เมทริกซ์สหสัมพันธ์เพียร์สันและสเปียร์แมนใน R พร้อมตัวอย่าง
⚡ สรุปอย่างชาญฉลาด
การหาค่าสัมประสิทธิ์สหสัมพันธ์แบบ Pearson และ Spearman ใน R จะวัดว่าตัวแปรสองตัวเคลื่อนไหวไปในทิศทางเดียวกันอย่างแรงแค่ไหน โดยใช้ฟังก์ชัน cor() สำหรับตัวแปรคู่เดียว และใช้เมทริกซ์สหสัมพันธ์สำหรับตัวแปรหลายตัว บทแนะนำนี้จะเพิ่มการทดสอบนัยสำคัญด้วย Hmisc และแสดงผลลัพธ์ด้วยแผนที่ความร้อน GGally

ความสัมพันธ์แบบไบวาเรียตในอาร์
ความสัมพันธ์แบบไบวาเรียตอธิบายความสัมพันธ์หรือความสัมพันธ์ระหว่างตัวแปรสองตัวใน R ในบทช่วยสอนนี้ เราจะพูดถึงแนวคิดเรื่องความสัมพันธ์และแสดงให้เห็นว่าสามารถใช้เพื่อวัดความสัมพันธ์ระหว่างตัวแปรสองตัวใน R ได้อย่างไร
ความสัมพันธ์ในการเขียนโปรแกรม R
มีสองวิธีหลักในการคำนวณความสัมพันธ์ระหว่างตัวแปรสองตัวในการเขียนโปรแกรม R:
- เพียร์สัน: ความสัมพันธ์แบบพาราเมตริก
- พลหอก: ความสัมพันธ์แบบไม่อิงพารามิเตอร์
เมทริกซ์สหสัมพันธ์เพียร์สันในอาร์
วิธีความสัมพันธ์แบบเพียร์สันมักใช้เป็นการตรวจสอบเบื้องต้นสำหรับความสัมพันธ์ระหว่างตัวแปรสองตัว
การขอ ค่าสัมประสิทธิ์สหสัมพันธ์เขียนด้วยตัว r ใช้วัดความแข็งแรงของ เชิงเส้น ความสัมพันธ์ระหว่างตัวแปรสองตัวคือ x และ y คำนวณได้ดังนี้:
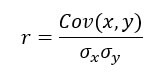
สีสดสวย
 คือค่าเบี่ยงเบนมาตรฐานของ x
คือค่าเบี่ยงเบนมาตรฐานของ x คือค่าเบี่ยงเบนมาตรฐานของ y
คือค่าเบี่ยงเบนมาตรฐานของ y
ความสัมพันธ์อยู่ระหว่าง -1 ถึง 1
- ค่า r ที่ใกล้เคียงหรือเท่ากับ 0 หมายความว่ามีความสัมพันธ์เชิงเส้นระหว่าง x และ y น้อยมากหรือไม่มีเลย
- ยิ่งค่า r เข้าใกล้ 1 หรือ -1 มากเท่าไร ความสัมพันธ์เชิงเส้นก็จะยิ่งแข็งแกร่งมากขึ้นเท่านั้น
คุณสามารถทดสอบว่าค่า r แตกต่างจากศูนย์หรือไม่โดยใช้สถิติ t ด้านล่าง โดยเปรียบเทียบกับค่าการแจกแจงแบบ Student ที่มีองศาอิสระ n – 2:
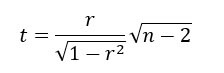
สเปียร์แมนอันดับสหสัมพันธ์ในอาร์
การหาค่าสัมประสิทธิ์สหสัมพันธ์ตามลำดับ (Rank correlation) จะเรียงลำดับข้อมูลตามลำดับและคำนวณระดับความคล้ายคลึงกันระหว่างลำดับเหล่านั้น ข้อดีของการหาค่าสัมประสิทธิ์สหสัมพันธ์ตามลำดับคือมีความทนทานต่อค่าผิดปกติและไม่เกี่ยวข้องกับการกระจายตัวของข้อมูล นอกจากนี้ การหาค่าสัมประสิทธิ์สหสัมพันธ์ตามลำดับยังเป็นตัวเลือกที่เหมาะสมสำหรับตัวแปรเชิงลำดับอีกด้วย
ค่าสัมประสิทธิ์สหสัมพันธ์ลำดับของสเปียร์แมน ซึ่งเขียนแทนด้วยสัญลักษณ์ โร (rho) มีค่าตั้งแต่ -1 ถึง 1 โดยค่าที่ใกล้เคียงกับค่าสุดขั้วใดค่าหนึ่งแสดงถึงความสัมพันธ์แบบโมโนโทนิกที่แข็งแกร่ง วิธีการคำนวณมีดังนี้:
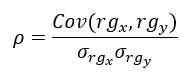
ตัวเศษคือค่าความแปรปรวนร่วมระหว่างอันดับของ x และ y และตัวส่วนคือผลคูณของค่าเบี่ยงเบนมาตรฐานของทั้งสองค่า
