50 questions et réponses d'entretien SQL pour 2026
Questions d'entretien SQL pour les débutants
1. Qu'est-ce qu'un SGBD ?
Un système de gestion de base de données (SGBD) est un programme qui contrôle la création, la maintenance et l'utilisation d'une base de données. Le SGBD peut être qualifié de gestionnaire de fichiers qui gère les données dans une base de données plutôt que de les enregistrer dans des systèmes de fichiers.
👉 Téléchargement PDF gratuit : Questions et réponses d'entretien SQL >>
2. Qu'est-ce que le SGBDR?
RDBMS signifie Relational Database Management System. Les SGBDR stockent les données dans la collection de tables, qui sont liées par des champs communs entre les colonnes de la table. Il fournit également des opérateurs relationnels pour manipuler les données stockées dans les tables.
Exemple : SQL Server.
3. Qu'est-ce que SQL?
SQL signifie Structured Query Language et il est utilisé pour communiquer avec la base de données. Il s'agit d'un langage standard utilisé pour effectuer des tâches telles que la récupération, la mise à jour, l'insertion et la suppression de données d'une base de données.
Standard Commandes SQL sont Sélectionner.
4. Qu'est-ce qu'une base de données ?
La base de données n'est rien d'autre qu'une forme organisée de données pour faciliter l'accès, le stockage, la récupération et la gestion des données. Ceci est également connu sous le nom de forme structurée de données accessibles de plusieurs manières.
Exemple : base de données de gestion scolaire, base de données de gestion bancaire.
5. Que sont les tables et les champs ?
Un tableau est un ensemble de données organisées dans un modèle avec des colonnes et des lignes. Les colonnes peuvent être classées comme verticales et les lignes comme horizontales. Une table a un nombre spécifié de colonnes appelées champs mais peut avoir n'importe quel nombre de lignes appelées enregistrement.
Exemple:.
Tableau : Employé.
Champ : ID d'employé, nom d'employé, date de naissance.
Données : 201456, David, 11/15/1960.
6. Qu'est-ce qu'une clé primaire?
A clé primaire est une combinaison de champs qui spécifient de manière unique une ligne. Il s’agit d’un type spécial de clé unique, et elle a une contrainte implicite NOT NULL. Cela signifie que les valeurs de clé primaire ne peuvent pas être NULL.
7. Qu'est-ce qu'une clé unique ?
Une contrainte de clé unique identifiait de manière unique chaque enregistrement de la base de données. Cela confère un caractère unique à la colonne ou à l'ensemble de colonnes.
Une contrainte de clé primaire est dotée d'une contrainte unique automatique définie. Mais pas dans le cas de Unique Key.
Il peut y avoir plusieurs contraintes uniques définies par table, mais une seule contrainte de clé primaire définie par table.
8. Qu'est-ce qu'une clé étrangère?
Une clé étrangère est une table qui peut être liée à la clé primaire d'une autre table. La relation doit être créée entre deux tables en référençant la clé étrangère avec la clé primaire d'une autre table.
9. Qu'est-ce qu'une jointure ?
Il s'agit d'un mot-clé utilisé pour interroger les données de plusieurs tables en fonction de la relation entre les champs des tables. Les clés jouent un rôle majeur lorsque les JOIN sont utilisées.
10. Quels sont les types de jointure et expliquez-les ?
Il y a différents types de jointure qui peut être utilisé pour récupérer des données et cela dépend de la relation entre les tables.
- Jointure interne.
La jointure interne renvoie des lignes lorsqu'il existe au moins une correspondance de lignes entre les tables.
- Rejoignez-vous à droite.
La jointure à droite renvoie les lignes communes entre les tables et toutes les lignes de la table de droite. Simplement, il renvoie toutes les lignes de la table de droite même s’il n’y a aucune correspondance dans la table de gauche.
- Joint gauche.
La jointure à gauche renvoie les lignes communes entre les tables et toutes les lignes de la table de gauche. Simplement, il renvoie toutes les lignes de la table de gauche même s'il n'y a aucune correspondance dans la table de droite.
- Rejoignez complètement.
La jointure complète renvoie des lignes lorsqu'il y a des lignes correspondantes dans l'une des tables. Cela signifie qu'il renvoie toutes les lignes de la table de gauche et toutes les lignes de la table de droite.
