Rにおける重回帰分析:単純回帰とステップワイズ回帰(例付き)
⚡ スマートサマリー
Rにおける単回帰分析と重回帰分析では、連続的な結果を、最小二乗法で適合させた予測変数の加重和としてモデル化します。このチュートリアルでは、lm()関数、係数の読み取り、因子予測変数、残差診断、予測、および自動変数選択について説明します。

機械学習における線形回帰の位置づけ
線形回帰は最も古い教師あり学習手法の1つです。 機械学習 アルゴリズムであり、今でもほとんどのアナリストが最初に頼るモデルです。最も初期の機械学習アプリケーションの1つは、 スパムフィルタ.
機械学習のその他の一般的な応用例としては、以下のようなものがある。
- 電子メール内の不要なスパムメッセージの識別
- ターゲットを絞った広告のための顧客行動のセグメント化
- 不正なクレジットカード取引の削減
- 住宅およびオフィスビルにおけるエネルギー利用の最適化
- 顔認識
教師あり学習
In 教師あり学習、アルゴリズムにフィードするトレーニング データにはラベルが含まれます。
欠陥種類の識別 はおそらく最も広く使われている教師あり学習手法でしょう。研究者が最初に取り組んだ分類タスクの一つがスパムフィルターでした。学習の目的は、メールがスパムかハム(正常なメール)かを予測することです。トレーニング後、機械はメールの種類を検出できるようになります。
回帰 は、機械学習分野で連続値を予測するためによく使用されます。回帰タスクは、 従属変数 のセットに基づいて 独立変数 (予測変数またはリグレッサーとも呼ばれます)。 たとえば、線形回帰は株価、天気予報、売上などを予測できます。
基本的な教師あり学習アルゴリズムには以下のようなものがあります。
- 線形回帰
- ロジスティック回帰
- 最近傍
- サポートベクターマシン(SVM)
- ディシジョン ツリーとランダム フォレスト
- ニューラルネットワーク
教師なし学習
In 教師なし学習、トレーニング データにはラベルが付いていません。システムは参照なしで学習しようとします。以下は、教師なし学習アルゴリズムの一覧です。
- K平均
- 階層的 Cluster 分析
- 期待の最大化
- 可視化と次元削減
- 主成分分析
- カーネルPCA
- 局所線形埋め込み
こうした背景を踏まえ、このチュートリアルの残りの部分では、R言語を用いて回帰モデルを段階的に構築していきます。
R での単純線形回帰
線形回帰は、ある目的変数と一連の予測変数との間の正確な関係を測定できるか、という単純な問いに答えるものです。
最も単純な確率モデルは直線モデルである。
![]()
コラボレー
- y = 従属変数
- x = 独立変数
-
 = ランダム誤差成分
= ランダム誤差成分 -
 = インターセプト
= インターセプト -
 = x の係数
= x の係数
次のプロットを考えてみましょう。
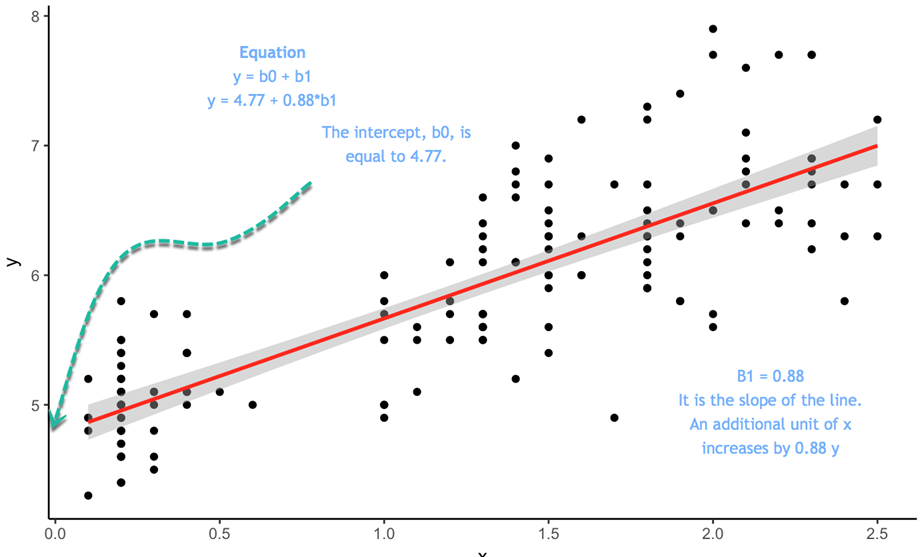
方程式は ![]() この方程式では切片が4.77なので、xが0のときのyの近似値は4.77です。傾きは、xが変化したときにyがどの程度の割合で変化するかを示します。
この方程式では切片が4.77なので、xが0のときのyの近似値は4.77です。傾きは、xが変化したときにyがどの程度の割合で変化するかを示します。
の最適値を推定するには、 ![]() (NAIST) と
(NAIST) と ![]() というメソッドを使います。 正規最小二乗(OLS)。 この方法では、二乗誤差の合計、つまり予測された y 値と実際の y 値の間の垂直距離を最小化するパラメーターを見つけようとします。 その違いは次のように知られています。 誤差項.
