データウェアハウス Archi構造、コンポーネント、図 Concepts
データウェアハウス Concepts
データ ウェアハウスの基本コンセプトは、企業の意思決定と予測のために単一バージョンの真実を容易にすることです。データ ウェアハウスは、単一または複数のソースからの履歴データと交換データを含む情報システムです。データウェアハウス Concepts 組織のレポートと分析のプロセスを簡素化します。
データウェアハウスの特徴
データウェアハウス Concepts 以下の特徴があります:
- 主題指向
- Integrated
- 時間変動
- 不揮発性
主題指向
データ ウェアハウスは、企業の進行中の業務ではなくテーマに関する情報を提供するため、主題指向です。これらの主題には、販売、マーケティング、流通などがあります。
データウェアハウスは、継続的な運用に焦点を合わせることはありません。代わりに、データのモデリングと分析に重点を置いています。 意思決定。 また、意思決定プロセスのサポートに役立たないデータを除外することで、特定の主題に関するシンプルかつ簡潔なビューを提供します。
Integrated
データ ウェアハウスでは、統合とは、異なるデータベースからのすべての類似データに対して共通の測定単位を確立することを意味します。 データは、共通かつ広く受け入れられる方法でデータウェアハウスに保存する必要もあります。
データ ウェアハウスは、メインフレーム、リレーショナル データベース、フラット ファイルなどのさまざまなソースからのデータを統合することによって開発されます。さらに、一貫した命名規則、形式、コーディングを維持する必要があります。
この統合は、データの効果的な分析に役立ちます。命名規則、属性の測定、エンコード構造などの一貫性を確保する必要があります。次の例を検討してください。
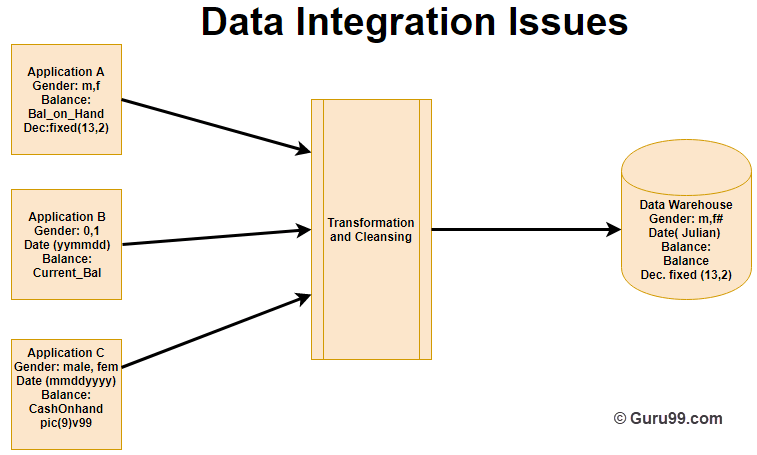
上の例では、A、B、C というラベルの付いた XNUMX つの異なるアプリケーションがあります。これらのアプリケーションに保存されている情報は、性別、日付、および残高です。 ただし、各アプリケーションのデータは異なる方法で保存されます。
- アプリケーションでは、性別フィールドに M や F などの論理値が格納されます。
- アプリケーションBの性別フィールドは数値ですが、
- アプリケーション C アプリケーションでは、性別フィールドは文字値の形式で保存されます。
- 日付と残高も同様です
ただし、変換とクリーニングのプロセスの後、このデータはすべて共通形式で データウェアハウス.
