成します。 セール。 このデータベースの下に XNUMX つのテーブルを作成します BOX (NAIST) と 棚卸.
ステップ2) 次のコマンドを実行して SALES データベースを作成します。
db2 create database SALES
ステップ3) SALESデータベースのアーカイブログをオンにします。また、次のコマンドを使用してデータベースをバックアップします。
db2 update db cfg for SALES using LOGARCHMETH3 LOGRETAIN db2 backup db SALES
ステップ4) 同じコマンドプロンプトで、sqlrepl-datastage-tutorial ディレクトリ内の setupDB サブディレクトリに移動します。tracダウンロードした圧縮ファイルからtedを取り出してください。

ステップ5) 次のコマンドを使用して Inventory テーブルを作成し、次のコマンドを実行してテーブルにデータをインポートします。
db2 import from inventory.ixf of ixf create into inventory
ステップ6) ターゲットテーブルを作成します。 ターゲットデータベースに次の名前を付けます ステージDB。
これでデータベースのソースとターゲットの両方を作成できたので、この DataStage チュートリアルの次のステップでは、データベースをレプリケートする方法を見ていきます。
以下の情報は、 ODBCデータソースの設定 に選出しました。 IBM InfoSphere Information Serverのドキュメント。
SQL レプリケーション オブジェクトの作成
以下の図は、変更データの流れがソースデータベースからターゲットデータベースにどのように配信されるかを示しています。ソースからターゲットへのマップを作成します。ping テーブルの間で サブスクリプション セットのメンバー そしてメンバーをグループ化します 購読.

