単語埋め込みとWord2Vecの例
⚡ スマートサマリー
単語埋め込みとWord2Vecは、テキストを密な数値ベクトルに変換することで、機械学習モデルが類似した意味を持つ単語を認識できるようにします。この資料では、その技術、CBOWおよびSkip-Gramアーキテクチャ、活性化関数、そして実際のアプリケーション向けのGensimによる完全な実装について説明します。
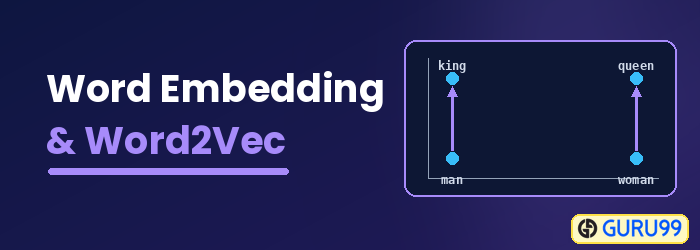
Word 埋め込みとは何ですか?
単語の埋め込み は、機械学習アルゴリズムが類似の意味を持つ単語を理解できるようにする単語表現タイプです。これは、ニューラルネットワーク、確率モデル、または単語共起行列の次元削減を使用して、単語を実数のベクトルにマッピングする言語モデリングおよび特徴学習技術です。いくつかの単語埋め込みモデルは Word2vec (Google)、GloVe(スタンフォード大学)、fastText(Facebook)。
単語埋め込みは、分散意味モデル、分散表現モデル、意味ベクトル空間、またはベクトル空間モデルとも呼ばれます。これらの名前を読むと、単語に出会います。 セマンティックつまり、似たような単語をまとめて分類するということです。例えば、リンゴ、マンゴー、バナナといった果物は近くに配置されるのに対し、本はこれらの単語から遠く離れた場所に配置されます。より広い意味では、単語埋め込みによって、果物のベクトル表現が本のベクトル表現から遠く離れた場所に配置されます。
Word の埋め込みはどこで使用されますか?
単語埋め込みは、特徴量生成、文書クラスタリング、テキスト分類、自然言語処理などのタスクに役立ちます。これらの応用例を列挙し、それぞれについて説明しましょう。
- 類似した単語を計算します。 単語埋め込みは、予測モデルの対象となる単語に類似した単語を提案するために使用されます。それに加えて、類似していない単語や、最も頻繁に使用される単語も提案します。
- 関連する単語のグループを作成します。 これは意味グループに使用されますpingこれは、似たような特徴を持つものをまとめてグループ化し、似ていないものを遠ざけるものです。
- テキスト分類の機能: テキストはベクトル配列にマッピングされ、モデルの学習と予測に使用されます。テキストベースの分類モデルは文字列では学習できないため、この処理によってテキストが機械学習に適した形式に変換されます。また、意味構築機能により、テキストベースの分類がさらに容易になります。
- ドキュメントのクラスタリング: これは、単語埋め込みとWord2vecが広く利用されているもう一つの応用例です。
- 自然言語処理: 単語埋め込みが有用で特徴抽出よりも優れているアプリケーションは数多くありますtrac品詞タグ付け、感情分析、構文分析などの段階。
単語埋め込みがどのような場面で適用されるかを理解できたところで、これらの埋め込みを作成するために最もよく使われるモデルを見ていきましょう。
Word2vecとは何ですか?