というメソッドを使います。 正規最小二乗(OLS)。 この方法では、二乗誤差の合計、つまり予測された y 値と実際の y 値の間の垂直距離を最小化するパラメーターを見つけようとします。 その違いは次のように知られています。 誤差項.
モデルを推定する前に、散布図をプロットすることで、y と x の間の線形関係が妥当かどうかを判断できます。
散布図
非常に単純なデータセットを使用して、単純な線形回帰の概念を説明します。 アメリカ人女性の平均身長と体重をインポートします。 データセットには 15 個の観測値が含まれています。 身長が体重と正の相関があるかどうかを測定したいと考えています。
library(ggplot2) path <- 'https://raw.githubusercontent.com/guru99-edu/R-Programming/master/women.csv' df <-read.csv(path) ggplot(df,aes(x=height, y = weight))+ geom_point()
出力:

散布図は、身長が伸びるにつれて体重が増加するという一般的な傾向を示しています。次のステップでは、身長が1単位増えるごとに体重がどれだけ増加するかを測定します。
最小二乗推定
単純な OLS 回帰では、次の計算が行われます。 ![]() (NAIST) と
(NAIST) と ![]() これは簡単です。このチュートリアルでは公式を導出するのではなく、公式を示すだけです。
これは簡単です。このチュートリアルでは公式を導出するのではなく、公式を示すだけです。
推定したいのは次のとおりです。 ![]()
OLS 回帰の目的は、次の式を最小化することです。
![]()
コラボレー
![]() は実際の値であり、
は実際の値であり、 ![]() は予測値です。
は予測値です。
の解決策 ![]() is
is ![]()
注意してください ![]() xの平均値を意味します
xの平均値を意味します
の解決策 ![]() is
is ![]()
Rでは、cov()関数とvar()関数を使用して推定できます。 ![]() そして、mean()関数を使用して推定することができます
そして、mean()関数を使用して推定することができます ![]()
beta <- cov(df$height, df$weight) / var (df$height) beta
出力:
##[1] 3.45
alpha <- mean(df$weight) - beta * mean(df$height) alpha
出力:
## [1] -87.51667
ベータ係数は、身長が1インチ増えるごとに、平均体重が3.45ポンド増加することを意味する。
線形方程式を手計算で推定することは、勉強にはなるが、実用的ではない。 R は、それを自動的に実行してくれるlm()関数を提供しており、次のセクション以降はこの関数を使用します。実際のプロジェクトでは、単一の予測変数モデルを適合させることはほとんどありません。回帰タスクでは通常、複数の推定変数が同時に使用されます。
R での重線形回帰
回帰分析の実践的な応用では、単純な直線モデルよりも複雑なモデルが使用されます。複数の独立変数を含む確率モデルは、 重回帰モデル。 このモデルの一般的な形式は次のとおりです。
![]()
行列表記では、モデルを書き換えることができます。
従属変数 y は、k 個の独立変数の関数になります。 係数の値 ![]() 独立変数の寄与を決定します
独立変数の寄与を決定します ![]() (NAIST) と
(NAIST) と ![]() .
.
