Multipel lineær regression i R: Simpelt og trinvis med eksempler
⚡ Smart opsummering
Simpel og multipel lineær regression i R modellerer et kontinuert resultat som en vægtet sum af prædiktorer tilpasset ved hjælp af ordinære mindste kvadraters metode. Denne gennemgang dækker lm(), koefficientaflæsning, faktorprædiktorer, residualdiagnostik, prædiktion og automatisk variabelvalg.

Hvor lineær regression passer ind i maskinlæring
Lineær regression er en af de ældste overvågede machine learning algoritmer, og det er stadig den første model, de fleste analytikere griber efter. En af de tidligste maskinlæringsapplikationer var spamfilter.
Andre almindelige anvendelser af maskinlæring inkluderer:
- Identifikation af uønskede spam-beskeder i e-mail
- Segmentering af kundeadfærd til målrettet annoncering
- Reduktion af svigagtige kreditkorttransaktioner
- Optimering af energiforbrug i boliger og kontorbygninger
- Ansigtsgenkendelse
Overvåget læring
In Overvåget læring, indeholder de træningsdata, du sender til algoritmen, en etiket.
Klassifikation er sandsynligvis den mest anvendte superviserede læringsteknik. En af de første klassificeringsopgaver, som forskere tog fat på, var spamfilteret. Formålet med læringen er at forudsige, om en e-mail klassificeres som spam eller skinke (god e-mail). Maskinen kan efter træningstrinnet registrere e-mailens klasse.
regressioner bruges almindeligvis inden for maskinlæring til at forudsige kontinuerlig værdi. En regressionsopgave kan forudsige værdien af en afhængig variabel baseret på et sæt af uafhængige variabler (også kaldet prædiktorer eller regressorer). For eksempel kan lineære regressioner forudsige en aktiekurs, vejrudsigt, salg og så videre.
Nogle grundlæggende overvågede læringsalgoritmer er:
- Lineær regression
- Logistisk regression
- Nærmeste naboer
- Support Vector Machine (SVM)
- Beslutningstræer og Random Forest
- Neurale netværk
Uovervåget læring
In Uovervåget læring, er træningsdataene umærkede. Systemet forsøger at lære uden reference. Nedenfor er en liste over uovervågede læringsalgoritmer.
- K-middel
- Hierarkisk Cluster Analyse
- Forventningsmaksimering
- Visualisering og dimensionsreduktion
- Hovedkomponentanalyse
- Kernel PCA
- Lokalt-lineær indlejring
Med den kontekst på plads, bygger resten af denne vejledning regressionsmodeller i R trin for trin.
Simpel lineær regression i R
Lineær regression besvarer et simpelt spørgsmål: Kan man måle en præcis sammenhæng mellem én målvariabel og et sæt prædiktorer?
Den enkleste probabilistiske model er den lineære model:
![]()
hvor
- y = Afhængig variabel
- x = Uafhængig variabel
-
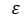 = tilfældig fejlkomponent
= tilfældig fejlkomponent -
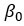 = opsnappe
= opsnappe -
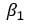 = Koefficient af x
= Koefficient af x
Overvej følgende plot:
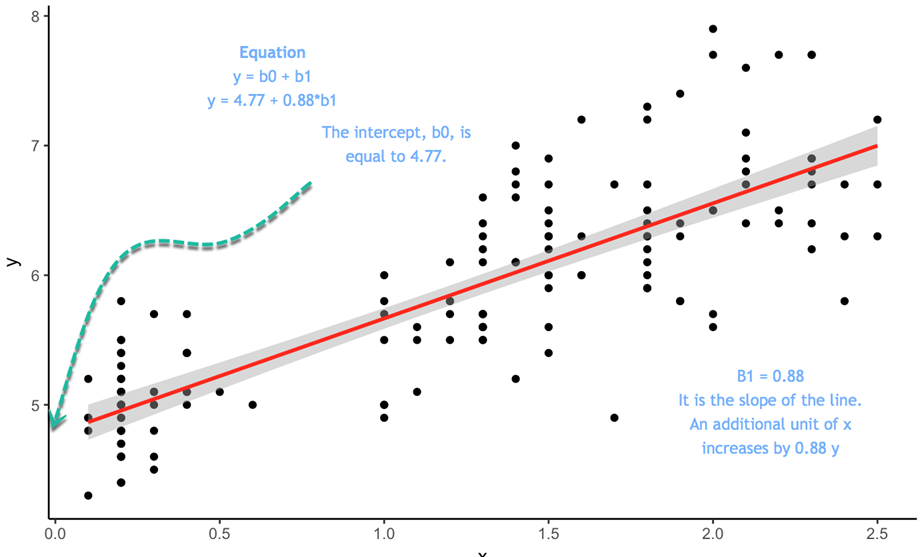
Ligningen er ![]() I denne ligning er skæringspunktet 4.77, så når x er lig med 0, er den tilpassede værdi af y 4.77. Hældningen fortæller dig, i hvilken andel y varierer, når x varierer.