Word2vec これは、単語の表現を向上させるために単語埋め込みを生成する技術またはモデルです。多数の正確な構文的および意味的な単語間の関係を捉える自然言語処理手法です。これは、学習後に同義語を検出し、部分的な文に対して追加の単語を提案できる浅い2層ニューラルネットワークです。
先に進む前に、以下の単語埋め込みの例図に示すように、浅いニューラルネットワークと深いニューラルネットワークの違いを確認してください。
浅層ニューラルネットワークは入力と出力の間に隠れ層が1つしかないのに対し、深層ニューラルネットワークは入力と出力の間に複数の隠れ層を持つ。入力はノードによって処理され、隠れ層と出力層はニューロンで構成される。
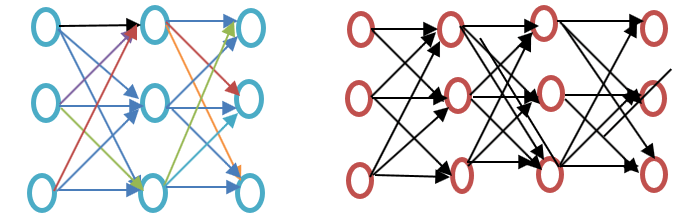
Word2vecは、入力層、1つの隠れ層、および出力層からなる2層ネットワークです。
Word2vecは、Tomas Mikolovが率いる研究者グループによって開発されました。 GoogleWord2vecは、潜在意味解析モデルよりも優れており、効率的です。
Word2vec を使用する理由
Word2vecは、単語をベクトル空間表現で表します。単語はベクトルの形で表現され、意味が似ている単語は近くに、意味が異なる単語は遠くに配置されます。これは意味関係とも呼ばれます。ニューラルネットワークはテキストを理解せず、数値のみを理解します。単語埋め込みは、テキストを数値ベクトルに変換する方法を提供します。
Word2vecは単語の言語的文脈を再構築します。先に進む前に、言語的文脈とは何かを理解しておきましょう。一般的に、私たちが話したり書いたりしてコミュニケーションをとる際、他の人はその文の目的を理解しようとします。例えば、「インドの気温は何度ですか?」という文の場合、文脈はユーザーが「インドの気温」を知りたいということです。つまり、文の主な目的は文脈です。話し言葉や書き言葉の周りの単語や文は、文脈の意味を判断するのに役立ちます。Word2vecは、これらの文脈を通して単語のベクトル表現を学習します。
Word2vec は何をするのですか?
Word埋め込み前
単語埋め込み以前にどのような手法が用いられていたのか、そしてその欠点は何かを知ることが重要です。次に、Word2vecを用いた単語埋め込みによって、それらの欠点がどのように克服されるのかを見ていきます。最後に、Word2vecの動作原理について説明します。その仕組みを理解することは非常に重要です。
潜在意味解析のアプローチ
これは、単語埋め込み以前に用いられていた手法です。単語をエンコードされたベクトルで表現する「単語の袋(Bag of Words)」の概念に基づいています。これは、次元が語彙のサイズに等しい疎なベクトル表現です。単語が辞書に存在する場合はカウントされ、存在しない場合はカウントされません。詳細については、以下のプログラムをご覧ください。
Word2vec の例

from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() data_corpus = ["guru99 is the best site for online tutorials. I love to visit guru99."] vocabulary = vectorizer.fit(data_corpus) X = vectorizer.transform(data_corpus) print(X.toarray()) print(vectorizer.get_feature_names_out())
出力:
[[1 2 1 1 1 1 1 1 1 1]] [u'best', u'guru99', u'is', u'love', u'online', u'sitefor', u'the', u'to', u'tutorials', u'visit']
Code 説明
- CountVectorizerは、単語を適切な形に並べることで語彙を格納するために使用されるモジュールです。これはsklearnからインポートされます。
- CountVectorizer クラスを使用してオブジェクトを作成します。
- CountVectorizerに適合させるリスト内のデータを書き込みます。
- データは、CountVectorizer クラスから作成されたオブジェクトに収まります。
- 語彙を用いてデータ内の単語数をカウントするために、単語袋法を適用します。単語またはトークンが語彙に含まれていない場合は、そのインデックス位置をゼロに設定します。
- 5行目の変数xは配列に変換されます(xで利用可能なメソッド)。これにより、3行目で指定された文またはリスト内の各トークンの出現回数が取得されます。
- これは、4行目のデータを使用して適合させた場合に、語彙に含まれる特徴を示しています。
潜在意味論的アプローチでは、行は固有の単語を表し、列はその単語が文書中に出現する回数を表します。これは、文書行列の形式で単語を表現したものです。TF-IDF(Term Frequency-Inverse Document Frequency)は、文書中の単語の頻度をカウントするために使用され、これは文書中の単語の頻度をコーパス全体の単語の頻度で割った値です。
Bag of Words 法の欠点
- 単語の順序は無視されます。たとえば、 これは悪いです = これは悪い.
