SQLite クエリ: 選択、どこ、LIMIT、OFFSET、カウント、グループ化
⚡ スマートサマリー
SQLite クエリは、SELECT、FROM、WHERE、GROUP BY、ORDER BY、LIMIT句を使用してデータを取得およびフィルタリングします。これらの句を演算子、集計関数、サブクエリ、および集合演算と組み合わせることで、あらゆるデータからレコードを読み取り、整形し、集計することができます。 SQLite データベース。

以下のセクションでは、SELECT と FROM を使用したデータの読み込み、WHERE とその演算子を使用した行のフィルタリング、結果の順序付けと制限、集計関数、GROUP BY と HAVING、サブクエリ、集合演算、NULL の処理、CASE 式、および共通テーブル式について説明します。
書くために SQLクエリ で SQLite データベースを使用する場合は、SELECT、FROM、WHERE、GROUP BY、ORDER BY、および LIMIT 句の仕組みと使用方法を理解しておく必要があります。
このチュートリアルでは、これらの句の使い方と書き方を学びます。 SQLite 条項。
選択によるデータの読み取り
SELECT 句は、クエリを実行するために使用する主要なステートメントです。 SQLite データベース。 SELECT 句では、何を選択するかを指定します。ただし、select 句の前に、FROM 句を使用してどこからデータを選択できるかを見てみましょう。
FROM 句は、データを選択する場所を指定するために使用されます。FROM 句では、データを選択する 1 つ以上のテーブルまたはサブクエリを指定できます。これについては、チュートリアルで後ほど説明します。
以下のすべての例では、sqlite3.exe を実行し、サンプル データベースへの接続を次のように開く必要があることに注意してください。
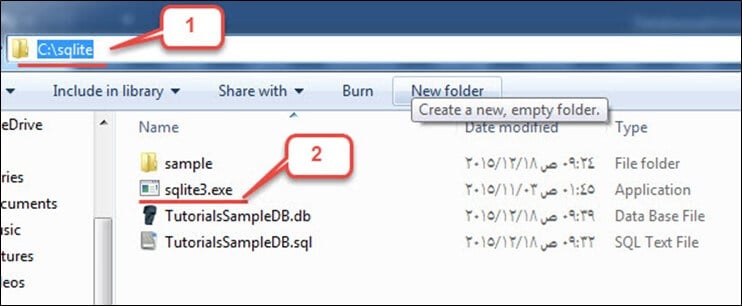
ステップ1) このステップでは、
マイコンピュータを開き、「C:\sqlite」ディレクトリに移動して、「sqlite3.exe」を開きます。
ステップ2) 以下のコマンドを使用して、「TutorialsSampleDB.db」データベースを開きます。
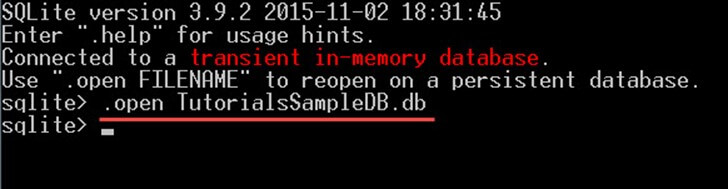
これで、データベースに対してあらゆる種類のクエリを実行する準備が整いました。
SELECT 句では、列名だけでなく、選択対象を指定するための他の多くのオプションを選択できます。次のようになります。
SELECT *
このコマンドは、FROM 句内のすべての参照テーブル (またはサブクエリ) からすべての列を選択します。 例えば:
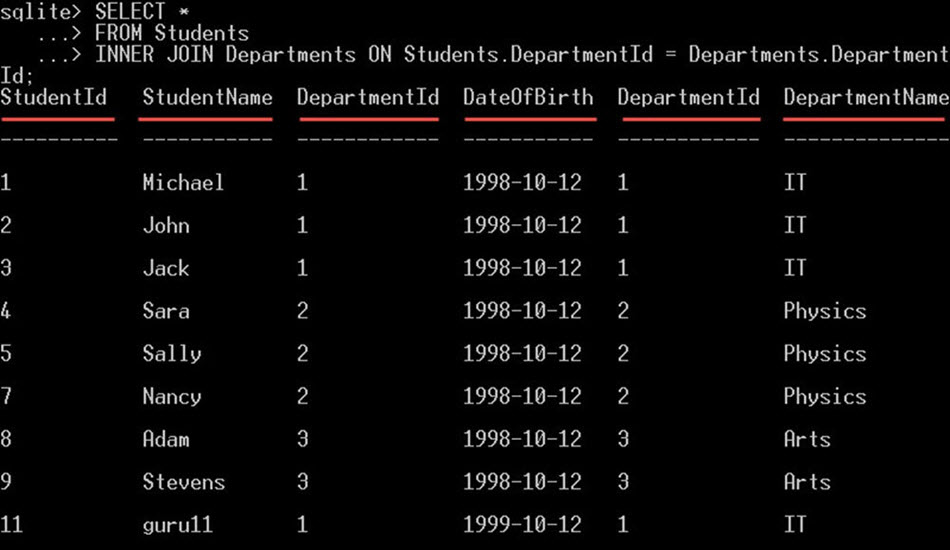
SELECT * FROM Students INNER JOIN Departments ON Students.DepartmentId = Departments.DepartmentId;
これにより、students テーブルとDepartments テーブルの両方からすべての列が選択されます。
SELECT テーブル名.*
これにより、テーブル「tablename」のみからすべての列が選択されます。 例えば:
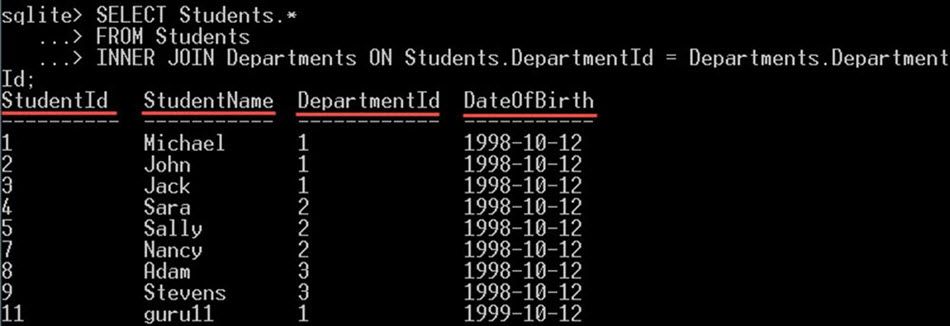
SELECT Students.* FROM Students INNER JOIN Departments ON Students.DepartmentId = Departments.DepartmentId;
これにより、students テーブルのみからすべての列が選択されます。
リテラル値
リテラル値は、SELECT ステートメントで指定できる定数値です。通常、SELECT 句で列名を使用するのと同じ方法でリテラル値を使用できます。これらのリテラル値は、SQL クエリによって返される行の各行に表示されます。
選択できるさまざまなリテラル値の例をいくつか示します。
- 数値リテラル – 1、2.55 などの任意の形式の数値。
- 文字列リテラル – 任意の文字列「USA」、「これはサンプル テキストです」など。
- NULL – NULL 値。
- Current_TIME – 現在の時刻が表示されます。
- CURRENT_DATE – 現在の日付が表示されます。
これは、返されるすべての行に対して定数値を選択する必要がある場合に便利です。 たとえば、「USA」という値を含む国という新しい列を使用して、Students テーブルからすべての学生を選択する場合は、次のように実行できます。
SELECT *, 'USA' AS Country FROM Students;
これにより、すべての生徒の列に加えて、次のような新しい列「国」が表示されます。
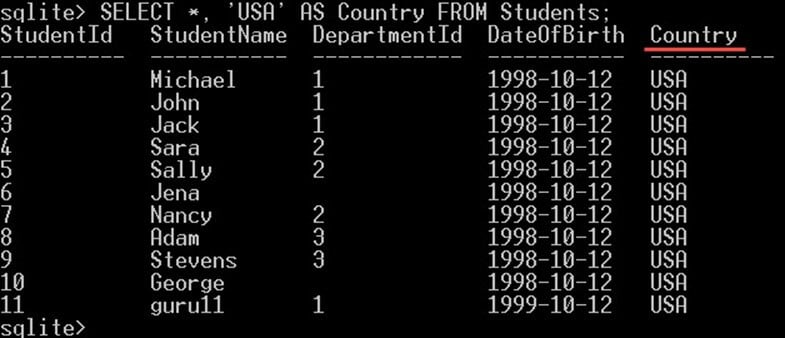
この新しい列 Country は、実際にはテーブルに追加された新しい列ではないことに注意してください。 これは結果を表示するためにクエリ内で作成される仮想列であり、テーブル上には作成されません。
名前と別名
エイリアスは列の新しい名前で、新しい名前の列を選択できるようになります。 列の別名はキーワード「AS」を使用して指定します。
たとえば、「StudentName」ではなく「Student Name」を返して StudentName 列を選択する場合は、次のようなエイリアスを付けることができます。
SELECT StudentName AS 'Student Name' FROM Students;
これにより、次のように生徒の名前が「StudentName」ではなく「Student Name」になります。

