Tutoriel DataStage pour les débutants : IBM Outil ETL
⚡ Résumé intelligent
DataStage à partir de IBM InfoSphere extracCe module permet de traiter, transformer et charger des données d'entreprise à grande échelle. Cette page explique l'architecture, les composants, le traitement parallèle, la configuration de la réplication SQL, la création de projets, la compilation des tâches et les tests d'intégration à l'aide d'un exemple concret de distribution DB2.

Qu’est-ce que DataStage ?
Étape de données est un outil ETL utilisé pour extracDataStage permet de traiter, transformer et charger des données de la source vers la destination. Ces données peuvent provenir de fichiers séquentiels, de fichiers indexés, de bases de données relationnelles, de sources de données externes, d'archives, d'applications d'entreprise, etc. DataStage facilite l'analyse métier en fournissant des données de qualité pour l'obtention d'informations stratégiques.
L'outil DataStage ETL est utilisé dans les grandes organisations comme interface entre différents systèmes. Il prend en charge l'extraction, le traitement et la transformation des données (ETL).tracIl s'agit de la conversion, de la traduction et du chargement de données de la source vers la destination cible. Il a été lancé pour la première fois par VMark au milieu des années 90. IBM en acquérant DataStage en 2005, il a été renommé IBM WebSphere DataStage et versions ultérieures pour IBM InfoSphère.
Jusqu'à présent, les différentes versions de Datastage disponibles sur le marché étaient Enterprise Edition (PX), Server Edition, MVS Edition, DataStage for PeopleSoft, etc. La dernière édition est IBM InfoSphere DataStage.
IBM Le serveur d'informations comprend les produits suivants,
- IBM InfoSphere DataStage
- IBM Étape de qualité InfoSphere
- IBM Directeur des services d'information InfoSphere
- IBM Analyseur d'informations InfoSphere
- IBM Serveur d'informations rapideTrack
- IBM Glossaire métier InfoSphere
La définition étant établie, la section suivante examine ce que le produit peut réellement faire à l'intérieur d'un entreposage de données sûr et sécurisé.
Présentation de DataStage
Datastage a les capacités suivantes.
- Il peut intégrer des données provenant du plus large éventail de sources de données d'entreprise et externes.
- Implémente des règles de validation des données
- Il est utile pour traiter et transformer de grandes quantités de données
- Il utilise une approche de traitement parallèle évolutive
- Il peut gérer des transformations complexes et gérer plusieurs processus d'intégration
- Tirez parti de la connectivité directe aux applications d’entreprise en tant que sources ou cibles
- Exploitez les métadonnées pour l’analyse et la maintenance
- Operatests par lots, en temps réel ou en tant que service Web
Dans les sections suivantes de ce didacticiel DataStage, nous décrivons brièvement les aspects suivants de IBM InfoSphere DataStage :
- Transformation de données
- Carrières
- Traitement parallèle
InfoSphere DataStage et QualityStage peuvent accéder aux données des applications d'entreprise et des sources de données telles que :
- Bases de données relationnelles
- Bases de données mainframe
- Applications métiers et analytiques
- Planification des ressources d'entreprise (ERP) ou bases de données de gestion de la relation client (CRM)
- Traitement analytique en ligne (OLAP) ou bases de données de gestion des performances
Types d'étapes de traitement
IBM Le travail de l'infosphère se compose d'étapes individuelles reliées entre elles. Il décrit le flux de données d'une source de données vers une cible de données. Habituellement, une étape comporte au minimum une entrée de données et/ou une sortie de données. Cependant, certaines étapes peuvent accepter plusieurs entrées et sorties de données vers plusieurs étapes.
Dans la conception de tâches, les différentes étapes que vous pouvez utiliser sont :
- Étape de transformation
- Étape de filtrage
- Étape agrégateur
- Étape Supprimer les doublons
- Rejoindre la scène
- Étape de recherche
- Étape de copie
- Étape de tri
- Conteneurs
Pourquoi utiliser DataStage pour l'intégration de données ?
Connaître la liste des fonctionnalités est une chose ; savoir quand l’outil justifie son coût de licence en est une autre. DataStage est choisi pour les charges de travail où le volume, la gouvernance et l’hétérogénéité des sources rendent les scripts écrits manuellement ingérables.
La raison principale est le débit. Le moteur répartissant les données entre les nœuds et assurant la diffusion simultanée des enregistrements entre les différentes étapes, l'ajout de matériel augmente le débit de manière quasi linéaire. Une tâche conçue sur un environnement de développement à deux nœuds s'exécute sans modification sur un cluster de production à huit nœuds.
Les autres raisons sont d'ordre organisationnel plutôt que technique :
- Métadonnées partagées : Les définitions de tables, les connexions et les termes métier sont stockés une seule fois dans le référentiel et réutilisés par chaque tâche, ce qui élimine la dérive qui apparaît lorsque chaque développeur définit une source indépendamment.
- Qualité des données intégrée : QualityStage exécute les opérations d'investigation, de standardisation, de correspondance et de survie en parallèle du flux ETL, de sorte que le nettoyage ne nécessite pas de produit supplémentaire.
- Connectivité étendue : Les connecteurs natifs atteignent DB2, OracleTeradata, mainframe VSAM, SAP, Salesforce et le stockage d'objets dans le cloud sans code personnalisé.
- Operacontrôle national : Director fournit l'historique d'exécution, le nombre de lignes, les avertissements et les points de redémarrage, que les auditeurs acceptent comme preuve d'un pipeline de données contrôlé.
- Réutilisabilité: Les conteneurs et ensembles de paramètres partagés permettent à une transformation testée de servir plusieurs tâches au lieu d'être copiée dans chacune d'elles.
Ces avantages dépendent directement de la manière dont le produit est assemblé, ce que la section suivante explique.
Composants DataStage et Architecture
DataStage comprend quatre composants principaux, à savoir :
- administrateur: Il est utilisé pour les tâches d'administration. Cela inclut la configuration des utilisateurs DataStage, la configuration des critères de purge et la création et le déplacement de projets.
- Gestionnaire: C'est l'interface principale du référentiel d'ETL DataStage. Il est utilisé pour le stockage et la gestion de métadonnées réutilisables. Grâce au gestionnaire DataStage, on peut visualiser et modifier le contenu du référentiel.
- Designer: Une interface de conception utilisée pour créer des applications OU des tâches DataStage. Il spécifie la source de données, la transformation requise et la destination des données. Les travaux sont compilés pour créer un exécutable planifié par le directeur et exécuté par le serveur.
- Réalisateur: Il est utilisé pour valider, planifier, exécuter et surveiller les tâches du serveur DataStage et les tâches parallèles.

