Comment installer Hadoop sur UbuntuÉtapes de téléchargement et d'installation
⚡ Résumé intelligent
Installation d'Apache Hadoop sur Ubuntu Cela nécessite deux étapes : décompresser la version sous un compte système dédié avec SSH sans mot de passe, puis modifier quatre fichiers XML avant de formater HDFS et de démarrer le cluster à nœud unique.

Dans ce tutoriel, nous vous guiderons étape par étape à travers le processus d'installation d'Apache Hadoop sur un système Linux (UbuntuIl s'agit d'un processus en deux étapes : d'abord télécharger et installer la version, puis la configurer.
Il y a deux conditions préalables :
- Vous devez avoir Ubuntu Installé et courir.
- Vous devez avoir Java Installé.
Notes de version Hadoop 3.x pour cette configuration
Les captures d'écran de ce guide ont été réalisées avec Hadoop 2.2.0. La séquence des étapes reste inchangée dans les versions actuelles, mais certains noms et valeurs par défaut ont été modifiés. Consultez le tableau ci-dessous avant de copier une commande telle quelle.
| Paramètre ou étape | Dans ce tutoriel (Hadoop 2.x) | Hadoop 3.x actuel |
|---|---|---|
| Archives de publication | hadoop-2.2.0.tar.gz |
hadoop-3.5.0.tar.gz, la première version stable 3.5, publiée le 2 avril 2026 |
| propriété du système de fichiers par défaut | fs.default.name en prose, fs.defaultFS dans le XML |
fs.defaultFS seulement; fs.default.name est obsolète |
| Propriété MapReduce | mapreduce.jobtracker.address |
mapreduce.framework.name ajuster à yarn; le travailTracker n'existe plus une fois que YARN planifie le travail |
| mapred-site.xml | Copié depuis mapred-site.xml.template |
Expédié en etc/hadoop L'étape de copie est déjà terminée, donc inutile. |
| Port d'interface utilisateur Web du NameNode | 50070 | 9870 |
| Java | Java 6 ou Java 7 | Java 8 ou Java 11 |
Tout le reste dans ce guide fonctionne de la même manière sur Hadoop 3 : le compte dédié, la clé SSH, les quatre fichiers de configuration et les scripts de démarrage et d’arrêt.
Partie 1) Téléchargez et installez Hadoop
Étape 1) Ajouter un utilisateur système Hadoop
Ajoutez un utilisateur système Hadoop à l'aide de la commande ci-dessous.
sudo addgroup hadoop_

sudo adduser --ingroup hadoop_ hduser_
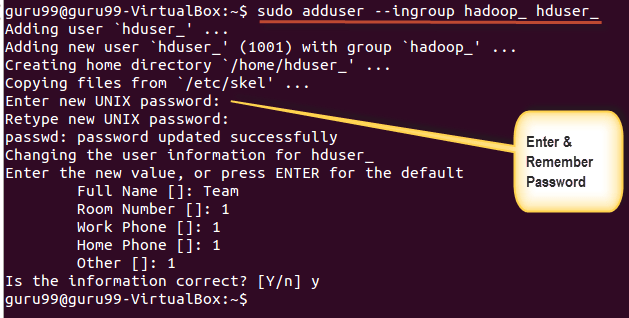
Entrez votre mot de passe, votre nom et d'autres détails.
NOTE: Il est possible que l'erreur mentionnée ci-dessous se produise lors de ce processus de configuration et d'installation.
« hduser n'est pas dans le fichier sudoers. Cet incident sera signalé.

Cette erreur peut être résolue en se connectant en tant qu'utilisateur root.

Exécuter la commande
sudo adduser hduser_ sudo

Re-login as hduser_

Étape 2) Configurer SSH
Pour gérer les nœuds d'un cluster, Hadoop nécessite un accès SSH.
Tout d’abord, changez d’utilisateur, entrez la commande suivante
su - hduser_

Cette commande créera une nouvelle clé.
ssh-keygen -t rsa -P ""

Activez l'accès SSH à la machine locale à l'aide de cette clé.
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
![]()
Testez maintenant la configuration SSH en vous connectant à localhost en tant qu'utilisateur 'hduser_'.
ssh localhost

À noter: Si vous voyez l'erreur ci-dessous en réponse à « ssh localhost », il est possible que le protocole SSH ne soit pas disponible sur ce système.

Pour résoudre ce problème –
Purger SSH en utilisant,
sudo apt-get purge openssh-server
Il est recommandé de purger le système avant de commencer l'installation.

Installez SSH à l'aide de la commande-
sudo apt-get install openssh-server

Étape 3) Téléchargez Hadoop
L'étape suivante consiste à télécharger Hadoop depuis le page des versions d'Apache Hadoop.

