50 preguntas y respuestas de la entrevista SQL para 2026
Preguntas de la entrevista SQL para principiantes
1. ¿Qué es SGBD?
Un sistema de gestión de bases de datos (DBMS) es un programa que controla la creación, mantenimiento y uso de una base de datos. DBMS puede denominarse como un administrador de archivos que administra datos en una base de datos en lugar de guardarlos en sistemas de archivos.
👉 Descarga gratuita de PDF: Preguntas y respuestas de la entrevista SQL >>
2. ¿Qué es RDBMS?
RDBMS significa Sistema de gestión de bases de datos relacionales. RDBMS almacena los datos en una colección de tablas, que están relacionadas por campos comunes entre las columnas de la tabla. También proporciona operadores relacionales para manipular los datos almacenados en las tablas.
Ejemplo: Servidor SQL.
3. ¿Qué es SQL?
SQL significa Lenguaje de consulta estructurado y se utiliza para comunicarse con la base de datos. Este es un lenguaje estándar utilizado para realizar tareas como recuperación, actualización, inserción y eliminación de datos de una base de datos.
Estándar Comandos SQL son Seleccionar.
4. ¿Qué es una base de datos?
La base de datos no es más que una forma organizada de datos para facilitar el acceso, almacenamiento, recuperación y gestión de datos. Esto también se conoce como forma estructurada de datos a los que se puede acceder de muchas maneras.
Ejemplo: Base de datos de gestión escolar, Base de datos de gestión bancaria.
5. ¿Qué son las tablas y los campos?
Una tabla es un conjunto de datos que se organizan en un modelo con columnas y filas. Las columnas se pueden clasificar como verticales y las filas como horizontales. Una tabla tiene un número específico de columnas llamadas campos, pero puede tener cualquier número de filas que se denomina registro.
Ejemplo:.
Mesa: Empleado.
Campo: ID de emp, nombre de emp, fecha de nacimiento.
Datos: 201456, David, 11/15/1960.
6. ¿Qué es una clave primaria?
A clave principal es una combinación de campos que especifican de forma única una fila. Este es un tipo especial de clave única y tiene una restricción implícita NOT NULL. Significa que los valores de la clave principal no pueden ser NULL.
7. ¿Qué es una clave única?
Una restricción de clave única identificaba de forma única cada registro en la base de datos. Esto proporciona unicidad para la columna o conjunto de columnas.
Una restricción de clave principal tiene definida una restricción única automática. Pero no, en el caso de Unique Key.
Puede haber muchas restricciones únicas definidas por tabla, pero solo una restricción de clave principal definida por tabla.
8. ¿Qué es una clave externa?
Una clave externa es una tabla que se puede relacionar con la clave principal de otra tabla. La relación debe crearse entre dos tablas haciendo referencia a la clave externa con la clave principal de otra tabla.
9. ¿Qué es una unión?
Esta es una palabra clave utilizada para consultar datos de más tablas en función de la relación entre los campos de las tablas. Las claves juegan un papel importante cuando se utilizan JOIN.
10. ¿Cuáles son los tipos de unión y explica cada uno?
Hay varios tipos de unión que se puede utilizar para recuperar datos y depende de la relación entre tablas.
- Unir internamente.
La unión interna devuelve filas cuando hay al menos una coincidencia de filas entre las tablas.
- Únete a la derecha.
Une a la derecha las filas de retorno que son comunes entre las tablas y todas las filas de la tabla del lado derecho. Simplemente, devuelve todas las filas de la tabla del lado derecho aunque no haya coincidencias en la tabla del lado izquierdo.
- Unirse a la izquierda.
La unión izquierda devuelve filas que son comunes entre las tablas y todas las filas de la tabla del lado izquierdo. Simplemente, devuelve todas las filas de la tabla del lado izquierdo aunque no haya coincidencias en la tabla del lado derecho.
- Únase completamente.
La unión completa devuelve filas cuando hay filas coincidentes en cualquiera de las tablas. Esto significa que devuelve todas las filas de la tabla del lado izquierdo y todas las filas de la tabla del lado derecho.
