Ενσωμάτωση Word και Word2Vec με παράδειγμα
⚡ Έξυπνη Σύνοψη
Το Word Embedding και το Word2Vec μετατρέπουν κείμενο σε πυκνά αριθμητικά διανύσματα, ώστε τα μοντέλα μηχανικής μάθησης να αναγνωρίζουν λέξεις με παρόμοιο νόημα. Αυτός ο πόρος εξηγεί την τεχνική, τις αρχιτεκτονικές CBOW και Skip-Gram, τις συναρτήσεις ενεργοποίησης και μια πλήρη υλοποίηση Gensim για πραγματικές εφαρμογές.
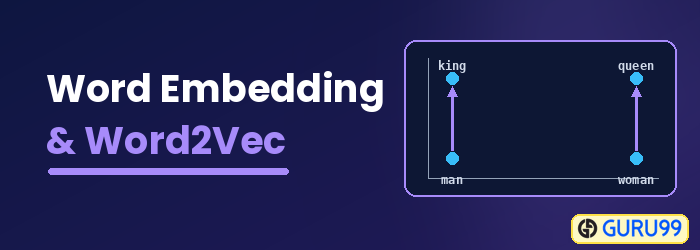
Τι είναι η ενσωμάτωση λέξεων;
Ενσωμάτωση λέξεων είναι ένας τύπος αναπαράστασης λέξεων που επιτρέπει στους αλγόριθμους μηχανικής μάθησης να κατανοούν λέξεις με παρόμοιες έννοιες. Είναι μια τεχνική μοντελοποίησης γλώσσας και εκμάθησης χαρακτηριστικών για την αντιστοίχιση λέξεων σε διανύσματα πραγματικών αριθμών χρησιμοποιώντας νευρωνικά δίκτυα, πιθανοτικά μοντέλα ή μείωση διαστάσεων στον πίνακα συν-εμφάνισης λέξεων. Ορισμένα μοντέλα ενσωμάτωσης λέξεων είναι το Word2vec (Google), GloVe (Στάνφορντ) και fastText (Facebook).
Η ενσωμάτωση λέξεων ονομάζεται επίσης κατανεμημένο σημασιολογικό μοντέλο, κατανεμημένο αναπαραστατημένο μοντέλο, σημασιολογικός διανυσματικός χώρος ή μοντέλο διανυσματικού χώρου. Καθώς διαβάζετε αυτά τα ονόματα, συναντάτε τη λέξη σημασιολογικός, που σημαίνει κατηγοριοποίηση παρόμοιων λέξεων. Για παράδειγμα, φρούτα όπως μήλο, μάνγκο και μπανάνα θα πρέπει να τοποθετούνται κοντά το ένα στο άλλο, ενώ τα βιβλία θα τοποθετούνται μακριά από αυτές τις λέξεις. Με μια ευρύτερη έννοια, η ενσωμάτωση λέξεων θα δημιουργήσει ένα διάνυσμα φρούτων που τοποθετείται μακριά από την διανυσματική αναπαράσταση των βιβλίων.
Πού χρησιμοποιείται το Word Embedding;
Η ενσωμάτωση λέξεων βοηθά στη δημιουργία χαρακτηριστικών, στην ομαδοποίηση εγγράφων, στην ταξινόμηση κειμένου και σε εργασίες επεξεργασίας φυσικής γλώσσας. Ας απαριθμήσουμε αυτές τις εφαρμογές και ας συζητήσουμε την καθεμία ξεχωριστά.
- Υπολογίστε παρόμοιες λέξεις: Η ενσωμάτωση λέξεων χρησιμοποιείται για την πρόταση λέξεων παρόμοιων με τη λέξη που υπόκειται στο μοντέλο πρόβλεψης. Παράλληλα, προτείνει επίσης ανόμοιες λέξεις, καθώς και τις πιο συνηθισμένες λέξεις.
- Δημιουργήστε μια ομάδα σχετικών λέξεων: Χρησιμοποιείται για σημασιολογικές ομάδεςping, το οποίο ομαδοποιεί πράγματα με παρόμοια χαρακτηριστικά και απομακρύνει τα ανόμοια αντικείμενα.
- Δυνατότητα ταξινόμησης κειμένου: Το κείμενο αντιστοιχίζεται σε πίνακες διανυσμάτων που τροφοδοτούνται στο μοντέλο για εκπαίδευση καθώς και για πρόβλεψη. Τα μοντέλα ταξινομητών που βασίζονται σε κείμενο δεν μπορούν να εκπαιδευτούν σε συμβολοσειρές, επομένως αυτό μετατρέπει το κείμενο σε μορφή που μπορεί να εκπαιδευτεί από μηχανές. Τα χαρακτηριστικά σημασιολογικής ανάπτυξης που διαθέτει βοηθούν περαιτέρω στην ταξινόμηση που βασίζεται σε κείμενο.
- Ομαδοποίηση εγγράφων: Αυτή είναι μια άλλη εφαρμογή όπου το Word Embedding και το Word2vec χρησιμοποιούνται ευρέως.
- Επεξεργασία φυσικής γλώσσας: Υπάρχουν πολλές εφαρμογές όπου η ενσωμάτωση λέξεων είναι χρήσιμη και υπερισχύει των λειτουργιών, π.χ.tracφάσεις αγωγής, όπως η προσθήκη ετικετών σε μέρη του λόγου, η ανάλυση συναισθήματος και η συντακτική ανάλυση.
Τώρα που καταλαβαίνετε πού εφαρμόζεται η ενσωμάτωση λέξεων, ας δούμε το πιο δημοφιλές μοντέλο που χρησιμοποιείται για τη δημιουργία αυτών των ενσωματώσεων.
Τι είναι το Word2vec;
Word2vec είναι μια τεχνική ή μοντέλο που παράγει ενσωματώσεις λέξεων για καλύτερη αναπαράσταση λέξεων. Είναι μια μέθοδος επεξεργασίας φυσικής γλώσσας που καταγράφει έναν μεγάλο αριθμό ακριβών συντακτικών και σημασιολογικών σχέσεων λέξεων. Είναι ένα ρηχό νευρωνικό δίκτυο δύο επιπέδων που μπορεί να ανιχνεύσει συνώνυμες λέξεις και να προτείνει πρόσθετες λέξεις για μερικές προτάσεις μόλις εκπαιδευτεί.