I denne ligning er skæringspunktet 4.77, så når x er lig med 0, er den tilpassede værdi af y 4.77. Hældningen fortæller dig, i hvilken andel y varierer, når x varierer.
At estimere de optimale værdier af ![]() og
og ![]() , bruger du en metode kaldet Almindelige mindste kvadrater (OLS). Denne metode forsøger at finde de parametre, der minimerer summen af de kvadrerede fejl, det vil sige den lodrette afstand mellem de forudsagte y-værdier og de faktiske y-værdier. Forskellen er kendt som fejlterm.
, bruger du en metode kaldet Almindelige mindste kvadrater (OLS). Denne metode forsøger at finde de parametre, der minimerer summen af de kvadrerede fejl, det vil sige den lodrette afstand mellem de forudsagte y-værdier og de faktiske y-værdier. Forskellen er kendt som fejlterm.
Før du estimerer modellen, kan du afgøre, om en lineær sammenhæng mellem y og x er plausibel ved at plotte et spredningsdiagram.
Scatterplot
Vi vil bruge et meget simpelt datasæt til at forklare begrebet simpel lineær regression. Vi importerer de gennemsnitlige højder og vægte for amerikanske kvinder. Datasættet indeholder 15 observationer. Du vil måle, om højder er positivt korreleret med vægte.
library(ggplot2) path <- 'https://raw.githubusercontent.com/guru99-edu/R-Programming/master/women.csv' df <-read.csv(path) ggplot(df,aes(x=height, y = weight))+ geom_point()
Output:

Scatterplottet antyder en generel tendens til, at vægten stiger, når højden stiger. I næste trin måler du, hvor meget vægten stiger for hver yderligere højdeenhed.
Mindste kvadraters skøn
I en simpel OLS-regression kan beregningen af ![]() og
og ![]() er ligetil. Denne vejledning udleder ikke formlerne, den angiver dem kun.
er ligetil. Denne vejledning udleder ikke formlerne, den angiver dem kun.
Du vil anslå: ![]()
Målet med OLS-regressionen er at minimere følgende ligning:
![]()
hvor
![]() er den faktiske værdi og
er den faktiske værdi og ![]() er den forudsagte værdi.
er den forudsagte værdi.
Løsningen til ![]() is
is ![]()
Bemærk, at ![]() betyder gennemsnitsværdien af x
betyder gennemsnitsværdien af x
Løsningen til ![]() is
is ![]()
I R kan du bruge funktionerne cov() og var() til at estimere ![]() og du kan bruge funktionen mean() til at estimere
og du kan bruge funktionen mean() til at estimere ![]()
beta <- cov(df$height, df$weight) / var (df$height) beta
Output:
##[1] 3.45
alpha <- mean(df$weight) - beta * mean(df$height) alpha
Output:
## [1] -87.51667
Beta-koefficienten indebærer, at for hver ekstra tomme højde stiger den gennemsnitlige vægt med 3.45 pund.
Det er lærerigt, men upraktisk at estimere en lineær ligning manuelt. R stiller lm()-funktionen til rådighed til at gøre det for dig, og du vil bruge den fra næste afsnit og fremefter. I virkelige projekter vil du næsten aldrig tilpasse en model med én prædiktor; regressionsopgaver involverer normalt mange estimatorer på én gang.
Multipel lineær regression i R
Praktiske anvendelser af regressionsanalyse bruger modeller, der er mere komplekse end den simple lineære model. Den probabilistiske model, der inkluderer mere end én uafhængig variabel, kaldes flere regressionsmodeller. Den generelle form for denne model er:
![]()
I matrixnotation kan du omskrive modellen:
Den afhængige variabel y er nu en funktion af k uafhængige variable. Værdien af koefficienten ![]() bestemmer bidraget fra den uafhængige variabel
bestemmer bidraget fra den uafhængige variabel ![]() og
og ![]() .
.
