NLTK Tokenize: Λέξεις και προτάσεις Tokenizer με Παράδειγμα
⚡ Έξυπνη Σύνοψη
Το NLTK Tokenize διαχωρίζει το μεγάλο κείμενο σε μικρότερες μονάδες που ονομάζονται tokens, ένα θεμελιώδες βήμα στην επεξεργασία φυσικής γλώσσας. Το κιτ εργαλείων παρέχει το word_tokenize για τη διάσπαση των προτάσεων σε λέξεις και το sent_tokenize για τη διαίρεση κειμένου σε μεμονωμένες προτάσεις.

Τι είναι η Tokenization;
Τεκμηρίωση είναι η διαδικασία με την οποία μια μεγάλη ποσότητα κειμένου χωρίζεται σε μικρότερα μέρη που ονομάζονται tokens. Αυτά τα διακριτικά είναι πολύ χρήσιμα για την εύρεση μοτίβων και θεωρούνται ως ένα βασικό βήμα για τη δημιουργία και τη λήμματοποίηση. Το tokenization βοηθά επίσης στην αντικατάσταση ευαίσθητων στοιχείων δεδομένων με μη ευαίσθητα στοιχεία δεδομένων.
Η επεξεργασία φυσικής γλώσσας χρησιμοποιείται για τη δημιουργία εφαρμογών όπως η ταξινόμηση κειμένου, έξυπνο chatbot, συναισθηματική ανάλυση, μετάφραση γλώσσας, κ.λπ. Είναι ζωτικής σημασίας να κατανοήσουμε το μοτίβο στο κείμενο για την επίτευξη του προαναφερθέντος σκοπού.
Προς το παρόν, μην ανησυχείτε για το stemming και το lemmatization, αλλά αντιμετωπίζετε τα ως βήματα για τον καθαρισμό δεδομένων κειμένου χρησιμοποιώντας NLP (Natural language processing). Θα συζητήσουμε το stemming και τη lemmatization αργότερα στο σεμινάριο. Καθήκοντα όπως Ταξινόμηση κειμένου ή φιλτράρισμα ανεπιθύμητων μηνυμάτων κάνει χρήση του NLP μαζί με βιβλιοθήκες βαθιάς μάθησης όπως οι Keras και Τάση ροής.
Η εργαλειοθήκη Natural Language έχει πολύ σημαντική ενότητα NLTK συμβολίζω προτάσεις που περιλαμβάνουν περαιτέρω υποενότητες
- λέξη συμβολίζω
- πρόταση συμβολίζω
Συμβολισμός λέξεων
Χρησιμοποιούμε τη μέθοδο word_tokenize() να χωρίσει μια πρόταση σε λέξεις. Η έξοδος του tokenization λέξεων μπορεί να μετατραπεί σε Data Frame για καλύτερη κατανόηση κειμένου σε εφαρμογές μηχανικής εκμάθησης. Μπορεί επίσης να παρασχεθεί ως είσοδος για περαιτέρω βήματα καθαρισμού κειμένου, όπως αφαίρεση σημείων στίξης, αφαίρεση αριθμητικών χαρακτήρων ή στέλεχος. Τα μοντέλα μηχανικής μάθησης χρειάζονται αριθμητικά δεδομένα για να εκπαιδευτούν και να κάνουν μια πρόβλεψη. Η δημιουργία διακριτικών λέξεων γίνεται ένα κρίσιμο μέρος της μετατροπής κειμένου (συμβολοσειράς) σε αριθμητικά δεδομένα. Διαβάστε σχετικά Bag of Words ή CountVetorizer. Ανατρέξτε στο παρακάτω παράδειγμα word tokenize NLTK για να κατανοήσετε καλύτερα τη θεωρία.
from nltk.tokenize import word_tokenize text = "God is Great! I won a lottery." print(word_tokenize(text)) Output: ['God', 'is', 'Great', '!', 'I', 'won', 'a', 'lottery', '.']
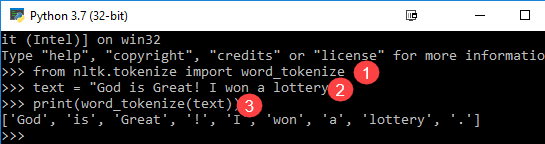
Code εξήγηση
- Η ενότητα word_tokenize εισάγεται από τη βιβλιοθήκη NLTK.
- Μια μεταβλητή "κείμενο" αρχικοποιείται με δύο προτάσεις.
- Η μεταβλητή κειμένου μεταβιβάζεται στην ενότητα word_tokenize και εκτυπώνεται το αποτέλεσμα. Αυτή η ενότητα διασπά κάθε λέξη με σημεία στίξης που μπορείτε να δείτε στην έξοδο.
Συμβολισμός Προτάσεων
Η υπομονάδα που είναι διαθέσιμη για τα παραπάνω είναι send_tokenize. Μια προφανής ερώτηση στο μυαλό σας θα ήταν γιατί χρειάζεται συμβολισμός προτάσεων όταν έχουμε την επιλογή του tokenization λέξεων. Φανταστείτε ότι πρέπει να μετράτε μέσες λέξεις ανά πρόταση, πώς θα υπολογίσετε; Για να ολοκληρώσετε μια τέτοια εργασία, χρειάζεστε τόσο το NLTK προτάσεων tokenizer όσο και το NLTK word tokenizer για να υπολογίσετε την αναλογία. Αυτή η έξοδος χρησιμεύει ως σημαντικό χαρακτηριστικό για την εκπαίδευση μηχανών, καθώς η απάντηση θα ήταν αριθμητική.
Ανατρέξτε στο παρακάτω παράδειγμα Tokenizer NLTK για να μάθετε πώς το tokenization προτάσεων διαφέρει από το tokenization λέξεων.
from nltk.tokenize import sent_tokenize text = "God is Great! I won a lottery." print(sent_tokenize(text)) Output: ['God is Great!', 'I won a lottery ']
Έχουμε 12 λέξεις και δύο προτάσεις για την ίδια είσοδο.
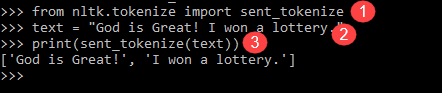
Επεξήγηση του προγράμματος
- Σε μια γραμμή όπως το προηγούμενο πρόγραμμα, εισήχθη η ενότητα sent_tokenize.
- Έχουμε πάρει την ίδια πρόταση. Περαιτέρω tokenizer προτάσεων στη μονάδα NLTK ανέλυσε αυτές τις προτάσεις και εμφανίζει την έξοδο. Είναι σαφές ότι αυτή η συνάρτηση σπάει κάθε πρόταση.
Πάνω από τη λέξη tokenizer Python Τα παραδείγματα είναι καλές πέτρες ρυθμίσεων για να κατανοήσετε τη μηχανική της συμβολικής λέξεων και προτάσεων.