Πριν προχωρήσουμε περαιτέρω, δείτε τη διαφορά μεταξύ ενός ρηχού και ενός βαθιού νευρωνικού δικτύου, όπως φαίνεται στο παρακάτω διάγραμμα παραδείγματος ενσωμάτωσης του Word:
Το ρηχό νευρωνικό δίκτυο αποτελείται μόνο από ένα κρυφό επίπεδο μεταξύ εισόδου και εξόδου, ενώ ένα βαθύ νευρωνικό δίκτυο περιέχει πολλαπλά κρυφά επίπεδα μεταξύ εισόδου και εξόδου. Η είσοδος υπόκειται σε κόμβους, ενώ το κρυφό επίπεδο, καθώς και το επίπεδο εξόδου, περιέχουν νευρώνες.
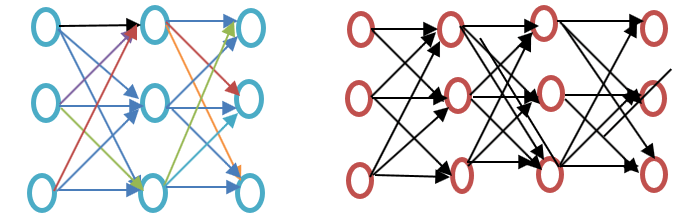
Το Word2vec είναι ένα δίκτυο δύο επιπέδων όπου υπάρχει μια είσοδος, ένα κρυφό επίπεδο και μια έξοδος.
Το Word2vec αναπτύχθηκε από μια ομάδα ερευνητών με επικεφαλής τον Tomas Mikolov στο GoogleΤο Word2vec είναι καλύτερο και πιο αποτελεσματικό από το μοντέλο λανθάνουσας σημασιολογικής ανάλυσης.
Γιατί Word2vec;
Το Word2vec αναπαριστά λέξεις σε μια αναπαράσταση διανυσματικού χώρου. Οι λέξεις αναπαριστώνται με τη μορφή διανυσμάτων και η τοποθέτηση γίνεται με τέτοιο τρόπο ώστε οι λέξεις με παρόμοια σημασία να εμφανίζονται μαζί και οι ανόμοιες λέξεις να βρίσκονται μακριά. Αυτό ονομάζεται επίσης σημασιολογική σχέση. Τα νευρωνικά δίκτυα δεν κατανοούν κείμενο. Αντίθετα, κατανοούν μόνο αριθμούς. Η ενσωμάτωση λέξεων παρέχει έναν τρόπο μετατροπής κειμένου σε αριθμητικό διάνυσμα.
Το Word2vec ανακατασκευάζει το γλωσσικό πλαίσιο των λέξεων. Πριν προχωρήσουμε περαιτέρω, ας κατανοήσουμε τι είναι το γλωσσικό πλαίσιο. Σε ένα γενικό σενάριο, όταν μιλάμε ή γράφουμε για να επικοινωνήσουμε, άλλοι άνθρωποι προσπαθούν να καταλάβουν τον στόχο της πρότασης. Για παράδειγμα, "Ποια είναι η θερμοκρασία της Ινδίας;" Εδώ, το πλαίσιο είναι ότι ο χρήστης θέλει να μάθει τη "θερμοκρασία της Ινδίας". Εν ολίγοις, ο κύριος στόχος μιας πρότασης είναι το πλαίσιο. Οι λέξεις ή οι προτάσεις που περιβάλλουν την προφορική ή γραπτή γλώσσα βοηθούν στον προσδιορισμό της σημασίας του πλαισίου. Το Word2vec μαθαίνει την διανυσματική αναπαράσταση των λέξεων μέσω αυτών των πλαισίων.
Τι κάνει το Word2vec;
Πριν από την ενσωμάτωση λέξεων
Είναι σημαντικό να γνωρίζουμε ποια προσέγγιση χρησιμοποιήθηκε πριν από την ενσωμάτωση λέξεων και ποια είναι τα μειονεκτήματά της, και στη συνέχεια θα δούμε πώς αυτά τα μειονεκτήματα ξεπερνιούνται με την ενσωμάτωση λέξεων χρησιμοποιώντας την προσέγγιση Word2vec. Τέλος, θα εξετάσουμε τον τρόπο λειτουργίας του Word2vec, επειδή είναι σημαντικό να κατανοήσουμε τη λειτουργία του.
Προσέγγιση Λανθάνουσας Σημασιολογικής Ανάλυσης
Αυτή είναι η προσέγγιση που χρησιμοποιήθηκε πριν από την ενσωμάτωση λέξεων. Χρησιμοποίησε την έννοια μιας Τσάντας Λέξεων, όπου οι λέξεις αναπαρίστανται με τη μορφή κωδικοποιημένων διανυσμάτων. Πρόκειται για μια αραιή διανυσματική αναπαράσταση όπου η διάσταση είναι ίση με το μέγεθος του λεξιλογίου. Εάν η λέξη εμφανίζεται στο λεξικό, καταμετράται. Διαφορετικά, δεν καταμετράται. Για να κατανοήσετε περισσότερα, ανατρέξτε στο παρακάτω πρόγραμμα.
Παράδειγμα Word2vec

from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() data_corpus = ["guru99 is the best site for online tutorials. I love to visit guru99."] vocabulary = vectorizer.fit(data_corpus) X = vectorizer.transform(data_corpus) print(X.toarray()) print(vectorizer.get_feature_names_out())
Παραγωγή:
[[1 2 1 1 1 1 1 1 1 1]] [u'best', u'guru99', u'is', u'love', u'online', u'sitefor', u'the', u'to', u'tutorials', u'visit']
Code εξήγηση
- Το CountVectorizer είναι η ενότητα που χρησιμοποιείται για την αποθήκευση του λεξιλογίου με βάση την προσαρμογή των λέξεων σε αυτό. Αυτό εισάγεται από το sklearn.