なお、列名は「StudentName」のままです。StudentName列はエイリアスによって変更されることなく、同じままです。
エイリアスによって列名は変更されません。 SELECT 句の表示名が変更されるだけです。
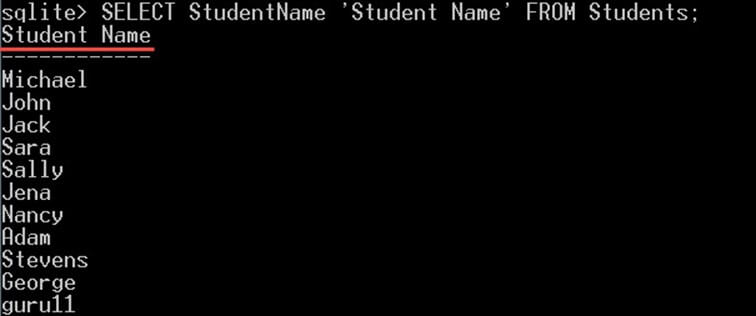
また、キーワード「AS」はオプションであることに注意してください。次のように、キーワードを省略してエイリアス名を入力できます。
SELECT StudentName 'Student Name' FROM Students;
そして、前のクエリとまったく同じ出力が得られます。
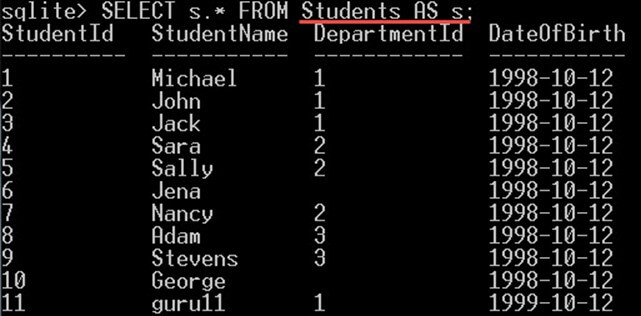
列だけでなくテーブルに別名を付けることもできます。 同じキーワード「AS」で。 たとえば、次のようにすることができます。
SELECT s.* FROM Students AS s;
これにより、テーブル Student: のすべての列が表示されます。
これは、複数のテーブルを結合する場合に非常に便利です。クエリ内で完全なテーブル名を繰り返す代わりに、各テーブルに短いエイリアス名を付けることができます。たとえば、次のクエリでは次のようになります。
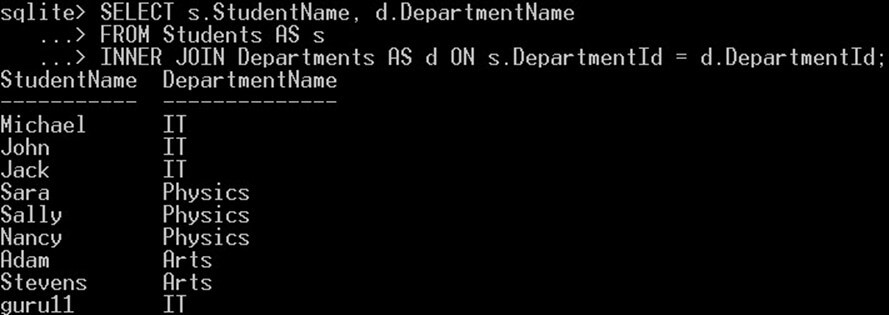
SELECT Students.StudentName, Departments.DepartmentName FROM Students INNER JOIN Departments ON Students.DepartmentId = Departments.DepartmentId;
このクエリは、「Students」テーブルから各学生の名前を選択し、「Departments」テーブルからその学部名を選択します。
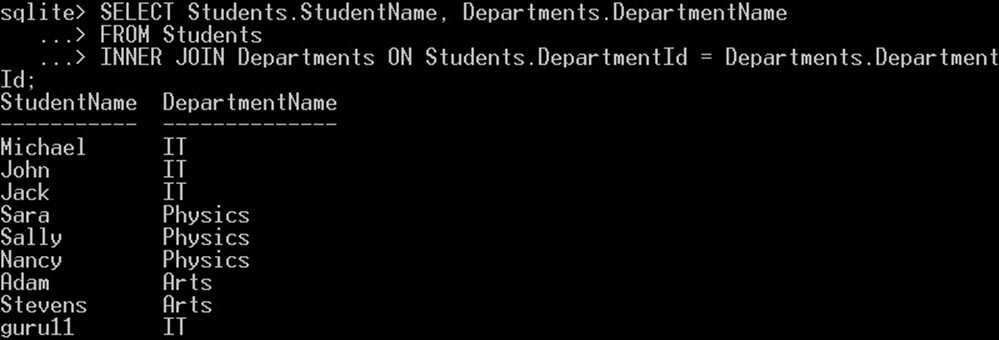
ただし、同じクエリを次のように記述することもできます。
SELECT s.StudentName, d.DepartmentName FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
学生テーブルに「s」というエイリアスを、部署テーブルに「d」というエイリアスを付けました。そして、テーブル名全体を使う代わりに、エイリアスを使って参照しました。INNER JOIN は、条件を使って 2 つ以上のテーブルを結合します。この例では、DepartmentId 列を使って学生テーブルと部署テーブルを結合しました。INNER JOIN の詳細な説明は「SQLite ジョイン」チュートリアル。
これにより、前のクエリとまったく同じ出力が得られます。
NeoCity
前のセクションで説明したように、SELECT 句と FROM 句を単独で使用して SQL クエリを作成すると、テーブルのすべての行が得られます。 ただし、返されたデータをフィルタリングする場合は、「WHERE」句を追加する必要があります。
WHERE句は、SQLクエリによって返される結果セットをフィルタリングするために使用されます。WHERE句の仕組みは次のとおりです。
- WHERE句には「式」を指定できます。
- この式は、FROM 句で指定されたテーブルから返される行ごとに評価されます。
- 式はブール式として評価され、結果は true、false、または null になります。
- その後、式が true 値で評価された行のみが返され、false または null の結果が返された行は無視され、結果セットには含まれません。
WHERE 句を使用して結果セットをフィルタリングするには、式と演算子を使用する必要があります。
演算子のリスト SQLite とそれらの使用方法
次のセクションでは、式と演算子を使用してフィルタリングする方法について説明します。
式は、演算子を使用して相互に結合された 1 つ以上のリテラル値または列です。
SELECT 句と WHERE 句の両方で式を使用できることに注意してください。
次の例では、SELECT 句と WHERE 句の両方で式と演算子を試して、そのパフォーマンスを確認します。
次のように指定できるさまざまな種類の式と演算子があります。
SQLite 連結演算子「||」
この演算子は、1 つ以上のリテラル値または列を連結するために使用されます。連結されたすべてのリテラル値または列から 1 つの結果文字列が生成されます。例:
SELECT 'Id with Name: '|| StudentId || StudentName AS StudentIdWithName FROM Students;
これは「StudentIdWithName」という新しいエイリアスに連結されます。
- リテラル文字列値「名前付きID:」
- 「StudentId」列の値と
- 「StudentName」列の値を使用して