ランダムエラーについて立てた仮定を簡単に紹介します。 ![]() OLS の:
OLS の:
- 平均は0に等しい
- に等しい分散

- 正規分布
- ランダムエラーは(確率的な意味で)独立しています。
を解決する必要があります ![]() 、予測された y 値と実際の y 値の間の二乗誤差の合計を最小化する回帰係数のベクトル。
、予測された y 値と実際の y 値の間の二乗誤差の合計を最小化する回帰係数のベクトル。
閉じた形式の解決策は次のとおりです。
![]()
と:
- を示します 転置 行列 X の
 を示します 可逆行列
を示します 可逆行列
以下の例では、組み込みのmtcarsデータセットを使用します。目的は、一連の特徴量から燃費(マイル/ガロン、mpg)を予測することです。
R の連続変数
今のところ、連続変数のみを使用し、カテゴリ特性は脇に置いておきます。変数 am は、トランスミッションがマニュアルの場合は 1、オートマチック車の場合は 0 の値を取るバイナリ変数です。vs もバイナリ変数です。
library(dplyr) df <- mtcars %>% select(-c(am, vs, cyl, gear, carb)) glimpse(df)
出力:
## Observations: 32 ## Variables: 6 ## $ mpg <dbl> 21.0, 21.0, 22.8, 21.4, 18.7, 18.1, 14.3, 24.4, 22.8, 19.... ## $ disp <dbl> 160.0, 160.0, 108.0, 258.0, 360.0, 225.0, 360.0, 146.7, 1... ## $ hp <dbl> 110, 110, 93, 110, 175, 105, 245, 62, 95, 123, 123, 180, ... ## $ drat <dbl> 3.90, 3.90, 3.85, 3.08, 3.15, 2.76, 3.21, 3.69, 3.92, 3.9... ## $ wt <dbl> 2.620, 2.875, 2.320, 3.215, 3.440, 3.460, 3.570, 3.190, 3... ## $ qsec <dbl> 16.46, 17.02, 18.61, 19.44, 17.02, 20.22, 15.84, 20.00, 2...
lm() 関数を使用してパラメータを計算できます。 この関数の基本的な構文は次のとおりです。
lm(formula, data, subset)
Arguments:
-formula: The equation you want to estimate
-data: The dataset used
-subset: Estimate the model on a subset of the dataset
方程式は次の形式であることを覚えておいてください
![]()
Rで
- 記号 = は ~ に置き換えられます
- 各 x は変数名に置き換えられます
- 定数を削除したい場合は、式の最後に -1 を追加します。
例:
身長と収入に基づいて個人の体重を推定したいと考えています。 方程式は
![]()
R の方程式は次のように記述されます。
y ~ X1+ X2+…+Xn # 切片あり
したがって、私たちの例では次のようになります。
- 体重〜身長+収入
目的は、一連の変数に基づいてガロンあたりのマイルを推定することです。 推定する方程式は次のとおりです。
![]()
最初の線形回帰を推定し、その結果を当てはめオブジェクトに保存します。
model <- mpg ~ disp + hp + drat + wt + qsec
fit <- lm(model, df)
fit
Code 説明
- model <- mpg ~ disp + hp + drat + wt + qsec: 推定するモデルを保存します
- lm(model, df): データフレーム df を使用してモデルを推定します。
## ## Call: ## lm(formula = model, data = df) ## ## Coefficients: ## (Intercept) disp hp drat wt ## 16.53357 0.00872 -0.02060 2.01577 -4.38546 ## qsec ## 0.64015
出力では、適合の品質に関する十分な情報が得られません。summary() 関数を使用すると、係数の有意性、自由度、残差の形状などの詳細にアクセスできます。
summary(fit)
出力:
## return the p-value and coefficient ## ## Call: ## lm(formula = model, data = df) ## ## Residuals: ## Min 1Q Median 3Q Max ## -3.5404 -1.6701 -0.4264 1.1320 5.4996 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 16.53357 10.96423 1.508 0.14362 ## disp 0.00872 0.01119 0.779 0.44281 ## hp -0.02060 0.01528 -1.348 0.18936 ## drat 2.01578 1.30946 1.539 0.13579 ## wt -4.38546 1.24343 -3.527 0.00158 ** ## qsec 0.64015 0.45934 1.394 0.17523 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 2.558 on 26 degrees of freedom ## Multiple R-squared: 0.8489, Adjusted R-squared: 0.8199 ## F-statistic: 29.22 on 5 and 26 DF, p-value: 6.892e-10
上記の表の出力からの推論