L'image ci-dessus explique comment IBM Infosphere DataStage interagit avec d'autres éléments du IBM Plateforme de serveur d'informations. DataStage est divisé en deux sections, Composants partagés et runtime ArchitectureLe tableau ci-dessous détaille la contribution de chacune de ces deux sections.
|
Owned |
Interface utilisateur unifiée |
|
|
Services communs |
|
|
|
Traitement parallèle commun |
|
|
|
Runtime Architecture |
Script SST |
|
Fonctionnement du traitement parallèle dans DataStage
Le tableau d'architecture ci-dessus désigne le traitement parallèle commun comme un service partagé. Cette section explique comment ce service exécute concrètement une tâche, car ce concept a été présenté dans la vue d'ensemble et détermine la vitesse d'exécution de la tâche.
Un travail parallèle utilise deux mécanismes simultanément, et les deux sont appliqués automatiquement lors de l'exécution plutôt que d'être codés manuellement.
1. Parallélisme du pipeline. Chaque étape d'un traitement démarre simultanément, sans attendre la fin de la précédente. L'étape source commence la lecture des lignes et les transfère vers un pipeline en mémoire. Le transformateur démarre dès l'arrivée des premières lignes et transfère sa sortie vers un second pipeline. Le connecteur cible commence l'écriture immédiatement après. Aucun fichier de destination intermédiaire n'est créé ; ainsi, dans un traitement en trois étapes, la lecture, la transformation et l'écriture se chevauchent au lieu de s'exécuter séquentiellement.
2. Parallélisme de partition. Les lignes sont réparties en partitions distinctes, et une copie complète de la logique de traitement est exécutée sur chaque partition, sur son propre nœud. Huit partitions correspondent à huit instances de Transformer exécutées simultanément. À la fin du flux, les partitions sont regroupées en un flux unique destiné à la cible.
Le choix de la méthode de partitionnement appropriée est la principale décision de réglage qu'un développeur doit prendre :
- Voiture: Par défaut, le moteur choisit une méthode en fonction des besoins de l'étape.
- Hash: Envoie les lignes ayant la même valeur de clé au même nœud. Nécessaire avant les opérations de jointure, d'agrégation et de suppression des doublons afin que les clés correspondantes soient réunies.
- Tournoi à la ronde : Traite les lignes uniformément une par une. Idéal pour charger un fichier plat où les groupes de clésping n'a pas d'importance.
- Entier: Copie l'intégralité des données sur chaque nœud. Utilisé pour les petites tables de référence lors d'une étape de recherche.
- Même: Le partitionnement existant reste inchangé, ce qui évite un repartitionnement inutile entre deux étapes.
- Plage et module : Répartissez les lignes par bande de valeurs ou par reste de clé numérique lorsqu'une répartition uniforme est nécessaire.
Un fichier de configuration (APT_CONFIG_FILE) indique le nombre de nœuds. Comme ce nombre est géré en dehors de la tâche, une même tâche compilée peut être exécutée aussi bien sur un ordinateur portable que sur une infrastructure de production sans aucune modification de conception.
Avant de pouvoir mettre tout cela à l'épreuve, l'environnement doit être en place.
Pré-requis pour l'outil Datastage
Pour DataStage, vous aurez besoin de la configuration suivante.
- Infosphère
- DataStage Server 9.1.2 ou version ultérieure
- Microsoft Édition Express de Visual Studio .NET 2010 C++
- Oracle client (client complet, pas client instantané) si vous vous connectez à un Oracle base de données
- Client DB2 si vous vous connectez à une base de données DB2
Désormais, dans cette série de didacticiels DataStage pour débutants, nous allons apprendre à télécharger et installer InfoSphere Information Server.
Téléchargement et installation d'InfoSphere Information Server
Pour accéder à DataStage, téléchargez et installez la dernière version de IBM Serveur InfoSphere. Le serveur prend en charge AIX, Linux et Windows système opérateur. Vous pouvez choisir selon les besoins.
Pour migrer vos données d'une ancienne version d'infosphere vers la nouvelle version, utilisez l'outil d'échange d'actifs.
Fichiers d'installation
Pour installer et configurer Infosphere Datastage, vous devez disposer des fichiers suivants dans votre configuration.
Pour Windows,
- EtlDeploymentPackage-windows-oracle.pkg
- EtlDeploymentPackage-windows-db2.pkg
Pour Linux,
- EtlDeploymentPackage-linux-db2.pkg
- EtlDeploymentPackage-linux-oracle.pkg
Une fois le serveur installé, l'exemple pratique présenté dans la suite de cette page utilise la capture des données modifiées ; il est donc utile de voir comment ces données circulent avant de le mettre en œuvre.
Flux de processus des données modifiées dans une tâche d'étape de transaction CDC

