Hive 結合とサブクエリのチュートリアルと例
結合クエリ
結合クエリは、Hive に存在する 2 つのテーブルに対して実行できます。ご理解いただくために 参加 Concepts ここで 2 つのテーブルを作成していることは明らかですが、
- Sample_joins(顧客詳細に関連)
- Sample_joins1(従業員が行った注文の詳細に関連)
ステップ1) 従業員のID、名前、年齢、住所、給与を列名とするテーブル「sample_joins」の作成

ステップ2) データのロードと表示
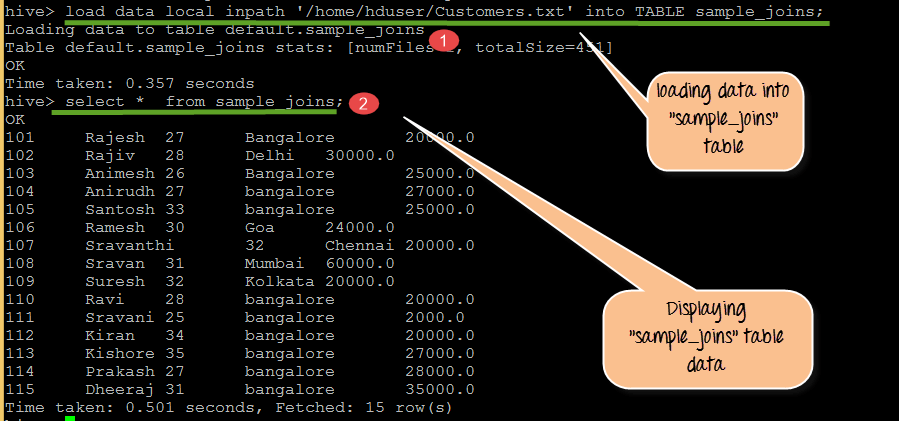
上のスクリーンショットより
- Customers.txtからsample_joinsにデータをロードする
- Sample_joins テーブルの内容の表示
ステップ3) Sample_joins1 テーブルの作成とデータのロード、表示

上記のスクリーンショットから、次のことがわかります。
- Orderid、Date1、Id、Amount 列を含むテーブル sample_joins1 の作成
- order.txtからsample_joins1にデータをロードする
- Sample_joins1 に存在するレコードを表示しています
これから、作成したテーブルで実行できるさまざまな種類の結合について説明しますが、その前に、結合に関して次の点を考慮する必要があります。
結合で観察すべきいくつかの点:
- 結合では等価結合のみが許可されます
- 同じクエリ内で XNUMX つ以上のテーブルを結合できます
- LEFT、RIGHT、FULL OUTER 結合は、一致しない ON 句をより詳細に制御するために存在します。
- 結合は可換ではありません
- 結合は、LEFT 結合か RIGHT 結合かに関係なく、左結合になります。
さまざまな種類の結合
結合には 4 つのタイプがあります。
- 内部結合
- 左外部結合
- 右外部結合
- 完全外部結合
内部結合:
この内部結合により、両方のテーブルに共通するレコードが取得されます。

上記のスクリーンショットから、次のことがわかります。
- ここでは、テーブルsample_joinsとsample_joins1の間でJOINキーワードを使用し、一致条件(c.Id= o.Id)を使用して結合クエリを実行しています。
- クエリで指定された条件をチェックして、両方のテーブルに存在する共通レコードを表示する出力
クエリ:
SELECT c.Id, c.Name, c.Age, o.Amount FROM sample_joins c JOIN sample_joins1 o ON(c.Id=o.Id);
左外部結合:
- Hive クエリ言語 LEFT OUTER JOIN は、右側のテーブルに一致するものがない場合でも、左側のテーブルのすべての行を返します。
- ON 句が右側のテーブルのレコードに一致しない場合でも、結合は右側のテーブルの各列に NULL を含む結果のレコードを返します。

上記のスクリーンショットから、次のことがわかります。
- ここでは、テーブルsample_joinsとsample_joins1の間で「LEFT OUTER JOIN」キーワードを使用し、一致条件を(c.Id= o.Id)として結合クエリを実行しています。例えば、 ここでは従業員 ID を参照として使用しており、ID がテーブルの右側と左側で共通であるかどうかをチェックします。 一致条件として機能します。
- クエリで指定された条件をチェックして、両方のテーブルに存在する共通のレコードを表示する出力。上記の出力の NULL 値は、sample_joins1 である右側のテーブルの値のない列です。
クエリ:
SELECT c.Id, c.Name, o.Amount, o.Date1 FROM sample_joins c LEFT OUTER JOIN sample_joins1 o ON(c.Id=o.Id)
右外部結合:
- Hive クエリ言語 RIGHT OUTER JOIN は、左側のテーブルに一致するものがない場合でも、右側のテーブルからすべての行を返します。
- ON 句が左側のテーブルのゼロレコードと一致する場合でも、結合は左側のテーブルの各列に NULL を含む結果のレコードを返します。
- RIGHT 結合は常に、右側のテーブルからレコードを返し、左側のテーブルから一致したレコードを返します。 左側のテーブルにその列に対応する値がない場合は、その場所に NULL 値が返されます。