- Δημιουργήστε το αντικείμενο χρησιμοποιώντας την κλάση CountVetorizer.
- Γράψτε τα δεδομένα στη λίστα που θα προσαρτηθούν στο CountVectorizer.
- Τα δεδομένα προσαρμόζονται στο αντικείμενο που δημιουργήθηκε από την κλάση CountVetorizer.
- Εφαρμόστε μια προσέγγιση bag-of-words για να μετρήσετε λέξεις στα δεδομένα χρησιμοποιώντας το λεξιλόγιο. Εάν μια λέξη ή ένα διακριτικό δεν είναι διαθέσιμο στο λεξιλόγιο, τότε μια τέτοια θέση δείκτη ορίζεται σε μηδέν.
- Η μεταβλητή στη γραμμή 5, η οποία είναι το x, μετατρέπεται σε έναν πίνακα (μια μέθοδος διαθέσιμη για το x). Αυτό παρέχει τον αριθμό κάθε διακριτικού στην πρόταση ή τη λίστα που παρέχεται στη γραμμή 3.
- Αυτό δείχνει τα χαρακτηριστικά που αποτελούν μέρος του λεξιλογίου όταν προσαρμόζεται χρησιμοποιώντας τα δεδομένα στη γραμμή 4.
Στην προσέγγιση Latent Semantic, η γραμμή αντιπροσωπεύει μοναδικές λέξεις, ενώ η στήλη αντιπροσωπεύει τον αριθμό των φορών που εμφανίζεται αυτή η λέξη στο έγγραφο. Είναι μια αναπαράσταση λέξεων με τη μορφή ενός πίνακα εγγράφων. Η Αντίστροφη Συχνότητα Όρων-Εγγράφου Συχνότητας (TF-IDF) χρησιμοποιείται για την καταμέτρηση της συχνότητας των λέξεων στο έγγραφο, η οποία είναι η συχνότητα του όρου στο έγγραφο διαιρούμενη με τη συχνότητα του όρου σε ολόκληρο το σώμα κειμένων.
Έλλειψη της μεθόδου Bag of Words
- Αγνοεί τη σειρά της λέξης· για παράδειγμα, Αυτό είναι κακό = κακό είναι αυτό.
- Αγνοεί τα συμφραζόμενα των λέξεων. Ας υποθέσουμε ότι γράφουμε την πρόταση «Αγαπούσε τα βιβλία. Η εκπαίδευση βρίσκεται καλύτερα στα βιβλία». Θα δημιουργούσε δύο διανύσματα: ένα για το «Αγαπούσε τα βιβλία» και ένα άλλο για το «Η εκπαίδευση βρίσκεται καλύτερα στα βιβλία». Θα τα αντιμετώπιζε και τα δύο ως ορθογώνια, γεγονός που τα καθιστά ανεξάρτητα, αλλά στην πραγματικότητα, σχετίζονται μεταξύ τους.
Για να ξεπεραστούν αυτοί οι περιορισμοί, αναπτύχθηκε η ενσωμάτωση λέξεων και το Word2vec είναι μια προσέγγιση που χρησιμοποιείται για την υλοποίησή της.
Πώς λειτουργεί το Word2vec;
Το Word2vec μαθαίνει μια λέξη προβλέποντας τα συμφραζόμενά της. Για παράδειγμα, ας πάρουμε τη λέξη «Αυτός» αγαπά Ποδόσφαιρο."
Θέλουμε να υπολογίσουμε το Word2vec για τη λέξη: αγαπά.
Υποθέτω:
loves = Vin. P(Vout / Vin) is calculated where, Vin is the input word. P is the probability of likelihood. Vout is the output word.
Η λεξη αγαπά μετακινείται πάνω από κάθε λέξη στο σώμα κειμένων. Κωδικοποιούνται τόσο οι συντακτικές όσο και οι σημασιολογικές σχέσεις μεταξύ των λέξεων. Αυτό βοηθά στην εύρεση παρόμοιων και ανάλογων λέξεων.
Όλα τα τυχαία χαρακτηριστικά της λέξης αγαπά υπολογίζονται. Αυτά τα χαρακτηριστικά αλλάζουν ή ενημερώνονται σε σχέση με τις λέξεις γειτόνων ή τα συμφραζόμενα με τη βοήθεια ενός Πίσω διάδοση μέθοδος.
Ένας άλλος τρόπος μάθησης είναι ότι εάν τα συμφραζόμενα δύο λέξεων είναι παρόμοια ή δύο λέξεις έχουν παρόμοια χαρακτηριστικά, τότε αυτές οι λέξεις σχετίζονται.
Word2vec Archiδομή
Υπάρχουν δύο αρχιτεκτονικές που χρησιμοποιούνται από το Word2vec:
- Συνεχής Τσάντα Λέξεων (CBOW)
- Skip-gram
Πριν προχωρήσουμε περαιτέρω, ας συζητήσουμε γιατί αυτές οι αρχιτεκτονικές ή τα μοντέλα είναι σημαντικά από την άποψη της αναπαράστασης λέξεων. Η εκμάθηση της αναπαράστασης λέξεων είναι ουσιαστικά μη επιβλεπόμενη, αλλά απαιτούνται στόχοι/ετικέτες για την εκπαίδευση του μοντέλου. Το Skip-gram και το CBOW μετατρέπουν την μη επιβλεπόμενη αναπαράσταση σε μια επιβλεπόμενη μορφή για την εκπαίδευση του μοντέλου.
Στο CBOW, η τρέχουσα λέξη προβλέπεται χρησιμοποιώντας το παράθυρο των παραθύρων περιβάλλοντος περιβάλλοντος. Για παράδειγμα, αν wi-1, wi-2, wi + 1, wi + 2 δίνονται λέξεις ή πλαίσιο, αυτό το μοντέλο θα παρέχει wi.