ใน R ทั้งสองค่าคำนวณได้ด้วยฟังก์ชัน cor() ซึ่งรับอาร์กิวเมนต์สามตัว ได้แก่ x, y และ method
cor(x, y, method)
ข้อโต้แย้ง:
- x: เวกเตอร์แรก
- y: เวกเตอร์ที่สอง
- วิธี: สูตรที่ใช้คำนวณความสัมพันธ์ ค่าสตริงสามค่า:
- “เพียร์สัน”
- “เคนดัลล์”
- “พลหอก”
สามารถเพิ่มอาร์กิวเมนต์ทางเลือกได้หากเวกเตอร์มีค่าหายไป: use = “complete.obs”
เราจะใช้ชุดข้อมูล BudgetUK ชุดข้อมูลนี้รายงานการจัดสรรงบประมาณของครัวเรือนชาวอังกฤษระหว่างปี 1980 ถึง 1982 มีข้อสังเกต 1519 รายการพร้อมคุณลักษณะ XNUMX ประการ ได้แก่:
- อาหาร: แบ่งปันอาหาร แบ่งปันการใช้จ่าย
- wfuel: แบ่งการใช้จ่ายน้ำมันเชื้อเพลิง
- ผ้า: ส่วนแบ่งงบประมาณสำหรับการใช้จ่ายด้านเสื้อผ้า
- วอลค: แบ่งปันการใช้จ่ายเครื่องดื่มแอลกอฮอล์
- wtrans: แบ่งปันค่าใช้จ่ายในการขนส่ง
- อย่างอื่น: ส่วนแบ่งของการใช้จ่ายสินค้าอื่นๆ
- โทเท็ปป์: การใช้จ่ายครัวเรือนทั้งหมดเป็นปอนด์
- เงินได้: รายได้สุทธิของครัวเรือนทั้งหมด
- อายุ: อายุครัวเรือน
- เด็ก ๆ: จำนวนบุตร
ตัวอย่าง
library(dplyr) PATH <- "https://raw.githubusercontent.com/guru99-edu/R-Programming/master/british_household.csv" data <- read.csv(PATH) %>% filter(income < 500) %>% mutate(log_income = log(income), log_totexp = log(totexp), children_fac = factor(children, order = TRUE, labels = c("No", "Yes"))) %>% select(-c(X, X.1, children, totexp, income)) glimpse(data)
Code คำอธิบาย
- ก่อนอื่นเรานำเข้าข้อมูลและดูด้วยฟังก์ชันเหลือบ () จากไลบรารี dplyr
- มี 3 ครัวเรือนที่รายงานรายได้ 500 ขึ้นไป ดังนั้นตัวกรอง (รายได้ < 500) จะลบครัวเรือนเหล่านั้นออก และจำนวนแถวจะลดลงจาก 1,519 เหลือ 1,516
- เป็นเรื่องปกติในการแปลงตัวแปรทางการเงินในบันทึก ช่วยลดผลกระทบของค่าผิดปกติและลดความเบ้ในชุดข้อมูล
Output:
## Observations: 1,516 ## Variables: 10 ## $ wfood <dbl> 0.4272, 0.3739, 0.1941, 0.4438, 0.3331, 0.3752, 0... ## $ wfuel <dbl> 0.1342, 0.1686, 0.4056, 0.1258, 0.0824, 0.0481, 0... ## $ wcloth <dbl> 0.0000, 0.0091, 0.0012, 0.0539, 0.0399, 0.1170, 0... ## $ walc <dbl> 0.0106, 0.0825, 0.0513, 0.0397, 0.1571, 0.0210, 0... ## $ wtrans <dbl> 0.1458, 0.1215, 0.2063, 0.0652, 0.2403, 0.0955, 0... ## $ wother <dbl> 0.2822, 0.2444, 0.1415, 0.2716, 0.1473, 0.3431, 0... ## $ age <int> 25, 39, 47, 33, 31, 24, 46, 25, 30, 41, 48, 24, 2... ## $ log_income <dbl> 4.867534, 5.010635, 5.438079, 4.605170, 4.605170,... ## $ log_totexp <dbl> 3.912023, 4.499810, 5.192957, 4.382027, 4.499810,... ## $ children_fac <ord> Yes, Yes, Yes, Yes, No, No, No, No, No, No, Yes, ...