InfoSphere CDC (Change Data Capture) 内のレプリケーションの単位は、サブスクリプションと呼ばれます。
- ソースで行われた変更は「キャプチャ制御テーブル」にキャプチャされ、CD テーブルに送信されてからターゲット テーブルに送信されます。適用プログラムには、変更を行う必要がある行の詳細が含まれます。また、CD テーブルをサブスクリプション セットに結合します。
- 購読には地図が含まれていますping ソースデータストアのデータがターゲットデータストアにどのように適用されるかを指定する詳細。なお、CDCは現在、 InfoSphere データのレプリケーション.
- サブスクリプションが実行されると、InfoSphere CDC はソース データベースの変更をキャプチャします。InfoSphere CDC は変更データをターゲットに配信し、同期ポイント情報をターゲット データベースのブックマーク テーブルに格納します。
- InfoSphere CDC は、ブックマーク情報を使用して、InfoSphere DataStage ジョブの進行状況をモニターします。
- 失敗した場合は、ブックマーク情報が再開ポイントとして使用されます。この例では、ASN.IBMSNAP_FEEDETL テーブルには、DataStage 関連の同期ポイント情報が格納され、 track DataStageの進捗状況。
このセクションでは、 IBM DataStageトレーニングチュートリアルでは、次のことを行う必要があります。
- レプリケーション オプションを保存するための CAPTURE CONTROL テーブルと APPLY CONTROL テーブルを作成する
- PRODUCTテーブルとINVENTORYテーブルをレプリケーション元として登録する
- XNUMX つのメンバーを含むサブスクリプション セットを作成する
- サブスクリプション セットのメンバーとターゲット CCD テーブルを作成する
ASNCLP コマンド行プログラムを使用して SQL レプリケーションをセットアップする
ステップ1) sqlrepl-datastage-tutorial/setupSQLRep ディレクトリで crtCtlTablesCaptureServer.asnclp スクリプト ファイルを見つけます。
ステップ2) ファイル内の置換そして " ” に、SALES データベースに接続するためのユーザー ID とパスワードを入力します。
ステップ3) ディレクトリを sqlrepl-datastage-tutorial/setupSQLRep ディレクトリに変更し、スクリプトを実行します。次のコマンドを使用します。このコマンドは SALES データベースに接続し、キャプチャ制御テーブルを作成するための SQL スクリプトを生成します。
asnclp –f crtCtlTablesCaptureServer.asnclp
ステップ4) 同じディレクトリで crtCtlTablesApplyCtlServer.asnclp スクリプト ファイルを見つけます。 次に、次の 2 つのインスタンスを置き換えます。 そして " 」を、STAGEDB データベースに接続するためのユーザー ID とパスワードに置き換えます。
ステップ5) 次に、同じコマンド プロンプトで次のコマンドを使用して適用制御テーブルを作成します。
asnclp –f crtCtlTablesApplyCtlServer.asnclp
ステップ6) crtRegistration.asnclp スクリプト ファイルを見つけて、次のすべてのインスタンスを置き換えます。 SALES データベースに接続するためのユーザー ID を使用します。 また、「」を変更します”を接続パスワードに入力します。
ステップ7) ソース テーブルを登録するには、次のスクリプトを使用します。登録の作成の一環として、ASNCLP プログラムは 2 つの CD テーブル (CDPRODUCT と CDINVENTORY) を作成します。
asnclp –f crtRegistration.asnclp
CREATE REGISTRATION コマンドでは、次のオプションが使用されます。
- 差分リフレッシュ: ソース表の行が変更された場合にのみ、アプライ・プログラムにターゲット表を更新するよう求めます。
- 両方の画像: このオプションは、変更が発生する前のソース列の値を登録するために使用され、変更が発生した後の値を XNUMX つ登録します。
ステップ8) ターゲット データベース (STAGEDB) に接続するには、次の手順に従います。
- crtTableSpaceApply.bat ファイルを見つけて、テキスト エディタで開きます。
- 交換するそしてユーザーIDとパスワードを使って
- DB2 コマンド ウィンドウで crtTableSpaceApply.bat と入力し、ファイルを実行します。
- このバッチ ファイルは、ターゲット データベース (STAGEDB) に新しいテーブルスペースを作成します。
ステップ9) crtSubscriptionSetAndAddMembers.asnclp スクリプト ファイルを見つけて、次の変更を行います。
- すべてのインスタンスを置き換えますそしてSALES データベース (ソース) に接続するためのユーザー ID とパスワードを使用します。
- すべてのインスタンスを置き換えますそしてAGEDB データベース (ターゲット) に接続するためのユーザー ID を使用します。
変更後、スクリプトを実行して、ソース テーブルとターゲット テーブルをグループ化するサブスクリプション セット (ST00) を作成します。 このスクリプトは、XNUMX つのサブスクリプション セット メンバーと、変更されたデータを保存するターゲット データベース内の CCD (一貫性のある変更データ) も作成します。 このデータは Infosphere DataStage によって使用されます。
ステップ10) スクリプトを実行して、サブスクリプション セット、サブスクリプション セットのメンバー、および CCD テーブルを作成します。
asnclp –f crtSubscriptionSetAndAddMembers.asnclp
サブスクリプション セットと XNUMX つのメンバーの作成に使用されるさまざまなオプションは次のとおりです。
- 凝縮オフで完了
- 外部
- ロードタイプインポートエクスポート
- タイミング連続
ステップ11) レプリケーション管理ツールの欠陥が原因です。 TARGET_CAPTURE_SCHEMA 列を設定するには、別のバッチ ファイルを実行する必要があります。 IBMSNAP_SUBS_SET コントロール テーブルを NULL に設定します。
- updateTgtCapSchema.bat ファイルを見つけます。 テキストエディタで開きます。 交換するそしてAGEDB データベースに接続するためのユーザー ID を使用します。
- DB2 コマンド ウィンドウで、コマンド updateTgtCapSchema.bat を入力し、ファイルを実行します。
CCD テーブルを DataStage にマップするための定義ファイルの作成
次のステップでレプリケーションを行う前に、CCD テーブルを DataStage に接続する必要があります。 このセクションでは、SQL を DataStage に接続する方法を説明します。
CCDテーブルをDataStageに接続するには、DataStage定義ファイル(.dsxファイル)を作成する必要があります。.dsxファイル形式は、DataStageがジョブ定義をインポートおよびエクスポートする際に使用されます。ASNCLPスクリプトを使用して2つの.dsxファイルを作成します。例えば、ここでは2つの.dsxファイルを作成しました。
- stagedb_AQ00_SET00_sJobs.dsx: XNUMX つの並列ジョブのワークフローを指示するジョブ シーケンスを作成します。
- stagedb_AQ00_SET00_pJobs.dsx : XNUMX つの並列ジョブを作成します
ASNCLP プログラムは、CCD 列を Datastage 列形式に自動的にマップします。 ASNCLP が実行されている場合にのみサポートされます。 Windows、Linux、または Unix の手順。