Le diagramme ci-dessus tracil s'agit d'une seule modification de la base de données source vers la base de données cible, dans l'ordre indiqué ci-dessous.
- Le service « InfoSphere CDC » pour la base de données surveille et capture les modifications provenant d'une base de données source.
- Selon la définition de réplication, « InfoSphere CDC » transfère les données modifiées vers « InfoSphere CDC for InfoSphere DataStage ».
- Le serveur « InfoSphere CDC for InfoSphere DataStage » envoie des données à « l'étape de transaction CDC » via une session TCP/IP. Le serveur « InfoSphere CDC for InfoSphere DataStage » envoie également un message COMMIT (accompagné d'informations de signet) pour marquer la limite de transaction dans le journal capturé.
- Pour chaque message COMMIT envoyé par le serveur « InfoSphere CDC for InfoSphere DataStage », l'« étape de transaction CDC » crée des marqueurs de fin de vague (EOW). Ces marqueurs sont envoyés sur tous les liens de sortie vers l'étape du connecteur de base de données cible.
- Lorsque « l'étape du connecteur de base de données cible » reçoit un marqueur de fin de vague sur tous les liens d'entrée, elle écrit les informations de signet dans une table de signets, puis valide la transaction dans la base de données cible.
- Le serveur « InfoSphere CDC for InfoSphere DataStage » demande des informations de signet à partir d'une table de signets sur la « base de données cible ».
- Le serveur « InfoSphere CDC for InfoSphere DataStage » reçoit les informations de signet.
Ces informations sont utilisées pour,
- Déterminez le point de départ dans le journal des transactions où les modifications sont lues au début de la réplication.
- Pour déterminer si le journal des transactions existant peut être nettoyé
Configuration de la réplication SQL
Avant de commencer avec Datastage, vous devez configurer la base de données. Vous allez créer deux bases de données DB2.
- Un pour servir de source de réplication et
- Un comme cible.
Vous créerez également deux tableaux (Produit et Inventaire) et les remplirez avec des exemples de données. Ensuite, vous pouvez tester votre intégration entre SQL Réplication et étape de données.
À l'avenir, vous configurerez la réplication SQL en créant tables de contrôle, ensembles d'abonnements, enregistrements et membres d'ensembles d'abonnements. Nous en apprendrons davantage à ce sujet en détail dans la section suivante.
Ici, nous prendrons un exemple d'article de vente au détail comme base de données et créerons deux tables Inventaire et Produit. Ces tables chargeront les données de la source à la cible via ces ensembles. (tables de contrôle, ensembles d'abonnements, enregistrements et membres d'ensembles d'abonnements.)
Étape 1) Créez une base de données source appelée Vente. Sous cette base de données, créez deux tables produits et Inventaire.
Étape 2) Exécutez la commande suivante pour créer la base de données SALES.
db2 create database SALES
Étape 3) Activez la journalisation des archives pour la base de données SALES. Sauvegardez également la base de données à l’aide des commandes suivantes
db2 update db cfg for SALES using LOGARCHMETH3 LOGRETAIN db2 backup db SALES
Étape 4) Dans la même invite de commandes, accédez au sous-répertoire setupDB du répertoire sqlrepl-datastage-tutorial que vous avez créé.tracextrait du fichier compressé téléchargé.

Étape 5) Utilisez la commande suivante pour créer une table d'inventaire et importer des données dans la table en exécutant la commande suivante.
db2 import from inventory.ixf of ixf create into inventory
Étape 6) Créez une table cible. Nommez la base de données cible comme STAGEDB.
Puisque vous avez maintenant créé les bases de données source et cible, la prochaine étape de ce didacticiel DataStage, nous verrons comment la répliquer.
Les informations suivantes peuvent être utiles dans configuration d'une source de données ODBC dans le IBM Documentation d'InfoSphere Information Server.
Création des objets de réplication SQL
L'image ci-dessous illustre le flux des données modifiées, acheminées de la base de données source vers la base de données cible. Vous créez une correspondance source-cible.ping entre les tables connues sous le nom de membres d'un ensemble d'abonnements et regroupez les membres dans un abonnement.