เราสามารถคำนวณค่าสัมประสิทธิ์สหสัมพันธ์ระหว่างรายได้และตัวแปร wfood ได้ด้วยวิธี "pearson" และ "spearman"
cor(data$log_income, data$wfood, method = "pearson")
Output:
## [1] -0.2466986
cor(data$log_income, data$wfood, method = "spearman")
Output:
## [1] -0.2501252
ก่อนที่จะขยายแนวคิดนี้ไปใช้กับตัวแปรทุกคู่ เราควรทำความเข้าใจวิธีการอ่านค่าสัมประสิทธิ์ตัวเดียวให้ชัดเจนเสียก่อน
วิธีตีความค่าสัมประสิทธิ์สหสัมพันธ์
ค่าสัมประสิทธิ์จะมีประโยชน์ก็ต่อเมื่อคุณสามารถอธิบายความหมายของมันได้ แถบด้านล่างเป็นค่าที่อ่านได้ตามปกติ และเครื่องหมายจะถูกอ่านแยกต่างหากจากค่าความแรง
| ค่าสัมบูรณ์ของ r | ความแข็งแกร่งของความสัมพันธ์ |
|---|---|
| เพื่อ 0.00 0.19 | อ่อนมากหรือไม่มีเลย |
| เพื่อ 0.20 0.39 | อ่อนแอ |
| เพื่อ 0.40 0.59 | ปานกลาง |
| เพื่อ 0.60 0.79 | แข็งแรง |
| เพื่อ 0.80 1.00 | แข็งแกร่งมาก |
ค่า -0.2467 ที่คำนวณได้ก่อนหน้านี้ระหว่าง log_income และ wfood จึงแสดงถึงความสัมพันธ์เชิงลบที่อ่อนแอ กล่าวคือ ครัวเรือนที่ร่ำรวยกว่าใช้จ่ายงบประมาณในส่วนของอาหารน้อยลงเล็กน้อย
มีข้อควรระวังสามประการที่ใช้กับสัมประสิทธิ์ทุกตัว
- ความสัมพันธ์ไม่ใช่สาเหตุ ค่า r ที่สูงแสดงว่าตัวแปรทั้งสองเคลื่อนไหวไปพร้อมกัน ไม่ได้หมายความว่าตัวแปรหนึ่งเป็นสาเหตุของอีกตัวแปรหนึ่ง ตัวแปรที่สามซึ่งวัดไม่ได้มักจะเป็นตัวขับเคลื่อนทั้งสองตัวแปร
- เพียร์สันมองเห็นแต่เส้นตรงเท่านั้น ความสัมพันธ์รูปตัว U ที่สมบูรณ์แบบจะให้ค่า r ที่ใกล้เคียงกับศูนย์ ควรพล็อตข้อมูลก่อนที่จะเชื่อถือตัวเลขเสมอ
- ขนาดสำคัญกว่าความหมาย ด้วยจำนวนข้อมูล 1,516 ตัวอย่าง ค่าสัมประสิทธิ์ 0.06 อาจมีความสำคัญทางสถิติ แต่ในทางปฏิบัติก็อาจไม่มีความหมาย
วิธีทดสอบความสำคัญของความสัมพันธ์ด้วย cor.test()
cor() จะส่งคืนค่าสัมประสิทธิ์เท่านั้น สำหรับคู่ข้อมูลเดียว cor.test() จะเพิ่มค่า p และช่วงความเชื่อมั่นในการเรียกเพียงครั้งเดียว
cor.test(data$log_income, data$wfood, method = "pearson")
ผลลัพธ์ที่ได้มีสี่ส่วนที่น่าสนใจ
- t และ df: ค่าสถิติการทดสอบและระดับความเป็นอิสระ n – 2
- p-value: ความน่าจะเป็นที่จะเห็นค่าสัมประสิทธิ์ที่มีขนาดใหญ่เช่นนี้ หากค่าสหสัมพันธ์ที่แท้จริงเป็นศูนย์
- ช่วงความเชื่อมั่น 95 เปอร์เซ็นต์ช่วงค่าที่เป็นไปได้สำหรับความสัมพันธ์ที่แท้จริง หากไม่รวมศูนย์ แสดงว่าความสัมพันธ์นั้นมีนัยสำคัญในระดับนั้น
