Trame de données R : comment créer, ajouter, sélectionner et sous-ensemble
⚡ Résumé intelligent
Un DataFrame R stocke des colonnes de types différents de même longueur, ce qui en fait la structure rectangulaire standard pour l'analyse. Les crochets permettent de sélectionner des lignes et des colonnes, le signe dollar permet de sélectionner une colonne et la fonction `subset()` permet de filtrer selon une condition.

Qu'est-ce qu'une trame de données ?
A trame de données Il s'agit d'une liste de vecteurs de même longueur. Une matrice ne contient qu'un seul type de données, tandis qu'un cadre de données accepte différents types de données (numériques, caractères, facteurs, etc.).
Cette définition place le cadre de données entre deux voisins que vous rencontrerez constamment dans R. matrice est rectangulaire mais à un seul type, et un liste Il s'agit d'un type multiple mais irrégulier. Le cadre de données emprunte une propriété à chaque type.
| Structure | Types de colonnes | longueurs des éléments | Utilisation typique |
|---|---|---|---|
| vecteur | Un seul type | Séquence unique | Une variable |
| Matrice | Un seul type | Flacons | Algèbre numérique |
| Liste | Tout mélange de types | Peut varier selon l'élément | Collections arbitraires |
| Cadre de données | Tout mélange de types | Chaque colonne a la même longueur. | Analyse tabulaire |
Puisqu'un data frame est en réalité une liste sous-jacente, les accesseurs utilisés sur les listes fonctionnent également ici, ce qui explique la réapparition du signe dollar plus loin dans ce tutoriel.
Comment créer un bloc de données
Nous pouvons créer un dataframe dans R En passant les variables a, b, c et d à la fonction data.frame(), on peut créer le dataframe et nommer les colonnes avec names(), en spécifiant simplement le nom de chaque variable.
data.frame(df, stringsAsFactors = TRUE)
Arguments:
- df: Il peut s'agir d'une matrice à convertir en bloc de données ou d'une collection de variables à joindre
- chaînesAsFactorsContrôle si les vecteurs de caractères sont convertis en colonnes de facteurs. La valeur par défaut était TRUE dans les versions antérieures et FALSE depuis R 4.0.0 ; il est donc nécessaire de la spécifier explicitement lorsque ce comportement est important.
Nous pouvons créer un dataframe dans R pour notre premier ensemble de données en combinant quatre variables de même longueur.
# Create a, b, c, d variables a <- c(10,20,30,40) b <- c('book', 'pen', 'textbook', 'pencil_case') c <- c(TRUE,FALSE,TRUE,FALSE) d <- c(2.5, 8, 10, 7) # Join the variables to create a data frame df <- data.frame(a,b,c,d) df
Sortie :
## a b c d ## 1 10 book TRUE 2.5 ## 2 20 pen FALSE 8.0 ## 3 30 textbook TRUE 10.0 ## 4 40 pencil_case FALSE 7.0
Chaque vecteur est devenu une colonne, et les quatre valeurs de chaque vecteur sont devenues les quatre lignes. Notez que les arguments n'étaient pas nommés ; R a donc déduit les en-têtes de colonnes à partir des noms des variables.
Nous pouvons voir que les en-têtes de colonnes portent le même nom que les variables. Nous pouvons changer le nom de la colonne dans R avec la fonction noms(). Consultez l'exemple de trame de données de création R ci-dessous :
# Name the data frame names(df) <- c('ID', 'items', 'store', 'price') df
Sortie :
## ID items store price ## 1 10 book TRUE 2.5 ## 2 20 pen FALSE 8.0 ## 3 30 textbook TRUE 10.0 ## 4 40 pencil_case FALSE 7.0
L'affectation à `names()` remplace tous les en-têtes simultanément ; le vecteur de remplacement doit donc contenir exactement une entrée par colonne. Pour renommer une seule colonne, utilisez un index du vecteur `names`, comme dans `names(df)[2] <- 'product'`.