- これは単語の文脈を無視します。例えば、「彼は本が好きだった。教育は本の中に最もよく見出される。」という文を書いたとします。すると、「彼は本が好きだった」と「教育は本の中に最もよく見出される。」という2つのベクトルが作成されます。このベクトルは両方を直交しているとみなし、独立しているように扱いますが、実際には両者は関連しています。
これらの限界を克服するために、単語埋め込みが開発され、Word2vecはその実装に用いられる手法の一つである。
Word2vec はどのように機能するのでしょうか?
Word2vecは、単語の周囲の文脈を予測することで単語を学習します。例えば、「He」という単語を見てみましょう。 で フットボール。"
単語のWord2vecを計算したい。 で.
仮定:
loves = Vin. P(Vout / Vin) is calculated where, Vin is the input word. P is the probability of likelihood. Vout is the output word.
抽出時間と で コーパス内の各単語を順に処理します。単語間の構文的および意味的な関係が符号化されます。これにより、類似語や類推語を見つけるのに役立ちます。
単語のすべてのランダムな特徴 で これらの特徴は計算されます。これらの特徴は、隣接語または文脈語に関して、 誤差逆伝播法 方法。
もう一つの学習方法としては、2つの単語の文脈が似ている場合、あるいは2つの単語が似たような特徴を持っている場合、それらの単語は関連していると考えるという方法がある。
Word2vec Archi構造
Word2vec で使用されるアーキテクチャは XNUMX つあります。
- 連続バッグ・オブ・ワード (CBOW)
- スキップグラム
先に進む前に、単語表現の観点から、これらのアーキテクチャやモデルがなぜ重要なのかを説明しましょう。単語表現の学習は基本的に教師なし学習ですが、モデルを訓練するにはターゲット/ラベルが必要です。Skip-gramとCBOWは、教師なし表現をモデル訓練のための教師あり形式に変換します。
CBOWでは、現在の単語は周囲のコンテキストウィンドウのウィンドウを使用して予測されます。たとえば、wI-1、ワットI-2、ワットi + 1、ワットi + 2 単語またはコンテキストが与えられると、このモデルは以下の情報を提供します。i.
Skip-GramはCBOWとは逆の動作をします。つまり、単語から与えられたシーケンスまたはコンテキストを予測します。例を逆にして理解することができます。i が与えられると、これはコンテキストを予測します、またはI-1、ワットI-2、ワットi + 1、ワットi + 2.
Word2vecでは、CBOW(Continuous Bag of Words)とskip-gramのどちらかを選択できるオプションが用意されています。これらのパラメータは、モデルのトレーニング中に指定できます。また、ネガティブサンプリングや階層型ソフトマックス層を使用するオプションもあります。
言葉の連続バッグ
連続的な単語袋アーキテクチャを理解するために、Word2vecの簡単な例となる図を描いてみましょう。

方程式を数学的に計算してみましょう。 V が語彙サイズ、N が隠れ層サイズであると仮定します。 入力は { x として定義されますI-1、XI-2、Xi + 1、Xi + 2 }。重み行列は、V * N を乗算することによって得られます。別の行列は、入力ベクトルと重み行列を乗算することによって得られます。これは、次の式によっても理解できます。
h = xitW
ここでxit WとWはそれぞれ入力ベクトルと重み行列である。
文脈と次の単語の一致度を計算するには、以下の式を参照してください。
u = 予測表現 * h
ここで、predictedrepresentationは上記の式で示されるモデルから得られる。
スキップグラムモデル
Skip-Gram法は、入力された単語から文を予測するために使用されます。これをよりよく理解するために、以下のWord2vecの例に示す図を描いてみましょう。

これは、入力が単語であり、モデルが文脈またはシーケンスを提供するという、連続単語バッグモデルの逆と捉えることができます。また、ターゲットが入力に渡され、出力層が選択された数の文脈単語に対応するために複数回複製されると考えることもできます。すべての出力層からの誤差ベクトルが合計され、バックプロパゲーション法によって重みが調整されます。
どのモデルを選択しますか?