Preguntas de la entrevista SQL para 3 años de experiencia
11. ¿Qué es la normalización?
La normalización es el proceso de minimizar la redundancia y la dependencia mediante la organización de campos y tablas de una base de datos. El objetivo principal de la Normalización es agregar, eliminar o modificar campos que se pueden realizar en una sola tabla.
12. ¿Qué es la desnormalización?
La desnormalización es una técnica utilizada para acceder a los datos desde formas de base de datos normales superiores a inferiores. También es el proceso de introducir redundancia en una tabla incorporando datos de las tablas relacionadas.
13. ¿Cuáles son las diferentes normalizaciones?
Normalización de la base de datos puede entenderse fácilmente con la ayuda de un estudio de caso. Las formas normales se pueden dividir en 6 formas, y se explican a continuación.
.png)
- Primera forma normal (1NF):.
Esto debería eliminar todas las columnas duplicadas de la tabla. Creación de tablas para los datos relacionados e identificación de columnas únicas.
- Segunda forma normal (2NF):.
Cumplir con todos los requisitos de la primera forma normal. Colocar los subconjuntos de datos en tablas separadas y crear relaciones entre las tablas utilizando claves primarias.
- Tercera forma normal (3NF):.
Esto debería cumplir con todos los requisitos de 2NF. Eliminar las columnas que no dependen de las restricciones de la clave principal.
- Cuarta Forma Normal (4NF):.
Si ninguna instancia de tabla de base de datos contiene dos o más datos independientes y de múltiples valores que describan la entidad relevante, entonces está en 4th Forma normal.
- Quinta Forma Normal (5NF):.
Una tabla está en quinta forma normal solo si está en 5NF y no se puede descomponer en ningún número de tablas más pequeñas sin pérdida de datos.
- Sexta Forma Normal (6NF):.
La sexta forma normal no está estandarizada, sin embargo, los expertos en bases de datos la están discutiendo desde hace algún tiempo. Con suerte, tendremos una definición clara y estandarizada para la sexta forma normal en un futuro próximo...
14. ¿Qué es una vista?
Una vista es una tabla virtual que consta de un subconjunto de datos contenidos en una tabla. Las vistas no están prácticamente presentes y se necesita menos espacio para almacenarlas. La vista puede tener datos de una o más tablas combinadas y depende de la relación.
15. ¿Qué es un índice?
Un índice es un método de optimización del rendimiento que permite recuperar registros de la tabla con mayor rapidez. Un índice crea una entrada para cada valor y permite recuperar datos con mayor rapidez.
16. ¿Cuáles son los diferentes tipos de índices?
Hay tres tipos de índices -.
- Índice único.
Esta indexación no permite que el campo tenga valores duplicados si la columna está indexada de forma única. El índice único se puede aplicar automáticamente cuando se define la clave principal.
- ClusterÍndice de edición.
Este tipo de índice reordena el orden físico de la tabla y realiza búsquedas en función de los valores clave. Cada tabla puede tener solo un índice agrupado.
- noClusterÍndice de edición.
noClusterEl índice ed no altera el orden físico de la tabla y mantiene el orden lógico de los datos. Cada tabla puede tener 999 índices no agrupados.
17. ¿Qué es un cursor?
Un cursor de base de datos es un control que permite recorrer las filas o registros de la tabla. Esto puede verse como un puntero a una fila de un conjunto de filas. El cursor es muy útil para recorrer, como recuperar, agregar y eliminar registros de bases de datos.
18. ¿Qué es una relación y qué son?
La relación de base de datos se define como la conexión entre las tablas de una base de datos. Existen varias relaciones de base de datos y son las siguientes:
- Relación Uno a Uno.
- Relación de uno a muchos.
- Relación de muchos a uno.
- Relación de autorreferencia.
19. ¿Qué es una consulta?
Una consulta de base de datos es un código escrito para recuperar la información de la base de datos. La consulta se puede diseñar de tal manera que coincida con nuestras expectativas del conjunto de resultados. Simplemente, una pregunta a la Base de Datos.