Vi introducerer kort den antagelse, vi lavede om den tilfældige fejl ![]() af OLS:
af OLS:
- Gennemsnit lig med 0
- Varians lig med

- Normal fordeling
- Tilfældige fejl er uafhængige (i en sandsynlig forstand)
Du skal løse for ![]() , vektoren af regressionskoefficienter, der minimerer summen af de kvadrerede fejl mellem de forudsagte og faktiske y-værdier.
, vektoren af regressionskoefficienter, der minimerer summen af de kvadrerede fejl mellem de forudsagte og faktiske y-værdier.
Løsningen i lukket form er:
![]()
med:
- angiver omsætte af matrixen X
 angiver inverterbar matrix
angiver inverterbar matrix
Eksemplerne nedenfor bruger det indbyggede mtcars-datasæt. Målet er at forudsige miles per gallon (mpg) ud fra et sæt funktioner.
Kontinuerlige variable i R
Indtil videre vil du kun bruge de kontinuerlige variable og lægge kategoriske træk til side. Variablen am er en binær variabel, der tager værdien 1, hvis gearkassen er manuel, og 0 for automatiske biler; vs er også en binær variabel.
library(dplyr) df <- mtcars %>% select(-c(am, vs, cyl, gear, carb)) glimpse(df)
Output:
## Observations: 32 ## Variables: 6 ## $ mpg <dbl> 21.0, 21.0, 22.8, 21.4, 18.7, 18.1, 14.3, 24.4, 22.8, 19.... ## $ disp <dbl> 160.0, 160.0, 108.0, 258.0, 360.0, 225.0, 360.0, 146.7, 1... ## $ hp <dbl> 110, 110, 93, 110, 175, 105, 245, 62, 95, 123, 123, 180, ... ## $ drat <dbl> 3.90, 3.90, 3.85, 3.08, 3.15, 2.76, 3.21, 3.69, 3.92, 3.9... ## $ wt <dbl> 2.620, 2.875, 2.320, 3.215, 3.440, 3.460, 3.570, 3.190, 3... ## $ qsec <dbl> 16.46, 17.02, 18.61, 19.44, 17.02, 20.22, 15.84, 20.00, 2...
Du kan bruge lm()-funktionen til at beregne parametrene. Den grundlæggende syntaks for denne funktion er:
lm(formula, data, subset)
Arguments:
-formula: The equation you want to estimate
-data: The dataset used
-subset: Estimate the model on a subset of the dataset
Husk en ligning er af følgende form
![]()
i R
- Symbolet = erstattes af ~
- Hvert x erstattes af variabelnavnet
- Hvis du vil droppe konstanten, skal du tilføje -1 i slutningen af formlen
Eksempel:
Du ønsker at estimere vægten af individer baseret på deres højde og indtjening. Ligningen er
![]()
Ligningen i R er skrevet som følger:
y ~ X1+ X2+…+Xn # Med skæring
Så for vores eksempel:
- Vej ~ højde + omsætning
Dit mål er at estimere mile per gallon baseret på et sæt variabler. Ligningen der skal estimeres er:
![]()
Du vil estimere din første lineære regression og gemme resultatet i tilpasningsobjektet.
model <- mpg ~ disp + hp + drat + wt + qsec
fit <- lm(model, df)
fit
Code Forklaring
- model <- mpg ~ disp + hk + drat + wt + qsec: Gem modellen for at estimere
- lm(model, df): Estimer modellen med datarammen df
## ## Call: ## lm(formula = model, data = df) ## ## Coefficients: ## (Intercept) disp hp drat wt ## 16.53357 0.00872 -0.02060 2.01577 -4.38546 ## qsec ## 0.64015
Outputtet giver ikke nok information om kvaliteten af pasformen. Du kan få adgang til flere detaljer såsom betydningen af koefficienterne, graden af frihed og formen af residualerne med summary()-funktionen.
summary(fit)
Output:
## return the p-value and coefficient ## ## Call: ## lm(formula = model, data = df) ## ## Residuals: ## Min 1Q Median 3Q Max ## -3.5404 -1.6701 -0.4264 1.1320 5.4996 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 16.53357 10.96423 1.508 0.14362 ## disp 0.00872 0.01119 0.779 0.44281 ## hp -0.02060 0.01528 -1.348 0.18936 ## drat 2.01578 1.30946 1.539 0.13579 ## wt -4.38546 1.24343 -3.527 0.00158 ** ## qsec 0.64015 0.45934 1.394 0.17523 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 2.558 on 26 degrees of freedom ## Multiple R-squared: 0.8489, Adjusted R-squared: 0.8199 ## F-statistic: 29.22 on 5 and 26 DF, p-value: 6.892e-10
Konklusioner fra ovenstående tabeloutput
- Tabellen viser en stærk negativ sammenhæng mellem wt og mpg, og en positiv koefficient for drat.