Datastage ジョブは CCD テーブルから行をプルします。
- あるジョブは、DataStage が終了していた場所に同期ポイントを設定します。trac2 つのテーブルからデータを取得します。ジョブは、ST00 サブスクリプション セットの SYNCHPOINT 値を選択することによってこの情報を取得します。 IBMSNAP_SUBS_SETテーブルを作成し、それをMAX_SYNCHPOINT列に挿入します。 IBMSNAP_FEEDETL テーブル。
- 2つの仕事tracPRODUCT_CCD テーブルと INVENTORY_CCD テーブルからデータを取得します。ジョブは、どの行から開始するかを認識しています。tracMIN_SYNCHPOINT と MAX_SYNCHPOINT の値を選択することによって、 IBMサブスクリプション セットの SNAP_FEEDETL テーブル。
定義がマッピングされたので、レプリケーションを開始してCCDテーブルへのデータ入力を開始できます。
レプリケーションの開始
レプリケーションを開始するには、以下の手順を使用します。 CCD テーブルにデータが設定されている場合は、レプリケーション セットアップが検証されていることを示します。 ターゲット CCD テーブル内の複製されたデータを表示するには、DB2 コントロール センターのグラフィカル ユーザー インターフェイスを使用します。
ステップ1) DB2 が実行されていないことを確認してから、次を使用します。 db2の開始
ステップ2) 次に、オペレーティング システムのプロンプトから asncap コマンドを使用して、プログラムのキャプチャを開始します。例:
asncap capture_server=SALES
上記のコマンドは、SALES データベースをキャプチャ サーバーとして指定します。 キャプチャの実行中はコマンド ウィンドウを開いたままにしてください。
ステップ3) 次に、新しいコマンド プロンプトを開きます。 次に、 APPLY asnapply コマンドを使用してプログラムを実行します。
asnapply control_server=STAGEDB apply_qual=AQ00

- このコマンドは、AGEDB データベースをアプライ・コントロール・サーバー (アプライ・コントロール表を含むデータベース) として指定します。
- 適用修飾子としての AQ00 (このコントロール表のセットの識別子)
適用を実行した状態でコマンド ウィンドウを開いたままにします。
ステップ4) 次に、別のコマンド プロンプトを開き、db2cc コマンドを発行して DB2 コントロール センターを起動します。 デフォルトのコントロールセンターを受け入れます。
ステップ5) 左側のナビゲーション ツリーで、[すべてのデータベース] > [STAGEDB] を開き、[テーブル] をクリックします。 Double テーブル名 (Product CCD) をクリックしてテーブルを開きます。このような感じになります。

同様に、INVENTORY の CCD テーブルを開くこともできます。

レプリケーションによってCCDテーブルへのデータ供給が確立されたため、データベース側からDataStageクライアントへと注意が移ります。
Datastage ツールでプロジェクトを作成する方法
まず、DataStage でプロジェクトを作成します。 そのためには、InfoSphere DataStage 管理者である必要があります。
インストールとレプリケーションが完了したら、プロジェクトを作成する必要があります。 DataStage では、プロジェクトはデータを整理するための方法です。 これには、特定のプロジェクトでのデータ ファイル、ステージ、ビルド ジョブの定義が含まれます。
DataStage でプロジェクトを作成するには、以下の手順に従います。
ステップ 1) DataStage ソフトウェアを起動します
DataStage and QualityStage アドミニストレーターを起動します。次に、[スタート] > [すべてのプログラム] > をクリックします。 IBM 情報サーバー > IBM WebSphere DataStage および QualityStage 管理者。
ステップ 2) DataStage サーバーとクライアントを接続する
DataStage クライアントから DataStage サーバーに接続するには、ドメイン名、ユーザー ID、パスワード、サーバー情報などの詳細を入力します。
ステップ 3) 新しいプロジェクトを追加する
「WebSphere DataStage 管理」ウィンドウ内。 「プロジェクト」タブをクリックし、「追加」をクリックします。
ステップ4) プロジェクトの詳細を入力する
WebSphere DataStage管理ウィンドウで、次のような詳細を入力します。
- 名前
- ファイルの場所
- 「OK」をクリックします