- この表は、重量と燃費の間に強い負の相関関係があり、乾燥重量については正の相関関係があることを示している。
- 変数 wt のみが mpg に統計的な影響を与えます。 統計で仮説をテストするには、以下を使用することを覚えておいてください。
- H0: 統計的に影響はない
- H1: 予測子は y に意味のある影響を与えます
- p 値が 0.05 より小さい場合、変数が統計的に有意であることを示します。
- 調整済み決定係数(R二乗):予測変数の数で補正した、モデルによって説明されるyの分散の割合。ここでは0.8199なので、モデルはmpgの分散の約82%を説明しています。R二乗は常に0から1の間にあり、値が大きいほど良いとされます。
あなたは ANOVA anova() 関数を使用して、各特徴が分散に与える影響を推定するテストを行います。
anova(fit)
出力:
## Analysis of Variance Table ## ## Response: mpg ## Df Sum Sq Mean Sq F value Pr(>F) ## disp 1 808.89 808.89 123.6185 2.23e-11 *** ## hp 1 33.67 33.67 5.1449 0.031854 * ## drat 1 30.15 30.15 4.6073 0.041340 * ## wt 1 70.51 70.51 10.7754 0.002933 ** ## qsec 1 12.71 12.71 1.9422 0.175233 ## Residuals 26 170.13 6.54 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
モデルのパフォーマンスを推定するより一般的な方法は、さまざまな尺度に対する残差を表示することです。
Lot() 関数を使用すると、XNUMX つのグラフを表示できます。
– 残差と近似値
– 通常の QQ プロット: 理論上の四分位数と標準化された残差
– スケール位置: 近似値と標準化残差の平方根
– 残差 vs レバレッジ: レバレッジ vs 標準化残差
plot(fit) の前に、par(mfrow = c(2, 2)) というコードを追加してください。このコードを追加しないと、R は次のグラフを表示するために Enter キーを押すように促します。
par(mfrow = c(2, 2))
Code 説明
- (mfrow=c(2,2)): XNUMX つのグラフを並べて表示するウィンドウを返します。
- 最初の 2 は行数を加算します
- 2 番目の XNUMX は列の数を追加します。
- (mfrow=c(3,2)) と書くと、3 行 2 列のウィンドウが作成されます。
plot(fit)
出力:

lm() 関数は、多くの有用な情報を含むリストを返します。作成した fit オブジェクトに $ 記号と表示したい情報を追加することで、これらの情報にアクセスできます。tract.
– 係数: `fit$coefficients`
– 残差: `fit$residuals`
– 近似値: `fit$fitted.values`
R の因子回帰
最後のモデル推定では、連続変数のみについて mpg を回帰します。 因子変数をモデルに追加するのは簡単です。 変数 am をモデルに追加します。 変数が因子水準であり、連続的ではないことを確認することが重要です。
df <- mtcars %>%
mutate(cyl = factor(cyl),
vs = factor(vs),
am = factor(am),
gear = factor(gear),
carb = factor(carb))
model <- mpg ~ .
summary(lm(model, df))
出力:
## ## Call: ## lm(formula = model, data = df) ## ## Residuals: ## Min 1Q Median 3Q Max ## -3.5087 -1.3584 -0.0948 0.7745 4.6251 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 23.87913 20.06582 1.190 0.2525 ## cyl6 -2.64870 3.04089 -0.871 0.3975 ## cyl8 -0.33616 7.15954 -0.047 0.9632 ## disp 0.03555 0.03190 1.114 0.2827 ## hp -0.07051 0.03943 -1.788 0.0939 . ## drat 1.18283 2.48348 0.476 0.6407 ## wt -4.52978 2.53875 -1.784 0.0946 . ## qsec 0.36784 0.93540 0.393 0.6997 ## vs1 1.93085 2.87126 0.672 0.5115 ## am1 1.21212 3.21355 0.377 0.7113 ## gear4 1.11435 3.79952 0.293 0.7733 ## gear5 2.52840 3.73636 0.677 0.5089 ## carb2 -0.97935 2.31797 -0.423 0.6787 ## carb3 2.99964 4.29355 0.699 0.4955 ## carb4 1.09142 4.44962 0.245 0.8096 ## carb6 4.47757 6.38406 0.701 0.4938 ## carb8 7.25041 8.36057 0.867 0.3995 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 2.833 on 15 degrees of freedom ## Multiple R-squared: 0.8931, Adjusted R-squared: 0.779 ## F-statistic: 7.83 on 16 and 15 DF, p-value: 0.000124
R は、最初の因子水準を基本グループとして使用します。 他のグループの係数を基本グループと比較する必要があります。