- การประมาณตัวอย่าง: ค่าสัมประสิทธิ์นั้นเอง ซึ่งเหมือนกับค่าที่ฟังก์ชัน cor() ส่งคืนทุกประการ
ฟังก์ชันเดียวกันนี้ใช้รันการทดสอบตามลำดับขั้น โดยเปลี่ยนค่าอาร์กิวเมนต์เพียงตัวเดียว:
# Spearman rank correlation with a p-value cor.test(data$log_income, data$wfood, method = "spearman") # One-sided test: is the correlation greater than zero? cor.test(data$log_income, data$wfood, alternative = "greater")
ควรใช้แบบไหนในสถานการณ์ใด ใช้ cor.test() เมื่อคุณกำลังตรวจสอบคู่ข้อมูลเฉพาะคู่เดียว เพราะมันให้ช่วงความเชื่อมั่นซึ่ง rcorr() ไม่ได้แสดง ใช้ rcorr() จาก Hmisc ที่แสดงไว้ข้างต้น เมื่อคุณต้องการค่า p สำหรับเมทริกซ์ทั้งหมดในคราวเดียว โปรดทราบว่าการทดสอบหลายคู่ข้อมูลจะเพิ่มอัตราผลบวกเท็จ ดังนั้นให้ปรับค่า p ด้วย p.adjust(p_value, method = “BH”) ก่อนที่จะสรุปผลจากเมทริกซ์ขนาดใหญ่
เมทริกซ์สหสัมพันธ์ในอาร์
การหาความสัมพันธ์แบบสองตัวแปรเป็นจุดเริ่มต้นที่ดี แต่การพิจารณาแบบหลายตัวแปรจะให้ภาพรวมที่กว้างขึ้น เมทริกซ์สหสัมพันธ์ เป็นตารางสี่เหลี่ยมที่แสดงค่าสหสัมพันธ์แบบคู่ระหว่างตัวแปรทุกตัวกับตัวแปรอื่นๆ ทุกตัว
ฟังก์ชัน cor() ส่งกลับเมทริกซ์สหสัมพันธ์ ข้อแตกต่างเพียงอย่างเดียวกับความสัมพันธ์แบบไบวาเรียตคือเราไม่จำเป็นต้องระบุว่าตัวแปรใด ตามค่าเริ่มต้น R จะคำนวณความสัมพันธ์ระหว่างตัวแปรทั้งหมด
ไม่สามารถคำนวณค่าสหสัมพันธ์สำหรับตัวแปรประเภทแฟกเตอร์ได้ ดังนั้นให้ลบทุกคอลัมน์ที่เป็นประเภทจัดกลุ่มออกก่อนที่จะส่งเฟรมข้อมูลไปยังฟังก์ชัน cor()
เมทริกซ์สหสัมพันธ์มีความสมมาตร ซึ่งหมายความว่าค่าที่อยู่เหนือเส้นทแยงมุมจะมีค่าเดียวกันกับค่าด้านล่าง การแสดงครึ่งหนึ่งของเมทริกซ์จะมองเห็นได้ชัดเจนกว่า
children_fac ถูกยกเว้นเนื่องจาก cor() ไม่สามารถทำงานกับแฟกเตอร์ได้
# the last column of data is a factor level. We don't include it in the code mat_1 <-as.dist(round(cor(data[,1:9]),2)) mat_1
Code คำอธิบาย
- cor(data[, 1:9]): คำนวณเมทริกซ์สหสัมพันธ์บนคอลัมน์ตัวเลขทั้งเก้าคอลัมน์
- รอบ(…, 2)ปัดเศษสัมประสิทธิ์ทุกตัวให้เหลือสองตำแหน่งทศนิยม
- as.dist()พิมพ์เฉพาะส่วนสามเหลี่ยมด้านล่าง เนื่องจากเมทริกซ์มีความสมมาตร
Output:
## wfood wfuel wcloth walc wtrans wother age log_income ## wfuel 0.11 ## wcloth -0.33 -0.25 ## walc -0.12 -0.13 -0.09 ## wtrans -0.34 -0.16 -0.19 -0.22 ## wother -0.35 -0.14 -0.22 -0.12 -0.29 ## age 0.02 -0.05 0.04 -0.14 0.03 0.02 ## log_income -0.25 -0.12 0.10 0.04 0.06 0.13 0.23 ## log_totexp -0.50 -0.36 0.34 0.12 0.15 0.15 0.21 0.49
ระดับความสำคัญ
ค่าสัมประสิทธิ์เพียงอย่างเดียวไม่ได้บอกว่าความสัมพันธ์นั้นมีความน่าเชื่อถือทางสถิติหรือไม่ ฟังก์ชัน rcorr() จากไลบรารี Hmisc จะส่งคืนค่า p-value สำหรับทุกคู่ เราสามารถดาวน์โหลดไลบรารีได้จาก คอนด้า และคัดลอกโค้ดเพื่อวางลงในเทอร์มินัล:
conda install -c r r-hmisc
rcorr() ต้องใช้ data frame ที่จะจัดเก็บเป็นเมทริกซ์ เราสามารถแปลงข้อมูลของเราให้เป็นเมทริกซ์ก่อนที่จะคำนวณเมทริกซ์สหสัมพันธ์ด้วยค่า p
library("Hmisc") data_rcorr <-as.matrix(data[, 1: 9]) mat_2 <-rcorr(data_rcorr) # mat_2 <-rcorr(as.matrix(data)) returns the same output
รายการวัตถุ mat_2 มีสามองค์ประกอบ:
- r: เอาท์พุตของเมทริกซ์สหสัมพันธ์
- n: จำนวนการสังเกต
- P: ค่า p
เราสนใจองค์ประกอบที่สาม นั่นคือค่า p เป็นเรื่องปกติที่จะแสดงเมทริกซ์สหสัมพันธ์ด้วยค่า p แทนค่าสัมประสิทธิ์สหสัมพันธ์
p_value <-round(mat_2[["P"]], 3) p_value
Code คำอธิบาย
- mat_2[[“พี”]]: ค่า p จะถูกเก็บไว้ในองค์ประกอบที่เรียกว่า P
- รอบ(mat_2[[“P”]], 3): ปัดเศษองค์ประกอบด้วยตัวเลขสามหลัก
Output:
wfood wfuel wcloth walc wtrans wother age log_income log_totexp wfood NA 0.000 0.000 0.000 0.000 0.000 0.365 0.000 0 wfuel 0.000 NA 0.000 0.000 0.000 0.000 0.076 0.000 0 wcloth 0.000 0.000 NA 0.001 0.000 0.000 0.160 0.000 0 walc 0.000 0.000 0.001 NA 0.000 0.000 0.000 0.105 0 wtrans 0.000 0.000 0.000 0.000 NA 0.000 0.259 0.020 0 wother 0.000 0.000 0.000 0.000 0.000 NA 0.355 0.000 0 age 0.365 0.076 0.160 0.000 0.259 0.355 NA 0.000 0 log_income 0.000 0.000 0.000 0.105 0.020 0.000 0.000 NA 0 log_totexp 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 NA
การแสดงภาพเมทริกซ์สหสัมพันธ์ใน R
แผนที่ความร้อนเป็นอีกวิธีหนึ่งในการอ่านเมทริกซ์ความสัมพันธ์ ไลบรารี GGally ขยายขีดความสามารถของ ggplot2 และสามารถติดตั้งได้จาก CRAN แทนที่จะใช้ conda:
install.packages("GGally")

ไลบรารีประกอบด้วยฟังก์ชันต่างๆ เพื่อแสดงสถิติสรุป เช่น ความสัมพันธ์และการแจกแจงของตัวแปรทั้งหมดใน a เมทริกซ์.