時変型
データ ウェアハウスのタイム ホライズンは、運用システムと比較してかなり広範囲です。データ ウェアハウスに収集されたデータは、特定の期間で認識され、履歴の観点から情報を提供します。明示的または暗黙的に、時間の要素が含まれます。
データウェアハウスのデータ表示時間の差異が発生する場所の XNUMX つは、レコード キーの構造です。 DW に含まれるすべての主キーには、暗黙的または明示的に時間の要素が含まれている必要があります。 日、週、月など。
時間差異のもう XNUMX つの側面は、データがウェアハウスに挿入されると、更新または変更できないことです。
不揮発性
データ ウェアハウスは不揮発性でもあり、新しいデータが入力されても以前のデータは消去されません。
データは読み取り専用で、定期的に更新されます。 これは、履歴データを分析し、いつ何が起こったのかを理解するのにも役立ちます。 トランザクション プロセス、リカバリ、同時実行制御メカニズムは必要ありません。
運用アプリケーション環境で実行される削除、更新、挿入などのアクティビティは、データウェアハウス環境では省略されます。データウェアハウスで実行されるデータ操作は、2つのタイプのみです。
- データの読み込み
- データアクセス
ここでは、アプリケーションとデータ ウェアハウスの主な違いをいくつか示します。
| Operaアプリケーション | データウェアハウス |
|---|---|
| データ アップグレード プロセスが最終製品の高い整合性を維持するようにするには、複雑なプログラムをコーディングする必要があります。 | データ更新を行わないため、このような問題は発生しません。 |
| データは正規化された形式で配置され、冗長性が最小限に抑えられます。 | データは正規化された形式で保存されません。 |
| デッドロックは非常に複雑なため、トランザクション、データ回復、ロールバック、解決の問題をサポートするためのテクノロジが必要です。 | 比較的シンプルなテクノロジーを提供します。 |
データウェアハウス Archi構造
データウェアハウス Archi構造 データ ウェアハウスは、複数のソースからの履歴データと交換可能なデータを含む情報システムであるため複雑です。データ ウェアハウス レイヤーを構築するには、単層、3 層、3 層の XNUMX つのアプローチがあります。データ ウェアハウスのこの XNUMX 層アーキテクチャは、次のように説明されます。
単層アーキテクチャ
単一レイヤーの目的は、保存されるデータの量を最小限に抑えることです。この目標は、データの冗長性を排除することです。このアーキテクチャは実際にはあまり使用されません。
2層アーキテクチャ
2 層アーキテクチャは、物理的に利用可能なソースとデータ ウェアハウスを分離するデータ ウェアハウス レイヤーの 1 つです。このアーキテクチャは拡張可能ではなく、多数のエンド ユーザーをサポートしていません。また、ネットワークの制限により接続の問題も発生します。
3層データウェアハウス Archi構造
これが最も広く使われている Archiデータウェアハウスの構造。
これは、上層、中層、下層で構成されます。
- 最下層: 最下層としてのデータウェアハウス サーバーのデータベース。 通常はリレーショナル データベース システムです。 データは、バックエンド ツールを使用してクレンジング、変換され、このレイヤーにロードされます。
- 中間層: データウェアハウスの中間層は、ROLAPまたはMOLAPモデルを使用して実装されたOLAPサーバーです。ユーザーにとって、このアプリケーション層は、tracデータベースのテッドビュー。このレイヤーは、エンドユーザーとデータベース間の仲介役も果たします。
- トップティア: 最上位層はフロントエンド クライアント層です。 最上位層は、接続してデータ ウェアハウスからデータを取得するためのツールと API です。 それは、クエリ ツール、レポート ツール、マネージド クエリ ツール、分析ツール、データ マイニング ツールなどです。
データウェアハウスのコンポーネント
