Proceso ETL (Extracción, Transformación y Carga) en un almacén de datos
Resumen inteligente
El proceso ETL (Extracción, Transformación y Carga) en un almacén de datos describe el flujo sistemático de transferencia de datos desde múltiples fuentes heterogéneas a un repositorio centralizado. Garantiza la consistencia, precisión y disponibilidad de los datos para el análisis mediante mecanismos estructurados de extracción, transformación y carga optimizada.

¿Qué es ETL?
ETL Es un proceso que extrae datos de diferentes sistemas fuente, los transforma (mediante cálculos, concatenaciones, etc.) y, finalmente, los carga en el sistema de almacenamiento de datos. La forma completa de ETL es «Extraer, Transformar y Cargar».
Es tentador pensar que crear un almacén de datos simplemente implica extraer datos de múltiples fuentes y cargarlos en una base de datos. Sin embargo, en realidad, requiere un proceso ETL complejo. Este proceso requiere la participación activa de diversas partes interesadas, como desarrolladores, analistas, evaluadores y altos ejecutivos, y es técnicamente complejo.
Para mantener su valor como herramienta para los tomadores de decisiones, el sistema de almacenamiento de datos debe adaptarse a los cambios del negocio. El ETL es una actividad recurrente (diaria, semanal o mensual) de un sistema de almacenamiento de datos y debe ser ágil, automatizada y estar bien documentada.
¿Por qué necesita ETL?
Hay muchas razones para adoptar ETL en la organización:
- Ayuda a las empresas a analizar sus datos comerciales para tomar decisiones comerciales críticas.
- Las bases de datos transaccionales no pueden responder preguntas comerciales complejas que puedan responderse con un ejemplo ETL.
- Un almacén de datos proporciona un repositorio de datos común
- ETL proporciona un método para mover datos de varias fuentes a un almacén de datos.
- A medida que cambian las fuentes de datos, el almacén de datos se actualizará automáticamente.
- Un sistema ETL bien diseñado y documentado es casi esencial para el éxito de un proyecto de almacén de datos.
- Permitir la verificación de reglas de transformación, agregación y cálculo de datos.
- El proceso ETL permite la comparación de datos de muestra entre el sistema de origen y el de destino.
- El proceso ETL puede realizar transformaciones complejas y requiere un área adicional para almacenar los datos.
- ETL ayuda a migrar datos a un almacén de datos, convirtiendo diferentes formatos y tipos en un sistema consistente.
- ETL es un proceso predefinido para acceder y manipular datos de origen en la base de datos de destino.
- ETL en un almacén de datos ofrece un contexto histórico profundo para el negocio.
- Ayuda a mejorar la productividad porque codifica y reutiliza sin necesidad de habilidades técnicas.
Con una comprensión clara del valor de ETL, profundicemos en el proceso de tres pasos que hace que todo funcione.
Proceso ETL en almacenes de datos
ETL es un proceso de 3 pasos
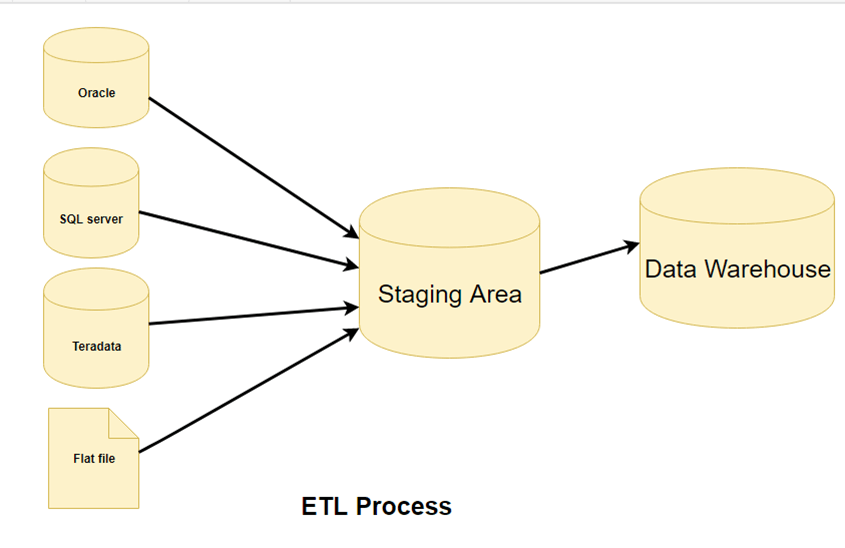
Paso 1) Extracción
En esta etapa de la arquitectura ETL, los datos se extraen del sistema de origen y se trasladan al área de ensayo. Las transformaciones, si las hubiera, se realizan en el área de ensayo para evitar la degradación del rendimiento del sistema de origen. Además, si se copian datos corruptos directamente del origen a la base de datos del almacén de datos, la reversión será un reto. El área de ensayo permite validar los datos extraídos antes de transferirlos al almacén de datos.