Το Skip-Gram εκτελεί το αντίθετο του CBOW, το οποίο υπονοεί ότι προβλέπει τη δεδομένη ακολουθία ή το πλαίσιο από τη λέξη. Μπορείτε να αντιστρέψετε το παράδειγμα για να το κατανοήσετε. Αν wi δίνεται, αυτό θα προβλέψει το πλαίσιο, ή wi-1, wi-2, wi + 1, wi + 2.
Το Word2vec παρέχει την επιλογή μεταξύ CBOW (Continuous Bag of Words) και skip-gram. Τέτοιες παράμετροι παρέχονται κατά την εκπαίδευση του μοντέλου. Κάποιος μπορεί να έχει την επιλογή να χρησιμοποιήσει αρνητική δειγματοληψία ή ένα ιεραρχικό επίπεδο softmax.
Συνεχής τσάντα με λέξεις
Ας σχεδιάσουμε ένα απλό παράδειγμα διαγράμματος Word2vec για να κατανοήσουμε την αρχιτεκτονική συνεχούς bag-of-words.

Ας υπολογίσουμε τις εξισώσεις μαθηματικά. Ας υποθέσουμε ότι το V είναι το μέγεθος του λεξιλογίου και το N είναι το μέγεθος του κρυφού στρώματος. Η είσοδος ορίζεται ως { xi-1, Χi-2, Χi + 1, Χi + 2 }. Λαμβάνουμε τον πίνακα βαρών πολλαπλασιάζοντας το V * N. Ένας άλλος πίνακας λαμβάνεται πολλαπλασιάζοντας το διάνυσμα εισόδου με τον πίνακα βαρών. Αυτό μπορεί επίσης να γίνει κατανοητό από την ακόλουθη εξίσωση.
h = xitW
όπου xit και W είναι το διάνυσμα εισόδου και ο πίνακας βαρών αντίστοιχα.
Για να υπολογίσετε την αντιστοίχιση μεταξύ των συμφραζόμενων και της επόμενης λέξης, ανατρέξτε στην παρακάτω εξίσωση.
u = προβλεπόμενη αναπαράσταση * h
όπου η προβλεπόμενη αναπαράσταση λαμβάνεται από το μοντέλο στην παραπάνω εξίσωση.
Μοντέλο Skip-Gram
Η προσέγγιση Skip-Gram χρησιμοποιείται για την πρόβλεψη μιας πρότασης δεδομένης μιας λέξης εισόδου. Για να την κατανοήσουμε καλύτερα, ας σχεδιάσουμε το διάγραμμα που φαίνεται στο παρακάτω παράδειγμα Word2vec.

Κάποιος μπορεί να το αντιμετωπίσει ως το αντίστροφο του μοντέλου Continuous Bag of Words, όπου η είσοδος είναι η λέξη και το μοντέλο παρέχει το περιεχόμενο ή την ακολουθία. Μπορούμε επίσης να συμπεράνουμε ότι ο στόχος τροφοδοτείται στην είσοδο και το επίπεδο εξόδου αναπαράγεται πολλές φορές για να φιλοξενήσει τον επιλεγμένο αριθμό λέξεων περιεχομένου. Το διάνυσμα σφάλματος από όλα τα επίπεδα εξόδου αθροίζεται για να ρυθμιστούν τα βάρη μέσω μιας μεθόδου backpropagation.
Ποιο μοντέλο να διαλέξω;
Το CBOW είναι αρκετές φορές ταχύτερο από το skip-gram και παρέχει καλύτερη συχνότητα για συχνές λέξεις, ενώ το skip-gram χρειάζεται μια μικρή ποσότητα δεδομένων εκπαίδευσης και αντιπροσωπεύει ακόμη και σπάνιες λέξεις ή φράσεις. Ο παρακάτω πίνακας συγκρίνει και τις δύο αρχιτεκτονικές με μια ματιά.
| Άποψη | CBOW | Skip-Gram |
|---|---|---|
| Πρόβλεψη | Προβλέπει τη λέξη-στόχο από τα συμφραζόμενα | Προβλέπει τα συμφραζόμενα από τη λέξη-στόχο |
| Ταχύτητα προπόνησης | Ταχύτερη | Βραδύτερη |
| Συχνές λέξεις | Μεγαλύτερη ακρίβεια | Χαμηλότερη ακρίβεια |
| Σπάνιες λέξεις | Ασθενέστερη εκπροσώπηση | Ισχυρότερη εκπροσώπηση |
| Δεδομένα εκπαίδευσης | Χρειάζονται περισσότερα δεδομένα | Λειτουργεί με λιγότερα δεδομένα |
Η σχέση μεταξύ Word2vec και NLTK
NLTK είναι το Φυσικό Language Toolκιτ. Χρησιμοποιείται για την προεπεξεργασία κειμένου. Μπορεί κανείς να εκτελέσει διαφορετικές λειτουργίες όπως προσθήκη ετικετών σε μέρη του λόγου, λεματική, δημιουργία θεμάτων, αφαίρεση λέξεων-κλειδιών και αφαίρεση σπάνιων ή λιγότερο χρησιμοποιούμενων λέξεων. Βοηθά στον καθαρισμό του κειμένου καθώς και στην προετοιμασία χαρακτηριστικών από τις αποτελεσματικές λέξεις. Από την άλλη πλευρά, το Word2vec χρησιμοποιείται για σημασιολογική (στενά συνδεδεμένα στοιχεία μεταξύ τους) και συντακτική (ακολουθία) αντιστοίχιση. Χρησιμοποιώντας το Word2vec, μπορεί κανείς να βρει παρόμοιες λέξεις, ανόμοιες λέξεις, μείωση διαστάσεων και πολλά άλλα. Ένα άλλο σημαντικό χαρακτηριστικό του Word2vec είναι η μετατροπή της αναπαράστασης κειμένου υψηλότερης διάστασης σε διανύσματα χαμηλότερης διάστασης.