ฟังก์ชัน ggcorr() มีอาร์กิวเมนต์มากมาย เราจะแนะนำเฉพาะข้อโต้แย้งที่เราจะใช้ในบทช่วยสอน:
ฟังก์ชัน ggcorr
ggcorr(df, method = c("pairwise", "pearson"), nbreaks = NULL, digits = 2, low = "#3B9AB2", mid = "#EEEEEE", high = "#F21A00", geom = "tile", label = FALSE, label_alpha = FALSE)
ข้อโต้แย้ง:
- df: ชุดข้อมูลที่ใช้
- วิธี:สูตรในการคำนวณความสัมพันธ์ โดยค่าเริ่มต้นจะคำนวณแบบคู่และเพียร์สัน
- แบ่ง: ส่งกลับช่วงหมวดหมู่สำหรับการใช้สีของสัมประสิทธิ์ ตามค่าเริ่มต้น ไม่มีการหยุดพักและการไล่ระดับสีจะต่อเนื่องกัน
- ตัวเลข: ปัดเศษค่าสัมประสิทธิ์สหสัมพันธ์ ตามค่าเริ่มต้น ให้ตั้งค่าเป็น 2
- ต่ำ: ควบคุมระดับสีล่าง
- ตรงกลาง: ควบคุมระดับกลางของสี
- สูง: ควบคุมระดับสูงของสี
- เรขาคณิต: ควบคุมรูปร่างของอาร์กิวเมนต์ทางเรขาคณิต ตามค่าเริ่มต้น "ไทล์"
- ฉลาก: ค่าบูลีน แสดงหรือไม่ติดฉลาก ตามค่าเริ่มต้น ให้ตั้งค่าเป็น "FALSE"
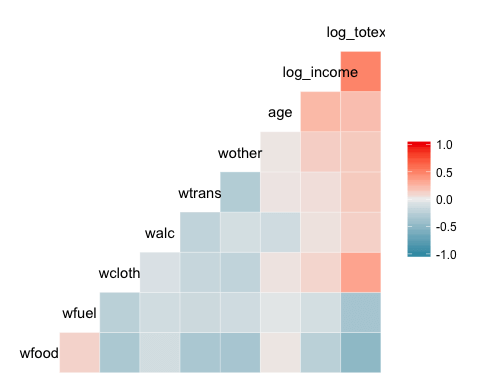
แผนที่ความร้อนพื้นฐาน
พล็อตพื้นฐานที่สุดของแพ็คเกจคือแผนที่ความร้อน คำอธิบายแผนภูมิแสดงสีแบบไล่ระดับจาก -1 ถึง 1 โดยสีร้อนแสดงถึงความสัมพันธ์เชิงบวกที่ชัดเจน และสีเย็นแสดงถึงความสัมพันธ์เชิงลบ
library(GGally) ggcorr(data)
Code คำอธิบาย
- ggcorr (ข้อมูล): จำเป็นต้องมีอาร์กิวเมนต์เดียวเท่านั้น ซึ่งก็คือชื่อเฟรมข้อมูล ตัวแปรระดับปัจจัยไม่รวมอยู่ในโครงเรื่อง
Output:
การเพิ่มการควบคุมลงในแผนที่ความร้อน
เราสามารถเพิ่มการควบคุมเพิ่มเติมให้กับกราฟได้:
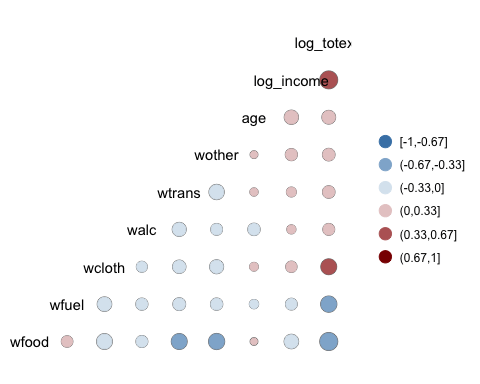
ggcorr(data, nbreaks = 6, low = "steelblue", mid = "white", high = "darkred", geom = "circle")
Code คำอธิบาย
- nbreaks=6: ทำลายตำนาน 6 อันดับ
- ต่ำ = “สตีลบลู”: ใช้สีอ่อนกว่าสำหรับความสัมพันธ์เชิงลบ
- กลาง = “สีขาว”: ใช้สีขาวสำหรับความสัมพันธ์ในระดับกลาง
- สูง = “เข้ม”: ใช้สีเข้มเพื่อความสัมพันธ์เชิงบวก
- geom = “วงกลม”:ใช้วงกลมเป็นรูปร่างของหน้าต่างในแผนที่ความร้อน ขนาดของวงกลมจะแปรผันตามค่าสัมบูรณ์ของความสัมพันธ์
Output:
การเพิ่มป้ายกำกับลงในแผนที่ความร้อน
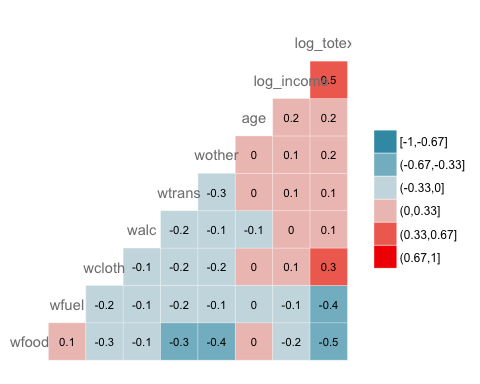
GGally ช่วยให้เราเพิ่มป้ายกำกับภายในหน้าต่างได้:
ggcorr(data, nbreaks = 6, label = TRUE, label_size = 3, color = "grey50")
Code คำอธิบาย
- ป้ายกำกับ = จริง: เพิ่มค่าสัมประสิทธิ์สหสัมพันธ์ภายในแผนที่ความร้อน
- สี = “สีเทา50”: เลือกสี เช่น สีเทา
- label_size = 3: กำหนดขนาดของฉลากเท่ากับ 3
Output:
ฟังก์ชัน ggpairs