各プロジェクトには以下が含まれます。
- データステージのジョブ
- 内蔵コンポーネント。 これらはジョブで使用される事前定義されたコンポーネントです。
- ユーザー定義のコンポーネント。 これらは、DataStage Manager または DataStage Designer を使用して作成されたカスタマイズされたコンポーネントです。
Datastage Infosphere にレプリケーション ジョブをインポートする方法を見ていきます。
Datastage および QualityStage Designer でレプリケーション ジョブをインポートする方法
ジョブをインポートします。 IBM InfoSphere DataStage and QualityStage Designer クライアント。そして、それらを IBM InfoSphere DataStage and QualityStage Director クライアント。
デザイナー兼クライアントは、建築プロジェクトのための白紙のキャンバスのようなものです。tracts、変換、ロード、およびデータの品質チェック。ジョブの基本的な構成要素を形成するツールを提供します。
- インターンシップ: データ ソースに接続して、ファイルの読み取りまたは書き込み、およびデータの処理を行います。
- リンク: データが流れるステージを接続します。
InfoSphere DataStage and QualityStage Designer クライアントのステージは、Designer ツール・パレットに保管されます。
InfoSphere QualityStage には次のステージが含まれています。
- 調査段階
- 標準化段階
- 一致周波数ステージ
- ワンソースマッチステージ
- XNUMXソースのマッチステージ
- サバイブステージ
- 標準化品質評価 (SQA) 段階
DataStage InfoSphere では 4 種類のジョブを作成できます。
- パラレルジョブ
- シーケンスジョブ
- メインフレーム ジョブ
- サーバージョブ
レプリケーション ジョブ ファイルをインポートする方法を段階的に見てみましょう。
ステップ1) DataStage および QualityStage デザイナーを起動します。 [スタート] > [すべてのプログラム] > をクリックします。 IBM 情報サーバー > IBM WebSphere DataStage および QualityStage デザイナー
ステップ2) 「プロジェクトに添付」ウィンドウで、次の詳細を入力します。
- ドメイン
- ユーザー名
- パスワード
- プロジェクト名
- OK

ステップ3) 次に、「ファイル」メニューから「インポート」をクリックします -> DataStage コンポーネント。
新しい DataStage リポジトリ インポート ウィンドウが開きます。
- このウィンドウで参照します STAGEDB_AQ00_ST00_sJobs.dsx 先ほど作成したファイル
- 「すべてインポート」オプションを選択します。
- 「影響分析を実行する」チェックボックスをオンにします。
- [OK] をクリックします。

ジョブがインポートされると、DataStage は STAGEDB_AQ00_ST00_sequence ジョブを作成します。
ステップ4) 同じ手順に従って、 STAGEDB_AQ00_ST00_pJobs.dsx ファイル。 このインポートにより、XNUMX つの並列ジョブが作成されます。
ステップ5) 「デザイナー リポジトリ」ペインの下 -> SQLREPフォルダーを開きます。 フォルダー内には、Sequence Job と XNUMX つの並列ジョブが表示されます。
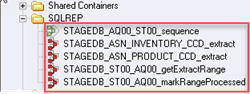
ステップ6) シーケンスジョブを表示します。 リポジトリ ツリーに移動し、STAGEDB_AQ00_ST00_sequence ジョブを右クリックして、[編集] をクリックします。 ジョブ シーケンスが制御する XNUMX つの並列ジョブのワークフローが表示されます。