CBOWはskip-gramよりも数倍高速で、頻繁に出現する単語の頻度をより正確に把握できます。一方、skip-gramは少量の学習データで済み、まれな単語やフレーズも表現できます。以下の表は、両方のアーキテクチャを一目で比較したものです。
| 側面 | CBOW | スキップグラム |
|---|---|---|
| 予測 | 文脈からターゲット単語を予測します | 対象単語から文脈を予測する |
| トレーニング速度 | 速く | もっとゆっくり |
| よく使われる単語 | より高い精度 | 精度が低い |
| 珍しい言葉 | 代表性の弱さ | より強力な代表性 |
| トレーニングデータ | さらなるデータが必要 | 少ないデータで動作します |
Word2vecとNLTKの関係
NLTK 自然な Language Toolキット。テキストの前処理に使用されます。品詞タグ付け、語幹抽出、語幹抽出、ストップワード除去、まれな単語や使用頻度の低い単語の除去など、さまざまな操作を実行できます。テキストのクリーニングと、有効な単語からの特徴抽出に役立ちます。一方、Word2vec は、意味的 (密接に関連する項目をまとめて) および構文的 (順序) マッチングに使用されます。Word2vec を使用すると、類似語、非類似語、次元削減など、さまざまな機能を見つけることができます。Word2vec のもう 1 つの重要な機能は、テキストの高次元表現を低次元ベクトルに変換することです。
NLTK と Word2vec をどこで使用するのですか?
上記のようなトークン化、品詞タグ付け、構文解析といった汎用的なタスクを実行する場合はNLTKを使用する必要がある一方、文脈、トピックモデリング、文書類似性に基づいて単語を予測する場合はWord2vecを使用する必要がある。
コードを使用した NLTK と Word2vec の関係
NLTKとWord2vecは、類似した単語表現や構文の一致を見つけるために併用できます。NLTKツールキットを使用すると、NLTKに付属する多くのパッケージをロードでき、Word2vecを使用してモデルを作成できます。作成したモデルは、実際の単語でテストできます。以下のコードで、両者の組み合わせを見てみましょう。さらに処理を進める前に、NLTKが提供するコーパスを確認してください。以下のコマンドを使用してダウンロードできます。
nltk(nltk.download('all'))

コードのスクリーンショットを参照してください。
import nltk import gensim from nltk.corpus import abc model = gensim.models.Word2Vec(abc.sents()) X = list(model.wv.vocab) data = model.most_similar('science') print(data)

出力:
[('law', 0.9415997266769409), ('practice', 0.9276568293571472), ('discussion', 0.9259148836135864), ('agriculture', 0.9257254004478455), ('media', 0.9232194423675537), ('policy', 0.922248125076294), ('general', 0.9166069030761719), ('undertaking', 0.916458249092102), ('tight', 0.9129181504249573), ('board', 0.9107444286346436)]
の説明 Code
- nltkライブラリをインポートします。ここから、次のステップで使用するabcコーパスをダウンロードできます。
- Gensimがインポートされました。Gensim Word2vecがインストールされていない場合は、「pip3 install gensim」コマンドを使用してインストールしてください。以下のスクリーンショットを参照してください。

- nltk.download('abc')を使用してダウンロードしたabcコーパスをインポートします。
- Gensimを使用してインポートしたWord2vecモデルに、ファイルを文として渡します。
- 語彙は変数として格納されます。
- このモデルはサンプル単語でテストされます 科学これらのファイルは科学に関連しているため。
- ここでは、「science」という類似語がモデルによって予測されています。
アクティベータと Word2Vec
ニューロンの活性化関数は、一連の入力が与えられたときのそのニューロンの出力を定義します。これは、異なる刺激によって異なるニューロンが活性化される脳内の活動に生物学的に着想を得ています。次の図を通して、活性化関数を理解しましょう。

ここで、x1、x2、…、x4はニューラルネットワークのノードです。
w1、w2、w3はノードの重みです。
すべての重みとノード値の合計(Σ)が活性化関数として機能します。
なぜアクティベーション機能なのか?