データウェアハウス コンポーネントについて学び、 Archiデータ ウェアハウスの構造を以下に示す図で示します。
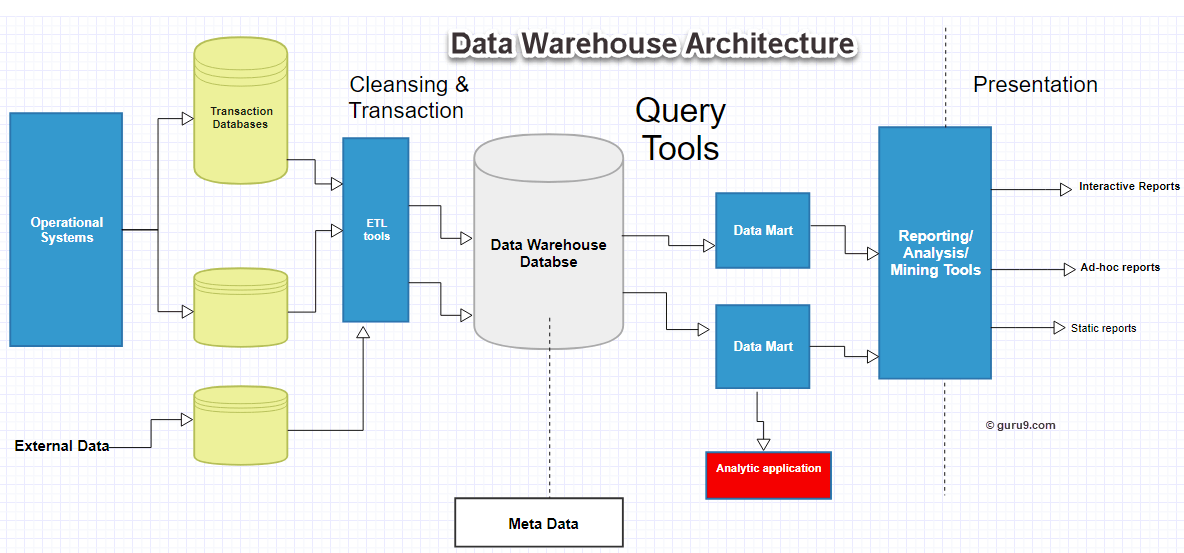
データ ウェアハウスは、環境全体が機能し、管理しやすく、アクセスしやすいようにするためのいくつかの主要なデータ ウェアハウス コンポーネントに囲まれた中央情報リポジトリである RDBMS サーバーに基づいています。
データ ウェアハウス コンポーネントは主に XNUMX つあります。
データ ウェアハウス データベース
中央データベースはデータウェアハウス環境の基盤です。このデータベースは、 RDBMS テクノロジー。 ただし、この種の実装は、従来の RDBMS システムがデータ ウェアハウジングではなくトランザクション データベース処理に最適化されているという事実によって制約を受けます。 たとえば、アドホック クエリ、複数テーブルの結合、集計はリソースを大量に消費し、パフォーマンスを低下させます。
したがって、以下にリストされているように、データベースに対する代替アプローチが使用されます。
- データウェアハウスでは、スケーラビリティを実現するためにリレーショナル データベースが並列に展開されます。並列リレーショナル データベースでは、さまざまなマルチプロセッサ構成または超並列プロセッサ上で共有メモリまたは共有なしモデルも使用できます。
- 新しいインデックス構造は、リレーショナル テーブル スキャンをバイパスし、速度を向上させるために使用されます。
- 多次元データベース (MDDB) を使用して、リレーショナル データ ウェアハウス モデルによる制限を克服します。例: Essbase から Oracle.
調達、取得、クリーンアップおよび変換ツール (ETL)
データソース、変換、移行ツールは、データウェアハウスでデータを統一フォーマットに変換するために必要なすべての変換、集計、および変更を実行するために使用されます。tract、変換およびロード(ETL)ツール。
それらの機能は次のとおりです。
- 規制規定に従ってデータを匿名化します。
- 運用データベースの不要なデータがデータ ウェアハウスに読み込まれないようにする。
- さまざまなソースから到着するデータの一般的な名前と定義を検索して置き換えます。
- 集計と派生データの計算
- データが欠落している場合は、デフォルトで入力します。
- 複数のデータ ソースから到着する重複を排除した繰り返しデータ。
これらの元tract、Transform、Load ツールは、cron ジョブ、バックグラウンド ジョブを生成する可能性があります。 COBOLプログラム、データ ウェアハウス内のデータを定期的に更新するシェル スクリプトなど。 これらのツールは、メタデータの保守にも役立ちます。
ボーマン ETLツール データベースとデータの異質性という課題に対処する必要があります。
メタデータという名前は、高度な技術的なデータ ウェアハウジングを示唆しています。 Concepts。ただし、それは非常に簡単です。メタデータは、データ ウェアハウスを定義するデータに関するデータです。データ ウェアハウスの構築、保守、管理に使用されます。
データウェアハウス内 Archiメタデータは、データ ウェアハウス データのソース、使用法、値、機能を指定するため、重要な役割を果たします。また、データを変更および処理する方法も定義します。データウェアハウスと密接に関係しています。
たとえば、販売データベースの行には次のものが含まれる場合があります。
4030 KJ732 299.90
これは、メタを調べて、それがそうであったことを知らせるまでは、意味のないデータです。
- モデル番号:4030
- 販売代理店ID:KJ732
- 総売上高 $299.90
したがって、メタデータはデータを知識に変換する上で不可欠な要素です。
メタデータは次の質問に答えるのに役立ちます
- データ ウェアハウスにはどのようなテーブル、属性、キーが含まれていますか?
- データはどこから来たのでしょうか?
- データは何回リロードされますか?
- クレンジングによってどのような変化が適用されましたか?