Rにおける線形回帰の前提条件
通常の最小二乗法は、以下の5つの条件が満たされた場合にのみ、信頼できる係数とp値を生成します。plot(fit)によって生成される4つの診断プロットは、まさにこれらの条件を確認するために存在します。
- 非直線性(標準):XNUMX%FS以下 各予測変数と y の関係は線形です。 残差と適合値の比較 グラフを描画してください。曲線が見える場合は、変換または多項式項が必要であることを意味します。
- 独立: 誤差項は無相関です。時系列データはしばしばこの条件を満たさないため、carパッケージのdurbinWatsonTest()関数でテストできます。
- ホモセダスティシティ: 誤差分散は適合値全体で一定です。 スケール・位置 プロットは違反を示している。
- 残差の正規性: 誤差は正規分布に従います。点は対角線上に位置するはずです。 通常のQQ プロット。
- 多重共線性なし: 予測変数は互いにほぼ重複しているわけではない。分散膨張係数が5を超える場合は、通常、警戒すべき水準となる。
library(car) vif(fit) # variance inflation factors shapiro.test(residuals(fit)) # normality of residuals
違反があったとしても必ずしもモデルが無効になるわけではありませんが、p値に対する信頼性が変わるため、係数を報告する前に必ず確認してください。
R言語で線形回帰モデルを使って予測を行う方法
モデルを当てはめるのは作業の半分に過ぎません。predict() 関数は、当てはめた係数を新しい観測値に適用します。
predict(object, newdata, interval = "none", level = 0.95) arguments: -object: The model returned by lm() -newdata: A data frame whose columns match the predictors used in the formula -interval: "none", "confidence" for the mean response, or "prediction" for a single new case -level: The confidence level, 0.95 by default
以下の3つの手順に従ってください。
- 新規症例のデータフレームを作成する。 列名は数式内の予測変数名と完全に一致している必要があり、因子レベルはトレーニングデータと一致している必要があります。
- predict() を呼び出します。 適合させたオブジェクトと新しいデータフレームを渡します。
- 間隔を追加します。 平均的な応答に関する不確実性を知りたい場合は「信頼度」を、個々の車の応答範囲を知りたい場合は「予測」を選択してください。
new_cars <- data.frame(wt = c(2.5, 3.2), hp = c(110, 175)) fit_final <- lm(mpg ~ wt + hp, data = mtcars) predict(fit_final, newdata = new_cars) predict(fit_final, newdata = new_cars, interval = "prediction")
結果を読んでいます。 重量2.5ポンド、出力110馬力の自動車の燃費は、およそ24.1mpgと予測される。予測区間は、適合直線の不確実性に加えて、単一の観測値の不確実性も含むため、常に信頼区間よりも広くなる。
予測の正確性を保つための2つのルールがあります。まず、訓練データの範囲を超えて外挿してはいけません。直線的な予測は、外的なデータには根拠がないからです。次に、モデルがまだ見たことのないデータで評価を行いましょう。そうしないと、報告される誤差は楽観的になりすぎてしまいます。
Rにおける線形回帰とロジスティック回帰の比較
結果が連続的でない場合、アナリストはしばしばlm()関数を使用します。以下の表は、その境界がどこにあるかを示しています。
| 基準 | 直線回帰 | ロジスティック回帰 |
|---|---|---|
| 応答変数 | 連続的な | 二値またはカテゴリ |
| 予測出力 | 任意の実数 | 0から1の間の確率 |
| 推定 | 通常の最小二乗法 | 最大尤度 |
| フィット寸法 | R二乗値、RMSE | AIC、逸脱度、精度 |
| R関数 | lm(数式、データ) | glm(formula, data, family = “binomial”) |
結果がイエスかノーかの決定であれば、 一般化線形モデル ゼロとイチを通る直線を無理やり引くのではなく。
R での段階的線形回帰
このチュートリアルの最後の部分では、 ステップワイズ回帰 アルゴリズム。このアルゴリズムの目的は、モデル内の潜在的な候補を追加および削除し、従属変数に大きな影響を与える候補を残すことです。このアルゴリズムは、データセットに予測子の大きなリストが含まれている場合に有効です。独立変数を手動で追加および削除する必要はありません。ステップワイズ回帰は、モデルに適合する最適な候補を選択するために構築されます。
実際にどのように動作するのか見ていきましょう。ここでは、教育的な説明のために、連続変数のみを含むmtcarsデータセットを使用します。分析を開始する前に、相関行列を使用してデータ間の関係性を確認することをお勧めします。GGallyライブラリはggplot2の拡張機能です。
このライブラリには、行列内のすべての変数の相関や分布などの要約統計を表示するさまざまな関数が含まれています。 ggscatmat 関数を使用しますが、次を参照してください。 ビネット GGally ライブラリの詳細については、を参照してください。
ggscatmat() の基本構文は次のとおりです。