Sélectionnez Écurie

Sélectionnez le fichier tar.gz (et non le fichier se terminant par src).

Une fois le téléchargement terminé, accédez au répertoire contenant le fichier tar.
![]()
Entrée,
sudo tar xzf hadoop-2.2.0.tar.gz
![]()
Maintenant, renommez hadoop-2.2.0 en hadoop.
sudo mv hadoop-2.2.0 hadoop
![]()
Enfin, transmettez le dossier au nouveau compte.
sudo chown -R hduser_:hadoop_ hadoop
![]()
Remplacez la version que vous avez réellement téléchargée par hadoop-2.2.0 dans les trois commandes ci-dessus.
Partie 2) Configurer Hadoop
Étape 1) Modifier le fichier ~/.bashrc
Ajoutez les lignes suivantes à la fin du fichier ~/.bashrc.
#Set HADOOP_HOME export HADOOP_HOME=<Installation Directory of Hadoop> #Set JAVA_HOME export JAVA_HOME=<Installation Directory of Java> # Add bin/ directory of Hadoop to PATH export PATH=$PATH:$HADOOP_HOME/bin
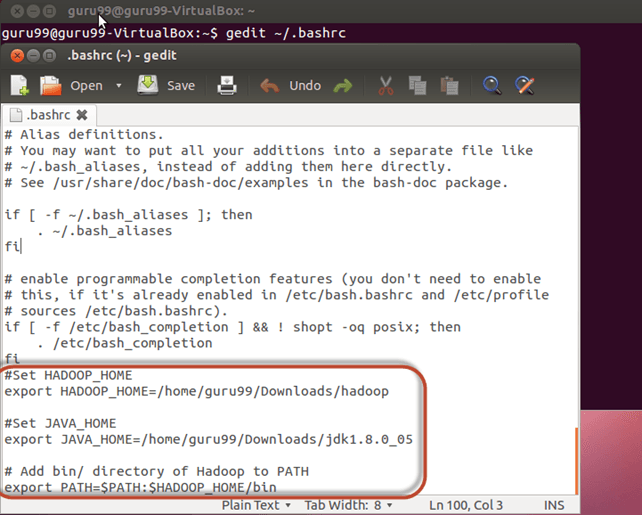
Maintenant, exécutez cette configuration d'environnement à l'aide de la commande ci-dessous.
. ~/.bashrc
![]()
Étape 2) Configurations relatives à HDFS
Définissez la variable d'environnement JAVA_HOME dans le fichier $HADOOP_HOME/etc/hadoop/hadoop-env.sh, comme indiqué ci-dessous.
![]()

Avec

Il y a deux paramètres dans $HADOOP_HOME/etc/hadoop/core-site.xml qui doivent être définis :
1. 'hadoop.tmp.dir' – Utilisé pour spécifier un répertoire qui sera utilisé par Hadoop pour stocker ses fichiers de données.
2. 'fs.defaultFS' – Spécifie le système de fichiers par défaut. L'ancien nom de cette propriété, 'fs.default.name', est obsolète.
Pour définir ces paramètres, ouvrez core-site.xml
sudo gedit $HADOOP_HOME/etc/hadoop/core-site.xml
![]()
Copiez les lignes ci-dessous entre les étiquettes.
<property> <name>hadoop.tmp.dir</name> <value>/app/hadoop/tmp</value> <description>Parent directory for other temporary directories.</description> </property> <property> <name>fs.defaultFS </name> <value>hdfs://localhost:54310</value> <description>The name of the default file system. </description> </property>

Accédez au répertoire $HADOOP_HOME/etc/hadoop.

Créez maintenant le répertoire mentionné dans core-site.xml.
sudo mkdir -p <Path of Directory used in above setting>
![]()
Accorder les autorisations au répertoire.
sudo chown -R hduser_:Hadoop_ <Path of Directory created in above step>
![]()
sudo chmod 750 <Path of Directory created in above step>
![]()
Étape 3) Configuration de MapReduce
Avant de commencer ces configurations, définissons le chemin HADOOP_HOME.
sudo gedit /etc/profile.d/hadoop.sh
Et entrez
export HADOOP_HOME=/home/guru99/Downloads/Hadoop

Entrez ensuite
sudo chmod +x /etc/profile.d/hadoop.sh
![]()
Quittez le terminal et redémarrez-le.
Tapez echo $HADOOP_HOME pour vérifier le chemin.
![]()
Copiez maintenant les fichiers
sudo cp $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml
![]()
Ouvrez le fichier mapred-site.xml
sudo gedit $HADOOP_HOME/etc/hadoop/mapred-site.xml
![]()
Ajoutez les paramètres ci-dessous entre les et étiquettes.
<property> <name>mapreduce.jobtracker.address</name> <value>localhost:54311</value> <description>MapReduce job tracker runs at this host and port. </description> </property>