それぞれのアイコンがステージになっており、
- getExtractレンジステージ: を更新します。 IBMSNAP_FEEDETL テーブル。データの開始点を設定します。tracDataStage が最後にtrac行をスキップし、終了点をサブスクリプション セットに対して処理された最後のトランザクションに設定します。
- getExtractRangeSuccessこの段階では開始点がexに渡されますtractFromINVENTORY_CCD ステージとextractFromPRODUCT_CCDステージ
- オールエックスtracts成功: この段階では、tractFromINVENTORY_CCD および extractFromPRODUCT_CCD が正常に完了しました。その後、フェッチされた最後の行の同期ポイントを setRangeProcessed ステージに渡します。
- setRange処理されたステージ:更新します IBMSNAP_FEEDETLテーブル。そのため、DataStageは次のデータ抽出ラウンドをどこから開始すればよいかを認識します。trac生産
ステップ7) 並列ジョブを表示します。 STAGEDB_ASN_INVENTORY_CCD を右クリックし、リポジトリの下の編集を選択します。 以下に示すようなウィンドウが開きます。

上の画像では、在庫 CCD テーブルからのデータと SyncFEEDETL テーブルの h ポイントの詳細が Lookup_6 ステージにレンダリングされます。
インポートされたジョブはまだ何も指していないため、次にデータ接続オブジェクトを定義する必要があります。
DataStageからSTAGEDBデータベースへのデータ接続を作成する
次のステップは、InfoSphere DataStage と SQL レプリケーションのターゲット・データベースの間にデータ接続を構築することです。 これには CCD テーブルが含まれています。
DataStage では、データ接続オブジェクトと関連するコネクタ ステージを使用して、ジョブ デザインでデータ ソースへの接続をすばやく定義します。
ステップ1) STAGEDBには、DataStageがデータの同期に使用するApplyコントロールテーブルと、tracデータが抽出されるCCDテーブルと、そのCCDテーブルtracted。以下のコマンドを使用してください。
db2 catalog tcpip node SQLREP remote ip_address server 50000 db2 catalog database STAGEDB as STAGEDB2 at node SQLREP
お願い: STAGEDBが作成されたシステムのIPアドレス
ステップ2) [ファイル] > [新規作成] > [その他] > [データ接続] をクリックします。
ステップ3) 「パラメータ」と「一般」という XNUMX つのタブのあるウィンドウが表示されます。

ステップ4) このステップでは、
- 一般に、タブでデータ接続に sqlreplConnect という名前を付けます。
- 以下に示すように、「パラメータ」タブで
- 「ステージタイプを使用して接続」フィールドの横にある参照ボタンをクリックし、
- 開いたウィンドウで、リポジトリ ツリーを [Stage Types] –> [Parallel] – > [Database] –> [DB2 Connector] に移動します。
- 開くをクリックします。

ステップ5) 接続パラメータテーブルに、次のような詳細を入力します。
- ConnectionString: ステージDB2
- : STAGEDBデータベースに接続するためのユーザーID
- パスワード : STAGEDBデータベースに接続するためのパスワード
- インスタンス: STAGEDB データベースを含む DB2 インスタンスの名前
ステップ6) 次のウィンドウでデータ接続を保存します。 「保存」ボタンをクリックします。
STAGEDB から DataStage へのテーブル定義のインポート
前のステップでは、InfoSphere DataStage と STAGEDB データベースが接続されていることを確認しました。 次に、PRODUCT_CCD テーブルと INVENTORY_CCD テーブルの列定義とその他のメタデータを Information Server リポジトリにインポートします。
デザイナー ウィンドウで、以下の手順に従います。
ステップ1) [インポート] > [テーブル定義] > [コネクタ インポート ウィザードの開始] を選択します。
ステップ2) ウィザードのコネクタ選択ページで、DB2 コネクタを選択し、「次へ」をクリックします。

ステップ3) 接続の詳細ページで「ロード」をクリックします。 これにより、ウィザードのフィールドに、前の章で作成したデータ接続からの接続情報が入力されます。

ステップ4) 同じページで「接続のテスト」をクリックします。 これにより、DataStage は STAGEDB データベースへの接続を試行するように求められます。 「接続に成功しました」というメッセージが表示されます。 「次へ」をクリックします。