メタデータは次のカテゴリに分類できます。
- テクニカルメタデータ: この種類のメタデータには、データ ウェアハウスの設計者と管理者が使用するウェアハウスに関する情報が含まれています。
- ビジネスメタデータ: この種のメタデータには、データ ウェアハウスに保存されている情報をエンドユーザーが簡単に理解できるようにする詳細が含まれています。
クエリツール
データ ウェアハウジングの主な目的の XNUMX つは、企業が戦略的な意思決定を行うための情報を提供することです。 クエリ ツールを使用すると、ユーザーはデータ ウェアハウス システムと対話できるようになります。
これらのツールは、次の XNUMX つの異なるカテゴリに分類されます。
- クエリおよびレポートツール
- アプリケーション開発ツール
- データマイニングツール
- OLAPツール
1. クエリおよびレポートツール
クエリおよびレポート ツールはさらに次のように分類できます。
- 報告ツール
- マネージドクエリツール
レポートツール:
報告ツール さらに、プロダクション レポート ツールとデスクトップ レポート ライターに分けることができます。
- レポート作成者: この種のレポート ツールは、エンド ユーザーの分析用に設計されたツールです。
- 生産レポート: この種のツールを使用すると、組織は定期的な運用レポートを作成できます。また、印刷や計算などの大量のバッチジョブもサポートします。人気のあるレポートツールには、Brio、Business Objectsなどがあります。 Oracle、PowerSoft、SAS Institute。
マネージド クエリ ツール:
この種のアクセス ツールは、ユーザーとデータベースの間にメタレイヤーを挿入することで、エンド ユーザーがデータベース、SQL、データベース構造の問題を解決するのに役立ちます。
2. アプリケーション開発ツール
場合によっては、組み込みのグラフィカル ツールや分析ツールが組織の分析ニーズを満たさないことがあります。 このような場合、カスタム レポートはアプリケーション開発ツールを使用して開発されます。
3. データマイニングツール
データマイニングは、大量のデータをマイニングすることによって、意味のある新しい相関関係、パターン、傾向を発見するプロセスです。 データマイニングツール このプロセスを自動化するために使用されます。
4.OLAPツール
これらのツールは、多次元データベースの概念に基づいています。これにより、ユーザーは精巧で複雑な多次元ビューを使用してデータを分析できます。
データウェアハウス バス Archi構造
データ ウェアハウス バスは、ウェアハウス内のデータの流れを決定します。 データ ウェアハウス内のデータ フローは、インフロー、アップフロー、ダウンフロー、アウトフロー、メタ フローに分類できます。
データ バスを設計する際には、データ マート全体にわたる共有ディメンションやファクトを考慮する必要があります。
データマート
A データマート ユーザーにデータを取得するために使用されるアクセス層です。 構築にかかる時間と費用が少ないため、大規模なデータ ウェアハウスのオプションとして提示されます。 ただし、データ マートの標準的な定義はなく、人によって異なります。
簡単に言うと、データマートはデータウェアハウスの子会社です。 データ マートは、特定のユーザー グループ用に作成されたデータのパーティションに使用されます。
データ マートは、データウェアハウスと同じデータベースに作成することも、物理的に別のデータベースに作成することもできます。
データウェアハウス Archiベストプラクティスを構築する
データ ウェアハウスを設計するには Archiこの構造では、以下のベスト プラクティスに従う必要があります。
- 情報検索用に最適化されたデータ ウェアハウス モデルを使用します。これには、ディメンション モード、非正規化、またはハイブリッド アプローチを使用できます。
- データ ウェアハウスでのトップダウン アプローチとボトムアップ アプローチとして適切な設計アプローチを選択します。
- データが迅速かつ正確に処理されることを保証する必要があります。 同時に、データを単一の真実のバージョンに統合するアプローチを取る必要があります。
- データ ウェアハウスのデータ取得とクレンジングのプロセスを慎重に設計します。
- データ ウェアハウスのコンポーネント間でメタデータを共有できるメタデータ アーキテクチャを設計する
- 情報検索の必要性がデータ量の底辺に近い場合は、ODSモデルの実装を検討してください。trac機能ピラミッド、またはアクセスする必要のある複数の運用ソースがある場合。
- データ モデルが単なる統合ではなく統合されていることを確認する必要があります。 その場合は、3NF データ モデルを検討する必要があります。 ETL やデータ クレンジング ツールの取得にも最適です
製品概要
- データ ウェアハウスは、単一または複数のソースからの履歴データと交換データを含む情報システムです。 これらのソースには、従来のデータ ウェアハウス、クラウド データ ウェアハウス、または仮想データ ウェアハウスを使用できます。
- データ ウェアハウスは、組織の進行中の業務ではなく主題に関する情報を提供するため、主題指向です。
- データ ウェアハウスでは、統合とは、異なるデータベースからのすべての同様のデータに対して共通の測定単位を確立することを意味します。
- データ ウェアハウスは不揮発性でもあり、新しいデータが入力されても以前のデータは消去されません。
- DW 内のデータは保存期間が長いため、データウェアハウスは時間変化します。
- データ ウェアハウスには主に 5 つのコンポーネントがあります Archi構造: 1) データベース 2) ETL ツール 3) メタデータ 4) クエリツール 5) データマート
- これらは、クエリ ツールの 1 つの主なカテゴリです。 2. クエリとレポート、ツール 3. アプリケーション開発ツール、 4. データ マイニング ツール XNUMX. OLAP ツール
- すべての変換と要約を実行するために、データ ソーシング、変換、および移行ツールが使用されます。
- データウェアハウス内 Archiメタデータは、データ ウェアハウス データのソース、使用法、値、機能を指定するため、重要な役割を果たします。