Ouvrez le fichier $HADOOP_HOME/etc/hadoop/hdfs-site.xml comme indiqué ci-dessous,
sudo gedit $HADOOP_HOME/etc/hadoop/hdfs-site.xml
![]()
Ajoutez les paramètres ci-dessous entre les et étiquettes.
<property> <name>dfs.replication</name> <value>1</value> <description>Default block replication.</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hduser_/hdfs</value> </property>

Créez le répertoire spécifié dans les paramètres ci-dessus.
sudo mkdir -p <Path of Directory used in above setting>
sudo mkdir -p /home/hduser_/hdfs
![]()
Ensuite, accordez-lui la propriété et les autorisations nécessaires.
sudo chown -R hduser_:hadoop_ <Path of Directory created in above step>
sudo chown -R hduser_:hadoop_ /home/hduser_/hdfs
![]()
sudo chmod 750 <Path of Directory created in above step>
sudo chmod 750 /home/hduser_/hdfs
![]()
Étape 4) Formater HDFS
Avant de démarrer Hadoop pour la première fois, formatez HDFS à l'aide de la commande ci-dessous.
$HADOOP_HOME/bin/hdfs namenode -format

Étape 5) Démarrer le cluster Hadoop à nœud unique
Démarrez le cluster Hadoop à nœud unique à l'aide de la commande ci-dessous.
$HADOOP_HOME/sbin/start-dfs.sh
Le résultat de la commande ci-dessus est affiché ci-dessous.

Ensuite, démarrez les démons YARN.
$HADOOP_HOME/sbin/start-yarn.sh

À l'aide de l'outil « jps », vérifiez si tous les processus liés à Hadoop sont en cours d'exécution.
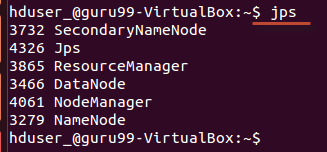
Si Hadoop a démarré avec succès, la sortie de jps devrait lister NameNode, NodeManager, ResourceManager, SecondaryNameNode et DataNode.
Étape 6) Arrêterping Hadoop
Arrêtez le cluster dans l'ordre inverse.
$HADOOP_HOME/sbin/stop-dfs.sh

$HADOOP_HOME/sbin/stop-yarn.sh

Comment vérifier que Hadoop est en cours d'exécution et corriger les erreurs courantes
La commande jps confirme le démarrage des processus, mais pas l'utilisation du cluster. Quatre vérifications supplémentaires permettent de trancher cette question.
- Ouvrez l'interface web du NameNode à l'adresse suivante :
http://localhost:9870(port 50070 sur Hadoop 2.x) et confirmez que le résumé indique un nœud actif. - Ouvrez l'interface ResourceManager à
http://localhost:8088pour confirmer que YARN a bien accepté le NodeManager. - Courir
hdfs dfsadmin -reportpour la capacité, les DataNodes actifs et tous les blocs sous-répliqués. - Écrivez quelque chose :
hdfs dfs -mkdir /testsuivie parhdfs dfs -ls /prouve que l'espace de noms accepte les modifications.
La plupart des échecs lors d'une première tentative se répartissent en cinq catégories.
| Symptôme | Causes | Fixer |
|---|---|---|
| La variable JAVA_HOME n'est pas définie et est introuvable. | La variable est exportée dans .bashrc mais pas dans hadoop-env.sh | Définissez également le chemin absolu du JDK dans hadoop-env.sh. |
| Accès refusé (clé publique, mot de passe) sur ssh localhost | Les clés autorisées sont manquantes ou trop permissives. | Ajoutez à nouveau id_rsa.pub, puis exécutez chmod 600 sur ~/.ssh/authorized_keys |
| Connexion refusée sur le port 22 | Le serveur openssh n'est pas installé ou n'est pas en cours d'exécution. | Installez openssh-server et démarrez le service ssh |
| DataNode manquant dans jps après un reformatage | Cluster Incohérence d'identifiant entre le NameNode formaté et l'ancien répertoire DataNode | Videz le dossier dfs.datanode.data.dir, puis formatez-le à nouveau. |
| start-dfs.sh : commande introuvable | Les variables d'environnement HADOOP_HOME et PATH n'ont jamais été initialisées dans le shell actuel. | Exécutez . ~/.bashrc ou ouvrez un nouveau terminal |