SQLite CAST演算子:
CAST演算子は、値を変換するために使用されます。 データ・タイプ 別のデータ型に変換します。
例えば、数値が「'12.5'」のように文字列として格納されていて、それを数値に変換したい場合は、CAST演算子を使って「CAST('12.5' AS REAL)」のように記述できます。また、12.5のような小数値があり、整数部分だけを取得したい場合は、「CAST(12.5 AS INTEGER)」のように整数にキャストできます。
例:
次のコマンドでは、さまざまな値を他のデータ型に変換してみます。
SELECT CAST('12.5' AS REAL) ToReal, CAST(12.5 AS INTEGER) AS ToInteger;
これにより、次のものが得られます。

結果は以下のようになります。
- CAST('12.5' AS REAL) – 値 '12.5' は文字列値であり、REAL 値に変換されます。
- CAST(12.5 AS INTEGER) – 値 12.5 は 12 進数値であるため、整数値に変換されます。 小数点以下切り捨てとなりXNUMXとなります。
SQLite 算術 Operators:
2つ以上の数値リテラル値または数値列を取り、1つの数値を返します。 SQLite には次の値があります:
- 加算演算子「+」は、2つの演算対象の合計値を返します。
- サブtraction “–” – サブtrac2 つのオペランドを比較し、その差を返します。
- 乗算記号「*」は、2つの被演算項の積を表します。
- 剰余(剰余演算子)「%」は、一方のオペランドをもう一方のオペランドで割ったときの余りを示します。
- 除算「/」 - 左側のオペランドを右側のオペランドで割った商を返します。
例:
次の例では、同じ SELECT 句内で、リテラル数値に対して 5 つの算術演算子を試してみます。
SELECT 25+6, 25-6, 25*6, 25%6, 25/6;
これにより、次のものが得られます。

ここで FROM 句を使用せずに SELECT ステートメントを使用していることに注目してください。そして、これは許可されています SQLite リテラル値を選択している限り。
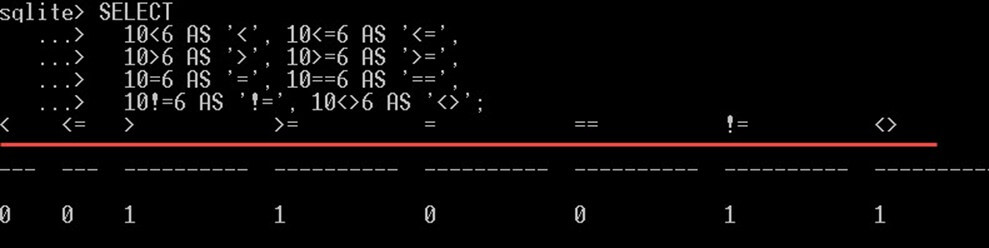
SQLite 比較演算子
次のように 2 つのオペランドを相互に比較し、true または false を返します。
- 「<」は、左オペランドが右オペランドより小さい場合にtrueを返します。
- 「<=」は、左オペランドが右オペランド以下である場合にtrueを返します。
- 「>」 – 左オペランドが右オペランドより大きい場合にtrueを返します。
- 「>=」は、左オペランドが右オペランド以上である場合にtrueを返します。
- 「=」と「==」は、2つのオペランドが等しい場合にtrueを返します。なお、これらの演算子はどちらも同じであり、違いはありません。
- 「!=」と「<>」は、2つのオペランドが等しくない場合にtrueを返します。なお、これらの演算子はどちらも同じであり、違いはありません。
ご了承ください、 SQLite 真の値を1、偽の値を0で表します。
例:
SELECT 10<6 AS '<', 10<=6 AS '<=', 10>6 AS '>', 10>=6 AS '>=', 10=6 AS '=', 10==6 AS '==', 10!=6 AS '!=', 10<>6 AS '<>';
これにより、次のような結果が得られます。
SQLite パターンマッチング演算子
「LIKE」はパターンマッチングに使用されます。「LIKE」を使用すると、ワイルドカードで指定したパターンに一致する値を検索できます。
左側のオペランドは、文字列リテラル値または文字列列のいずれかになります。パターンは次のように指定できます。
- パターンを含みます。たとえば、StudentName LIKE '%a%' と指定すると、StudentName 列の任意の位置に文字「a」が含まれる学生の名前が検索されます。
- パターンから始めます。例えば、「StudentName LIKE 'a%'」と入力すると、名前が「a」で始まる学生を検索します。
- パターンで終わります。例えば、「StudentName LIKE '%a'」のように指定すると、名前の末尾が「a」で終わる学生を検索します。
- 文字列内の任意の1文字をアンダースコア「_」で照合します。例:「StudentName LIKE 'J___'」 – 4文字の学生名を検索します。名前は「J」で始まり、「J」の後に任意の3文字が続く必要があります。
パターンマッチングの例:
「j」文字で始まる生徒の名前を取得します。
SELECT StudentName FROM Students WHERE StudentName LIKE 'j%';
結果:

「y」文字で終わる生徒の名前を取得します。
SELECT StudentName FROM Students WHERE StudentName LIKE '%y';
結果:

「n」文字を含む生徒の名前を取得します。
SELECT StudentName FROM Students WHERE StudentName LIKE '%n%';
結果:

「GLOB」はLIKE演算子と同等ですが、LIKE演算子とは異なり、大文字と小文字を区別します。例えば、次の2つのコマンドは異なる結果を返します。
SELECT 'Jack' GLOB 'j%'; SELECT 'Jack' LIKE 'j%';
これにより、次のものが得られます。