- Kun variablen wt har en statistisk indvirkning på mpg. Husk, at for at teste en hypotese i statistik, bruger vi:
- H0: Ingen statistisk effekt
- H1: Prædiktoren har en meningsfuld indvirkning på y
- Hvis p-værdien er lavere end 0.05, indikerer det, at variablen er statistisk signifikant
- Justeret R-kvadrat: den andel af variansen af y, der forklares af modellen, korrigeret for antallet af prædiktorer. Her er den 0.8199, så modellen forklarer omkring 82 procent af variansen af mpg. R-kvadrat ligger altid mellem 0 og 1, og højere jo bedre.
Du kan køre ANOVA test for at estimere effekten af hver funktion på varianserne med funktionen anova().
anova(fit)
Output:
## Analysis of Variance Table ## ## Response: mpg ## Df Sum Sq Mean Sq F value Pr(>F) ## disp 1 808.89 808.89 123.6185 2.23e-11 *** ## hp 1 33.67 33.67 5.1449 0.031854 * ## drat 1 30.15 30.15 4.6073 0.041340 * ## wt 1 70.51 70.51 10.7754 0.002933 ** ## qsec 1 12.71 12.71 1.9422 0.175233 ## Residuals 26 170.13 6.54 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
En mere konventionel måde at estimere modellens ydeevne på er at vise restproduktet mod forskellige mål.
Du kan bruge plot()-funktionen til at vise fire grafer:
– Residualer vs. tilpassede værdier
– Normal QQ-plot: Teoretisk kvartil vs standardiserede residualer
– Skala-placering: Tilpassede værdier vs. kvadratrødder af de standardiserede residualer
– Residualer vs Gearing: Gearing vs Standardiserede residualer
Du tilføjer koden par(mfrow = c(2, 2)) før plot(fit). Hvis du ikke tilføjer denne kodelinje, beder R dig om at trykke på enter-kommandoen for at vise den næste graf.
par(mfrow = c(2, 2))
Code Forklaring
- (mfrow=c(2,2)): returner et vindue med de fire grafer side om side.
- De første 2 tilføjer antallet af rækker
- Den anden 2 tilføjer antallet af kolonner.
- Hvis du skriver (mfrow=c(3,2)): vil du oprette et 3 rækker 2 kolonner vindue
plot(fit)
Output:

Formlen lm() returnerer en liste, der indeholder en masse nyttige oplysninger. Du kan tilgå dem med det fit-objekt, du har oprettet, efterfulgt af $-tegnet og de oplysninger, du vil have vist.tract.
– koefficienter: `fit$koefficienter`
– residualer: `fit$residuals`
– tilpasset værdi: `fit$fitted.values`
Faktorer regression i R
I den sidste modelestimering regresserer du kun mpg på kontinuerte variabler. Det er ligetil at tilføje faktorvariable til modellen. Du tilføjer variablen am til din model. Det er vigtigt at være sikker på, at variablen er et faktorniveau og ikke kontinuert.
df <- mtcars %>%
mutate(cyl = factor(cyl),
vs = factor(vs),
am = factor(am),
gear = factor(gear),
carb = factor(carb))
model <- mpg ~ .
summary(lm(model, df))
Output:
## ## Call: ## lm(formula = model, data = df) ## ## Residuals: ## Min 1Q Median 3Q Max ## -3.5087 -1.3584 -0.0948 0.7745 4.6251 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 23.87913 20.06582 1.190 0.2525 ## cyl6 -2.64870 3.04089 -0.871 0.3975 ## cyl8 -0.33616 7.15954 -0.047 0.9632 ## disp 0.03555 0.03190 1.114 0.2827 ## hp -0.07051 0.03943 -1.788 0.0939 . ## drat 1.18283 2.48348 0.476 0.6407 ## wt -4.52978 2.53875 -1.784 0.0946 . ## qsec 0.36784 0.93540 0.393 0.6997 ## vs1 1.93085 2.87126 0.672 0.5115 ## am1 1.21212 3.21355 0.377 0.7113 ## gear4 1.11435 3.79952 0.293 0.7733 ## gear5 2.52840 3.73636 0.677 0.5089 ## carb2 -0.97935 2.31797 -0.423 0.6787 ## carb3 2.99964 4.29355 0.699 0.4955 ## carb4 1.09142 4.44962 0.245 0.8096 ## carb6 4.47757 6.38406 0.701 0.4938 ## carb8 7.25041 8.36057 0.867 0.3995 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 2.833 on 15 degrees of freedom ## Multiple R-squared: 0.8931, Adjusted R-squared: 0.779 ## F-statistic: 7.83 on 16 and 15 DF, p-value: 0.000124
R bruger det første faktorniveau som en basisgruppe. Du skal sammenligne koefficienterne for den anden gruppe med basisgruppen.