Questions d'entretien SQL pour 3 ans d'expérience
11. Qu'est-ce que la normalisation?
La normalisation est le processus consistant à minimiser la redondance et la dépendance en organisant les champs et la table d'une base de données. L'objectif principal de la normalisation est d'ajouter, supprimer ou modifier des champs pouvant être créés dans une seule table.
12. Qu'est-ce que la dénormalisation ?
La dénormalisation est une technique utilisée pour accéder aux données des formes de base de données normales supérieures à inférieures. Il s'agit également d'un processus d'introduction de redondance dans une table en incorporant les données des tables associées.
13. Quelles sont toutes les différentes normalisations ?
Normalisation de la base de données peut être facilement compris à l’aide d’une étude de cas. Les formes normales peuvent être divisées en 6 formes, et elles sont expliquées ci-dessous -.
.png)
- Première forme normale (1NF) :.
Cela devrait supprimer toutes les colonnes en double du tableau. Création de tableaux pour les données associées et identification de colonnes uniques.
- Deuxième forme normale (2NF) :.
Répondre à toutes les exigences de la première forme normale. Placer les sous-ensembles de données dans des tables séparées et Création de relations entre les tables à l'aide de clés primaires.
- Troisième forme normale (3NF) :.
Cela devrait répondre à toutes les exigences de 2NF. Suppression des colonnes qui ne dépendent pas des contraintes de clé primaire.
- Quatrième forme normale (4NF) :.
Si aucune instance de table de base de données ne contient au moins deux données indépendantes et à valeurs multiples décrivant l'entité concernée, alors elle est en 4th Forme normale.
- Cinquième forme normale (5NF) :.
Un tableau est en 5ème forme normale uniquement s'il est en 4NF et il ne peut pas être décomposé en un nombre quelconque de tableaux plus petits sans perte de données.
- Sixième Forme Normale (6NF) :.
La 6e forme normale n'est pas standardisée, mais elle est cependant discutée par les experts en bases de données depuis un certain temps. Espérons que nous aurons une définition claire et standardisée de la 6e forme normale dans un avenir proche…
14. Qu'est-ce qu'une vue ?
Une vue est une table virtuelle constituée d'un sous-ensemble de données contenues dans une table. Les vues ne sont pas virtuellement présentes et le stockage prend moins de place. La vue peut contenir des données d'une ou plusieurs tables combinées, et cela dépend de la relation.
15. Qu'est-ce qu'un indice ?
Un index est une méthode de réglage des performances permettant une récupération plus rapide des enregistrements de la table. Un index crée une entrée pour chaque valeur et il sera plus rapide de récupérer les données.
16. Quels sont les différents types d’index ?
Il existe trois types d'index -.
- Indice unique.
Cette indexation ne permet pas au champ d'avoir des valeurs en double si la colonne est indexée de manière unique. L'index unique peut être appliqué automatiquement lorsque la clé primaire est définie.
- Clustered Index.
Ce type d'index réorganise l'ordre physique de la table et de la recherche en fonction des valeurs clés. Chaque table ne peut avoir qu'un seul index clusterisé.
- NonClustered Index.
NonClusterL'index ed ne modifie pas l'ordre physique de la table et maintient l'ordre logique des données. Chaque table peut avoir 999 index non groupés.
17. Qu'est-ce qu'un curseur ?
Un curseur de base de données est un contrôle qui permet de parcourir les lignes ou les enregistrements de la table. Cela peut être considéré comme un pointeur vers une ligne dans un ensemble de lignes. Le curseur est très utile pour les déplacements tels que la récupération, l'ajout et la suppression d'enregistrements de base de données.
18. Qu'est-ce qu'une relation et que sont-elles ?
La relation avec la base de données est définie comme la connexion entre les tables d'une base de données. Il existe différentes relations entre les bases de données, et elles sont les suivantes :
- Relation individuelle.
- Relation un à plusieurs.
- Relation plusieurs à une.
- Relation d'auto-référencement.
19. Qu'est-ce qu'une requête ?
Une requête DB est un code écrit afin de récupérer les informations de la base de données. La requête peut être conçue de telle manière qu'elle corresponde à nos attentes concernant l'ensemble de résultats. Simplement, une question à la base de données.