# Print the structure
str(df)
Sortie :
## 'data.frame': 4 obs. of 4 variables: ## $ ID : num 10 20 30 40 ## $ items: Factor w/ 4 levels "book","pen","pencil_case",..: 1 2 4 3 ## $ store: logi TRUE FALSE TRUE FALSE ## $ price: num 2.5 8 10 7
Note de version. Le résultat ci-dessus a été généré avec une version de R antérieure à la 4.0.0, où la fonction `data.frame()` convertissait par défaut les vecteurs de caractères en facteurs, ce qui explique pourquoi `items` est présenté comme un facteur à quatre niveaux. La documentation de base de R indique que ce comportement par défaut est celui de la version initiale de R. modifié en stringsAsFactors = FALSE pour R 4.0.0L'exécution du même code sur une version actuelle laisse les éléments sous forme de colonne de caractères simples, et la fonction `str()` affiche `chr` à la place. Ajoutez `stringsAsFactors = TRUE` à l'appel `data.frame()` pour reproduire le résultat affiché, ou consultez le tutoriel sur les facteurs pour les cas où des facteurs sont réellement souhaités.
Tranche de données
Une fois le cadre construit, l'étape suivante consiste à en extraire des parties. Le découpage est la méthode de base en R pour ce faire ; elle utilise les mêmes crochets que les vecteurs, mais avec deux positions au lieu d'une.
Il est possible d'extraire des valeurs d'un DataFrame. On sélectionne les lignes et les colonnes à retourner entre crochets, précédés du nom du DataFrame.
Un bloc de données est composé de lignes et de colonnes, df[A, B]. A représente les lignes et B les colonnes. Nous pouvons découper soit en spécifiant les lignes et/ou les colonnes.
D'après l'image 1 ci-dessous, la partie gauche représente Lignes, et la partie droite est la colonnes. Notez que le symbole : signifie à. Par exemple, 1:3 vise à sélectionner des valeurs parmi 1 à 3.
![Syntaxe de découpage des data frames en R : df[A, B] avec les lignes à gauche de la virgule et les colonnes à droite](https://www.guru99.com/images/r_programming/032918_1452_RDataFrames1.png)
Le diagramme ci-dessous illustre comment accéder aux différentes sélections du cadre de données :
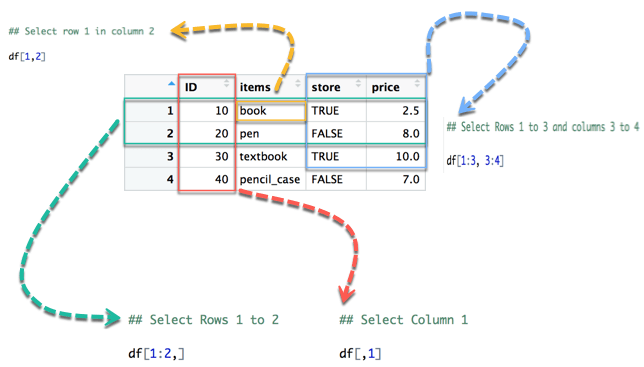
- La flèche jaune sélectionne le rangée 1 " colonne 2
- La flèche verte sélectionne le lignes 1 à 2 ans, qui
- La flèche rouge sélectionne le colonne 1
- La flèche bleue sélectionne le lignes 1 à 3 et colonnes 3 à 4 ans, qui
Notez que si nous laissons la partie gauche vide, R sélectionnera toutes les rangées. Par analogie, si on laisse la partie droite vide, R sélectionnera toutes les colonnes.
Nous pouvons exécuter le code dans la console :
## Select row 1 in column 2
df[1,2]
Sortie :
## [1] book ## Levels: book pen pencil_case textbook
La ligne Levels apparaît car les éléments sont pris en compte dans cette session. Sur R 4.0.0 et versions ultérieures, le même appel affiche la chaîne « book » sans la ligne Levels.
## Select Rows 1 to 2
df[1:2,]
Sortie :
## ID items store price ## 1 10 book TRUE 2.5 ## 2 20 pen FALSE 8.0
## Select Columns 1
df[,1]
Sortie :
## [1] 10 20 30 40
La sélection d'une seule colonne avec `df[,1]` supprime le cadre et renvoie un vecteur simple. Ajoutez `drop = FALSE`, comme dans `df[, 1, drop = FALSE]`, lorsqu'un cadre de données à une seule colonne est nécessaire.
## Select Rows 1 to 3 and columns 3 to 4
df[1:3, 3:4]
Sortie :
## store price ## 1 TRUE 2.5 ## 2 FALSE 8.0 ## 3 TRUE 10.0
Il est également possible de sélectionner les colonnes par leur nom. Par exemple, le code ci-dessous…tracdeux colonnes : ID et magasin.