ステップ5) [データ ソースの場所] ページで、[ホスト名] フィールドと [データベース名] フィールドに正しく入力されていることを確認します。 次に、「次へ」をクリックします。
ステップ6) スキーマページ。 アプライ・コントロール・テーブル (ASN) のスキーマを入力するか、ASN スキーマがスキーマ・フィールドに事前に入力されていることを確認します。 次に、「次へ」をクリックします。 選択ページには、ASN スキーマで定義されているテーブルのリストが表示されます。

ステップ7) メタデータをインポートする必要がある最初のテーブルは次のとおりです。 IBMSNAP_FEEDETL は、適用制御テーブルです。DataStage が同期を維持できるようにする同期ポイントの詳細が含まれています。 tracそのうちk行はCCDテーブルから取得されています。 IBMSNAP_FEEDETL を選択し、「次へ」をクリックします。
ステップ8) のインポートを完了するには、 IBMSNAP_FEEDETL テーブル定義。 「インポート」をクリックし、開いたウィンドウで「開く」をクリックします。
ステップ9) 手順 1 ~ 8 をあと XNUMX 回繰り返して、PRODUCT_CCD テーブルの定義をインポートし、次に INVENTORY_CCD テーブルの定義をインポートします。
ご注意: 在庫と製品の定義をインポートする際には、スキーマを ASN から PRODUCT_CCD および INVENTORY_CCD が作成されたスキーマに必ず変更してください。
これで、DataStage には、SQL レプリケーション ターゲット データベースに接続するために必要なすべての詳細が揃いました。
DataStage ジョブのプロパティの設定
XNUMX つの DataStage 並列ジョブのそれぞれに、STAGEDB データベースに接続する XNUMX つ以上のステージが含まれています。 ステージを変更して、接続情報を追加し、DataStage が設定するデータセット ファイルにリンクする必要があります。
ステージには、編集可能な事前定義済みのプロパティがあります。ここでは、STAGEDB_ASN_PRODUCT_CCD_ex のこれらのプロパティの一部を変更します。trac並列ジョブ。
ステップ1) Designerリポジトリツリーを参照します。SQLREPフォルダの下にあるSTAGEDB_ASN_PRODUCT_CCD_exを選択します。trac並列ジョブ。編集するには、ジョブを右クリックします。並列ジョブのデザインウィンドウがデザイナーパレットに開きます。
ステップ2) 緑色のアイコンを探してください。このアイコンは、DB2コネクタの段階を示しています。これは、tracCCDテーブルからデータを取得します。 Doubleアイコンをクリックします。ステージエディタウィンドウが開きます。


ステップ3) エディターで「ロード」をクリックしてフィールドに接続情報を入力します。 ステージエディタを閉じて変更を保存するには、「OK」をクリックします。
ステップ4) STAGEDB_ASN_PRODUCT_CCD_ex のデザインウィンドウに戻ります。tract 並列ジョブ。取得アイコンを探してください。SynchPoints DB2 コネクタ ステージ。次に、アイコンをダブルクリックします。
ステップ5) 次に、ロード ボタンをクリックして、フィールドに接続情報を入力します。
ご注意: アプライ・コントロール・サーバーとして STAGEDB 以外のデータベースを使用している場合。次に、取得用の接続情報をロードするオプションを選択します。SynchPoints ステージ。CCD テーブルではなくコントロール テーブルと対話します。
ステップ6) このステップでは、
- InfoSphere DataStage が実行されるシステム上に空のテキスト ファイルを作成します。
- このファイルに productdataset.ds という名前を付け、保存場所をメモします。
- DataStage は、CCD テーブルから変更をフェッチした後、このファイルに変更を書き込みます。
- リンクされたジョブ間でデータを移動するために使用されるデータ セットまたはファイルは、永続データ セットと呼ばれます。 これは DataSet ステージによって表されます。
ステップ7) 次に、デザイン ウィンドウでステージ エディターを開き、アイコン insert_into_a_dataset をダブルクリックします。別のウィンドウが開きます。