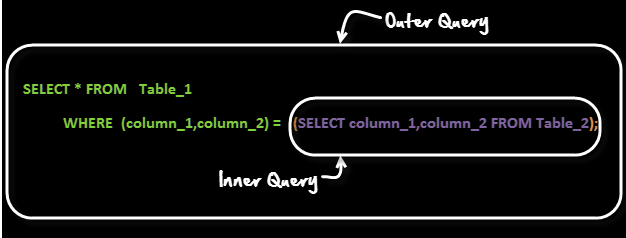
20. Qu'est-ce qu'une sous-requête ?
Une sous-requête est une requête au sein d’une autre requête. La requête externe est appelée requête principale et la requête interne est appelée sous-requête. La sous-requête est toujours exécutée en premier et le résultat de la sous-requête est transmis à la requête principale.
Examinons la syntaxe de la sous-requête :
Une plainte courante des clients de la vidéothèque MyFlix concerne le faible nombre de titres de films. La direction souhaite acheter des films dans une catégorie comportant le moins de titres.
Vous pouvez utiliser une requête comme
SELECT category_name FROM categories WHERE category_id =( SELECT MIN(category_id) from movies);
Questions d'entretien SQL pour 5 ans d'expérience
21. Quels sont les types de sous-requêtes ?
Il existe deux types de sous-requêtes : corrélées et non corrélées.
Une sous-requête corrélée ne peut pas être considérée comme une requête indépendante, mais elle peut référencer la colonne d'une table répertoriée dans la liste FROM de la requête principale.
Une sous-requête non corrélée peut être considérée comme une requête indépendante et les résultats de la sous-requête sont remplacés dans la requête principale.
22. Qu'est-ce qu'une procédure stockée?
La procédure stockée est une fonction composée de nombreuses instructions SQL pour accéder au système de base de données. Plusieurs instructions SQL sont consolidées dans une procédure stockée et les exécutent à tout moment et en tout lieu.
23. Qu'est-ce qu'un déclencheur?
Un déclencheur de base de données est un code ou des programmes qui s'exécutent automatiquement en réponse à un événement sur une table ou une vue dans une base de données. Principalement, le déclencheur aide à maintenir l’intégrité de la base de données.
Exemple : lorsqu'un nouvel étudiant est ajouté à la base de données des étudiants, de nouveaux enregistrements doivent être créés dans les tables associées telles que les tables d'examen, de score et de présence.
24. Quelle est la différence entre les commandes DELETE et TRUNCATE ?
La commande DELETE est utilisée pour supprimer des lignes de la table et la clause WHERE peut être utilisée pour un ensemble conditionnel de paramètres. La validation et la restauration peuvent être effectuées après l'instruction de suppression.
TRUNCATE supprime toutes les lignes du tableau. L’opération de troncature ne peut pas être annulée.
25. Que sont les variables locales et globales et leurs différences ?
Les variables locales sont les variables qui peuvent être utilisées ou exister à l'intérieur de la fonction. Elles ne sont pas connues des autres fonctions et ces variables ne peuvent pas être référencées ou utilisées. Des variables peuvent être créées chaque fois que cette fonction est appelée.
Les variables globales sont les variables qui peuvent être utilisées ou exister dans tout le programme. La même variable déclarée dans global ne peut pas être utilisée dans les fonctions. Les variables globales ne peuvent pas être créées chaque fois que cette fonction est appelée.
26. Qu'est-ce qu'une contrainte?
La contrainte peut être utilisée pour spécifier la limite du type de données de la table. La contrainte peut être spécifiée lors de la création ou de la modification de l'instruction table. Des exemples de contraintes sont.
- PAS NUL.
- VÉRIFIER.
- DÉFAUT.
- UNIQUE.
- CLÉ PRIMAIRE.
- CLÉ ÉTRANGÈRE.
27. Qu'est-ce que les données Integrity?
Centres de données Integrity définit l'exactitude et la cohérence des données stockées dans une base de données. Il peut également définir des contraintes d'intégrité pour appliquer des règles métier aux données lorsqu'elles sont saisies dans l'application ou la base de données.