# Slice with columns name df[, c('ID', 'store')]
Sortie :
## ID store ## 1 10 TRUE ## 2 20 FALSE ## 3 30 TRUE ## 4 40 FALSE
Les noms sont plus sûrs que les positions dans le code de production, car l'insertion ou le réordonnancement d'une colonne modifie silencieusement ce à quoi df[, 3] fait référence tandis que df[, 'store'] continue de pointer vers les mêmes données.
Ajouter une colonne au bloc de données
Vous pouvez également ajouter une colonne à un DataFrame. Pour cela, utilisez le symbole $ afin de nommer la nouvelle variable et d'ajouter une colonne au DataFrame dans R.
# Create a new vector quantity <- c(10, 35, 40, 5) # Add `quantity` to the `df` data frame df$quantity <- quantity df
Sortie :
## ID items store price quantity ## 1 10 book TRUE 2.5 10 ## 2 20 pen FALSE 8.0 35 ## 3 30 textbook TRUE 10.0 40 ## 4 40 pencil_case FALSE 7.0 5
Remarque : Le nombre d’éléments du vecteur doit être égal au nombre d’éléments du data frame. Exécutez l’instruction suivante pour ajouter une colonne au data frame dans R.
quantity <- c(10, 35, 40)
# Add `quantity` to the `df` data frame
df$quantity <- quantity
Donne une erreur :
Error in `lt;-.data.frame`(`*tmp*`, quantity, value = c(10, 35, 40))
replacement has 3 rows, data has 4
Le message indique le nom de l'opérateur de remplacement pour les data frames et précise les deux nombres d'éléments, vous indiquant ainsi exactement ce qu'il faut corriger. R ne réutilise un élément de remplacement que si sa longueur est un diviseur exact du nombre de lignes. C'est pourquoi une valeur de longueur 1, comme `df$currency <- 'EUR'`, est acceptée, tandis qu'un vecteur de longueur 3 correspondant à quatre lignes est refusé. `cbind()` ajoute une colonne de la même manière, et `rbind()` est son équivalent pour l'ajout de lignes.
Sélectionnez une colonne d'un bloc de données
Il arrive que l'on doive stocker une colonne d'un dataframe pour une utilisation ultérieure ou effectuer une opération sur une colonne. On peut utiliser le signe $ pour sélectionner la colonne dans un dataframe.
# Select the column ID
df$ID
Sortie :
## [1] 1 2 3 4
Lisez attentivement ce résultat. L'identifiant (ID) a été construit à partir du vecteur c(10, 20, 30, 40), donc une console active affichera ici 10 20 30 40 ; les chiffres 1 2 3 4 affichés ci-dessus correspondent aux positions sur la ligne et non aux valeurs stockées. Le [1] en début de ligne représente simplement l'indice du premier élément de cette ligne, et non une donnée.
Trois chemins permettent d'accéder à la même colonne : df$ID, df[['ID']] et df[, 'ID']. Le signe dollar permet une correspondance partielle ; ainsi, df$ID trouvera toujours ID, ce qui est pratique dans la console mais risqué dans un script enregistré.
Sous-ensemble d'un bloc de données
Dans la section précédente, nous avons sélectionné une colonne entière sans condition. Il est possible de sous-ensemble selon qu'une certaine condition était vraie ou non.
Nous utilisons la fonction subset().
subset(x, condition) arguments: - x: data frame used to perform the subset - condition: define the conditional statement
Nous souhaitons retourner uniquement les articles dont le prix est supérieur à 5, nous pouvons donc procéder comme suit :
# Select price above 5
subset(df, subset = price > 5)
Sortie :
ID items store price 2 20 pen FALSE 8 3 30 textbook TRUE 10 4 40 pencil_case FALSE 7
Les étiquettes de ligne 2, 3 et 4 correspondent aux noms de lignes d'origine conservés depuis `df`, ce qui permet de constater que la première ligne a été filtrée. La fonction `subset()` accepte également un argument `select` pour sélectionner simultanément des colonnes ; la forme équivalente entre crochets est `df[df$price > 5, ]`. Cette dernière conserve les lignes contenant des valeurs NA lorsque la condition n'est pas remplie, tandis que `subset()` les supprime. Par conséquent, les deux ne sont pas toujours interchangeables.