ไลบรารี GGally ยังมีฟังก์ชัน ggpairs() ซึ่งส่งคืนเมทริกซ์ของกราฟ สำหรับตัวแปรที่เลือก k ตัว ผลลัพธ์จะเป็นตารางขนาด ak x k โดยเส้นทแยงมุมแสดงการกระจายของแต่ละตัวแปร ขณะที่แผงด้านบนและด้านล่างของเส้นทแยงมุมสามารถแสดงผลการคำนวณที่แตกต่างกันได้ ไวยากรณ์คือ:
ggpairs(df, columns = 1:ncol(df), title = NULL, upper = list(continuous = "cor"), lower = list(continuous = "smooth"), mapping = NULL)
ข้อโต้แย้ง:
- df: ชุดข้อมูลที่ใช้
- คอลัมน์: เลือกคอลัมน์ที่จะวาดโครงเรื่อง
- ชื่อเรื่อง: รวมชื่อเรื่อง
- บน: ควบคุมกล่องด้านบนเส้นทแยงมุมของกราฟ จำเป็นต้องระบุประเภทของการคำนวณหรือกราฟที่จะส่งคืน หาก continuous = “cor” เราจะขอให้ R คำนวณค่าสหสัมพันธ์ โปรดทราบว่า อาร์กิวเมนต์ต้องเป็นลิสต์ มีอาร์กิวเมนต์อื่นๆ ให้เลือกใช้ โปรดดูที่... เอกสารประกอบ GGally เพื่อสอบถามรายละเอียดเพิ่มเติมได้ค่ะ
- ลด:ควบคุมกล่องที่อยู่ด้านล่างแนวทแยง
- แผนที่ping: บ่งบอกถึงความสวยงามของกราฟ ตัวอย่างเช่น เราสามารถคำนวณกราฟสำหรับกลุ่มต่างๆ
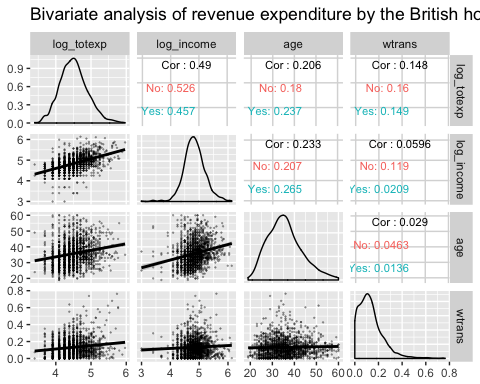
การวิเคราะห์แบบสองตัวแปรด้วย ggpair ร่วมกับกลุ่มping
กราฟถัดไปแสดงข้อมูลสามรายการ:
- เมทริกซ์สหสัมพันธ์ระหว่างตัวแปร log_totexp, log_income, อายุ และ wtrans จัดกลุ่มตามว่าครัวเรือนมีลูกหรือไม่
- พล็อตการกระจายของตัวแปรแต่ละตัวตามกลุ่ม
- แสดงแผนภูมิกระจายพร้อมแนวโน้มตามกลุ่ม
library(ggplot2) ggpairs(data, columns = c("log_totexp", "log_income", "age", "wtrans"), title = "Bivariate analysis of revenue expenditure by the British household", upper = list(continuous = wrap("cor", size = 3)), lower = list(continuous = wrap("smooth", alpha = 0.3, size = 0.1)), mapping = aes(color = children_fac))
Code คำอธิบาย
- คอลัมน์ = c("log_totexp", "log_income", "อายุ", "wtrans"): เลือกตัวแปรที่จะแสดงในกราฟ
- title = “การวิเคราะห์ Bivariate ของรายจ่ายรายรับโดยครัวเรือนอังกฤษ”: เพิ่มชื่อเรื่อง
- บน = รายการ (): ควบคุมส่วนบนของกราฟ คือเหนือเส้นทแยงมุม
- ต่อเนื่อง = ห่อ ("คร", ขนาด = 3)): คำนวณค่าสัมประสิทธิ์สหสัมพันธ์ เราล้อมอาร์กิวเมนต์ต่อเนื่องไว้ภายในฟังก์ชัน wrap() เพื่อควบคุมความสวยงามของกราฟ ( เช่น ขนาด = 3) -lower = list(): ควบคุมส่วนล่างของกราฟ คือด้านล่างเส้นทแยงมุม
- ต่อเนื่อง = ห่อ ("เรียบ",อัลฟา = 0.3,ขนาด=0.1): เพิ่มแผนภูมิกระจายที่มีแนวโน้มเป็นเส้นตรง เราล้อมอาร์กิวเมนต์ต่อเนื่องไว้ภายในฟังก์ชัน wrap() เพื่อควบคุมความสวยงามของกราฟ ( เช่น size=0.1, alpha=0.3)