Πού να χρησιμοποιήσετε το NLTK και το Word2vec;
Αν κάποιος πρέπει να ολοκληρώσει κάποιες εργασίες γενικής χρήσης όπως αναφέρθηκαν παραπάνω, όπως η δημιουργία διακριτικών, η ετικέτα POS και η ανάλυση, πρέπει να επιλέξει το NLTK, ενώ για την πρόβλεψη λέξεων σύμφωνα με κάποιο πλαίσιο, τη μοντελοποίηση θεμάτων ή την ομοιότητα εγγράφων, πρέπει να χρησιμοποιήσει το Word2vec.
Σχέση NLTK και Word2vec με τη βοήθεια κώδικα
Το NLTK και το Word2vec μπορούν να χρησιμοποιηθούν μαζί για την εύρεση παρόμοιων αναπαραστάσεων λέξεων ή συντακτικής αντιστοίχισης. Το κιτ εργαλείων NLTK μπορεί να χρησιμοποιηθεί για τη φόρτωση πολλών πακέτων που συνοδεύουν το NLTK και ένα μοντέλο μπορεί να δημιουργηθεί χρησιμοποιώντας το Word2vec. Στη συνέχεια, μπορεί να δοκιμαστεί σε λέξεις σε πραγματικό χρόνο. Ας δούμε τον συνδυασμό και των δύο στον ακόλουθο κώδικα. Πριν από την περαιτέρω επεξεργασία, ρίξτε μια ματιά στα σώματα κειμένων που παρέχει το NLTK. Μπορείτε να τα κατεβάσετε χρησιμοποιώντας την εντολή:
nltk(nltk.download('all'))

Δείτε το στιγμιότυπο οθόνης για τον κωδικό.
import nltk import gensim from nltk.corpus import abc model = gensim.models.Word2Vec(abc.sents()) X = list(model.wv.vocab) data = model.most_similar('science') print(data)

Παραγωγή:
[('law', 0.9415997266769409), ('practice', 0.9276568293571472), ('discussion', 0.9259148836135864), ('agriculture', 0.9257254004478455), ('media', 0.9232194423675537), ('policy', 0.922248125076294), ('general', 0.9166069030761719), ('undertaking', 0.916458249092102), ('tight', 0.9129181504249573), ('board', 0.9107444286346436)]
Επεξήγηση του Code
- Η βιβλιοθήκη nltk εισάγεται, από όπου μπορείτε να κατεβάσετε το corpus abc που θα χρησιμοποιήσουμε στο επόμενο βήμα.
- Το Gensim εισήχθη. Εάν το Gensim Word2vec δεν είναι εγκατεστημένο, εγκαταστήστε το χρησιμοποιώντας την εντολή "pip3 install gensim". Δείτε το παρακάτω στιγμιότυπο οθόνης.

- Εισαγάγετε το σώμα abc, το οποίο έχει ληφθεί χρησιμοποιώντας το nltk.download('abc').
- Μεταβιβάστε τα αρχεία στο μοντέλο Word2vec, το οποίο εισάγεται χρησιμοποιώντας το Gensim, ως προτάσεις.
- Το λεξιλόγιο αποθηκεύεται με τη μορφή μιας μεταβλητής.
- Το μοντέλο δοκιμάζεται στη λέξη-δείγμα επιστήμη, καθώς αυτά τα αρχεία σχετίζονται με την επιστήμη.
- Εδώ, η παρόμοια λέξη «επιστήμη» προβλέπεται από το μοντέλο.
Activators και Word2Vec
Η συνάρτηση ενεργοποίησης ενός νευρώνα ορίζει την έξοδο αυτού του νευρώνα δεδομένου ενός συνόλου εισόδων. Είναι βιολογικά εμπνευσμένη από τη δραστηριότητα στον εγκέφαλό μας, όπου διαφορετικοί νευρώνες ενεργοποιούνται χρησιμοποιώντας διαφορετικά ερεθίσματα. Ας κατανοήσουμε τη συνάρτηση ενεργοποίησης μέσω του ακόλουθου διαγράμματος.

Εδώ x1, x2, … x4 είναι οι κόμβοι του νευρωνικού δικτύου.
w1, w2, w3 είναι τα βάρη των κόμβων.
Το άθροισμα (Σ) όλων των βαρών και των τιμών κόμβων λειτουργεί ως συνάρτηση ενεργοποίησης.
Γιατί η λειτουργία ενεργοποίησης;
Εάν δεν χρησιμοποιείται συνάρτηση ενεργοποίησης, η έξοδος θα είναι γραμμική, αλλά η λειτουργικότητα μιας γραμμικής συνάρτησης είναι περιορισμένη. Για να επιτευχθεί σύνθετη λειτουργικότητα όπως η ανίχνευση αντικειμένων, η ταξινόμηση εικόνων, ηping κείμενο χρησιμοποιώντας φωνή και πολλές άλλες μη γραμμικές εξόδους, απαιτείται μια συνάρτηση ενεργοποίησης.
Πώς υπολογίζεται το επίπεδο ενεργοποίησης στην ενσωμάτωση λέξης (Word2vec)
Το Επίπεδο Softmax (κανονικοποιημένη εκθετική συνάρτηση) είναι η συνάρτηση επιπέδου εξόδου που ενεργοποιεί ή πυροδοτεί κάθε κόμβο. Μια άλλη προσέγγιση που χρησιμοποιείται είναι το Ιεραρχικό softmax, όπου η πολυπλοκότητα υπολογίζεται από τον τύπο O(log2V), ενώ στο softmax είναι O(V), όπου V είναι το μέγεθος του λεξιλογίου. Η διαφορά μεταξύ αυτών είναι η μείωση της πολυπλοκότητας στο ιεραρχικό επίπεδο softmax. Για να κατανοήσετε τη λειτουργικότητά του, ανατρέξτε στο παρακάτω παράδειγμα ενσωμάτωσης Word:

Ας υποθέσουμε ότι θέλουμε να υπολογίσουμε την πιθανότητα να παρατηρήσουμε τη λέξη αγάπη δεδομένου ενός συγκεκριμένου πλαισίου. Η ροή από τη ρίζα στον κόμβο φύλλου θα μετακινηθεί πρώτα στον κόμβο 2 και στη συνέχεια στον κόμβο 5. Έτσι, αν έχουμε μέγεθος λεξιλογίου 8, χρειάζονται μόνο τρεις υπολογισμοί. Αυτό επιτρέπει την ανάλυση του υπολογισμού της πιθανότητας μιας λέξης (αγάπη).