ステップ8) このウィンドウでは、

- プロパティタブで、 Target フォルダーが開き、File = DATASETNAME プロパティが強調表示されます。
- 右側にファイルフィールドがあります
- productdataset.ds ファイルへのフルパスを入力します
- 「OK」をクリックします。
これで、製品 CCD テーブルに必要なプロパティがすべて更新されました。 デザイン ウィンドウを閉じて、すべての変更を保存します。
ステップ9) 次に、STAGEDB_ASN_INVENTORY_CCD_ex を見つけて開きます。tracDesigner のリポジトリ ペインから並列ジョブを選択し、手順 3~8 を繰り返します。
ご注意:
- 取得するには、コントロール サーバー データベースの接続情報をステージ エディターにロードする必要があります。Synchポイントステージ。コントロールサーバーが STAGEDB ではない場合。
- STAGEDB_ST00_AQ00_getEx の場合tractRange および STAGEDB_ST00_AQ00_markRange で並列ジョブを処理し、すべての DB2 コネクタ ステージを開きます。次に、ロード機能を使用して STAGEDB データベースの接続情報を追加します。
すべてのプロパティが設定されたので、ジョブをコンパイルして実行できます。
DataStage ジョブのコンパイルと実行
DataStage ジョブのコンパイル準備が整うと、デザイナーは入力、変換、式、その他の詳細を確認してジョブの設計を検証します。
ジョブのコンパイルが正常に完了すると、実行する準備が整います。 XNUMX つのジョブすべてをコンパイルしますが、実行するのは「ジョブ シーケンス」のみです。 これは、このジョブが XNUMX つの並列ジョブすべてを制御するためです。
ステップ1) SQLREP フォルダーの下。 (Cntrl+Shift)。次に、右クリックして、「複数のジョブのコンパイル」オプションを選択します。

ステップ2) DataStage コンパイル ウィザードで XNUMX つのジョブが選択されていることがわかります。 「次へ」をクリックします。

ステップ3) コンパイルが開始され、完了すると「コンパイルが成功しました」というメッセージが表示されます。

ステップ4) 次に、DataStage および QualityStage Director を開始します。 [スタート] > [すべてのプログラム] > を選択します。 IBM 情報サーバー > IBM WebSphere DataStage および QualityStage ディレクター。
ステップ5) 左側のプロジェクト ナビゲーション ペイン内。 SQLREP フォルダーをクリックします。 これにより、XNUMX つのジョブすべてがディレクター ステータス テーブルに追加されます。
ステップ6) STAGEDB_AQ00_S00_sequence ジョブを選択します。 メニュー バーから、[ジョブ] > [今すぐ実行] をクリックします。

コンパイルが完了すると、完了ステータスが表示されます。

PRODUCT_CCD テーブルと INVENTORY_CCD テーブルに保存されている変更された行が、tracDataStageによって処理され、2つのデータセットファイルに挿入されました。
ステップ7) Designerに戻り、STAGEDB_ASN_PRODUCT_CCD_exを開きます。tractジョブ。ステージエディターを開くには Double「insert_into_a_dataset」アイコンをクリックします。次に、「データの表示」をクリックします。
ステップ8) 表示する行ウィンドウでデフォルトを受け入れます。次に、[OK] をクリックします。データ ブラウザー ウィンドウが開き、データ セット ファイルの内容が表示されます。