最初のステートメントは、GLOB 演算子が大文字と小文字を区別するため 0 (偽) を返します。したがって、'j' は 'J' と等しくありません。ただし、1 番目のステートメントは、LIKE 演算子が大文字と小文字を区別しないため XNUMX (真) を返します。したがって、'j' は 'J' と等しくなります。
その他のオペレーター:
SQLite そして
1 つ以上の式を組み合わせる論理演算子。すべての式が「true」値を返す場合にのみ true を返します。ただし、すべての式が「false」値を返す場合にのみ false を返します。
例:
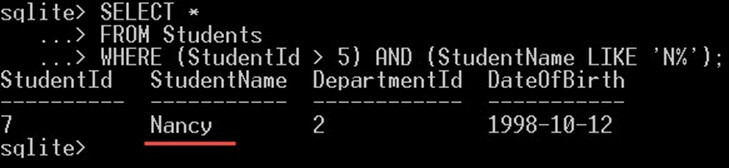
次のクエリは、StudentId > 5 を持ち、StudentName が文字 N で始まる学生を検索します。返される学生は、次の XNUMX つの条件を満たす必要があります。
SELECT * FROM Students WHERE (StudentId > 5) AND (StudentName LIKE 'N%');
出力として、上のスクリーンショットでは、「Nancy」のみが表示されます。 ナンシーは両方の条件を満たす唯一の学生です。
SQLite OR
1 つ以上の式を結合する論理演算子です。結合された演算子の 1 つが true になる場合は true を返します。ただし、すべての式が false になる場合は false を返します。
例:
次のクエリは、StudentId > 5 または StudentName が文字 N で始まる学生を検索します。返される学生は、少なくとも次の条件の XNUMX つを満たす必要があります。
SELECT * FROM Students WHERE (StudentId > 5) OR (StudentName LIKE 'N%');
これにより、次のものが得られます。
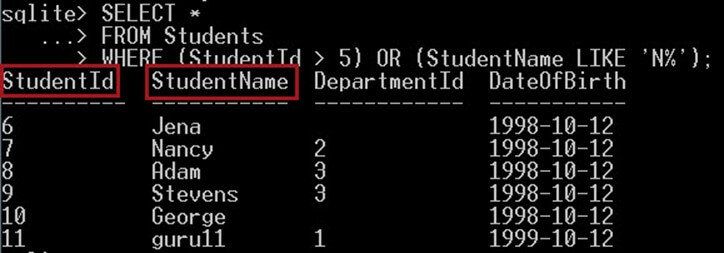
出力として、上のスクリーンショットでは、名前に文字「n」が含まれる学生の名前と、値が 5 を超える学生 ID が表示されます。
ご覧のとおり、結果は AND 演算子を使用したクエリとは異なります。
SQLite BETWEEN
BETWEEN は、2 つの値の範囲内にある値を選択するために使用されます。たとえば、「X BETWEEN Y AND Z」は、値 X が 2 つの値 Y と Z の間にある場合に true (1) を返します。そうでない場合は false (0) を返します。「X BETWEEN Y AND Z」は「X >= Y AND X <= Z」と同等で、X は Y 以上で、X は Z 以下である必要があります。
例:
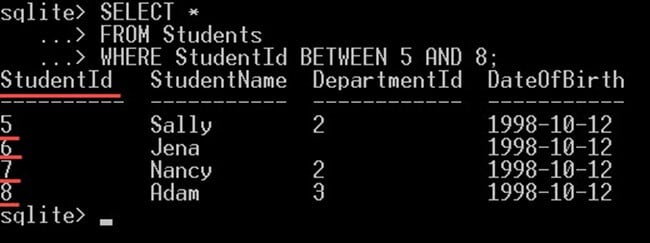
次のクエリ例では、ID 値が 5 から 8 までの学生を取得するクエリを記述します。
SELECT * FROM Students WHERE StudentId BETWEEN 5 AND 8;
これにより、ID 5、6、7、および 8 を持つ学生のみが得られます。
SQLite IN
1 つのオペランドとオペランドのリストを受け取ります。最初のオペランドの値がリスト内のオペランドの値の 0 つと等しい場合は true を返します。オペランドのリストに最初のオペランドの値が含まれている場合は、IN 演算子は true (XNUMX) を返します。それ以外の場合は false (XNUMX) を返します。
例えば「col IN(x, y, z)」のように。これは「(col=x) or (col=y) or (col=z)」と同等です。
例:
次のクエリは、ID が 2、4、6、8 の学生のみを選択します。
SELECT * FROM Students WHERE StudentId IN(2, 4, 6, 8);
いいね:

前のクエリは次のクエリとまったく同じ結果を返します。これらは同等だからです。
SELECT * FROM Students WHERE (StudentId = 2) OR (StudentId = 4) OR (StudentId = 6) OR (StudentId = 8);
どちらのクエリも正確な出力を返します。ただし、2 つのクエリの違いは、最初のクエリでは「IN」演算子を使用したことです。2 番目のクエリでは、複数の「OR」演算子を使用しました。
IN演算子は、複数のOR演算子を使用することと同等です。「WHERE StudentId IN(2, 4, 6, 8)」は、「WHERE (StudentId = 2) OR (StudentId = 4) OR (StudentId = 6) OR (StudentId = 8);」と同等です。
いいね:

SQLite ありませんで
「NOT IN」演算子は、「IN」演算子の反対です。構文は同じで、1つの演算子と演算子のリストを受け取ります。最初の演算子の値がリスト内のいずれかの演算子の値と等しくない場合、trueを返します。つまり、演算子のリストに最初の演算子が含まれていない場合は、true(0)を返します。例:「col NOT IN(x, y, z)」。これは「(col<>x) AND (cole<>y) AND (colle<>z)」と同等です。
例:
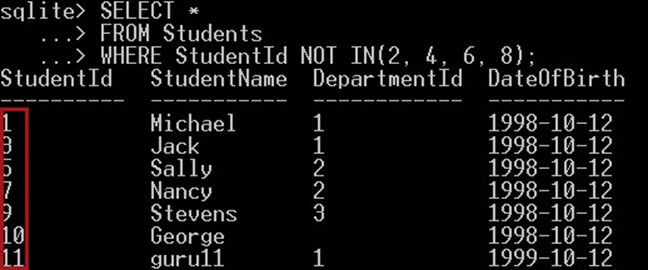
次のクエリは、ID 2、4、6、8 のいずれかと等しくない ID を持つ学生を選択します。
SELECT * FROM Students WHERE StudentId NOT IN(2, 4, 6, 8);
このような
前のクエリは同等であるため、次のクエリとまったく同じ結果が得られます。
SELECT * FROM Students WHERE (StudentId <> 2) AND (StudentId <> 4) AND (StudentId <> 6) AND (StudentId <> 8);
いいね:
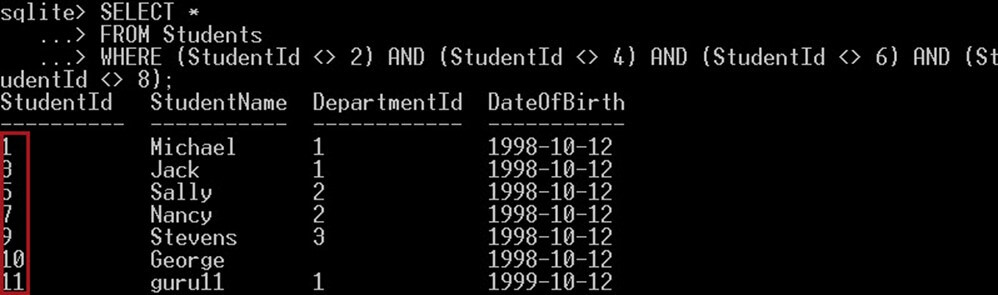
上のスクリーンショットでは、
複数の不等号演算子「<>」を使用して、次の ID 2、4、6、8 のいずれとも等しくない学生のリストを取得しました。このクエリは、これらの ID リスト以外のすべての学生を返します。
SQLite 存在する
EXISTS 演算子はオペランドを取りません。その後に SELECT 句のみを取ります。EXISTS 演算子は、SELECT 句から返された行がある場合は true (1) を返し、SELECT 句から返された行がない場合は false (0) を返します。
例:
次の例では、学生テーブルに学科 ID が存在する場合に学科名を選択します。
SELECT DepartmentName FROM Departments AS d WHERE EXISTS (SELECT DepartmentId FROM Students AS s WHERE d.DepartmentId = s.DepartmentId);
これにより、次のものが得られます。

返されるのは「IT、物理学、芸術」の3つの学科のみです。「数学」という学科名は、その学科に学生がいないため返されません。つまり、学生テーブルに学科IDが存在しないということです。そのため、EXISTS演算子は「数学」学科を無視しました。
SQLite NOT
Reverseは、その直後に続く演算子の結果です。例:
- NOT BETWEEN – BETWEEN が false を返す場合は true を返し、その逆の場合は true を返します。
- NOT LIKE – LIKE が false を返す場合は true を返し、その逆も同様です。
- NOT GLOB – GLOB が false を返す場合は true を返し、その逆も同様です。
- NOT EXISTS – EXISTS が false を返す場合は true を返し、その逆も同様です。
例:
次の例では、NOT 演算子を EXISTS 演算子と組み合わせて使用し、Students テーブルに存在しない学部名を取得します。これは、EXISTS 演算子の逆の結果です。したがって、検索は、department テーブルに存在しない DepartmentId を通じて実行されます。
SELECT DepartmentName FROM Departments AS d WHERE NOT EXISTS (SELECT DepartmentId FROM Students AS s WHERE d.DepartmentId = s.DepartmentId);
出力:

返されるのは「数学」学科のみです。「数学」学科は、学生テーブルに存在しない唯一の学科だからです。
制限と順序付け
SQLite 注文
SQLite 順序は、1 つ以上の式によって結果を並べ替えることです。結果セットを並べ替えるには、次のように ORDER BY 句を使用する必要があります。
- まず、ORDER BY 句を指定する必要があります。
- ORDER BY 句はクエリの最後に指定する必要があります。 その後に LIMIT 句のみを指定できます。
- データを並べ替える式を指定します。この式には列名または式を指定できます。
- 式の後に、オプションでソート方向を指定できます。 データを降順に並べる場合は DESC、データを昇順に並べる場合は ASC のいずれかです。 どれも指定しなかった場合、データは昇順に並べ替えられます。
- 「,」を挟んでさらに多くの式を指定できます。
例:
次の例では、名前の降順で並べられたすべての学生を選択し、次に学部名の昇順で並べられたすべての学生を選択します。
SELECT s.StudentName, d.DepartmentName FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId ORDER BY d.DepartmentName ASC , s.StudentName DESC;
これにより、次のものが得られます。
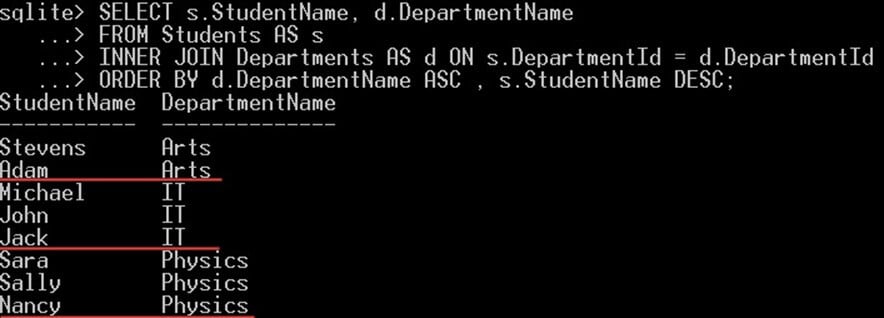
- SQLite まず、すべての学生を学部名で昇順に並べます
- 次に、各学部名ごとに、その学部名に属するすべての学生が名前の降順で表示されます。
SQLite 制限:
LIMIT 句を使用すると、SQL クエリによって返される行数を制限できます。 たとえば、LIMIT 10 では 10 行のみが表示され、他の行はすべて無視されます。
LIMIT句では、OFFSET句を使用して、特定の位置から始まる特定の行数を選択できます。たとえば、「LIMIT 4 OFFSET 4」は最初の4行を無視し、5行目から始まる4行を返します。つまり、5行目、6行目、7行目、8行目が取得されます。
OFFSET句は省略可能です。「LIMIT 4, 4」のように記述しても、正確な結果が得られます。
例:
次の例では、クエリを使用して、学生 ID 3 から始まる 5 人の学生のみを返します。
SELECT * FROM Students LIMIT 4,3;
これにより、行 5 から始まる 5 人の学生のみが得られます。つまり、StudentId が 6、7、および XNUMX の行が得られます。

重複を削除する
SQLクエリで重複する値が返される場合は、「DISTINCT」キーワードを使用して重複を削除し、重複のない値のみを返すことができます。DISTINCTキーワードの後に複数の列を指定することも可能です。
例:
次のクエリは重複した「部門名の値」を返します。ここでは、IT、Physics、Arts という名前の重複した値があります。
SELECT d.DepartmentName FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
これにより、部門名の重複した値が得られます。
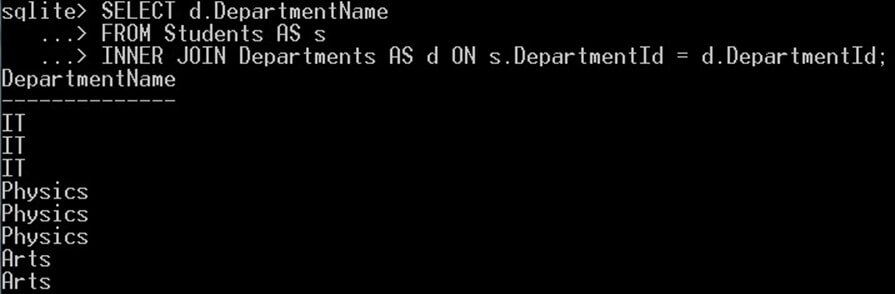
部門名の値が重複していることに注目してください。 ここで、同じクエリで DISTINCT キーワードを使用して、重複を削除し、一意の値のみを取得します。 このような:
SELECT DISTINCT d.DepartmentName FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
これにより、部門名列には次の XNUMX つの一意の値のみが得られます。
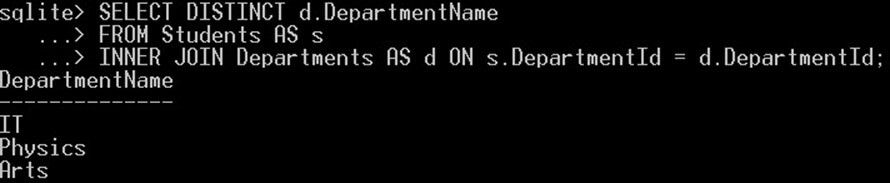
集計
SQLite 集計は、で定義された組み込み関数です。 SQLite これは、複数の行の複数の値を 1 つの値にグループ化します。
でサポートされている集計は次のとおりです。 SQLite:
SQLite AVG()
すべての x 値の平均を返します。
例:
次の例では、すべての試験で学生が得る平均点数を取得します。
SELECT AVG(Mark) FROM Marks;
これにより、値「18.375」が得られます。

これらの結果は、すべてのマーク値の合計をそのカウントで割ったものから得られます。
COUNT() – COUNT(X) または COUNT(*)
x 値が出現した回数の合計を返します。 COUNT で使用できるオプションをいくつか示します。
- COUNT(x): x 値のみをカウントします (x は列名です)。 NULL 値は無視されます。
- COUNT(*): すべての列のすべての行をカウントします。
- COUNT (DISTINCT x): x の前に DISTINCT キーワードを指定すると、x の個別の値の数を取得できます。
例:
次の例では、COUNT(DepartmentId)、COUNT(*)、COUNT(DISTINCT DepartmentId) を使用して部門の合計数を取得し、それらの違いを調べます。
SELECT COUNT(DepartmentId), COUNT(DISTINCT DepartmentId), COUNT(*) FROM Students;
これにより、次のものが得られます。