Ποιες άλλες επιλογές είναι διαθέσιμες εκτός από το Hierarchical Softmax;
Σε γενικές γραμμές, οι διαθέσιμες επιλογές ενσωμάτωσης λέξεων είναι Differentiated Softmax, CNN-Softmax, Importance Sampling, Adaptive Importance Sampling, Noise Contrastive Estimation, Negative Sampling, Self-Normalization και Infrequent Normalization.
Μιλώντας συγκεκριμένα για το Word2vec, διαθέτουμε αρνητική δειγματοληψία.
Η Αρνητική Δειγματοληψία είναι ένας τρόπος δειγματοληψίας των δεδομένων εκπαίδευσης. Μοιάζει κάπως με την στοχαστική βαθμιδωτή κάθοδο, αλλά με κάποια διαφορά. Η αρνητική δειγματοληψία αναζητά μόνο παραδείγματα αρνητικής εκπαίδευσης. Βασίζεται στην εκτίμηση της αντίθεσης θορύβου και λαμβάνει τυχαία δείγματα λέξεων που δεν βρίσκονται στο πλαίσιο. Είναι μια γρήγορη μέθοδος εκπαίδευσης και επιλέγει τυχαία το πλαίσιο. Εάν η προβλεπόμενη λέξη εμφανίζεται στο τυχαία επιλεγμένο πλαίσιο, και τα δύο διανύσματα είναι κοντά το ένα στο άλλο.
Τι συμπέρασμα μπορεί να εξαχθεί;
Οι ενεργοποιητές ενεργοποιούν τους νευρώνες όπως ακριβώς ενεργοποιούνται οι νευρώνες μας χρησιμοποιώντας εξωτερικά ερεθίσματα. Το επίπεδο Softmax είναι μία από τις συναρτήσεις του επιπέδου εξόδου που ενεργοποιεί τους νευρώνες στην περίπτωση ενσωμάτωσης λέξεων. Στο Word2vec, έχουμε επιλογές όπως ιεραρχική softmax και αρνητική δειγματοληψία. Χρησιμοποιώντας ενεργοποιητές, μπορεί κανείς να μετατρέψει μια γραμμική συνάρτηση σε μια μη γραμμική συνάρτηση και ένας σύνθετος αλγόριθμος μηχανικής μάθησης μπορεί να υλοποιηθεί χρησιμοποιώντας τέτοιες συναρτήσεις.
Τι είναι το Gensim;
Τζένσιμ είναι μια εργαλειοθήκη μοντελοποίησης θεμάτων ανοιχτού κώδικα και επεξεργασίας φυσικής γλώσσας που υλοποιείται στο Python και Cython. Το κιτ εργαλείων Gensim επιτρέπει στους χρήστες να εισάγουν το Word2vec για μοντελοποίηση θεμάτων, ώστε να ανακαλύψουν κρυφή δομή στο σώμα κειμένου. Το Gensim παρέχει όχι μόνο μια υλοποίηση του Word2vec, αλλά και το Doc2vec και το FastText.
Αυτή η ενότητα επικεντρώνεται στο Word2vec, επομένως θα επιμείνουμε στο τρέχον θέμα.
Πώς να εφαρμόσετε το Word2vec χρησιμοποιώντας το Gensim
Μέχρι τώρα, έχουμε συζητήσει τι είναι το Word2vec, τις διαφορετικές αρχιτεκτονικές του, γιατί υπάρχει μια μετατόπιση από μια «τσάντα» λέξεων στο Word2vec, τη σχέση μεταξύ Word2vec και NLTK με ζωντανό κώδικα και τις συναρτήσεις ενεργοποίησης.
Παρακάτω είναι η βήμα προς βήμα μέθοδος για την υλοποίηση του Word2vec χρησιμοποιώντας το Gensim:
Βήμα 1) Συλλογή δεδομένων
Το πρώτο βήμα για την εφαρμογή οποιουδήποτε μοντέλου μηχανικής μάθησης ή την εφαρμογή επεξεργασίας φυσικής γλώσσας είναι η συλλογή δεδομένων.
Παρακαλούμε παρατηρήστε τα δεδομένα για να δημιουργήσετε ένα έξυπνο chatbot όπως φαίνεται στο παρακάτω παράδειγμα Gensim Word2vec.
[{"tag": "welcome",
"patterns": ["Hi", "How are you", "Is any one to talk?", "Hello", "hi are you available"],
"responses": ["Hello, thanks for contacting us", "Good to see you here", "Hi there, how may I assist you?"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "I will come back soon"],
"responses": ["See you later, thanks for visiting", "have a great day ahead", "Wish you Come back again soon."]
},
{"tag": "thankful",
"patterns": ["Thanks for helping me", "Thank your guidance", "That's helpful and kind from you"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "It is my duty to help you"]
},
{"tag": "hoursopening",
"patterns": ["What hours are you open?", "Tell your opening time?", "When are you open?", "Just your timing please"],
"responses": ["We're open every day 8am-7pm", "Our office hours are 8am-7pm every day", "We open office at 8 am and close at 7 pm"]
},
{"tag": "payments",
"patterns": ["Can I pay using credit card?", "Can I pay using Mastercard?", "Can I pay using cash only?"],
"responses": ["We accept VISA, Mastercard and credit card", "We accept credit card, debit cards and cash. Please don't worry"]
}
]
Να τι καταλαβαίνουμε από τα δεδομένα:
- Αυτά τα δεδομένα περιέχουν τρία πράγματα: ετικέτα, μοτίβο και απαντήσεις. Η ετικέτα είναι η πρόθεση (ποιο είναι το θέμα της συζήτησης).
- Τα δεδομένα είναι σε μορφή JSON.
- Ένα μοτίβο είναι μια ερώτηση που οι χρήστες θα κάνουν στο bot.
- Οι απαντήσεις είναι οι απαντήσεις που θα παρέχει το chatbot στην αντίστοιχη ερώτηση/μοτίβο.