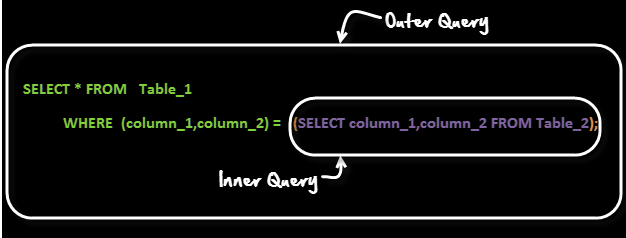
20. ¿Qué es la subconsulta?
Una subconsulta es una consulta dentro de otra consulta. La consulta externa se denomina consulta principal y la consulta interna se denomina subconsulta. La subconsulta siempre se ejecuta primero y el resultado de la subconsulta se pasa a la consulta principal.
Veamos la sintaxis de la subconsulta:
Una queja común de los clientes en la biblioteca de videos MyFlix es la poca cantidad de títulos de películas. La dirección quiere comprar películas de la categoría que tenga el menor número de títulos.
Puedes usar una consulta como
SELECT category_name FROM categories WHERE category_id =( SELECT MIN(category_id) from movies);
Preguntas de la entrevista SQL para 5 años de experiencia
21. ¿Cuáles son los tipos de subconsulta?
Hay dos tipos de subconsultas: correlacionadas y no correlacionadas.
Una subconsulta correlacionada no puede considerarse una consulta independiente, pero puede hacer referencia a la columna de una tabla incluida en la lista FROM de la consulta principal.
Una subconsulta no correlacionada se puede considerar como una consulta independiente y el resultado de la subconsulta se sustituye en la consulta principal.
22. ¿Qué es un procedimiento almacenado?
El procedimiento almacenado es una función que consta de muchas declaraciones SQL para acceder al sistema de base de datos. Varias declaraciones SQL se consolidan en un procedimiento almacenado y se ejecutan cuando y donde sea necesario.
23. ¿Qué es un disparador?
Un disparador de base de datos es un código o programas que se ejecutan automáticamente en respuesta a algún evento en una tabla o vista en una base de datos. Principalmente, el disparador ayuda a mantener la integridad de la base de datos.
Ejemplo: cuando se agrega un nuevo estudiante a la base de datos de estudiantes, se deben crear nuevos registros en las tablas relacionadas, como las tablas de examen, puntuación y asistencia.
24. ¿Cuál es la diferencia entre los comandos ELIMINAR y TRUNCAR?
El comando DELETE se usa para eliminar filas de la tabla y la cláusula WHERE se puede usar para un conjunto condicional de parámetros. La confirmación y la reversión se pueden realizar después de la declaración de eliminación.
TRUNCATE elimina todas las filas de la tabla. La operación de truncamiento no se puede revertir.
25. ¿Qué son las variables locales y globales y sus diferencias?
Las variables locales son las variables que se pueden usar o existen dentro de la función. Las otras funciones no las conocen y esas variables no se pueden hacer referencia ni utilizar. Se pueden crear variables cada vez que se llama a esa función.
Las variables globales son las variables que se pueden utilizar o existen en todo el programa. La misma variable declarada en global no se puede utilizar en funciones. Las variables globales no se pueden crear cada vez que se llama a esa función.
26. ¿Qué es una restricción?
La restricción se puede utilizar para especificar el límite en el tipo de datos de la tabla. La restricción se puede especificar al crear o modificar la declaración de la tabla. Ejemplos de restricciones son.
- NO NULO.
- CHEQUE.
- DEFECTO.
- ÚNICA.
- CLAVE PRIMARIA.
- CLAVE EXTERNA.
27. ¿Qué son los datos? Integrity?
Datos Integrity Define la precisión y la coherencia de los datos almacenados en una base de datos. También puede definir restricciones de integridad para aplicar reglas comerciales a los datos cuando se ingresan en la aplicación o la base de datos.
28. ¿Qué es el incremento automático?