Antagelser om lineær regression i R
Almindelige mindste kvadraters metode producerer kun troværdige koefficienter og p-værdier, når fem betingelser er opfyldt. De fire diagnostiske plots, der produceres af plot(fit), eksisterer netop for at kontrollere dem.
- Linearitet: Forholdet mellem hver prædiktor og y er lineært. Tjek Resterende vs. Tilpassede plot; en synlig kurve betyder, at du har brug for en transformation eller et polynomielt led.
- Uafhængighed: Fejlordene er ukorrelerede. Tidsordnede data overtræder ofte dette, hvilket du kan teste med durbinWatsonTest() fra bilpakken.
- Homoskedasticitet: Fejlvariansen er konstant på tværs af tilpassede værdier. En tragtform i Skalaplacering Plottet signalerer en overtrædelse.
- Normalitet af residualer: Fejlene følger en normalfordeling. Punkterne skal sidde på diagonalen af Normal QQ grund.
- Ingen multikollinearitet: Prædiktorer er ikke næsten dubletter af hinanden. En variansinflationsfaktor over 5 er den sædvanlige advarselslinje.
library(car) vif(fit) # variance inflation factors shapiro.test(residuals(fit)) # normality of residuals
Overtrædelser ugyldiggør ikke altid en model, men de ændrer, hvor sikker du kan være på p-værdierne, så tjek dem, før du rapporterer en koefficient.
Sådan laver du forudsigelser med en lineær regressionsmodel i R
At tilpasse en model er kun halvdelen af arbejdet. Funktionen predict() anvender de tilpassede koefficienter på nye observationer.
predict(object, newdata, interval = "none", level = 0.95) arguments: -object: The model returned by lm() -newdata: A data frame whose columns match the predictors used in the formula -interval: "none", "confidence" for the mean response, or "prediction" for a single new case -level: The confidence level, 0.95 by default
Følg disse tre trin.
- Opbyg en dataramme for nye sager. Kolonnenavnene skal stemme nøjagtigt overens med prædiktornavnene i formlen, og faktorniveauerne skal stemme overens med træningsdataene.
- Kald predict(). Send det tilpassede objekt og den nye dataframe.
- Tilføj et interval. Vælg "konfidens", når du vil have usikkerheden omkring det gennemsnitlige svar, og "forudsigelse", når du vil have rækkevidden for én enkelt bil.
new_cars <- data.frame(wt = c(2.5, 3.2), hp = c(110, 175)) fit_final <- lm(mpg ~ wt + hp, data = mtcars) predict(fit_final, newdata = new_cars) predict(fit_final, newdata = new_cars, interval = "prediction")
Læsning af resultatet. En bil på 2.5 kg og 110 hestekræfter forventes at have et forbrug på cirka 24.1 mpg. Forudsigelsesintervallet er altid bredere end konfidensintervallet, fordi det indeholder usikkerheden fra en enkelt observation oveni usikkerheden fra den tilpassede linje.
To regler holder forudsigelser ærlige. Ekstrapoler aldrig ud over træningsprediktorernes område, da der ikke er noget bevis for den rette linje. Og evaluer altid på data, som modellen ikke har set, ellers er den rapporterede fejl optimistisk.
Lineær regression vs. logistisk regression i R
Analytikere bruger ofte lm(), når resultatet ikke er kontinuerligt. Tabellen nedenfor viser, hvor grænsen går.
| Kriterier | Lineær regression | Logistisk regression |
|---|---|---|
| Responsvariabel | Kontinuerlig | Binær eller kategorisk |
| Forudsagt output | Ethvert reelt tal | En sandsynlighed mellem 0 og 1 |
| estimering | Almindelige mindste kvadraters | Maksimal sandsynlighed |
| Tilpasningsmål | R-kvadrat, RMSE | AIC, afvigelse, nøjagtighed |
| R funktion | lm(formel, data) | glm(formel, data, familie = "binomial") |
Hvis resultatet er et ja eller nej, gå videre til generaliseret lineær model i stedet for at tvinge en lige linje gennem nuller og ettaller.