L'unité de réplication au sein d'InfoSphere CDC (Change Data Capture) est appelée abonnement.
- Les modifications effectuées dans la source sont capturées dans la « Table de contrôle de capture » qui est envoyée à la table CD puis à la table cible. Tandis que le programme de candidature contiendra les détails sur la ligne à partir de laquelle les modifications doivent être effectuées. Il rejoindra également la table CD dans l'ensemble d'abonnement.
- Un abonnement contient une carteping détails qui précisent comment les données d'un magasin de données source sont appliquées à un magasin de données cible. Remarque : CDC est maintenant appelé Réplication des données de l'infosphère.
- Lorsqu'un abonnement est exécuté, InfoSphere CDC capture les modifications apportées à la base de données source. InfoSphere CDC transmet les données modifiées à la cible et stocke les informations sur les points de synchronisation dans une table de signets de la base de données cible.
- InfoSphere CDC utilise les informations de signet pour surveiller la progression du travail InfoSphere DataStage.
- En cas d'échec, les informations du signet sont utilisées comme point de redémarrage. Dans notre exemple, l'ASN.IBMLa table SNAP_FEEDETL stocke les informations de point de synchronisation liées à DataStage qui sont utilisées pour track Progression de DataStage.
Dans cette section de IBM Tutoriel de formation DataStage, vous devez faire les choses suivantes,
- Créez des tables CAPTURE CONTROL et APPLY CONTROL pour stocker les options de réplication
- Enregistrez les tables PRODUCT et INVENTORY comme sources de réplication
- Créer un ensemble d'abonnements avec deux membres
- Créer des membres d'un ensemble d'abonnements et cibler des tables CCD
Utilisez le programme de ligne de commande ASNCLP pour configurer la réplication SQL
Étape 1) Recherchez le fichier de script crtCtlTablesCaptureServer.asnclp dans le répertoire sqlrepl-datastage-tutorial/setupSQLRep.
Étape 2) Dans le fichier remplacer et " » avec votre identifiant et votre mot de passe de connexion à la base de données SALES.
Étape 3) Accédez au répertoire sqlrepl-datastage-tutorial/setupSQLRep et exécutez le script. Utilisez la commande suivante. La commande se connectera à la base de données SALES, générera un script SQL pour créer les tables de contrôle Capture.
asnclp –f crtCtlTablesCaptureServer.asnclp
Étape 4) Recherchez le fichier de script crtCtlTablesApplyCtlServer.asnclp dans le même répertoire. Remplacez maintenant deux instances de et " » avec l'identifiant et le mot de passe de connexion à la base de données STAGEDB.
Étape 5) Maintenant, dans la même invite de commande, utilisez la commande suivante pour créer des tables de contrôle d'application.
asnclp –f crtCtlTablesApplyCtlServer.asnclp
Étape 6) Localisez les fichiers de script crtRegistration.asnclp et remplacez toutes les instances de avec l'ID utilisateur pour se connecter à la base de données SALES. Changez également " » au mot de passe de connexion.
Étape 7) Pour enregistrer les tables sources, utilisez le script suivant. Dans le cadre de la création de l'enregistrement, le programme ASNCLP créera deux tables CD. CDPRODUCT ET CDINVENTAIRE.
asnclp –f crtRegistration.asnclp
La commande CREATE REGISTRATION utilise les options suivantes :
- Actualisation différentielle : Il invite le programme Apply à mettre à jour la table cible uniquement lorsque les lignes de la table source changent.
- Image les deux: Cette option est utilisée pour enregistrer la valeur dans la colonne source avant que le changement ne se produise, et une pour la valeur après le changement.
Étape 8) Pour vous connecter à la base de données cible (STAGEDB), suivez les étapes suivantes.
- Recherchez le fichier crtTableSpaceApply.bat, ouvrez-le dans un éditeur de texte
- Remplacer et avec l'identifiant et le mot de passe
- Dans la fenêtre de commande DB2, entrez crtTableSpaceApply.bat et exécutez le fichier.
- Ce fichier batch crée un nouveau tablespace sur la base de données cible ( STAGEDB)
Étape 9) Recherchez les fichiers de script crtSubscriptionSetAndAddMembers.asnclp et effectuez les modifications suivantes.
- Remplacer toutes les instances de et avec l'identifiant et le mot de passe de connexion à la base de données SALES (source).
- Remplacer toutes les instances de et avec l'ID utilisateur de connexion à la base de données STAGEDB (cible).
Après les modifications, exécutez le script pour créer un ensemble d'abonnements (ST00) qui regroupe les tables source et cible. Le script crée également deux membres d'ensemble d'abonnements et un CCD (consistent change data) dans la base de données cible qui stockera les données modifiées. Ces données seront consommées par Infosphere DataStage.
Étape 10) Exécutez le script pour créer l'ensemble d'abonnements, les membres de l'ensemble d'abonnements et les tables CCD.
asnclp –f crtSubscriptionSetAndAddMembers.asnclp
Diverses options utilisées pour créer un ensemble d'abonnements et deux membres incluent
- Terminer en mode condensé
- Externe
- Type de charge import export
- Chronométrage continu
Étape 11) En raison d'un défaut dans les outils d'administration de réplication. Vous devez exécuter un autre fichier batch pour définir la colonne TARGET_CAPTURE_SCHEMA dans le IBMTable de contrôle SNAP_SUBS_SET sur null.
- Localisez le fichier updateTgtCapSchema.bat. Ouvrez-le dans un éditeur de texte. Remplacer et avec l'ID utilisateur pour se connecter à la base de données STAGEDB.
- Dans la fenêtre de commande DB2, entrez la commande updateTgtCapSchema.bat et exécutez le fichier.
Création des fichiers de définition pour mapper les tables CCD à DataStage
Avant de procéder à la réplication à l'étape suivante, nous devons connecter la table CCD à DataStage. Dans cette section, nous verrons comment connecter SQL à DataStage.
Pour connecter une table CCD à DataStage, vous devez créer des fichiers de définition DataStage (.dsx). Le format .dsx est utilisé par DataStage pour importer et exporter les définitions de tâches. Vous utiliserez un script ASNCLP pour créer deux fichiers .dsx. Par exemple, nous en avons créé deux ici.
- stagedb_AQ00_SET00_sJobs.dsx: crée une séquence de tâches qui dirige le flux de travail des quatre tâches parallèles.
- stagedb_AQ00_SET00_pJobs.dsx : Crée les quatre tâches parallèles
Le programme ASNCLP mappe automatiquement la colonne CCD au format de colonne Datastage. Il n'est pris en charge que lorsque l'ASNCLP s'exécute sur Windows, Linux ou Procédure Unix.

Les tâches Datastage extraient les lignes de la table CCD.
- Une tâche définit un point de synchronisation là où DataStage s'est arrêté dans extracLe traitement récupère les données des deux tables. Il obtient ces informations en sélectionnant la valeur SYNCHPOINT pour l'ensemble d'abonnements ST00. IBMSNAP_SUBS_SET et en l'insérant dans la colonne MAX_SYNCHPOINT du IBMTableau SNAP_FEEDETL.
- Deux emplois qui extracLes données proviennent des tables PRODUCT_CCD et INVENTORY_CCD. Les tâches savent quelles lignes démarrer.tracen sélectionnant les valeurs MIN_SYNCHPOINT et MAX_SYNCHPOINT dans le IBMTable SNAP_FEEDETL pour l'ensemble d'abonnements.
Une fois les définitions cartographiées, la réplication peut maintenant être lancée afin que les tables CCD commencent à se remplir.
Démarrage de la réplication
Pour démarrer la réplication, vous suivrez les étapes ci-dessous. Lorsque les tables CCD sont remplies de données, cela indique que la configuration de la réplication est validée. Pour afficher les données répliquées dans les tables CCD cible, utilisez l'interface utilisateur graphique de DB2 Control Center.
Étape 1) Assurez-vous que DB2 est en cours d'exécution, sinon utilisez démarrage de DB2 commander.
Étape 2) Utilisez ensuite la commande asncap à partir d’une invite du système d’exploitation pour démarrer le programme de capture. Par exemple.
asncap capture_server=SALES
La commande ci-dessus spécifie la base de données SALES comme serveur de capture. Gardez la fenêtre de commande ouverte pendant l'exécution de la capture.
Étape 3) Ouvrez maintenant une nouvelle invite de commande. Puis démarrez le APPLIQUER programme en utilisant la commande asnapply.
asnapply control_server=STAGEDB apply_qual=AQ00