La palabra clave de incremento automático permite al usuario crear un número único que se generará cuando se inserte un nuevo registro en la tabla. La palabra clave AUTO INCREMENT se puede utilizar en Oracle y la palabra clave IDENTITY se puede utilizar en SQL SERVER.
En su mayoría, esta palabra clave se puede utilizar siempre que se utilice PRIMARY KEY.
29. Cuál es la diferencia entre Cluster y NoCluster ¿Índice?
ClusterEl índice ed se utiliza para recuperar fácilmente los datos de la base de datos modificando la forma en que se almacenan los registros. La base de datos ordena las filas por la columna que se configura como índice agrupado.
Un índice no agrupado no modifica la forma en que se almacenó, sino que crea un objeto completamente independiente dentro de la tabla. Vuelve a apuntar a las filas de la tabla original después de la búsqueda.
30. ¿Qué es el almacén de datos?
Datawarehouse es un depósito central de datos de múltiples fuentes de información. Esos datos se consolidan, transforman y se ponen a disposición para la extracción y el procesamiento en línea. Los datos del almacén tienen un subconjunto de datos llamado Data Marts.
31. ¿Qué es la autounión?
La autounión está configurada para que se utilice como consulta para compararse consigo misma. Esto se utiliza para comparar valores en una columna con otros valores en la misma columna en la misma tabla. ALIAS ES se puede utilizar para la misma comparación de tablas.
32. ¿Qué es la unión cruzada?
La unión cruzada se define como producto cartesiano donde el número de filas de la primera tabla se multiplica por el número de filas de la segunda tabla. Si se supone que se utiliza la cláusula WHERE en la unión cruzada, la consulta funcionará como una UNIÓN INTERNA.
33. ¿Qué son las funciones definidas por el usuario?
Las funciones definidas por el usuario son las funciones escritas para usar esa lógica cuando sea necesario. No es necesario escribir la misma lógica varias veces. En cambio, la función se puede llamar o ejecutar cuando sea necesario.
34. ¿Cuáles son todos los tipos de funciones definidas por el usuario?
Hay tres tipos de funciones definidas por el usuario.
- Funciones escalares.
- Funciones con valores de tabla en línea.
- Funciones valoradas en múltiples declaraciones.
Unidad de retorno escalar, variante que define la cláusula de retorno. Otros dos tipos devuelven la tabla como devolución.
35. ¿Qué es el cotejo?
La intercalación se define como un conjunto de reglas que determinan cómo se pueden ordenar y comparar los datos de los caracteres. Esto se puede utilizar para comparar caracteres A y de otros idiomas y también depende del ancho de los caracteres.
El valor ASCII se puede utilizar para comparar estos datos de caracteres.
36. ¿Cuáles son los diferentes tipos de sensibilidad de intercalación?
A continuación se presentan diferentes tipos de sensibilidad de intercalación:
- Sensibilidad a mayúsculas y minúsculas: A y a y B y b.
- Sensibilidad al acento.
- Sensibilidad Kana: caracteres kana japoneses.
- Sensibilidad de ancho: caracteres de un solo byte y caracteres de dos bytes.
37. ¿Ventajas y desventajas del procedimiento almacenado?
El procedimiento almacenado se puede utilizar como programación modular: significa crear una vez, almacenar y llamar varias veces cuando sea necesario. Esto admite una ejecución más rápida en lugar de ejecutar múltiples consultas. Esto reduce el tráfico de la red y proporciona una mejor seguridad a los datos.
La desventaja es que solo se puede ejecutar en la base de datos y utiliza más memoria en el servidor de la base de datos.
38. ¿Qué es el procesamiento de transacciones en línea (OLTP)?
El procesamiento de transacciones en línea (OLTP) gestiona aplicaciones basadas en transacciones que se pueden utilizar para la entrada, recuperación y procesamiento de datos. OLTP hace que la gestión de datos sea simple y eficiente. A diferencia de los sistemas OLAP, el objetivo de los sistemas OLTP es atender transacciones en tiempo real.
Ejemplo: transacciones bancarias diarias.