El almacén de datos necesita integrar sistemas que tengan diferentes DBMS, hardware, OperaSistemas de transmisión y protocolos de comunicación. Las fuentes pueden incluir aplicaciones heredadas como mainframes, aplicaciones personalizadas, dispositivos de punto de contacto como cajeros automáticos, centrales de llamadas, archivos de texto, hojas de cálculo, sistemas ERP, datos de proveedores y socios, entre otros.
Por lo tanto, se necesita un mapa de datos lógico antes de extraer y cargar físicamente los datos. Este mapa describe la relación entre los datos de origen y los de destino.
Tres métodos de extracción de datos:
- Extracción completa
- Extracción parcial: sin notificación de actualización.
- Extracción parcial: con notificación de actualización
Independientemente del método utilizado, la extracción no debería afectar el rendimiento ni el tiempo de respuesta de los sistemas fuente. Estos sistemas fuente son bases de datos de producción en vivo. Cualquier ralentización o bloqueo podría afectar los resultados de la empresa.
Algunas validaciones se realizan durante la Extracción:
- Conciliar registros con los datos de origen
- Asegúrese de que no se cargue spam ni datos no deseados
- Verificación del tipo de datos
- Eliminar todo tipo de datos duplicados/fragmentados
- Compruebe si todas las teclas están en su lugar.
Paso 2) Transformación
Los datos extraídos del servidor de origen son sin procesar y no se pueden utilizar en su formato original. Por lo tanto, deben depurarse, mapearse y transformarse. De hecho, este es el paso clave donde el proceso ETL añade valor y modifica los datos para generar informes de inteligencia empresarial (BI) detallados.
Es uno de los conceptos ETL importantes donde se aplica un conjunto de funciones a los datos extraídos. Los datos que no requieren ninguna transformación se denominan movimiento directo or datos de paso.
En el paso de transformación, puede realizar operaciones personalizadas con los datos. Por ejemplo, si el usuario desea la suma de los ingresos por ventas que no están en la base de datos, o si el nombre y el apellido de una tabla están en columnas diferentes, es posible concatenarlos antes de cargarlos.

Los siguientes son datos Integrity Problemas:
- Diferentes grafías de la misma persona, como Jon, John, etc.
- Hay varias formas de indicar el nombre de una empresa, como Google, Google Inc.
- Uso de diferentes nombres como Cleaveland y Cleveland.
- Puede darse el caso en que varias aplicaciones generen distintos números de cuenta para el mismo cliente.
- En algunos casos, los archivos de datos requeridos permanecen en blanco
- Producto no válido recogido en el POS, ya que la entrada manual puede dar lugar a errores.
Las validaciones se realizan durante esta etapa.
- Filtrado: seleccione solo ciertas columnas para cargar
- Uso de reglas y tablas de búsqueda para la estandarización de datos
- Conversión de juegos de caracteres y manejo de codificación
- Conversión de unidades de medida, como conversiones de fecha y hora, conversiones de moneda, conversiones numéricas, etc.
- Comprobación de la validación del umbral de datos. Por ejemplo, la edad no puede tener más de dos dígitos.
- Validación del flujo de datos desde el área de staging hasta las tablas intermedias.
- Los campos obligatorios no deben dejarse en blanco.
- Limpieza (por ejemplo, asignar NULL a 0 o Género Masculino a “M” y Femenino a “F”, etc.)
- Dividir una columna en varias columnas y fusionar varias columnas en una sola columna.
- Transponiendo filas y columnas,
- Utilice búsquedas para fusionar datos
- Utilizando cualquier validación de datos compleja (por ejemplo, si las dos primeras columnas de una fila están vacías, entonces rechaza automáticamente el procesamiento de la fila)
Paso 3) Cargando
La carga de datos en la base de datos del almacén de datos de destino es el último paso del proceso ETL. En un almacén de datos típico, es necesario cargar un gran volumen de datos en un periodo relativamente corto (noches). Por lo tanto, el proceso de carga debe optimizarse para un mejor rendimiento.
En caso de fallo de carga, se deben configurar mecanismos de recuperación para reiniciar desde el punto de fallo sin pérdida de integridad de los datos. Los administradores del almacén de datos deben supervisar, reanudar y cancelar las cargas según el rendimiento del servidor.
Tipos de Carga:
- Carga inicial — rellenar todas las tablas del almacén de datos
- Carga incremental — aplicar cambios continuos según sea necesario periódicamente.
- Actualización completa —borrar el contenido de una o más tablas y recargar con datos nuevos.
Verificación de carga
- Asegúrese de que los datos del campo clave no falten ni sean nulos.