活性化関数を使用しない場合、出力は線形になりますが、線形関数の機能には限界があります。物体検出、画像分類、ty などの複雑な機能を実現するには、ping 音声を使用したテキスト出力や、その他多くの非線形出力には、活性化関数が必要です。
単語埋め込み (Word2vec) でのアクティベーション レイヤーの計算方法
ソフトマックス層(正規化指数関数)は、各ノードをアクティブ化または発火させる出力層関数です。別の手法として階層型ソフトマックスがあり、その複雑さはO(log)で計算されます。2語彙サイズをVとすると、softmaxではO(V)となりますが、softmaxではO(V)となります。この違いは、階層型softmax層における計算量の削減にあります。その機能を理解するために、以下の単語埋め込みの例をご覧ください。

単語が観測される確率を計算したいとします。 愛 ある特定のコンテキストが与えられた場合。ルートからリーフノードへの流れは、まずノード2に移動し、次にノード5に移動します。したがって、語彙サイズが8の場合、必要な計算は3つだけです。これにより、1つの単語の確率の計算を分解できます(愛).
階層的ソフトマックス以外に利用できるオプションはありますか?
一般的に、単語埋め込みのオプションとしては、Differentiated Softmax、CNN-Softmax、Importance Sampling、Adaptive Importance Sampling、Noise Contrastive Estimation、Negative Sampling、Self-Normalization、Infrequent Normalizationなどが挙げられます。
Word2vecについて具体的に述べると、ネガティブサンプルが利用可能です。
ネガティブサンプリングは、トレーニングデータをサンプリングする方法の一つです。確率的勾配降下法に似ていますが、いくつかの違いがあります。ネガティブサンプリングは、ネガティブなトレーニング例のみを探します。ノイズコントラスト推定に基づいており、文脈に含まれていない単語をランダムにサンプリングします。高速なトレーニング方法であり、文脈をランダムに選択します。予測された単語がランダムに選択された文脈に現れる場合、両方のベクトルは互いに近くなります。
どのような結論が導き出せるでしょうか?
アクティベーターは、人間のニューロンが外部刺激によって発火するのと同様に、ニューロンを発火させます。ソフトマックス層は、単語埋め込みの場合にニューロンを発火させる出力層関数の1つです。Word2vecでは、階層型ソフトマックスやネガティブサンプリングなどのオプションがあります。アクティベーターを使用することで、線形関数を非線形関数に変換でき、そのような関数を用いて複雑な機械学習アルゴリズムを実装できます。
ゲンシムとは何ですか?
ゲンシム は、オープンソースのトピック モデリングおよび自然言語処理ツールキットであり、 Python また、Cythonも利用できます。Gensimツールキットを使用すると、トピックモデリングのためにWord2vecをインポートして、テキスト本文に隠された構造を発見できます。Gensimは、Word2vecだけでなく、Doc2vecとFastTextの実装も提供しています。
このセクションはWord2vecに焦点を当てているため、現在のトピックに沿って進めていきます。
Gensimを使用してWord2vecを実装する方法
これまで、Word2vecとは何か、その様々なアーキテクチャ、単語の袋からWord2vecへの移行の理由、Word2vecとライブコードを用いたNLTKの関係、そして活性化関数について説明してきました。
Gensimを使用してWord2vecを実装する手順を以下に示します。
ステップ 1) データ収集
機械学習モデルを実装する場合や自然言語処理を実装する場合の最初のステップは、データ収集です。
以下の Gensim Word2vec の例に示すように、データを観察してインテリジェントなチャットボットを構築してください。
[{"tag": "welcome",
"patterns": ["Hi", "How are you", "Is any one to talk?", "Hello", "hi are you available"],
"responses": ["Hello, thanks for contacting us", "Good to see you here", "Hi there, how may I assist you?"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "I will come back soon"],
"responses": ["See you later, thanks for visiting", "have a great day ahead", "Wish you Come back again soon."]