Trinvis lineær regression i R
Den sidste del af denne tutorial omhandler trinvis regression algoritme. Formålet med denne algoritme er at tilføje og fjerne potentielle kandidater i modellerne og beholde dem, der har en væsentlig indflydelse på den afhængige variabel. Denne algoritme er meningsfuld, når datasættet indeholder en stor liste af prædiktorer. Du behøver ikke manuelt at tilføje og fjerne de uafhængige variabler. Den trinvise regression er bygget til at vælge de bedste kandidater til at passe til modellen.
Lad os se, hvordan det fungerer i praksis. Du bruger mtcars-datasættet med de kontinuerlige variabler udelukkende til pædagogisk illustration. Før du begynder analysen, er det god praksis at inspicere sammenhængene i dataene med en korrelationsmatrix. GGally-biblioteket er en udvidelse af ggplot2.
Biblioteket indeholder forskellige funktioner til at vise opsummerende statistik såsom korrelation og fordeling af alle variablerne i en matrix. Vi vil bruge ggscatmat-funktionen, men du kan henvise til tegnefilm for mere information om GGally-biblioteket.
Den grundlæggende syntaks for ggscatmat() er:
ggscatmat(df, columns = 1:ncol(df), corMethod = "pearson") arguments: -df: A matrix of continuous variables -columns: Pick up the columns to use in the function. By default, all columns are used -corMethod: Define the function to compute the correlation between variable. By default, the algorithm uses the Pearson formula
Du viser korrelationen for alle dine variabler og beslutter, hvilke der er de bedste kandidater til det første trin i den trinvise regression. Der er nogle stærke korrelationer mellem dine variabler og den afhængige variabel, mpg.
library(GGally) df <- mtcars %>% select(-c(am, vs, cyl, gear, carb)) ggscatmat(df, columns = 1: ncol(df))
Output:

Trinvis regression Trin for trin eksempel
Variabelvalg er en vigtig del af tilpasningen af en model, og trinvis regression udfører denne søgning automatisk. For at estimere, hvor mange mulige valg der er i datasættet, beregner du ![]() med k er antallet af prædiktorer. Mængden af muligheder vokser sig større med antallet af uafhængige variable. Derfor skal du have en automatisk søgning.
med k er antallet af prædiktorer. Mængden af muligheder vokser sig større med antallet af uafhængige variable. Derfor skal du have en automatisk søgning.
Du skal installere olsrr-pakken fra CRAN. Pakken er endnu ikke tilgængelig i Anaconda. Derfor installerer du det direkte fra kommandolinjen:
install.packages("olsrr")
Du kan plotte alle undersæt af muligheder med tilpasningskriterierne (dvs. R-kvadrat, justeret R-kvadrat, Bayesianske kriterier). Modellen med de laveste AIC-kriterier vil være den endelige model.
library(olsrr) model <- mpg~. fit <- lm(model, df) test <- ols_all_subset(fit) plot(test)
Code Forklaring
- mpg ~.: Konstruer modellen til at estimere
- lm(model, df): Kør OLS-modellen
- ols_all_subset(tilpasning): Konstruer graferne med de relevante statistiske oplysninger
- plot (test): Tegn graferne
Output:

Lineære regressionsmodeller bruger t-test at estimere den statistiske effekt af en uafhængig variabel på den afhængige variabel. Forskere sætter almindeligvis den maksimale tærskelværdi til 10 procent, og lavere p-værdier indikerer en stærkere statistisk sammenhæng. Trinvis regression er bygget op omkring denne test for at tilføje og fjerne kandidatprædiktorer. Algoritmen fungerer som følger:

- Trin 1: Regresser hver prædiktor på y separat. Nemlig regress x_1 på y, x_2 på y til x_n. Opbevar p-værdi og hold regressoren med en p-værdi lavere end en defineret tærskel (0.1 som standard). Prædiktorerne med en signifikans lavere end tærsklen vil blive tilføjet den endelige model. Hvis ingen variabel har en p-værdi lavere end indtastningstærsklen, stopper algoritmen, og du har din endelige model med kun en konstant.
- Trin 2: Brug prædiktoren med den laveste p-værdi og tilføjer separat én variabel. Du regresserer en konstant, den bedste prædiktor for trin et og en tredje variabel. Du tilføjer til den trinvise model de nye prædiktorer med en værdi lavere end indtastningstærsklen. Hvis ingen variabel har en p-værdi lavere end 0.1, så stopper algoritmen, og du har din endelige model med kun én prædiktor. Du regresserer den trinvise model for at kontrollere betydningen af trin 1 bedste prædiktorer. Hvis den er højere end udtagningstærsklen, beholder du den i den trinvise model. Ellers udelukker du det.