以下の通りです:
- COUNT(DepartmentId) はすべての部門 ID の数を示し、NULL 値は無視されます。
- COUNT(DISTINCTDepartmentId) では、DepartmentId の個別の値が得られます。これは 3 つだけです。これは、部門名の 8 つの異なる値です。 学生名には学部名の値が XNUMX つあることに注意してください。 ただし、異なるのは数学、IT、物理の XNUMX つの値だけです。
- COUNT(*) は、students テーブル内の行数をカウントします。これは、10 人の生徒に対して 10 行です。
GROUP_CONCAT() – GROUP_CONCAT(X) または GROUP_CONCAT(X,Y)
GROUP_CONCAT 集計関数は、複数の値をコンマで区切って 1 つの値に連結します。次のオプションがあります。
- GROUP_CONCAT(X): これは、x のすべての値を XNUMX つの文字列に連結します。カンマ「,」は値の間の区切り文字として使用されます。 NULL 値は無視されます。
- GROUP_CONCAT(X, Y): これにより、x の値が XNUMX つの文字列に連結され、デフォルトの区切り文字「,」の代わりに y の値が各値の間の区切り文字として使用されます。 NULL 値も無視されます。
- GROUP_CONCAT(DISTINCT X): これは、値の間の区切り文字としてカンマ「,」を使用して、x のすべての個別の値を XNUMX つの文字列に連結します。 NULL 値は無視されます。
GROUP_CONCAT(部門名) の例
次のクエリは、学生テーブルと部門テーブルのすべての部門名の値を、コンマで区切られた 1 つの文字列に連結します。したがって、値のリストを返すのではなく、各行に 1 つの値を返します。すべての値がコンマで区切られた状態で、1 行に 1 つの値のみが返されます。
SELECT GROUP_CONCAT(d.DepartmentName) FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
これにより、次のものが得られます。

これにより、8 つの部門名の値がカンマ区切りの XNUMX つの文字列に連結されたリストが得られます。
GROUP_CONCAT(DISTINCT 部門名) の例
次のクエリは、学生テーブルと部門テーブルの部門名の個別の値を、コンマで区切られた 1 つの文字列に連結します。
SELECT GROUP_CONCAT(DISTINCT d.DepartmentName) FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
これにより、次のものが得られます。

結果が前の結果とどのように異なるかに注目してください。 異なる部門名である XNUMX つの値のみが返され、重複する値は削除されました。
GROUP_CONCAT(部門名 ,'&') の例
次のクエリは、学生テーブルと部門テーブルの部門名列のすべての値を 1 つの文字列に連結しますが、区切り文字としてコンマではなく文字「&」を使用します。
SELECT GROUP_CONCAT(d.DepartmentName, '&') FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
これにより、次のものが得られます。

値の間を区切るために、デフォルトの文字「,」の代わりに文字「&」がどのように使用されているかに注目してください。
SQLite MAX() & MIN()
MAX(X) は、X 値の最大値を返します。 x のすべての値が null の場合、MAX は NULL 値を返します。 一方、MIN(X) は X 値から最小値を返します。 X のすべての値が null の場合、MIN は NULL 値を返します。
例:
次のクエリでは、MIN関数とMAX関数を使用して、「Marks」テーブルから最高点と最低点を取得します。
SELECT MAX(Mark), MIN(Mark) FROM Marks;
これにより、次のものが得られます。

SQLite 合計(x)、合計(x)
どちらもすべての x 値の合計を返します。ただし、次の点で異なります。
- すべての値が null の場合、SUM は null を返しますが、Total は 0 を返します。
- TOTAL は常に浮動小数点値を返します。 すべての x 値が整数の場合、SUM は整数値を返します。 ただし、値が整数でない場合は、浮動小数点値が返されます。
例:
次のクエリでは、SUM関数とtotal関数を使用して、「Marks」テーブル内のすべての点数の合計を取得します。
SELECT SUM(Mark), TOTAL(Mark) FROM Marks;
これにより、次のものが得られます。

ご覧のとおり、TOTAL は常に浮動小数点を返します。 ただし、「マーク」列の値が整数である可能性があるため、SUM は整数値を返します。
SUM と TOTAL の違いの例:
次のクエリでは、NULL 値の合計を取得する場合の SUM と TOTAL の違いを示します。
SELECT SUM(Mark), TOTAL(Mark) FROM Marks WHERE TestId = 4;
これにより、次のものが得られます。