- La commande spécifie la base de données STAGEDB comme serveur de contrôle Apply (la base de données qui contient les tables de contrôle Apply)
- AQ00 comme qualificatif Apply (l'identifiant de cet ensemble de tables de contrôle)
Laissez la fenêtre de commande ouverte pendant qu'Apply est en cours d'exécution.
Étape 4) Ouvrez maintenant une autre invite de commande et exécutez la commande db2cc pour lancer le centre de contrôle DB2. Acceptez le centre de contrôle par défaut.
Étape 5) Maintenant, dans l'arborescence de navigation de gauche, ouvrez Toutes les bases de données > STAGEDB, puis cliquez sur Tables. Double cliquez sur le nom de la table (Product CCD) pour ouvrir la table. Cela ressemblera à ceci.

De même, vous pouvez également ouvrir la table CCD pour INVENTORY.

La réplication alimente désormais les tables CCD, l'attention se déplace donc de la base de données vers les clients DataStage.
Comment créer des projets dans l'outil Datastage
Tout d’abord, vous allez créer un projet dans DataStage. Pour cela, vous devez être un administrateur InfoSphere DataStage.
Une fois l'installation et la réplication terminées, vous devez créer un projet. Dans DataStage, les projets sont une méthode d'organisation de vos données. Cela comprend la définition des fichiers de données, des étapes et des tâches de construction dans un projet spécifique.
Pour créer un projet dans DataStage, suivez les étapes ci-dessous :
Étape 1) Lancez le logiciel DataStage
Lancez l'administrateur DataStage et QualityStage. Cliquez ensuite sur Démarrer > Tous les programmes > IBM Serveur d'informations > IBM Administrateur WebSphere DataStage et QualityStage.
Étape 2) Connectez le serveur et le client DataStage
Pour vous connecter au serveur DataStage à partir de votre client DataStage, saisissez des détails tels que le nom de domaine, l'ID utilisateur, le mot de passe et les informations sur le serveur.
Étape 3) Ajouter un nouveau projet
Dans la fenêtre Administration WebSphere DataStage. Cliquez sur l'onglet Projets, puis cliquez sur Ajouter.
Étape 4) Entrez les détails du projet
Dans la fenêtre Administration WebSphere DataStage, entrez des détails tels que
- Nom
- Emplacement du fichier
- Cliquez sur OK'

Chaque projet contient :
- Emplois DataStage
- Composants intégrés. Ce sont des composants prédéfinis utilisés dans un travail.
- Composants définis par l'utilisateur. Il s'agit de composants personnalisés créés à l'aide de DataStage Manager ou DataStage Designer.
Nous verrons comment importer des tâches de réplication dans Datastage Infosphere.
Comment importer des tâches de réplication dans Datastage et QualityStage Designer
Vous importerez des travaux dans le IBM Client InfoSphere DataStage et QualityStage Designer. Et vous les exécutez dans le IBM Client InfoSphere DataStage et QualityStage Director.
Le client-concepteur est comme une toile vierge pour les projets de construction. Il extracIl permet de traiter, transformer, charger et vérifier la qualité des données. Il fournit les outils qui constituent les éléments de base d'un travail. Il comprend
- Étapes: Il se connecte aux sources de données pour lire ou écrire des fichiers et traiter les données.
- Liens: Il relie les étapes le long desquelles circulent vos données
Les étapes du client InfoSphere DataStage et QualityStage Designer sont stockées dans la palette d'outils Designer.
Les étapes suivantes sont incluses dans InfoSphere QualityStage :
- Étape d'enquête
- Étape de standardisation
- Étape de fréquence de correspondance
- Étape de jumelage à source unique
- Étape de correspondance à deux sources
- Survivre à l'étape
- Étape d’évaluation de la qualité de la normalisation (SQA)
Vous pouvez créer 4 types de Jobs dans l'infosphère DataStage.
- Tâche parallèle
- Travail de séquence
- Travail sur ordinateur central
- Travail de serveur
Voyons étape par étape comment importer des fichiers de tâches de réplication.
Étape 1) Démarrez DataStage et QualityStage Designer. Cliquez sur Démarrer > Tous les programmes > IBM Serveur d'informations > IBM WebSphere DataStage et QualityStage Designer
Étape 2) Dans la fenêtre Attacher au projet, entrez les détails suivants.
- Domaine
- Nom d'utilisateur ( Ou : Nom d'épouse )
- Mot de passe
- Nom Du Projet
- OK

Étape 3) Maintenant, dans le menu Fichier, cliquez sur importer -> Composants DataStage.
Une nouvelle fenêtre d'importation du référentiel DataStage s'ouvrira.
- Dans cette fenêtre, parcourez STAGEDB_AQ00_ST00_sJobs.dsx fichier que nous avions créé plus tôt
- Sélectionnez l'option "Tout importer".
- Cochez la case « Effectuer une analyse d’impact ».
- Cliquez sur OK.'