},
{"tag": "thankful",
"patterns": ["Thanks for helping me", "Thank your guidance", "That's helpful and kind from you"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "It is my duty to help you"]
},
{"tag": "hoursopening",
"patterns": ["What hours are you open?", "Tell your opening time?", "When are you open?", "Just your timing please"],
"responses": ["We're open every day 8am-7pm", "Our office hours are 8am-7pm every day", "We open office at 8 am and close at 7 pm"]
},
{"tag": "payments",
"patterns": ["Can I pay using credit card?", "Can I pay using Mastercard?", "Can I pay using cash only?"],
"responses": ["We accept VISA, Mastercard and credit card", "We accept credit card, debit cards and cash. Please don't worry"]
}
]
データから分かったことは以下のとおりです。
- このデータには、タグ、パターン、応答の3つの要素が含まれています。タグは意図(議論のトピック)を表します。
- データはJSON形式です。
- パターンとは、ユーザーがボットに尋ねる質問のことです。
- 応答とは、チャットボットが対応する質問/パターンに対して提供する回答のことです。
ステップ 2) データの前処理
生データを処理することは非常に重要です。 クリーンなデータがマシンに供給されると、モデルはより正確に応答し、より効率的にデータを学習します。
このステップでは、ストップワードの削除、語幹抽出、不要な単語の削除などを行います。先に進む前に、データを読み込み、データフレームに変換することが重要です。以下のコードを参照してください。
import json json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f)
の説明 Code:
- データはJSON形式なので、JSONがインポートされます。
- ファイルは変数に格納されます。
- ファイルが開かれ、データ変数に読み込まれます。
データのインポートが完了したので、次はデータをデータフレームに変換します。次のステップについては、以下のコードを参照してください。
import pandas as pd df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join)
の説明 Code:
1. 上記でインポートしたpandasを使用して、データをデータフレームに変換します。
2. 列パターン内のリストを文字列に変換します。
from nltk.corpus import stopwords from textblob import Word stop = stopwords.words('english') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
Code 説明:
1. 英語のストップワードは、nltkツールキットのストップワードモジュールを使用してインポートされます。
2. テキストのすべての単語は、for条件とラムダ関数を使用して小文字に変換されます。 ラムダ関数 は匿名関数です。
3. データフレーム内のテキストのすべての行について文字列の句読点がチェックされ、句読点がフィルタリングされます。
4. 数字やドットなどの文字は正規表現を使用して削除されます。
5. Digits はテキストから削除されます。
6. ストップワードはこの段階で削除されます。
7. 単語はフィルタリングされ、語幹抽出法を用いて同じ単語の異なる形が削除されます。これでデータの前処理は完了です。
出力:
, patterns, responses, tag 0,hi one talk hello hi available,"['Hello, thanks for contacting us', 'Good to see you here', ' Hi there, how may I assist you?']",welcome 1,bye see later goodbye come back soon,"['See you later, thanks for visiting', 'have a great day ahead', 'Wish you Come back again soon.']",goodbye 2,thanks helping thank guidance thats helpful kind,"['Happy to help!', 'Any time!', 'My pleasure', 'It is my duty to help you']",thankful 3,hour open tell opening time open timing please,"[""We're open every day 8am-7pm"", 'Our office hours are 8am-7pm every day', 'We open office at 8 am and close at 7 pm']",hoursopening 4,pay using credit card pay using mastercard pay using cash,"['We accept VISA, Mastercard and credit card', 'We accept credit card, debit cards and cash. Please dont worry']",payments
ステップ 3) Word2vec を使用したニューラル ネットワークの構築
それでは、GensimのWord2vecモジュールを使ってモデルを構築しましょう。まずはGensimからWord2vecをインポートする必要があります。インポート後、モデルを構築し、最終段階ではリアルタイムデータを使ってモデルの検証を行います。
from gensim.models import Word2Vec
これで、Word2Vec を使用してモデルを正常に構築できます。Word2Vec を使用してモデルを作成する方法については、次のコードを参照してください。テキストはリスト形式でモデルに渡されるため、以下のコードを使用してデータフレームからテキストをリストに変換します。
Bigger_list = [] for i in df['patterns']: li = list(i.split("")) Bigger_list.append(li) Model = Word2Vec(Bigger_list, min_count=1, size=300, workers=4)
の説明 Code:
1. 内側のリストが追加されたbigger_listを作成しました。これがWord2Vecモデルに渡される形式です。
2. ループが実装され、データフレームのpatterns列の各エントリが反復処理されます。