39. ¿Qué es la CLÁUSULA?
La cláusula SQL se define para limitar el conjunto de resultados proporcionando una condición a la consulta. Normalmente, esto filtra algunas filas de todo el conjunto de registros.
Ejemplo: consulta que tiene la condición WHERE
Consulta que tiene condición HAVING.
40. ¿Qué es el procedimiento almacenado recursivo?
Un procedimiento almacenado que se llama a sí mismo hasta que alcanza alguna condición límite. Esta función o procedimiento recursivo ayuda a los programadores a utilizar el mismo conjunto de código tantas veces como desee.
Preguntas de la entrevista SQL para más de 10 años de experiencia
41. ¿Qué son los comandos Unión, menos e Interactuar?
El operador UNION se utiliza para combinar los resultados de dos tablas y elimina filas duplicadas de las tablas.
El operador MINUS se utiliza para devolver filas de la primera consulta, pero no de la segunda. Los registros coincidentes de la primera y la segunda consulta y otras filas de la primera consulta se mostrarán como un conjunto de resultados.
El operador INTERSECT se utiliza para devolver filas devueltas por ambas consultas.
42. ¿Qué es un comando ALIAS?
El nombre ALIAS se puede dar a una tabla o columna. Este nombre de alias puede ser referido en Dónde cláusula para identificar la tabla o columna.
Ejemplo-.
Select st.StudentID, Ex.Result from student st, Exam as Ex where st.studentID = Ex. StudentID
Aquí, st se refiere al nombre de alias de la tabla de estudiantes y Ex se refiere al nombre de alias de la tabla de exámenes.
43. ¿Cuál es la diferencia entre las declaraciones TRUNCATE y DROP?
El comando TRUNCATE elimina todas las filas de la tabla y no se puede revertir. El comando DROP elimina una tabla de la base de datos y la operación no se puede revertir.
44. ¿Qué son las funciones agregadas y escalares?
Las funciones agregadas se utilizan para evaluar cálculos matemáticos y devolver valores únicos. Esto se puede calcular a partir de las columnas de una tabla. Las funciones escalares devuelven un valor único basado en el valor de entrada.
Ejemplo -.
Agregado – max(), recuento – Calculado con respecto a numérico.
Escalar – UCASE(), NOW() – Calculado con respecto a cadenas.
45. ¿Cómo se puede crear una tabla vacía a partir de una tabla existente?
El ejemplo será -.
Select * into studentcopy from student where 1=2
Aquí, estamos copiando la tabla de estudiantes a otra tabla con la misma estructura sin copiar filas.
46. ¿Cómo recuperar registros comunes de dos tablas?
El conjunto de resultados de registros comunes se puede lograr mediante -.
Select studentID from student INTERSECT Select StudentID from Exam
47. ¿Cómo recuperar registros alternativos de una tabla?
Se pueden obtener registros para números de fila pares e impares.
Para mostrar números pares-.
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=0
Para mostrar números impares-.
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=1
from (Seleccione rowno, StudentId de estudiante) donde mod(rowno,2)=1.[/sql]
48. ¿Cómo seleccionar registros únicos de una tabla?
Seleccione registros únicos de una tabla utilizando la palabra clave DISTINCT.
Select DISTINCT StudentID, StudentName from Student.
49. ¿Cuál es el comando utilizado para recuperar los primeros 5 caracteres de la cadena?
Hay muchas formas de recuperar los primeros 5 caracteres de la cadena -.
Select SUBSTRING(StudentName,1,5) as studentname from student
Select LEFT(Studentname,5) as studentname from student
50. ¿Qué operador se utiliza en la consulta para la coincidencia de patrones?
El operador LIKE se utiliza para la coincidencia de patrones y se puede utilizar como -.
- %: coincide con cero o más caracteres.
- _(Subrayado): coincide exactamente con un carácter.
Ejemplo -.
Select * from Student where studentname like 'a%'
Select * from Student where studentname like 'ami_'
Estas preguntas de la entrevista también te ayudarán en tu viva(orals)