SQL レプリケーションと DataStage 間の統合のテスト
前のステップで、ジョブをコンパイルして実行しました。 このセクションでは、SQL レプリケーションと DataStage の統合を確認します。 そのために、ソーステーブルに変更を加え、同じ変更が DataStage に更新されるかどうかを確認します。
ステップ1) オペレーティング システムの sqlrepl-datastage-scripts フォルダーに移動します。
ステップ2) 次の手順に従って SQL レプリケーションを開始します。
- startSQLCapture.bat を実行します (Windows) ファイルを使用して、SALES データベースでキャプチャー・プログラムを開始します。
- startSQLApply.bat を実行します (Windows) ファイルを使用して、AGEDB データベースでアプライ・プログラムを開始します。
ステップ3) 次に、updateSourceTables.sql ファイルを開きます。 SALES データベースに接続するための置換そしてユーザーIDとパスワードを使用します。
ステップ4) DB2 コマンド ウィンドウを開きます。 ディレクトリを sqlrepl-datastage-tutorial\scripts に変更し、指定されたコマンドで issue を実行します。
db2 -tvf updateSourceTables.sql
SQL スクリプトは、Sales データベースの両方のテーブル (PRODUCT、INVENTORY) に対して更新、挿入、削除などのさまざまな操作を実行します。
ステップ5) DataStage が実行されているシステム上。 DataStage Director を開き、STAGEDB_AQ00_S00_sequence ジョブを実行します。 「ジョブ」>「今すぐ実行」をクリックします。

ジョブを実行すると、次のアクティビティが実行されます。
- キャプチャー・プログラムは、SALES データベース・ログ内の XNUMX 行の変更を読み取り、CD テーブルに挿入します。
- アプライ・プログラムは、SALES の CD 表から変更行をフェッチし、それらを STAGEDB の CCD 表に挿入します。
- DataStage の 2 つの例tractジョブはCCDテーブルから変更を取得し、productdataset.dsファイルとinventorydataset.dsファイルに書き込みます。
データ セットを調べることで、上記の手順が実行されたことを確認できます。
ステップ6) 以下の手順に従ってください。
- Designerを起動します。STAGEDB_ASN_PRODUCT_CCD_exを開きます。trac仕事。
- その後 Double「insert_into_a_dataset」アイコンをクリックします。ステージエディターで。 「データの表示」をクリックします。
- 表示する行ウィンドウでデフォルトを受け入れ、[OK] をクリックします。
データセットには XNUMX つの新しい行が含まれています。 変更が実装されたことを確認する最も簡単な方法は、データ ブラウザーの右端までスクロールすることです。 最後の XNUMX 行を見てください (下の画像を参照)

文字 I、U、D は、それぞれの新しい行を生成する INSERT、UPDATE、DELETE 操作を指定します。
Inventory テーブルに対しても同じチェックを行うことができます。
DataStageとその他の人気ETLツールとの比較
エンドツーエンドのワークフローが正常に動作するようになったら、次に必ず出てくる疑問は、チームが既に所有している可能性のある他のソリューションと比較して、DataStageがどのような位置づけにあるのかということです。以下の表は、購入を決定する際に最もよく用いられる基準に基づいて、DataStageを広く利用されている3つのプラットフォームと比較したものです。
| 基準 | IBM DataStage | 情報 パワーセンター | タレンド | SSIS |
|---|---|---|---|---|
| 処理モデル | パイプラインとパーティションの並列処理 | メタデータ駆動型パーティショニング | 生成された Java or Spark コード | インメモリデータフロー |
| 最適 | 非常に大規模なエンタープライズバッチおよびCDCワークロード | 複雑なレガシーアーキテクチャと厳格なガバナンス | クラウドネイティブでコスト意識の高いチーム | Microsoft SQL Server 財産 |
| ライセンシング | 商用、プレミアムティア | 商業用 | オープンソース版と商用版 | SQL Serverがバンドルされています |
| 学習曲線 | 急勾配、ETLスペシャリスト募集中 | 急な | 中程度、コーディングスキルがあると役立ちます | 穏健派 |
| データ品質 | QualityStageはスイートに含まれています | データ品質製品(別売) | Talend Data Qualityが含まれています | アドオンコンポーネント |
つまり、DataStageは、ライセンスコストよりも、生のスループット、メインフレームへの到達範囲、監査対応のデータリネージが重要な場合に選択されます。主にクラウドで作業するチーム データレイクアーキテクチャ または比較trac最初にtを注文すると、トレードオフが見つかるかもしれません ETL と ELT の比較 より関連性の高いもの、そしてより幅広い候補リストがまとめに掲載されています ETLツール (NAIST) と データ統合ツール.