- Pruebe vistas de modelado basadas en las tablas de destino.
- Compruebe que los valores combinados y las medidas calculadas.
- Verificaciones de datos en la tabla de dimensiones así como en la tabla de historial.
- Consulte los informes de BI en la tabla de dimensiones y hechos cargados.
Canalización ETL y procesamiento paralelo
La canalización ETL permite que se realicen la extracción, la transformación y la carga simultáneamente En lugar de secuencialmente. Tan pronto como se extrae una porción de datos, se transforma y se carga mientras continúa la extracción de nuevos datos. Esto procesamiento paralelo Mejora enormemente el rendimiento, reduce el tiempo de inactividad y maximiza la utilización de los recursos del sistema.
Este procesamiento paralelo es esencial para analítica en tiempo realIntegración de datos a gran escala y sistemas ETL en la nube. Al superponer tareas, el ETL segmentado garantiza una transferencia de datos más rápida, una mayor eficiencia y una entrega de datos más consistente para las empresas modernas.
¿Cómo la IA mejora los pipelines ETL modernos?
La inteligencia artificial revoluciona el ETL al hacer que las canalizaciones de datos sean adaptativas, inteligentes y autooptimizables. Los algoritmos de IA pueden mapear esquemas automáticamente, detectar anomalías y predecir reglas de transformación sin necesidad de configuración manual. Esto permite que los flujos de trabajo ETL gestionen fácilmente las estructuras de datos en constante evolución, manteniendo la calidad de los datos.
Las plataformas ETL modernas optimizadas con IA aprovechan tecnologías como AutoML para la ingeniería automática de características, el mapeo de esquemas basado en PLN que comprende las relaciones semánticas entre campos y algoritmos de detección de anomalías que identifican problemas de calidad de los datos en tiempo real. Estas capacidades reducen significativamente el esfuerzo manual que tradicionalmente se requería en el desarrollo y mantenimiento de ETL.
Aprendizaje automático Mejora el ajuste del rendimiento, garantizando una integración de datos más rápida y precisa. Al incorporar automatización e inteligencia predictiva, el ETL basado en IA proporciona información en tiempo real e impulsa una mayor eficiencia en los ecosistemas de datos híbridos y en la nube.
Para implementar los conceptos mencionados, las organizaciones recurren a herramientas ETL especializadas. A continuación, se presentan algunas de las principales opciones disponibles en el mercado.
Herramientas ETL
Hay muchas Herramientas ETL Disponibles en el mercado. A continuación, se presentan algunos de los más destacados:
1. MarkLogic:
MarkLogic es una solución de almacenamiento de datos que facilita y agiliza la integración de datos mediante una variedad de funciones empresariales. Permite consultar diferentes tipos de datos, como documentos, relaciones y metadatos.
https://www.marklogic.com/product/getting-started/
2. Oracle:
Oracle es la base de datos líder en la industria. Ofrece una amplia gama de soluciones de almacenamiento de datos, tanto locales como en la nube. Ayuda a optimizar la experiencia del cliente al aumentar la eficiencia operativa.
https://www.oracle.com/index.html
3. Amazon RojoShift:
Amazon Redshift es una herramienta de almacenamiento de datos. Es una herramienta sencilla y rentable para analizar todo tipo de datos utilizando estándares. SQL y herramientas de BI existentes. También permite ejecutar consultas complejas en petabytes de datos estructurados.
https://aws.amazon.com/redshift/?nc2=h_m1
Aquí hay una lista completa de útiles Herramientas de almacenamiento de datos.
Mejores prácticas para el proceso ETL
Las siguientes son las mejores prácticas para los pasos del proceso ETL:
- Nunca intentes limpiar todos los datos:
A todas las organizaciones les gustaría tener todos sus datos limpios, pero la mayoría no está dispuesta a pagar por esperar. Limpiarlos todos tomaría demasiado tiempo, así que es mejor no intentar limpiarlos todos. - Equilibrar la limpieza con las prioridades del negocio:
Si bien debe evitar depurar excesivamente todos los datos, asegúrese de depurar los campos críticos y de alto impacto para garantizar su confiabilidad. Centre los esfuerzos de depuración en los elementos de datos que afectan directamente las decisiones de negocio y la precisión de los informes. - Determine el costo de limpiar los datos:
Antes de limpiar todos los datos sucios, es importante que determine el costo de limpieza de cada elemento de datos sucios. - Para acelerar el procesamiento de consultas, tenga vistas e índices auxiliares:
Para reducir los costos de almacenamiento, almacene los datos resumidos en cintas de disco. Además, se requiere un equilibrio entre el volumen de datos que se almacenarán y su uso detallado. Compensación a nivel de granularidad de los datos para disminuir los costos de almacenamiento.