ggscatmat(df, columns = 1:ncol(df), corMethod = "pearson") arguments: -df: A matrix of continuous variables -columns: Pick up the columns to use in the function. By default, all columns are used -corMethod: Define the function to compute the correlation between variable. By default, the algorithm uses the Pearson formula
すべての変数の相関関係を表示し、段階的回帰分析の最初のステップに最適な変数を決定します。変数と従属変数であるmpgの間には、強い相関関係がいくつか見られます。
library(GGally) df <- mtcars %>% select(-c(am, vs, cyl, gear, carb)) ggscatmat(df, columns = 1: ncol(df))
出力:

ステップワイズ回帰のステップバイステップの例
変数選択はモデル適合の重要な部分であり、ステップワイズ回帰はその探索を自動的に実行します。データセット内の可能な選択肢の数を推定するには、次の計算を行います。 ![]() k は予測子の数です。 可能性の量は、独立変数の数とともに大きくなります。 そのため、自動検索が必要です。
k は予測子の数です。 可能性の量は、独立変数の数とともに大きくなります。 そのため、自動検索が必要です。
CRAN から olsrr パッケージをインストールする必要があります。 このパッケージはまだ Anaconda では利用できません。 したがって、コマンドラインから直接インストールします。
install.packages("olsrr")
適合基準 (つまり、R XNUMX 乗、調整済み R XNUMX 乗、ベイジアン基準) を使用して、可能性のすべてのサブセットをプロットできます。 AIC 基準が最も低いモデルが最終モデルになります。
library(olsrr) model <- mpg~. fit <- lm(model, df) test <- ols_all_subset(fit) plot(test)
Code 説明
- MPG ~.: 推定するモデルを構築する
- lm(model, df): OLSモデルを実行します
- ols_all_subset(適合):関連する統計情報を用いてグラフを作成する
- プロット(テスト): グラフをプロットする
出力:

線形回帰モデルでは、 t検定 独立変数が従属変数に及ぼす統計的影響を推定します。研究者は一般的に最大閾値を10%に設定し、p値が低いほど統計的関連性が強いことを示します。ステップワイズ回帰は、この検定に基づいて候補となる予測変数を追加および削除します。アルゴリズムは次のように動作します。

- ステップ 1: y の各予測子を個別に回帰します。 つまり、y の x_1、y の x_2 を x_n に回帰します。 保管してください p値 そして、定義されたしきい値 (デフォルトでは 0.1) よりも低い p 値を持つ回帰変数を維持します。 しきい値よりも重要度が低い予測変数が最終モデルに追加されます。 入力しきい値よりも低い p 値を持つ変数がない場合、アルゴリズムは停止し、定数のみを含む最終モデルが得られます。
- ステップ 2: p 値が最低の予測子を使用し、変数を 0.1 つ別々に追加します。定数、ステップ 1 の最良の予測子、および XNUMX 番目の変数を回帰します。入力しきい値よりも低い値を持つ新しい予測子をステップワイズ モデルに追加します。p 値が XNUMX 未満の変数がない場合、アルゴリズムは停止し、予測子が XNUMX つだけの最終モデルが作成されます。ステップワイズ モデルを回帰して、ステップ XNUMX の最良の予測子の重要性を確認します。削除しきい値よりも高い場合は、ステップワイズ モデルに保持します。それ以外の場合は、除外します。
- ステップ 3: 新しい最適なステップワイズ モデルで手順 2 を複製します。アルゴリズムは、入力値に基づいてステップワイズ モデルに予測子を追加し、除外しきい値を満たさない場合はステップワイズ モデルから予測子を除外します。
- アルゴリズムは、変数を追加または除外できなくなるまで続行されます。
olsrr パッケージの関数 ols_stepwise() を使用してアルゴリズムを実行できます。
ols_stepwise(fit, pent = 0.1, prem = 0.3, details = FALSE) arguments: -fit: Model to fit. Need to use `lm()`before to run `ols_stepwise() -pent: Threshold of the p-value used to enter a variable into the stepwise model. By default, 0.1 -prem: Threshold of the p-value used to exclude a variable into the stepwise model. By default, 0.3 -details: Print the details of each step
⚠️ パッケージに関する注意事項: olsrr の最近のバージョンでは、これらの関数名が変更されました。 ols_step_all_possible() ols_all_subset() の代わりに、 ols_step_both_p() ols_stepwise() の代わりに使用します。引数と出力は変更ありません。
その前に、アルゴリズムの手順を示します。 以下は、従属変数と独立変数を含む表です。
| 従属変数 | 独立変数 |
|---|---|
| MPG | disp |
| hp | |
| ねずみ | |
| wt | |
| qsec |
お気軽にご連絡ください
まず、アルゴリズムは各独立変数に対してモデルを個別に実行することから始まります。 表には、各モデルの p 値が示されています。