3. 列パターンの各要素は分割され、内部リスト li に格納されます。
4. 内側のリストが外側のリストに追加されます。
5. このリストはWord2Vecモデルに提供されます。ここで提供されるパラメータの一部を理解しましょう。
最小数: この値よりも出現頻度が低い単語はすべて無視されます。
サイズ: これは単語ベクトルの次元を表します。
労働者: これらはモデルをトレーニングするためのスレッドです。
他にも選択肢があり、重要なものについては以下で説明します。
ウィンドウ: 文内の現在の単語と予測された単語の間の最大距離。
代表: これは学習アルゴリズムであり、スキップグラムの場合は1、連続単語袋の場合は0となります。これらについては、上記で詳しく説明しました。
Hs: これが1の場合は、階層型ソフトマックスを使用して学習を行い、0の場合は、ネガティブサンプリングを使用します。
アルファ: 初期学習率。
最終的なコードを以下に表示してみましょう。
# list of libraries used by the code import string from gensim.models import Word2Vec import logging from nltk.corpus import stopwords from textblob import Word import json import pandas as pd # data in json format json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f) # displaying the list of stopwords stop = stopwords.words('english') # dataframe df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join) # cleaning the data using the NLP approach print(df) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()])) # taking the outer list bigger_list = [] for i in df['patterns']: li = list(i.split(" ")) bigger_list.append(li) # structure of data to be taken by the model.word2vec print("Data format for the overall list:", bigger_list) # custom data is fed to machine for further processing model = Word2Vec(bigger_list, min_count=1, size=300, workers=4)
ステップ4) モデルの保存
モデルは、バイナリファイルとモデルファイルという2つの形式で保存できます。バイナリファイルはバイナリ形式です。モデルの保存方法については、以下の手順を参照してください。
model.save("word2vec.model") model.save("model.bin")
上記コードの説明
1. モデルは.modelファイル形式で保存されます。
2. モデルは.binファイル形式で保存されます。
このモデルを使用して、類似語、非類似語、最も頻繁に使用される単語などのリアルタイムテストを実施します。
ステップ 5) モデルのロードとリアルタイム テストの実行
モデルは以下のコードを使用して読み込まれます。
model = Word2Vec.load('model.bin')
そこから語彙を印刷したい場合は、以下のコマンドを使用します。
vocab = list(model.wv.vocab)
結果をご覧ください:
['see', 'thank', 'back', 'thanks', 'soon', 'open', 'mastercard', 'card', 'time', 'pay', 'talk', 'cash', 'one', 'please', 'goodbye', 'thats', 'helpful', 'hour', 'credit', 'hi', 'later', 'guidance', 'opening', 'timing', 'hello', 'helping', 'bye', 'tell', 'come', 'using', 'kind', 'available']
ステップ 6) 最も類似した単語のチェック
実際に実装してみましょう。
similar_words = model.most_similar('thanks') print(similar_words)
結果をご覧ください:
[('kind', 0.16104359924793243), ('using', 0.1352398842573166), ('come', 0.11500970274209976), ('later', 0.09989878535270691), ('helping', 0.04855936020612717), ('credit', 0.04659383371472359), ('pay', 0.0329081267118454), ('thank', 0.02484947443008423), ('hour', 0.0202352125197649), ('opening', 0.018177658319473267)]
ステップ 7) 指定された単語の単語と一致しません
dissimlar_words = model.doesnt_match('See you later, thanks for visiting'.split()) print(dissimlar_words)
私たちは言葉を提供しました 「また後で。来てくれてありがとう」これは、これらの単語の中で最も類似性の低い単語を出力します。このコードを実行して結果を見てみましょう。
上記のコードを実行した結果:
Thanks
ステップ 8) XNUMX つの単語間の類似性を見つける
これは、2つの単語間の類似性の確率という観点から結果を示します。このセクションの実行方法については、以下のコードを参照してください。
similarity_two_words = model.similarity('please', 'see') print("Please provide the similarity between these two words:") print(similarity_two_words)
上記のコードの実行結果は以下のとおりです。
0.13706
以下のコードを実行すると、さらに類似の単語を見つけることができます。
similar = model.similar_by_word('kind') print(similar)
上記のコードの出力:
[('credit', 0.11764447391033173), ('cash', 0.11440904438495636), ('one', 0.11151769757270813), ('hour', 0.0944807156920433), ('using', 0.0705675333738327), ('thats', 0.05206916481256485), ('later', 0.04502468928694725), ('bye', 0.03960943967103958), ('back', 0.03837274760007858), ('thank', 0.0380823090672493)]