Une fois la tâche importée, DataStage créera la tâche STAGEDB_AQ00_ST00_sequence.
Étape 4) Suivez les mêmes étapes pour importer le Fichier STAGEDB_AQ00_ST00_pJobs.dsx. Cette importation crée les quatre tâches parallèles.
Étape 5) Sous le volet Référentiel du concepteur -> Ouvrez le dossier SQLREP. À l’intérieur du dossier, vous verrez Sequence Job et quatre tâches parallèles.
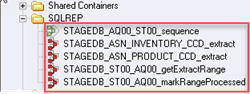
Étape 6) Pour voir le travail de séquence. Accédez à l'arborescence du référentiel, cliquez avec le bouton droit sur la tâche STAGEDB_AQ00_ST00_sequence et cliquez sur Modifier. Il affichera le flux de travail des quatre tâches parallèles contrôlées par la séquence de tâches.

Chaque icône est une étape,
- obtenirExtracÉtape de la gamme: Il met à jour le IBMTable SNAP_FEEDETL. Elle définira le point de départ des données extraction au point où DataStage dernier extracted rows et définir le point final sur la dernière transaction traitée pour l'ensemble d'abonnements.
- obtenirExtracsuccès de la plageCette étape fournit les points de départ à l'extractFromINVENTORY_CCD étape et extractFromPRODUCT_CCD étape
- AllExtractsSuccès : Cette étape garantit que les deux extractFromINVENTORY_CCD et extracL'opération tFromPRODUCT_CCD s'est terminée avec succès. Les points de synchronisation des dernières lignes récupérées sont ensuite transmis à l'étape setRangeProcessed.
- Étape setRangeProcessed: Il met à jour IBMTable SNAP_FEEDETL. Ainsi, DataStage sait d'où commencer le prochain cycle d'extraction de données.tracproduction
Étape 7) Pour voir les travaux parallèles. Cliquez avec le bouton droit sur STAGEDB_ASN_INVENTORY_CCD et sélectionnez modifier sous le référentiel. Cela ouvrira la fenêtre comme indiqué ci-dessous.

Ici, dans l'image ci-dessus, vous pouvez voir que les données de la table CCD d'inventaire et SyncLes détails du point h de la table FEEDETL sont rendus à l'étape Lookup_6.
Les tâches importées ne pointent toujours vers rien, il faut donc définir un objet de connexion de données.
Création d'une connexion de données entre DataStage et la base de données STAGEDB
L'étape suivante consiste désormais à établir une connexion de données entre InfoSphere DataStage et la base de données cible de réplication SQL. Il contient les tables CCD.
Dans DataStage, vous utilisez des objets de connexion de données avec des étapes de connecteur associées pour définir rapidement une connexion à une source de données dans une conception de tâche.
Étape 1) STAGEDB contient à la fois les tables de contrôle Apply que DataStage utilise pour synchroniser ses données.traction et les tables CCD à partir desquelles les données sont extraitestracted. Utilisez les commandes suivantes
db2 catalog tcpip node SQLREP remote ip_address server 50000 db2 catalog database STAGEDB as STAGEDB2 at node SQLREP
Note: Adresse IP du système sur lequel STAGEDB a été créé
Étape 2) Cliquez sur Fichier > Nouveau > Autre > Connexion de données.
Étape 3) Vous aurez une fenêtre avec deux onglets, Paramètres et Général.

Étape 4) Dans cette étape,
- En général, onglet, nommez la connexion de données sqlreplConnect
- Dans l'onglet Paramètres, comme indiqué ci-dessous
- Cliquez sur le bouton Parcourir à côté du champ « Connecter à l'aide du type d'étape » et dans le champ
- Ouvrez la fenêtre, accédez à l'arborescence du référentiel jusqu'à Types d'étape -> Parallèle -> Base de données -> Connecteur DB2.
- Cliquez sur Ouvrir.

Étape 5) Dans le tableau Paramètres de connexion, entrez des détails tels que
- Chaîne de connexion: STAGEDB2
- Nom d'utilisateur ( Ou : Nom d'épouse ): ID utilisateur pour la connexion à la base de données STAGEDB
- Mot de passe: Mot de passe de connexion à la base de données STAGEDB
- Instance : Nom de l'instance DB2 qui contient la base de données STAGEDB
Étape 6) Dans la fenêtre suivante, enregistrez la connexion de données. Cliquez sur le bouton « Enregistrer ».
Importation de définitions de table de STAGEDB dans DataStage
À l'étape précédente, nous avons vu qu'InfoSphere DataStage et la base de données STAGEDB sont connectés. Maintenant, importez la définition de colonne et d'autres métadonnées pour les tables PRODUCT_CCD et INVENTORY_CCD dans le référentiel Information Server.
Dans la fenêtre du concepteur, suivez les étapes ci-dessous.
Étape 1) Sélectionnez Importer > Définitions de table > Démarrer l'assistant d'importation de connecteur.
Étape 2) Dans la page de sélection du connecteur de l'assistant, sélectionnez le connecteur DB2 et cliquez sur Suivant.

Étape 3) Cliquez sur charger sur la page de détails de la connexion. Cela remplira les champs de l'assistant avec les informations de connexion de la connexion de données que vous avez créée dans le chapitre précédent.

Étape 4) Cliquez sur Tester la connexion sur la même page. Cela invitera DataStage à tenter une connexion à la base de données STAGEDB. Vous pouvez voir le message « la connexion est réussie ». Cliquez sur Suivant.

Étape 5) Assurez-vous que sur la page Emplacement de la source de données, les champs Nom d'hôte et Nom de la base de données sont correctement renseignés. Cliquez ensuite sur suivant.
Étape 6) Sur la page Schéma. Saisissez le schéma des tables de contrôle Apply (ASN) ou vérifiez que le schéma ASN est pré-rempli dans le champ Schéma. Cliquez ensuite sur suivant. La page de sélection affichera la liste des tables définies dans le schéma ASN.