- แผนที่ping = aes(color = children_fac): แบ่งแต่ละแผงตาม children_fac ซึ่งเป็นปัจจัยเรียงลำดับที่ระบุว่า “ไม่มี” สำหรับครัวเรือนที่ไม่มีเด็ก และ “มี” สำหรับครัวเรือนที่มีเด็ก
Output:

การวิเคราะห์แบบสองตัวแปรด้วย ggpair พร้อมกลุ่มย่อยping
กราฟด้านล่างนี้แตกต่างออกไปเล็กน้อย เราเปลี่ยนตำแหน่งของแผนที่ping ภายในอาร์กิวเมนต์ด้านบน
ggpairs(data, columns = c("log_totexp", "log_income", "age", "wtrans"), title = "Bivariate analysis of revenue expenditure by the British household", upper = list(continuous = wrap("cor", size = 3), mapping = aes(color = children_fac)), lower = list( continuous = wrap("smooth", alpha = 0.3, size = 0.1)) )
Code คำอธิบาย
- รหัสเดียวกันกับตัวอย่างก่อนหน้า ยกเว้น:
- แผนที่ping = aes(color = children_fac): ย้ายรายการไปไว้ด้านบน = list() เราต้องการเฉพาะการคำนวณที่เรียงซ้อนตามกลุ่มในส่วนบนของกราฟเท่านั้น
Output:
การหาความสัมพันธ์ใน R: ประเด็นสำคัญและข้อมูลอ้างอิงฟังก์ชัน
- ความสัมพันธ์แบบไบวาเรียตอธิบายความสัมพันธ์หรือความสัมพันธ์ระหว่างตัวแปรสองตัวใน R
- มีสองวิธีหลักในการคำนวณความสัมพันธ์ระหว่างตัวแปรสองตัวใน การเขียนโปรแกรม R: เพียร์สันและสเปียร์แมน
- วิธีความสัมพันธ์แบบเพียร์สันมักใช้เป็นการตรวจสอบเบื้องต้นสำหรับความสัมพันธ์ระหว่างตัวแปรสองตัว
- ความสัมพันธ์ของอันดับจะเรียงลำดับการสังเกตตามอันดับ และคำนวณระดับของความคล้ายคลึงกันระหว่างอันดับ
- ค่าสัมประสิทธิ์สหสัมพันธ์ลำดับของสเปียร์แมนมีค่าตั้งแต่ -1 ถึง 1 โดยค่าที่อยู่ใกล้ค่าสุดขั้วใดค่าหนึ่งแสดงถึงความสัมพันธ์แบบโมโนโทนิกที่แข็งแกร่ง
- เมทริกซ์สหสัมพันธ์คือตารางสี่เหลี่ยมที่เก็บค่าสหสัมพันธ์ระหว่างตัวแปรแต่ละตัวเป็นคู่ๆ
- ค่า p-value จะบอกคุณว่าความสัมพันธ์ที่สังเกตได้นั้นแตกต่างจากศูนย์ในเชิงสถิติหรือไม่
ฟังก์ชันความสัมพันธ์ทุกฟังก์ชันที่ใช้ในบทเรียนนี้แสดงไว้ด้านล่าง:
| ห้องสมุด | วัตถุประสงค์ | วิธี | Code |
|---|---|---|---|
| ฐาน | ความสัมพันธ์แบบสองตัวแปร | เพียร์สัน |
cor(dfx2, method = "pearson") |
| ฐาน | ความสัมพันธ์แบบสองตัวแปร | พลหอก |
cor(dfx2, method = "spearman") |
| ฐาน | ความสัมพันธ์หลายตัวแปร | เพียร์สัน |
cor(df, method = "pearson") |
| ฐาน | ความสัมพันธ์หลายตัวแปร | พลหอก |
cor(df, method = "spearman") |
| มช | ค่า P | - |
rcorr(as.matrix(data[,1:9]))[["P"]] |
| จีจีแอลลี่ | แผนที่ความร้อน | - |
ggcorr(df)
|
| จีจีแอลลี่ | เมทริกซ์พล็อตหลายตัวแปร | - |
ggpairs(df, columns = c("x1", "x2")) |