## [[1]] ## (Intercept) disp ## 3.576586e-21 9.380327e-10 ## ## [[2]] ## (Intercept) hp ## 6.642736e-18 1.787835e-07 ## ## [[3]] ## (Intercept) drat ## 0.1796390847 0.0000177624 ## ## [[4]] ## (Intercept) wt ## 8.241799e-19 1.293959e-10 ## ## [[5] ## (Intercept) qsec ## 0.61385436 0.01708199
モデルに入るために、アルゴリズムは最小の p 値を持つ変数を保持します。 上記の出力から、それは wt です
ステップ 1
最初のステップでは、アルゴリズムは wt と他の変数に対して独立して mpg を実行します。
## [[1]] ## (Intercept) wt disp ## 4.910746e-16 7.430725e-03 6.361981e-02 ## ## [[2]] ## (Intercept) wt hp ## 2.565459e-20 1.119647e-06 1.451229e-03 ## ## [[3]] ## (Intercept) wt drat ## 2.737824e-04 1.589075e-06 3.308544e-01 ## ## [[4]] ## (Intercept) wt qsec ## 7.650466e-04 2.518948e-11 1.499883e-03
各変数は最終モデルに採用される可能性のある候補です。しかし、アルゴリズムはp値が低い変数のみを残します。結果として、hpのp値はqsecよりもわずかに低いため、hpが最終モデルに採用されました。
ステップ 2
アルゴリズムは最初のステップを繰り返しますが、今回は最終モデルに XNUMX つの独立変数を使用します。
## [[1]] ## (Intercept) wt hp disp ## 1.161936e-16 1.330991e-03 1.097103e-02 9.285070e-01 ## ## [[2]] ## (Intercept) wt hp drat ## 5.133678e-05 3.642961e-04 1.178415e-03 1.987554e-01 ## ## [[3]] ## (Intercept) wt hp qsec ## 2.784556e-03 3.217222e-06 2.441762e-01 2.546284e-01
残りの候補はいずれも、エントリー閾値を下回るp値を持っていません。アルゴリズムはここで停止し、最終モデルは次のようになります。
## ## Call: ## lm(formula = mpg ~ wt + hp, data = df) ## ## Residuals: ## Min 1Q Median 3Q Max ## -3.941 -1.600 -0.182 1.050 5.854 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 37.22727 1.59879 23.285 < 2e-16 *** ## wt -3.87783 0.63273 -6.129 1.12e-06 *** ## hp -0.03177 0.00903 -3.519 0.00145 ** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 2.593 on 29 degrees of freedom ## Multiple R-squared: 0.8268, Adjusted R-squared: 0.8148 ## F-statistic: 69.21 on 2 and 29 DF, p-value: 9.109e-12
結果を比較するには、関数 ols_stepwise() を使用できます。
stp_s <-ols_stepwise(fit, details=TRUE)
出力:
このアルゴリズムは2つのステップで解を見つけ出し、上記の手動による手順と同じ出力を返します。
したがって、最終的なモデルは2つの予測変数と切片によって説明され、燃費(マイル/ガロン)は総馬力と重量の両方と負の相関関係にある。
## You are selecting variables based on p value... ## 1 variable(s) added.... ## Variable Selection Procedure ## Dependent Variable: mpg ## ## Stepwise Selection: Step 1 ## ## Variable wt Entered ## ## Model Summary ## -------------------------------------------------------------- ## R 0.868 RMSE 3.046 ## R-Squared 0.753 Coef. Var 15.161 ## Adj. R-Squared 0.745 MSE 9.277 ## Pred R-Squared 0.709 MAE 2.341 ## -------------------------------------------------------------- ## RMSE: Root Mean Square Error ## MSE: Mean Square Error ## MAE: Mean Absolute Error ## ANOVA ## -------------------------------------------------------------------- ## Sum of ## Squares DF Mean Square F Sig. ## -------------------------------------------------------------------- ## Regression 847.725 1 