Étape 7) La première table à partir de laquelle nous devons importer des métadonnées est IBMSNAP_FEEDETL est une table de contrôle d'application. Elle contient des informations détaillées sur les points de synchronisation permettant à DataStage de conserver track lignes extraites des tables CCD. Choisissez IBMSNAP_FEEDETL et cliquez sur Suivant.
Étape 8) Pour terminer l'importation du IBMDéfinition de la table SNAP_FEEDETL. Cliquez sur importer puis dans la fenêtre ouverte, cliquez sur ouvrir.
Étape 9) Répétez les étapes 1 à 8 deux fois de plus pour importer les définitions de la table PRODUCT_CCD, puis de la table INVENTORY_CCD.
REMARQUE: lors de l'importation des définitions pour l'inventaire et le produit, assurez-vous de modifier les schémas ASN par le schéma sous lequel PRODUCT_CCD et INVENTORY_CCD ont été créés.
DataStage dispose désormais de tous les détails nécessaires pour se connecter à la base de données cible de réplication SQL.
Définition des propriétés pour les tâches DataStage
Pour chacune des quatre tâches parallèles DataStage dont nous disposons, il contient une ou plusieurs étapes qui se connectent à la base de données STAGEDB. Vous devez modifier les étapes pour ajouter des informations de connexion et créer un lien vers les fichiers d'ensemble de données que DataStage remplit.
Les étapes possèdent des propriétés prédéfinies modifiables. Nous allons ici modifier certaines de ces propriétés pour l'étape STAGEDB_ASN_PRODUCT_CCD_ex.tractravail parallèle.
Étape 1) Parcourez l'arborescence du référentiel Designer. Sous le dossier SQLREP, sélectionnez STAGEDB_ASN_PRODUCT_CCD_extracPour modifier une tâche parallèle, cliquez dessus avec le bouton droit. La fenêtre de conception s'ouvre alors dans la palette du concepteur.
Étape 2) Repérez l'icône verte. Cette icône indique l'étape du connecteur DB2. Elle est utilisée pour…tracting données à partir du tableau CCD. Double-cliquez sur l'icône. Une fenêtre d'éditeur de scène s'ouvre.


Étape 3) Dans l'éditeur, cliquez sur Charger pour remplir les champs avec les informations de connexion. Pour fermer l'éditeur d'étape et enregistrer vos modifications, cliquez sur OK.
Étape 4) Revenez maintenant à la fenêtre de conception pour STAGEDB_ASN_PRODUCT_CCD_extract tâche parallèle. Localisez l'icône pour obtenirSyncÉtape du connecteur DB2 hPoints. Double-cliquez ensuite sur l'icône.
Étape 5) Cliquez maintenant sur le bouton Charger pour remplir les champs avec les informations de connexion.
REMARQUE: Si vous utilisez une base de données autre que STAGEDB comme serveur de contrôle Apply. Sélectionnez ensuite l'option permettant de charger les informations de connexion pour le getSyncÉtape hPoints, qui interagit avec les tables de contrôle plutôt qu'avec la table CCD.
Étape 6) Dans cette étape,
- Créez un fichier texte vide sur le système sur lequel InfoSphere DataStage s'exécute.
- Nommez ce fichier productdataset.ds et notez l’endroit où vous l’avez enregistré.
- DataStage écrira les modifications dans ce fichier après avoir récupéré les modifications de la table CCD.
- Les ensembles de données ou les fichiers utilisés pour déplacer des données entre des tâches liées sont appelés ensembles de données persistants. Il est représenté par une étape DataSet.
Étape 7) Ouvrez maintenant l'éditeur d'étape dans la fenêtre de conception et double-cliquez sur l'icône insert_into_a_dataset. Cela ouvrira une autre fenêtre.

Étape 8) Dans cette fenêtre,

- Sous l'onglet Propriétés, assurez-vous que le Target Le dossier est ouvert et la propriété File = DATASETNAME est mise en surbrillance.
- A droite, vous aurez un champ fichier
- Entrez le chemin complet du fichier productdataset.ds
- Cliquez sur OK'.
Vous avez maintenant mis à jour toutes les propriétés nécessaires pour la table CCD du produit. Fermez la fenêtre de conception et enregistrez toutes les modifications.
Étape 9) Localisez et ouvrez maintenant le fichier STAGEDB_ASN_INVENTORY_CCD_ex.tract tâche parallèle à partir du volet du référentiel du Designer et répétez les étapes 3 à 8.
REMARQUE:
- Vous devez charger les informations de connexion pour la base de données du serveur de contrôle dans l'éditeur de scène pour obtenirSyncÉtape hPoints. Si votre serveur de contrôle n'est pas STAGEDB.
- Pour STAGEDB_ST00_AQ00_getExtracLes tâches parallèles tRange et STAGEDB_ST00_AQ00_markRangeProcessed ouvrent toutes les étapes du connecteur DB2. Utilisez ensuite la fonction de chargement pour ajouter les informations de connexion à la base de données STAGEDB.
Toutes les propriétés sont maintenant définies, les tâches peuvent donc être compilées et exécutées.
Compilation et exécution des tâches DataStage
Lorsque la tâche DataStage est prête à être compilée, le concepteur valide la conception de la tâche en examinant les entrées, les transformations, les expressions et d'autres détails.
Lorsque la compilation du travail est terminée avec succès, il est prêt à être exécuté. Nous compilerons les cinq tâches, mais exécuterons uniquement la « séquence de tâches ». En effet, cette tâche contrôle les quatre tâches parallèles.
Étape 1) Sous le dossier SQLREP. Sélectionnez chacun des cinq travaux par (Cntrl+Shift). Ensuite, faites un clic droit et choisissez l’option de compilation de tâches multiples.

Étape 2) Vous verrez cinq tâches sélectionnées dans l'assistant de compilation DataStage. Cliquez sur Suivant.

Étape 3) La compilation commence et affiche un message « Compilé avec succès » une fois terminé.