Βήμα 2) Προεπεξεργασία δεδομένων
Είναι πολύ σημαντικό να επεξεργάζεστε τα ακατέργαστα δεδομένα. Εάν τα καθαρισμένα δεδομένα τροφοδοτηθούν στο μηχάνημα, τότε το μοντέλο θα ανταποκριθεί με μεγαλύτερη ακρίβεια και θα μάθει τα δεδομένα πιο αποτελεσματικά.
Αυτό το βήμα περιλαμβάνει την αφαίρεση λέξεων διακοπής, θεμάτων, περιττών λέξεων κ.λπ. Πριν προχωρήσετε, είναι σημαντικό να φορτώσετε δεδομένα και να τα μετατρέψετε σε ένα πλαίσιο δεδομένων. Ανατρέξτε στον παρακάτω κώδικα για αυτό.
import json json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f)
Επεξήγηση του Code:
- Καθώς τα δεδομένα είναι σε μορφή JSON, το json εισάγεται.
- Το αρχείο αποθηκεύεται στη μεταβλητή.
- Το αρχείο ανοίγει και φορτώνεται στη μεταβλητή δεδομένων.
Τώρα τα δεδομένα εισάγονται και είναι καιρός να τα μετατρέψετε σε ένα πλαίσιο δεδομένων. Ανατρέξτε στον παρακάτω κώδικα για το επόμενο βήμα.
import pandas as pd df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join)
Επεξήγηση του Code:
1. Τα δεδομένα μετατρέπονται σε ένα πλαίσιο δεδομένων χρησιμοποιώντας pandas, τα οποία εισήχθησαν παραπάνω.
2. Μετατρέπει τη λίστα στα μοτίβα στηλών σε συμβολοσειρά.
from nltk.corpus import stopwords from textblob import Word stop = stopwords.words('english') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
Code Επεξήγηση:
1. Οι αγγλικές λέξεις-κλειδιά εισαγωγής εισάγονται χρησιμοποιώντας τη λειτουργική μονάδα λέξεων-κλειδιών από το κιτ εργαλείων nltk.
2. Όλες οι λέξεις του κειμένου μετατρέπονται σε πεζά γράμματα χρησιμοποιώντας μια συνθήκη for και μια συνάρτηση λάμδα. A Λειτουργία λάμδα είναι μια ανώνυμη συνάρτηση.
3. Όλες οι γραμμές του κειμένου στο πλαίσιο δεδομένων ελέγχονται για σημεία στίξης συμβολοσειρών και αυτά φιλτράρονται.
4. Χαρακτήρες όπως αριθμοί ή τελείες αφαιρούνται χρησιμοποιώντας μια κανονική έκφραση.
5. Digits αφαιρούνται από το κείμενο.
6. Οι λέξεις διακοπής αφαιρούνται σε αυτό το στάδιο.
7. Οι λέξεις φιλτράρονται τώρα και οι διαφορετικές μορφές της ίδιας λέξης αφαιρούνται χρησιμοποιώντας λημματοποίηση. Με αυτά, έχουμε ολοκληρώσει την προεπεξεργασία δεδομένων.
Παραγωγή:
, patterns, responses, tag 0,hi one talk hello hi available,"['Hello, thanks for contacting us', 'Good to see you here', ' Hi there, how may I assist you?']",welcome 1,bye see later goodbye come back soon,"['See you later, thanks for visiting', 'have a great day ahead', 'Wish you Come back again soon.']",goodbye 2,thanks helping thank guidance thats helpful kind,"['Happy to help!', 'Any time!', 'My pleasure', 'It is my duty to help you']",thankful 3,hour open tell opening time open timing please,"[""We're open every day 8am-7pm"", 'Our office hours are 8am-7pm every day', 'We open office at 8 am and close at 7 pm']",hoursopening 4,pay using credit card pay using mastercard pay using cash,"['We accept VISA, Mastercard and credit card', 'We accept credit card, debit cards and cash. Please dont worry']",payments
Βήμα 3) Κατασκευή νευρωνικού δικτύου με χρήση του Word2vec
Τώρα είναι η ώρα να κατασκευάσουμε ένα μοντέλο χρησιμοποιώντας την ενότητα Gensim Word2vec. Πρέπει να εισαγάγουμε το Word2vec από το Gensim. Ας το κάνουμε αυτό, και στη συνέχεια θα το κατασκευάσουμε, και στο τελικό στάδιο θα ελέγξουμε το μοντέλο σε δεδομένα πραγματικού χρόνου.
from gensim.models import Word2Vec
Τώρα μπορούμε να κατασκευάσουμε με επιτυχία το μοντέλο χρησιμοποιώντας το Word2Vec. Ανατρέξτε στην επόμενη γραμμή κώδικα για να μάθετε πώς να δημιουργήσετε το μοντέλο χρησιμοποιώντας το Word2Vec. Το κείμενο παρέχεται στο μοντέλο με τη μορφή λίστας, επομένως θα μετατρέψουμε το κείμενο από το πλαίσιο δεδομένων σε λίστα χρησιμοποιώντας τον παρακάτω κώδικα.
Bigger_list = [] for i in df['patterns']: li = list(i.split("")) Bigger_list.append(li) Model = Word2Vec(Bigger_list, min_count=1, size=300, workers=4)
Επεξήγηση του Code:
1. Δημιουργήθηκε το bigger_list όπου προσαρτάται η εσωτερική λίστα. Αυτή είναι η μορφή που τροφοδοτείται στο μοντέλο Word2Vec.
2. Υλοποιείται ένας βρόχος και κάθε καταχώρηση της στήλης μοτίβων του πλαισίου δεδομένων επαναλαμβάνεται.
3. Κάθε στοιχείο των μοτίβων στηλών διαιρείται και αποθηκεύεται στην εσωτερική λίστα li.
4. Η εσωτερική λίστα προσαρτάται στην εξωτερική λίστα.
5. Αυτή η λίστα παρέχεται στο μοντέλο Word2Vec. Ας κατανοήσουμε ορισμένες από τις παραμέτρους που παρέχονται εδώ.