- Trin 3: Du replikerer trin 2 på den nye bedste trinvise model. Algoritmen tilføjer prædiktorer til den trinvise model baseret på de indtastede værdier og udelukker prædiktor fra den trinvise model, hvis den ikke opfylder ekskluderingstærsklen.
- Algoritmen fortsætter, indtil ingen variabel kan tilføjes eller udelukkes.
Du kan udføre algoritmen med funktionen ols_stepwise() fra olsrr-pakken.
ols_stepwise(fit, pent = 0.1, prem = 0.3, details = FALSE) arguments: -fit: Model to fit. Need to use `lm()`before to run `ols_stepwise() -pent: Threshold of the p-value used to enter a variable into the stepwise model. By default, 0.1 -prem: Threshold of the p-value used to exclude a variable into the stepwise model. By default, 0.3 -details: Print the details of each step
⚠️ Pakkebemærkning: Nyere versioner af olsrr har omdøbt disse funktioner. Brug ols_step_all_possible() i stedet for ols_all_subset() og ols_step_both_p() i stedet for ols_stepwise(). Argumenterne og outputtet forbliver uændrede.
Før det viser vi dig trinene i algoritmen. Nedenfor er en tabel med de afhængige og uafhængige variable:
| Afhængig variabel | Uafhængige variabler |
|---|---|
| mpg | disp |
| hp | |
| rotte | |
| wt | |
| qsec |
Starten
Til at begynde med starter algoritmen med at køre modellen på hver uafhængig variabel separat. Tabellen viser p-værdien for hver model.
## [[1]] ## (Intercept) disp ## 3.576586e-21 9.380327e-10 ## ## [[2]] ## (Intercept) hp ## 6.642736e-18 1.787835e-07 ## ## [[3]] ## (Intercept) drat ## 0.1796390847 0.0000177624 ## ## [[4]] ## (Intercept) wt ## 8.241799e-19 1.293959e-10 ## ## [[5] ## (Intercept) qsec ## 0.61385436 0.01708199
For at komme ind i modellen beholder algoritmen variablen med den laveste p-værdi. Fra ovenstående output er det wt
Trin 1
I det første trin kører algoritmen mpg på wt og de andre variable uafhængigt.
## [[1]] ## (Intercept) wt disp ## 4.910746e-16 7.430725e-03 6.361981e-02 ## ## [[2]] ## (Intercept) wt hp ## 2.565459e-20 1.119647e-06 1.451229e-03 ## ## [[3]] ## (Intercept) wt drat ## 2.737824e-04 1.589075e-06 3.308544e-01 ## ## [[4]] ## (Intercept) wt qsec ## 7.650466e-04 2.518948e-11 1.499883e-03
Hver variabel er en potentiel kandidat til at indgå i den endelige model. Algoritmen beholder dog kun den variable med den laveste p-værdi. Det viser sig, at hp har en lidt lavere p-værdi end qsec, så hp indgår i den endelige model.
Trin 2
Algoritmen gentager det første trin, men denne gang med to uafhængige variable i den endelige model.
## [[1]] ## (Intercept) wt hp disp ## 1.161936e-16 1.330991e-03 1.097103e-02 9.285070e-01 ## ## [[2]] ## (Intercept) wt hp drat ## 5.133678e-05 3.642961e-04 1.178415e-03 1.987554e-01 ## ## [[3]] ## (Intercept) wt hp qsec ## 2.784556e-03 3.217222e-06 2.441762e-01 2.546284e-01
Ingen af de resterende kandidater har en p-værdi under indgangstærsklen. Algoritmen stopper her, og dette er den endelige model:
## ## Call: ## lm(formula = mpg ~ wt + hp, data = df) ## ## Residuals: ## Min 1Q Median 3Q Max ## -3.941 -1.600 -0.182 1.050 5.854 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 37.22727 1.59879 23.285 < 2e-16 *** ## wt -3.87783 0.63273 -6.129 1.12e-06 *** ## hp -0.03177 0.00903 -3.519 0.00145 ** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 2.593 on 29 degrees of freedom ## Multiple R-squared: 0.8268, Adjusted R-squared: 0.8148 ## F-statistic: 69.21 on 2 and 29 DF, p-value: 9.109e-12
Du kan bruge funktionen ols_stepwise() til at sammenligne resultaterne.
stp_s <-ols_stepwise(fit, details=TRUE)
Output:
Algoritmen finder en løsning efter to trin og returnerer det samme output som den manuelle gennemgang ovenfor.