28. Qu'est-ce que l'incrémentation automatique ?
Le mot-clé d'incrémentation automatique permet à l'utilisateur de créer un numéro unique à générer lorsqu'un nouvel enregistrement est inséré dans la table. Le mot-clé AUTO INCREMENT peut être utilisé dans Oracle et le mot-clé IDENTITY peut être utilisé dans SQL SERVER.
La plupart du temps, ce mot-clé peut être utilisé chaque fois que PRIMARY KEY est utilisé.
29. Quelle est la différence entre Cluster et non-Cluster Indice?
ClusterL'index ed est utilisé pour récupérer facilement les données de la base de données en modifiant la manière dont les enregistrements sont stockés. La base de données trie les lignes en fonction de la colonne qui doit être indexée en cluster.
Un index non clusterisé ne modifie pas la façon dont il a été stocké mais crée un objet complètement distinct dans la table. Il renvoie aux lignes du tableau d'origine après la recherche.
30. Qu'est-ce que Datawarehouse ?
Datawarehouse est un référentiel central de données provenant de plusieurs sources d'informations. Ces données sont consolidées, transformées et mises à disposition pour l'extraction et le traitement en ligne. Les données d'entrepôt comportent un sous-ensemble de données appelé Data Marts.
31. Qu'est-ce que l'auto-adhésion ?
L'auto-jointure est définie comme une requête utilisée pour se comparer à elle-même. Ceci est utilisé pour comparer les valeurs d’une colonne avec d’autres valeurs de la même colonne dans le même tableau. ALIAS ES peut être utilisé pour la même comparaison de tableaux.
32. Qu'est-ce que la jointure croisée ?
La jointure croisée est définie comme un produit cartésien où le nombre de lignes de la première table est multiplié par le nombre de lignes de la deuxième table. Si supposons que la clause WHERE soit utilisée dans une jointure croisée, la requête fonctionnera comme une INNER JOIN.
33. Que sont les fonctions définies par l'utilisateur ?
Les fonctions définies par l'utilisateur sont les fonctions écrites pour utiliser cette logique chaque fois que cela est nécessaire. Il n’est pas nécessaire d’écrire plusieurs fois la même logique. Au lieu de cela, la fonction peut être appelée ou exécutée chaque fois que nécessaire.
34. Quels sont tous les types de fonctions définies par l'utilisateur ?
Il existe trois types de fonctions définies par l'utilisateur.
- Fonctions scalaires.
- Fonctions valorisées par le tableau en ligne.
- Fonctions valorisées à plusieurs instructions.
Unité de retour scalaire, la variante définit la clause de retour. Deux autres types renvoient la table en guise de retour.
35. Qu'est-ce que le classement ?
Le classement est défini comme un ensemble de règles qui déterminent la manière dont les données de caractères peuvent être triées et comparées. Cela peut être utilisé pour comparer les caractères A et ceux d'autres langues et dépend également de la largeur des caractères.
La valeur ASCII peut être utilisée pour comparer ces données de caractères.
36. Quels sont les différents types de sensibilité de classement ?
Voici différents types de sensibilité de classement -.
- Sensibilité à la casse – A et a et B et b.
- Sensibilité aux accents.
- Sensibilité Kana – Caractères Kana japonais.
- Sensibilité à la largeur – Caractère à un octet et caractère à deux octets.
37. Avantages et inconvénients de la procédure stockée ?
La procédure stockée peut être utilisée comme programmation modulaire – cela signifie créer une fois, stocker et appeler plusieurs fois chaque fois que nécessaire. Cela permet une exécution plus rapide au lieu d'exécuter plusieurs requêtes. Cela réduit le trafic réseau et offre une meilleure sécurité des données.
L'inconvénient est qu'il ne peut être exécuté que dans la base de données et utilise plus de mémoire sur le serveur de base de données.
38. Qu'est-ce que le traitement des transactions en ligne (OLTP) ?
Le traitement des transactions en ligne (OLTP) gère les applications basées sur les transactions qui peuvent être utilisées pour la saisie, la récupération et le traitement des données. OLTP rend la gestion des données simple et efficace. Contrairement aux systèmes OLAP, l'objectif des systèmes OLTP est de servir les transactions en temps réel.