TestId = 4 にはマークがないため、そのテストには null 値が存在することに注意してください。 SUM は null 値を空白として返しますが、TOTAL は 0 を返します。
グループBY
GROUP BY 句は、行をグループにグループ化するために使用される XNUMX つ以上の列を指定するために使用されます。 同じ値を持つ行がグループに集められます (配置されます)。
グループ化列に含まれない他の列については、集計関数を使用できます。
例:
次のクエリを実行すると、各学部に在籍する学生の総数がわかります。
SELECT d.DepartmentName, COUNT(s.StudentId) AS StudentsCount FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId GROUP BY d. DepartmentName;
これにより、次のものが得られます。
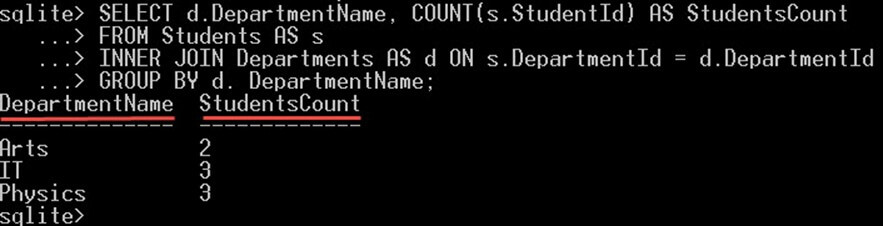
GROUPBYDepartmentName 句は、すべての学生を学部名ごとに XNUMX つのグループにグループ化します。 「学科」のグループごとに、そのグループの学生をカウントします。
HAVING 句
GROUP BY 句によって返されるグループをフィルタリングする場合は、GROUP BY の後の式で「HAVING」句を指定できます。 この式は、これらのグループをフィルタリングするために使用されます。
例:
次のクエリでは、学生が 2 人だけいる学部を選択します。
SELECT d.DepartmentName, COUNT(s.StudentId) AS StudentsCount FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId GROUP BY d. DepartmentName HAVING COUNT(s.StudentId) = 2;
これにより、次のものが得られます。
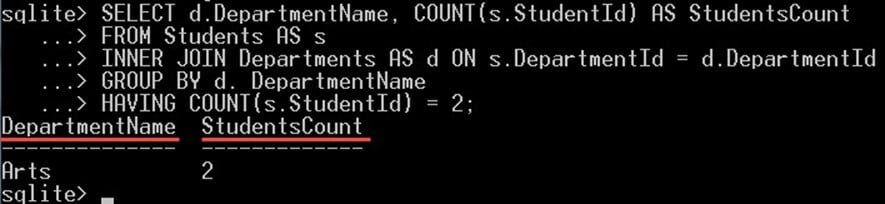
HAVING COUNT(S.StudentId) = 2 という句は、返されるグループをフィルターし、ちょうど 2 人の学生を含むグループのみを返します。この場合、芸術学部には XNUMX 人の学生がいるので、出力に表示されます。
SQLite クエリとサブクエリ
任意のクエリ内で、SELECT、INSERT、DELETE、UPDATE、または別のサブクエリ内で別のクエリを使用できます。
この入れ子になったクエリはサブクエリと呼ばれます。 次に、SELECT 句でサブクエリを使用する例をいくつか見ていきます。 ただし、データの変更チュートリアルでは、INSERT、DELETE、および UPDATE ステートメントでサブクエリを使用する方法を説明します。
FROM 句の例でのサブクエリの使用
次のクエリでは、FROM 句内にサブクエリを含めます。
SELECT s.StudentName, t.Mark FROM Students AS s INNER JOIN ( SELECT StudentId, Mark FROM Tests AS t INNER JOIN Marks AS m ON t.TestId = m.TestId ) ON s.StudentId = t.StudentId;
クエリ:
SELECT StudentId, Mark FROM Tests AS t INNER JOIN Marks AS m ON t.TestId = m.TestId
上記のクエリは FROM 句内にネストされているため、ここではサブクエリと呼ばれます。 クエリ内で返された列を参照できるように、エイリアス名「t」を付けていることに注意してください。
このクエリにより次のことが得られます。
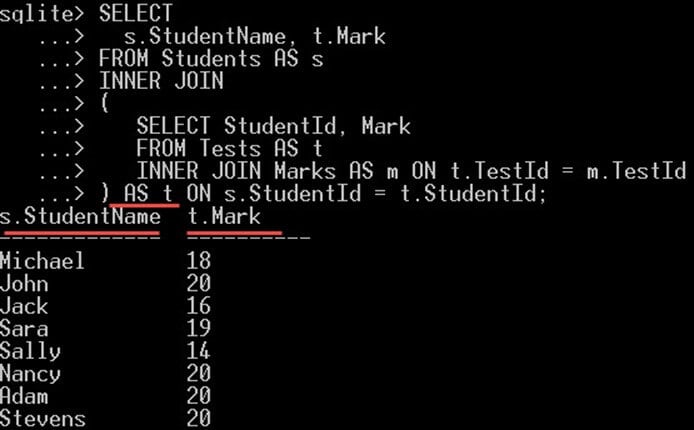
したがって、私たちの場合、
- s.StudentName は、学生の名前を与えるメイン クエリから選択され、
- t.Mark はサブクエリから選択されます。 これらの各生徒が取得した得点を示します
WHERE 句でのサブクエリの使用例
次のクエリでは、WHERE 句にサブクエリを含めます。
SELECT DepartmentName FROM Departments AS d WHERE NOT EXISTS (SELECT DepartmentId FROM Students AS s WHERE d.DepartmentId = s.DepartmentId);
クエリ:
SELECT DepartmentId FROM Students AS s WHERE d.DepartmentId = s.DepartmentId
上記のクエリは、WHERE 句にネストされているため、ここではサブクエリと呼ばれます。サブクエリは、演算子 NOT EXISTS によって使用される DepartmentId 値を返します。
このクエリにより次のことが得られます。
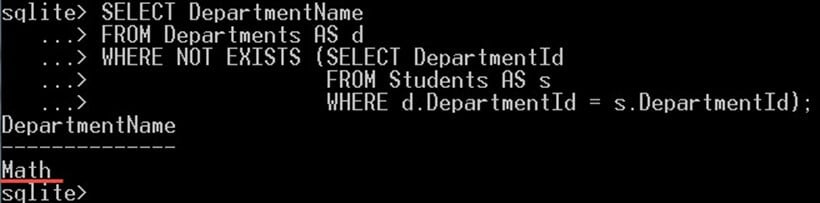
上記のクエリでは、学生が在籍していない学部を選択しました。 ここの「数学」部門です。
作成セッションプロセスで Operaション – UNION、交差
SQLite 次の SET 操作をサポートします。
ユニオン&ユニオンオール
複数の SELECT ステートメントから返された XNUMX つ以上の結果セット (行のグループ) を XNUMX つの結果セットに結合します。
UNION は個別の値を返します。 ただし、UNION ALL は重複を含まず、重複も含めます。
列名は最初の SELECT ステートメントで指定した列名になることに注意してください。
UNION の例
次の例では、students テーブルから DepartmentId のリストを取得し、departments テーブルから DepartmentId のリストを同じ列で取得します。
SELECT DepartmentId AS DepartmentIdUnioned FROM Students UNION SELECT DepartmentId FROM Departments;
これにより、次のものが得られます。
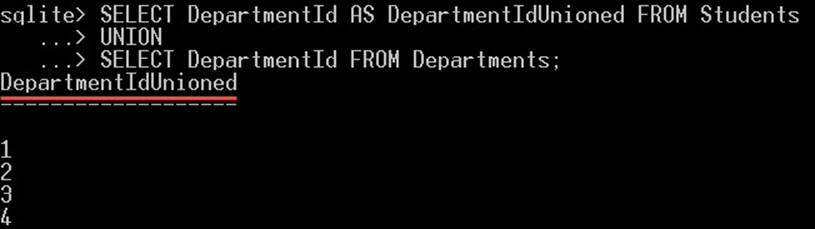
このクエリは、個別の部門 ID 値である 5 行のみを返します。 最初の値が null 値であることに注目してください。
SQLite UNION ALL の例
次の例では、students テーブルから DepartmentId のリストを取得し、departments テーブルから DepartmentId のリストを同じ列で取得します。
SELECT DepartmentId AS DepartmentIdUnioned FROM Students UNION ALL SELECT DepartmentId FROM Departments;
これにより、次のものが得られます。
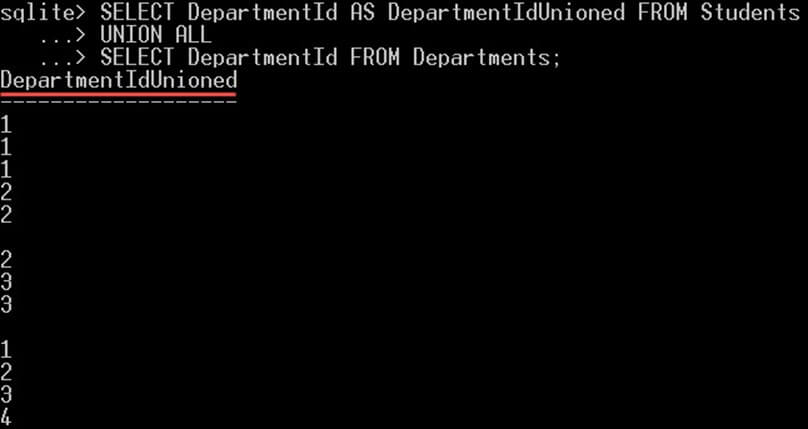
クエリは 14 行を返します。そのうち 10 行はstudents テーブルから、4 行はDepartments テーブルから返されます。 返される値には重複があることに注意してください。 また、列名が最初の SELECT ステートメントで指定されたものであることに注意してください。
ここで、UNION ALL を UNION に置き換えた場合に、UNION all がどのような異なる結果をもたらすかを見てみましょう。
SQLite 交差する
結合された結果セットの両方に存在する値を返します。 結合された結果セットのいずれかに存在する値は無視されます。
例:
次のクエリでは、DepartmentId 列の Students テーブルと Departments テーブルの両方に存在する DepartmentId 値を選択します。
SELECT DepartmentId FROM Students Intersect SELECT DepartmentId FROM Departments;
これにより、次のものが得られます。
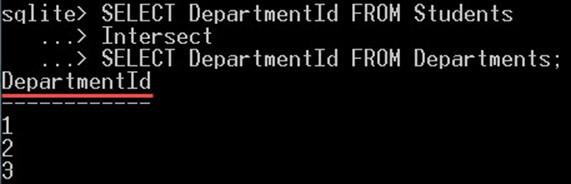
クエリは 1 つの値 2、3、および XNUMX のみを返します。これらの値は両方のテーブルに存在します。
ただし、値 null と 4 は含まれませんでした。これは、null 値はstudents テーブルにのみ存在し、Departments テーブルには存在しないためです。 そして、値 4 は、students テーブルではなく、Departments テーブルに存在します。
そのため、値 NULL と 4 は両方とも無視され、戻り値に含まれませんでした。
例外
たとえば、行のリストが 1 つ (list2 と list1) あり、list2 から list1 に存在しない行だけを取得したい場合、「EXCEPT」句を使用できます。EXCEPT 句は 2 つのリストを比較し、listXNUMX に存在し、listXNUMX に存在しない行を返します。
例:
次のクエリでは、departments テーブルに存在し、students テーブルには存在しない DepartmentId 値を選択します。
SELECT DepartmentId FROM Departments EXCEPT SELECT DepartmentId FROM Students;
これにより、次のものが得られます。