Den endelige model forklares derfor af to prædiktorer og et skæringspunkt: miles per gallon er negativt relateret til både brutto hestekræfter og vægt.
## You are selecting variables based on p value... ## 1 variable(s) added.... ## Variable Selection Procedure ## Dependent Variable: mpg ## ## Stepwise Selection: Step 1 ## ## Variable wt Entered ## ## Model Summary ## -------------------------------------------------------------- ## R 0.868 RMSE 3.046 ## R-Squared 0.753 Coef. Var 15.161 ## Adj. R-Squared 0.745 MSE 9.277 ## Pred R-Squared 0.709 MAE 2.341 ## -------------------------------------------------------------- ## RMSE: Root Mean Square Error ## MSE: Mean Square Error ## MAE: Mean Absolute Error ## ANOVA ## -------------------------------------------------------------------- ## Sum of ## Squares DF Mean Square F Sig. ## -------------------------------------------------------------------- ## Regression 847.725 1 847.725 91.375 0.0000 ## Residual 278.322 30 9.277 ## Total 1126.047 31 ## -------------------------------------------------------------------- ## ## Parameter Estimates ## ---------------------------------------------------------------------------------------- ## model Beta Std. Error Std. Beta t Sig lower upper ## ---------------------------------------------------------------------------------------- ## (Intercept) 37.285 1.878 19.858 0.000 33.450 41.120 ## wt -5.344 0.559 -0.868 -9.559 0.000 -6.486 -4.203 ## ---------------------------------------------------------------------------------------- ## 1 variable(s) added... ## Stepwise Selection: Step 2 ## ## Variable hp Entered ## ## Model Summary ## -------------------------------------------------------------- ## R 0.909 RMSE 2.593 ## R-Squared 0.827 Coef. Var 12.909 ## Adj. R-Squared 0.815 MSE 6.726 ## Pred R-Squared 0.781 MAE 1.901 ## -------------------------------------------------------------- ## RMSE: Root Mean Square Error ## MSE: Mean Square Error ## MAE: Mean Absolute Error ## ANOVA ## -------------------------------------------------------------------- ## Sum of ## Squares DF Mean Square F Sig. ## -------------------------------------------------------------------- ## Regression 930.999 2 465.500 69.211 0.0000 ## Residual 195.048 29 6.726 ## Total 1126.047 31 ## -------------------------------------------------------------------- ## ## Parameter Estimates ## ---------------------------------------------------------------------------------------- ## model Beta Std. Error Std. Beta t Sig lower upper ## ---------------------------------------------------------------------------------------- ## (Intercept) 37.227 1.599 23.285 0.000 33.957 40.497 ## wt -3.878 0.633 -0.630 -6.129 0.000 -5.172 -2.584 ## hp -0.032 0.009 -0.361 -3.519 0.001 -0.050 -0.013 ## ---------------------------------------------------------------------------------------- ## No more variables to be added or removed.
Lineær regression i R: Vigtige konklusioner og funktionsreference
- Lineær regression besvarer et simpelt spørgsmål: Kan man måle en præcis sammenhæng mellem én målvariabel og et sæt prædiktorer?
- Den ordinære mindste kvadraters metode finder de parametre, der minimerer summen af de kvadrerede fejl, det vil sige den lodrette afstand mellem de forudsagte y-værdier og de faktiske y-værdier.
- Den probabilistiske model, der omfatter mere end én uafhængig variabel, kaldes multiple regressionsmodeller.
- Formålet med Stepwise Linear Regression-algoritmen er at tilføje og fjerne potentielle kandidater i modellerne og beholde dem, der har en signifikant indflydelse på den afhængige variabel.
- Variabelvalg er en vigtig del af tilpasningen af en model, og trinvis regression udfører denne søgning automatisk.
Alle funktioner, der bruges i denne vejledning, er anført nedenfor:
| Bibliotek | Objektiv | Funktion | argumenter |
|---|---|---|---|
| bund | Beregn en lineær regression | lm() | formel, data |
| bund | Opsummer modellen | Resumé() | passer |
| bund | Extract-koefficienter | lm()$koefficient | |
| bund | Extract-residualer | lm()$rester | |
| bund | Extract-tilpasset værdi | lm()$fitted.values | |
| olsrr | Kør trinvis regression | ols_stepwise() | fit, pent = 0.1, prem = 0.3, detaljer = FALSK |
BemærkHusk at konvertere kategoriske variabler til faktorer, før modellen tilpasses.