Min_count: Αγνοεί όλες τις λέξεις με συνολική συχνότητα χαμηλότερη από αυτήν.
Διαστάσεις: Λέει τη διάσταση των διανυσμάτων λέξεων.
Εργαζόμενοι: Αυτά είναι τα νήματα για την εκπαίδευση του μοντέλου.
Υπάρχουν επίσης και άλλες διαθέσιμες επιλογές και μερικές σημαντικές εξηγούνται παρακάτω.
Παράθυρο: Μέγιστη απόσταση μεταξύ της τρέχουσας και της προβλεπόμενης λέξης μέσα σε μια πρόταση.
Sg: Είναι ένας αλγόριθμος εκπαίδευσης: 1 για το skip-gram και 0 για ένα Continuous Bag of Words. Τα έχουμε συζητήσει λεπτομερώς παραπάνω.
Hs: Αν αυτό είναι 1, τότε χρησιμοποιούμε ιεραρχική softmax για εκπαίδευση, και αν είναι 0, τότε χρησιμοποιείται αρνητική δειγματοληψία.
Αλφα: Αρχικός ρυθμός εκμάθησης.
Ας εμφανίσουμε τον τελικό κωδικό παρακάτω:
# list of libraries used by the code import string from gensim.models import Word2Vec import logging from nltk.corpus import stopwords from textblob import Word import json import pandas as pd # data in json format json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f) # displaying the list of stopwords stop = stopwords.words('english') # dataframe df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join) # cleaning the data using the NLP approach print(df) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()])) # taking the outer list bigger_list = [] for i in df['patterns']: li = list(i.split(" ")) bigger_list.append(li) # structure of data to be taken by the model.word2vec print("Data format for the overall list:", bigger_list) # custom data is fed to machine for further processing model = Word2Vec(bigger_list, min_count=1, size=300, workers=4)
Βήμα 4) Αποθήκευση μοντέλου
Το μοντέλο μπορεί να αποθηκευτεί με τη μορφή bin και αρχείου μοντέλου. Το Bin είναι η δυαδική μορφή. Δείτε τις παρακάτω γραμμές για να αποθηκεύσετε το μοντέλο.
model.save("word2vec.model") model.save("model.bin")
Επεξήγηση του παραπάνω κώδικα
1. Το μοντέλο αποθηκεύεται με τη μορφή αρχείου .model.
2. Το μοντέλο αποθηκεύεται με τη μορφή αρχείου .bin.
Θα χρησιμοποιήσουμε αυτό το μοντέλο για να κάνουμε δοκιμές σε πραγματικό χρόνο, όπως παρόμοιες λέξεις, ανόμοιες λέξεις και πιο συνηθισμένες λέξεις.
Βήμα 5) Φόρτωση μοντέλου και εκτέλεση δοκιμών σε πραγματικό χρόνο
Το μοντέλο φορτώνεται χρησιμοποιώντας τον παρακάτω κώδικα:
model = Word2Vec.load('model.bin')
Αν θέλετε να εκτυπώσετε το λεξιλόγιο από αυτό, αυτό γίνεται χρησιμοποιώντας την παρακάτω εντολή:
vocab = list(model.wv.vocab)
Δείτε το αποτέλεσμα:
['see', 'thank', 'back', 'thanks', 'soon', 'open', 'mastercard', 'card', 'time', 'pay', 'talk', 'cash', 'one', 'please', 'goodbye', 'thats', 'helpful', 'hour', 'credit', 'hi', 'later', 'guidance', 'opening', 'timing', 'hello', 'helping', 'bye', 'tell', 'come', 'using', 'kind', 'available']
Βήμα 6) Έλεγχος των περισσότερων παρόμοιων λέξεων
Ας εφαρμόσουμε τα πράγματα πρακτικά:
similar_words = model.most_similar('thanks') print(similar_words)
Δείτε το αποτέλεσμα:
[('kind', 0.16104359924793243), ('using', 0.1352398842573166), ('come', 0.11500970274209976), ('later', 0.09989878535270691), ('helping', 0.04855936020612717), ('credit', 0.04659383371472359), ('pay', 0.0329081267118454), ('thank', 0.02484947443008423), ('hour', 0.0202352125197649), ('opening', 0.018177658319473267)]
Βήμα 7) Δεν ταιριάζει με τις λέξεις που παρέχονται
dissimlar_words = model.doesnt_match('See you later, thanks for visiting'.split()) print(dissimlar_words)
Έχουμε δώσει τις λέξεις «Τα λέμε αργότερα, ευχαριστώ για την επίσκεψή σας»Αυτό εκτυπώνει την πιο ανόμοια λέξη από αυτές τις λέξεις. Ας εκτελέσουμε αυτόν τον κώδικα και ας βρούμε το αποτέλεσμα.
Το αποτέλεσμα μετά την εκτέλεση του παραπάνω κώδικα:
Thanks
Βήμα 8) Εύρεση της ομοιότητας μεταξύ δύο λέξεων
Αυτό δείχνει το αποτέλεσμα με βάση την πιθανότητα ομοιότητας μεταξύ δύο λέξεων. Δείτε τον παρακάτω κώδικα για τον τρόπο εκτέλεσης αυτής της ενότητας.
similarity_two_words = model.similarity('please', 'see') print("Please provide the similarity between these two words:") print(similarity_two_words)
Το αποτέλεσμα του παραπάνω κώδικα είναι το παρακάτω:
0.13706
Μπορείτε να βρείτε παρόμοιες λέξεις εκτελώντας τον παρακάτω κώδικα:
similar = model.similar_by_word('kind') print(similar)
Έξοδος του παραπάνω κώδικα:
[('credit', 0.11764447391033173), ('cash', 0.11440904438495636), ('one', 0.11151769757270813), ('hour', 0.0944807156920433), ('using', 0.0705675333738327), ('thats', 0.05206916481256485), ('later', 0.04502468928694725), ('bye', 0.03960943967103958), ('back', 0.03837274760007858), ('thank', 0.0380823090672493)]