Exemple – Transactions bancaires quotidiennes.
39. Qu'est-ce que la CLAUSE ?
La clause SQL est définie pour limiter le jeu de résultats en fournissant une condition à la requête. Cela filtre généralement certaines lignes de l'ensemble des enregistrements.
Exemple – Requête avec la condition WHERE
Requête qui a la condition HAVING.
40. Qu'est-ce qu'une procédure stockée récursive ?
Une procédure stockée qui s'appelle d'elle-même jusqu'à ce qu'elle atteigne une condition aux limites. Cette fonction ou procédure récursive aide les programmeurs à utiliser le même ensemble de codes un certain nombre de fois.
Questions d'entretien SQL pour plus de 10 ans d'expérience
41. Que sont les commandes Union, moins et Interact ?
L'opérateur UNION est utilisé pour combiner les résultats de deux tables et élimine les lignes en double des tables.
L'opérateur MINUS est utilisé pour renvoyer les lignes de la première requête mais pas de la deuxième requête. Les enregistrements correspondants de la première et de la deuxième requête ainsi que les autres lignes de la première requête seront affichés sous forme d'ensemble de résultats.
L'opérateur INTERSECT est utilisé pour renvoyer les lignes renvoyées par les deux requêtes.
42. Qu'est-ce qu'une commande ALIAS?
Le nom ALIAS peut être donné à une table ou une colonne. Ce pseudonyme peut être référencé dans clause O pour identifier la table ou la colonne.
Exemple-.
Select st.StudentID, Ex.Result from student st, Exam as Ex where st.studentID = Ex. StudentID
Ici, st fait référence au nom d'alias de la table des étudiants et Ex fait référence au nom d'alias de la table d'examen.
43. Quelle est la différence entre les instructions TRUNCATE et DROP ?
TRUNCATE supprime toutes les lignes de la table et ne peut pas être annulée. La commande DROP supprime une table de la base de données et l'opération ne peut pas être annulée.
44. Que sont les fonctions globales et scalaires ?
Les fonctions d'agrégation sont utilisées pour évaluer les calculs mathématiques et renvoyer des valeurs uniques. Cela peut être calculé à partir des colonnes d’un tableau. Les fonctions scalaires renvoient une valeur unique basée sur la valeur d'entrée.
Exemple -.
Agrégat – max(), count – Calculé par rapport au numérique.
Scalaire – UCASE(), NOW() – Calculé par rapport aux chaînes.
45. Comment créer une table vide à partir d'une table existante ?
L'exemple sera -.
Select * into studentcopy from student where 1=2
Ici, nous copions la table des étudiants vers une autre table avec la même structure sans aucune ligne copiée.
46. Comment récupérer des enregistrements communs à partir de deux tables ?
L'ensemble de résultats d'enregistrements communs peut être obtenu par -.
Select studentID from student INTERSECT Select StudentID from Exam
47. Comment récupérer des enregistrements alternatifs à partir d'une table ?
Les enregistrements peuvent être récupérés pour les numéros de ligne impairs et pairs.
Pour afficher les nombres pairs-.
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=0
Pour afficher les nombres impairs-.
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=1
from (Sélectionnez rowno, studentId from student) où mod(rowno,2)=1.[/sql]
48. Comment sélectionner des enregistrements uniques dans une table ?
Sélectionnez des enregistrements uniques dans une table à l'aide du mot clé DISTINCT.
Select DISTINCT StudentID, StudentName from Student.
49. Quelle est la commande utilisée pour récupérer les 5 premiers caractères de la chaîne ?
Il existe de nombreuses façons de récupérer les 5 premiers caractères de la chaîne -.
Select SUBSTRING(StudentName,1,5) as studentname from student
Select LEFT(Studentname,5) as studentname from student
50. Quel opérateur est utilisé dans la requête pour la correspondance de modèles ?
L'opérateur LIKE est utilisé pour la correspondance de modèles et peut être utilisé comme -.
- % – Correspond à zéro ou plusieurs caractères.
- _(Souligné) – Correspondant exactement à un caractère.
Exemple -.
Select * from Student where studentname like 'a%'
Select * from Student where studentname like 'ami_'
Ces questions d'entretien vous aideront également dans votre soutenance