Étape 4) Démarrez maintenant DataStage et QualityStage Director. Sélectionnez Démarrer > Tous les programmes > IBM Serveur d'informations > IBM Directeur WebSphere DataStage et QualityStage.
Étape 5) Dans le volet de navigation du projet sur la gauche. Cliquez sur le dossier SQLREP. Cela amène les cinq emplois dans la table des statuts de directeur.
Étape 6) Sélectionnez le travail STAGEDB_AQ00_S00_sequence. Dans la barre de menu, cliquez sur Travail > Exécuter maintenant.

Une fois la compilation terminée, vous verrez l'état terminé.

Vérifiez maintenant si les lignes modifiées stockées dans les tables PRODUCT_CCD et INVENTORY_CCD ont été modifiées.tractraités par DataStage et insérés dans les deux fichiers de données.
Étape 7) Retournez dans le concepteur et ouvrez le fichier STAGEDB_ASN_PRODUCT_CCD_extract job. Pour ouvrir l'éditeur de scène Double-cliquez sur l'icône insert_into_a_dataset. Cliquez ensuite sur Afficher les données.
Étape 8) Acceptez les valeurs par défaut dans la fenêtre des lignes à afficher. Cliquez ensuite sur OK. Une fenêtre de navigateur de données s'ouvrira pour afficher le contenu du fichier d'ensemble de données.

Test de l'intégration entre la réplication SQL et DataStage
À l'étape précédente, nous avons compilé et exécuté le travail. Dans cette section, nous vérifierons l'intégration de la réplication SQL et de DataStage. Pour cela, nous apporterons des modifications à la table source et verrons si la même modification est mise à jour dans le DataStage.
Étape 1) Accédez au dossier sqlrepl-datastage-scripts correspondant à votre système d'exploitation.
Étape 2) Démarrez la réplication SQL en suivant les étapes :
- Exécutez startSQLCapture.bat (Windows) pour démarrer le programme Capture dans la base de données SALES.
- Exécutez startSQLApply.bat (Windows) pour démarrer le programme Apply dans la base de données STAGEDB.
Étape 3) Ouvrez maintenant le fichier updateSourceTables.sql. Pour vous connecter à la base de données SALES, remplacez et avec l'identifiant et le mot de passe de l'utilisateur.
Étape 4) Ouvrez une fenêtre de commande DB2. Changez le répertoire en sqlrepl-datastage-tutorial\scripts et exécutez issue à l'aide de la commande donnée :
db2 -tvf updateSourceTables.sql
Le script SQL effectuera diverses opérations comme Mettre à jour, Insérer et supprimer sur les deux tables (PRODUCT, INVENTORY) de la base de données Sales.
Étape 5) Sur le système sur lequel DataStage est exécuté. Ouvrez DataStage Director et exécutez la tâche STAGEDB_AQ00_S00_sequence. Cliquez sur Travail > Exécuter maintenant.

Lorsque vous exécutez le travail, les activités suivantes seront effectuées.
- Le programme Capture lit les modifications sur six lignes dans le journal de la base de données SALES et les insère dans les tables CD.
- Le programme Apply récupère les lignes de modifications des tables CD de SALES et les insère dans les tables CCD de STAGEDB.
- Les deux DataStage extracLes tâches t récupèrent les modifications des tables CCD et les écrivent dans les fichiers productdataset.ds et inventory dataset.ds.
Vous pouvez vérifier que les étapes ci-dessus ont eu lieu en examinant les ensembles de données.
Étape 6) Suivez les étapes ci-dessous,
- Démarrez le concepteur. Ouvrez le fichier STAGEDB_ASN_PRODUCT_CCD_extractravail.
- Ensuite Double-cliquez sur l'icône insert_into_a_dataset. Dans l'éditeur de scène. Cliquez sur Afficher les données.
- Acceptez les valeurs par défaut dans la fenêtre des lignes à afficher et cliquez sur OK.
L'ensemble de données contient trois nouvelles lignes. Le moyen le plus simple de vérifier que les modifications sont mises en œuvre est de faire défiler l'écran à l'extrême droite du navigateur de données. Regardez maintenant les trois dernières lignes (voir l'image ci-dessous)

Les lettres I, U et D spécifient les opérations INSERT, UPDATE et DELETE qui ont abouti à chaque nouvelle ligne.
Vous pouvez faire la même vérification pour la table Inventaire.
DataStage comparé à d'autres outils ETL populaires
Une fois le flux de bout en bout opérationnel, la question suivante est généralement de savoir comment DataStage se compare aux solutions alternatives que l'équipe possède peut-être déjà. Le tableau ci-dessous le compare à trois plateformes largement utilisées selon les critères qui déterminent le plus souvent un achat.
| Critères | IBM Étape de données | informatique Centre d'alimentation | Talend | SSIS |
|---|---|---|---|---|
| Modèle de traitement | Parallélisme de pipeline et de partition | Partitionnement basé sur les métadonnées | Création Java or Spark code | Flux de données en mémoire |
| Meilleur ajustement | Charges de travail par lots et CDC d'entreprise très importantes | Architectures héritées complexes avec une gouvernance lourde | Équipes natives du cloud et sensibles aux coûts | Microsoft SQL Server propriétés |
| Licence | Commercial, niveau premium | Commerciales | Édition open source et versions commerciales | Intégré avec SQL Server |
| Courbe d'apprentissage | Steep recherche des spécialistes ETL | Raide | Des compétences modérées en programmation sont utiles. | Modérée |
| Qualité des données | QualityStage est inclus dans la suite | Produit de qualité des données séparé | Talend Data Quality inclus | Composants additionnels |
En résumé, DataStage est choisi lorsque le débit brut, la portée sur les mainframes et la traçabilité des données à des fins d'audit priment sur le coût de la licence. Il est particulièrement adapté aux équipes travaillant principalement dans le cloud. architecture du lac de données ou en comparant extracL'ordre initial peut permettre de constater les compromis dans ETL vs ELT plus pertinent, et une liste restreinte plus large apparaît dans le récapitulatif de Outils ETL et outils d'intégration de données.