847.725 91.375 0.0000 ## Residual 278.322 30 9.277 ## Total 1126.047 31 ## -------------------------------------------------------------------- ## ## Parameter Estimates ## ---------------------------------------------------------------------------------------- ## model Beta Std. Error Std. Beta t Sig lower upper ## ---------------------------------------------------------------------------------------- ## (Intercept) 37.285 1.878 19.858 0.000 33.450 41.120 ## wt -5.344 0.559 -0.868 -9.559 0.000 -6.486 -4.203 ## ---------------------------------------------------------------------------------------- ## 1 variable(s) added... ## Stepwise Selection: Step 2 ## ## Variable hp Entered ## ## Model Summary ## -------------------------------------------------------------- ## R 0.909 RMSE 2.593 ## R-Squared 0.827 Coef. Var 12.909 ## Adj. R-Squared 0.815 MSE 6.726 ## Pred R-Squared 0.781 MAE 1.901 ## -------------------------------------------------------------- ## RMSE: Root Mean Square Error ## MSE: Mean Square Error ## MAE: Mean Absolute Error ## ANOVA ## -------------------------------------------------------------------- ## Sum of ## Squares DF Mean Square F Sig. ## -------------------------------------------------------------------- ## Regression 930.999 2 465.500 69.211 0.0000 ## Residual 195.048 29 6.726 ## Total 1126.047 31 ## -------------------------------------------------------------------- ## ## Parameter Estimates ## ---------------------------------------------------------------------------------------- ## model Beta Std. Error Std. Beta t Sig lower upper ## ---------------------------------------------------------------------------------------- ## (Intercept) 37.227 1.599 23.285 0.000 33.957 40.497 ## wt -3.878 0.633 -0.630 -6.129 0.000 -5.172 -2.584 ## hp -0.032 0.009 -0.361 -3.519 0.001 -0.050 -0.013 ## ---------------------------------------------------------------------------------------- ## No more variables to be added or removed.
Rにおける線形回帰:重要なポイントと関数リファレンス
- 線形回帰は、ある目的変数と一連の予測変数との間の正確な関係を測定できるか、という単純な問いに答えるものです。
- 最小二乗法は、予測されたy値と実際のy値との間の垂直距離である二乗誤差の合計を最小にするパラメータを見つけます。
- 複数の独立変数を含む確率モデルは重回帰モデルと呼ばれます。
- ステップワイズ線形回帰アルゴリズムの目的は、モデル内の潜在的な候補を追加および削除し、従属変数に大きな影響を与える候補を保持することです。
- 変数選択はモデル構築において重要な部分であり、ステップワイズ回帰はそれを自動的に実行します。
このチュートリアルで使用されるすべての関数は以下のとおりです。
| 図書館 | DevOps Tools Engineer試験のObjective | 演算 | Arguments |
|---|---|---|---|
| ベース | 線形回帰を計算する | lm() | 数式、データ |
| ベース | モデルの要約 | まとめ() | フィット |
| ベース | Extract係数 | lm()$係数 | |
| ベース | Extract残差 | lm()$残差 | |
| ベース | Extract適合値 | lm()$fitted.values | |
| オルスル | ステップワイズ回帰を実行する | ols_stepwise() | フィット、ペント = 0.1、プレム = 0.3、詳細 = FALSE |
お願いモデルを当てはめる前に、カテゴリ変数を因子に変換することを忘れないでください。