クエリは値 4 のみを返します。これは、Departments テーブルに存在する唯一の値であり、students テーブルには存在しません。
NULLの処理
「NULL」値は特別な値です SQLiteこれは、不明な値または欠落した値を表すために使用されます。null値は「0」や空白「」とは全く異なることに注意してください。0と空白は既知の値ですが、null値は不明です。
NULL 値には特別な処理が必要です SQLite, 次に、NULL 値を処理する方法を見ていきます。
NULL値を検索する
通常の等価演算子 (=) を使用して null 値を検索することはできません。たとえば、次のクエリは、DepartmentId 値が null である学生を検索します。
SELECT * FROM Students WHERE DepartmentId = NULL;
このクエリでは結果が得られません。
![]()
NULL 値は、NULL 値自体を含む他の値と等しくないため、結果が返されませんでした。
ただし、クエリを正しく機能させるには、次のように「IS NULL」演算子を使用してNULL値を検索する必要があります。
SELECT * FROM Students WHERE DepartmentId IS NULL;
これにより、次のものが得られます。

クエリは、DepartmentId 値が null の学生を返します。
nullではない値を取得したい場合は、次のように「IS NOT NULL」演算子を使用する必要があります。
SELECT * FROM Students WHERE DepartmentId IS NOT NULL;
これにより、次のものが得られます。
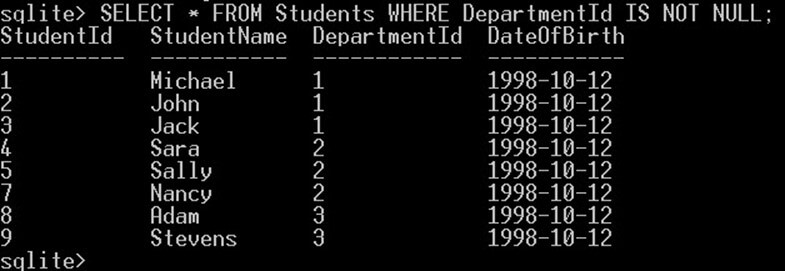
クエリは、NULL のDepartmentId 値を持たない学生を返します。
条件付き結果
値のリストがあり、いくつかの条件に基づいてそれらのいずれかを選択したい場合。 そのため、選択するには、その特定の値の条件が true である必要があります。
CASE 式は、すべての値に対してこれらの条件リストを評価します。 条件が true の場合、その値が返されます。
たとえば、「Grade」という列があり、次のように成績値に基づいてテキスト値を選択する場合:
– グレードが 85 を超える場合は「優秀」。
– グレードが 70 ~ 85 の場合は「非常に良い」。
– 評定が 60 ~ 70 の場合は「良好」。
その後、CASE 式を使用してそれを行うことができます。
これを使用して SELECT 句でロジックを定義すると、たとえば if ステートメントなどの特定の条件に応じて特定の結果を選択できます。
CASE 演算子は、次のようにさまざまな構文で定義できます。
さまざまな条件を使用できます。
CASE WHEN condition1 THEN result1 WHEN condition2 THEN result2 WHEN condition3 THEN result3 … ELSE resultn END
または、式を XNUMX つだけ使用し、選択できるさまざまな値を入力することもできます。
CASE expression WHEN value1 THEN result1 WHEN value2 THEN result2 WHEN value3 THEN result3 … ELSE restuln END
ELSE 句はオプションであることに注意してください。
例:
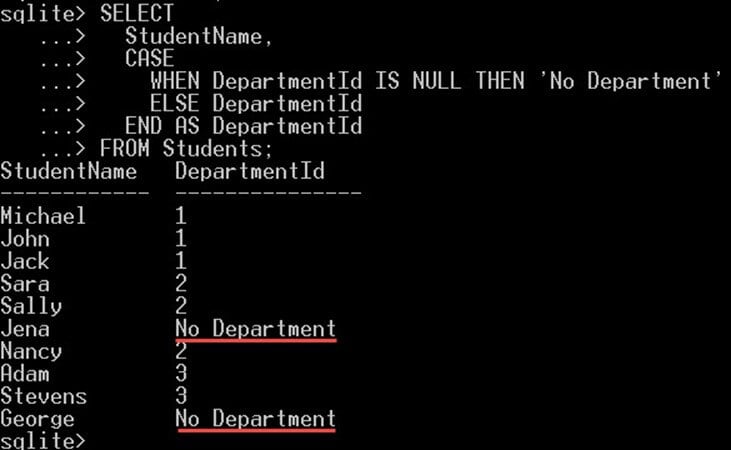
次の例では、Students テーブルの department Id 列に NULL 値を指定して CASE 式を使用し、次のように「No Department」というテキストを表示します。
SELECT StudentName, CASE WHEN DepartmentId IS NULL THEN 'No Department' ELSE DepartmentId END AS DepartmentId FROM Students;
- CASE 演算子は、DepartmentId の値が null かどうかをチェックします。
- NULL 値の場合は、DepartmentId 値の代わりにリテラル値「NoDepartment」が選択されます。
- が null 値でない場合は、DepartmentId 列の値が選択されます。
これにより、以下に示すような出力が得られます。
共通テーブル式
共通テーブル式 (CTE) は、指定された名前を持つ SQL ステートメント内で定義されるサブクエリです。
SQL ステートメントから定義され、クエリの読み取り、保守、理解が容易になるため、サブクエリよりも利点があります。
共通テーブル式は、次のように SELECT ステートメントの前に WITH 句を置くことで定義できます。
WITH CTEname AS ( SELECT statement ) SELECT, UPDATE, INSERT, or update statement here FROM CTE
「CTEname」は、CTEに任意の名前を付けることができ、後で参照する際に使用できます。なお、CTEにはSELECT、UPDATE、INSERT、またはDELETEステートメントを定義できます。
次に、SELECT 句で CTE を使用する方法の例を見てみましょう。
例:
次の例では、SELECT ステートメントから CTE を定義し、後で別のクエリでそれを使用します。
WITH AllDepartments AS ( SELECT DepartmentId, DepartmentName FROM Departments ) SELECT s.StudentId, s.StudentName, a.DepartmentName FROM Students AS s INNER JOIN AllDepartments AS a ON s.DepartmentId = a.DepartmentId;
このクエリでは、CTEを定義し、「AllDepartments」という名前を付けました。このCTEは、SELECTクエリから定義されました。
SELECT DepartmentId, DepartmentName FROM Departments
次に、CTE を定義した後、その後に続く SELECT クエリでそれを使用しました。
共通テーブル式はクエリの出力に影響を与えないことに注意してください。 これは、同じクエリ内で再利用するために論理ビューまたはサブクエリを定義する方法です。 共通テーブル式は、宣言した変数のようなもので、サブクエリとして再利用します。 SELECT ステートメントのみがクエリの出力に影響します。
このクエリにより次のことが得られます。

高度なクエリ
高度なクエリとは、複雑な結合、サブクエリ、および一部の集計を含むクエリです。次のセクションでは、高度なクエリの例を示します。
どこで手に入れるかというと、
- 学科名と各学科の学生全員
- 学生名をカンマで区切って入力します
- 少なくとも3人の学生が在籍している学科を示す
SELECT d.DepartmentName, COUNT(s.StudentId) StudentsCount, GROUP_CONCAT(StudentName) AS Students FROM Departments AS d INNER JOIN Students AS s ON s.DepartmentId = d.DepartmentId GROUP BY d.DepartmentName HAVING COUNT(s.StudentId) >= 3;
DepartmentsテーブルからDepartmentNameを取得するためにJOIN句を追加しました。その後、2つの集計関数を含むGROUP BY句を追加しました。
- 「COUNT」は学科グループごとに学生数をカウントします。
- GROUP_CONCAT は、各グループの学生を XNUMX つの文字列でカンマ区切りで連結します。
GROUP BY の後で、HAVING 句を使用して学部をフィルタリングし、少なくとも 3 人の学生がいる学部のみを選択しました。
結果は次のようになります。