上記のスクリーンショットから、次のことがわかります。
- ここでは、テーブルsample_joinsとsample_joins1の間で「RIGHT OUTER JOIN」キーワードを使用し、一致条件を(c.Id= o.Id)として結合クエリを実行しています。
- クエリで指定された条件をチェックして、両方のテーブルに存在する共通レコードを表示する出力
クエリー:
SELECT c.Id, c.Name, o.Amount, o.Date1 FROM sample_joins c RIGHT OUTER JOIN sample_joins1 o ON(c.Id=o.Id)
完全外部結合:
クエリで指定された JOIN 条件に基づいて、sample_joins テーブルとsample_joins1 テーブルの両方のレコードを結合します。
両方のテーブルからすべてのレコードを返し、どちらかの側で一致する値が欠落している列には NULL 値を埋めます。

上記のスクリーンショットから、次のことがわかります。
- ここでは、テーブルsample_joinsとsample_joins1の間で「FULL OUTER JOIN」キーワードを使用し、一致条件(c.Id= o.Id)で結合クエリを実行しています。
- クエリで指定された条件をチェックして、両方のテーブルに存在するすべてのレコードを表示する出力。 ここでの出力の NULL 値は、両方のテーブルの列に値が欠落していることを示します。
クエリー
SELECT c.Id, c.Name, o.Amount, o.Date1 FROM sample_joins c FULL OUTER JOIN sample_joins1 o ON(c.Id=o.Id)
サブクエリ
クエリ内に存在するクエリはサブクエリと呼ばれます。 メイン クエリは、サブクエリによって返される値に依存します。
サブクエリは XNUMX つのタイプに分類できます
- FROM 句のサブクエリ
- WHERE 句のサブクエリ
使用する場合:
- 異なるテーブルの XNUMX つの列の値を組み合わせた特定の値を取得するには
- あるテーブル値の他のテーブルへの依存関係
- 他のテーブルからの XNUMX つの列の値の比較チェック
構文:
Subquery in FROM clause SELECT <column names 1, 2…n>From (SubQuery) <TableName_Main > Subquery in WHERE clause SELECT <column names 1, 2…n> From<TableName_Main>WHERE col1 IN (SubQuery);
例:
SELECT col1 FROM (SELECT a+b AS col1 FROM t1) t2
ここで、t1 と t2 はテーブル名です。 色付きのものはテーブル t1 に対して実行されたサブクエリです。 ここで、a と b はサブクエリに追加され、col1 に割り当てられる列です。 Col1 はメインテーブルに存在する列の値です。 サブクエリに存在するこの列「col1」は、列col1のメインテーブルクエリと同等です。
カスタムスクリプトの埋め込み
ハイブ クライアントの要件に合わせてユーザー固有のスクリプトを作成できるようになります。 ユーザーは独自のマップを作成し、要件に合わせてスクリプトを減らすことができます。 これらは、埋め込みカスタム スクリプトと呼ばれます。 コーディング ロジックはカスタム スクリプトで定義されており、ETL 時にそのスクリプトを使用できます。
埋め込みスクリプトを選択する場合:
- クライアント固有の要件では、開発者は Hive でスクリプトを作成してデプロイする必要があります
- Hive の組み込み関数が特定のドメイン要件に対して機能しない場合
このために、Hive では TRANSFORM 句を使用して、マップ スクリプトとリデューサー スクリプトの両方を埋め込みます。
この埋め込みカスタムスクリプトでは、次の点に注意する必要があります。
- 列は文字列に変換され、ユーザー スクリプトに渡される前に TAB で区切られます。
- ユーザースクリプトの標準出力はタブ区切りの文字列列として扱われます。
サンプル埋め込みスクリプト、
FROM ( FROM pv_users MAP pv_users.userid, pv_users.date USING 'map_script' AS dt, uid CLUSTER BY dt) map_output INSERT OVERWRITE TABLE pv_users_reduced REDUCE map_output.dt, map_output.uid USING 'reduce_script' AS date, count;
上記のスクリプトから、次のことがわかります。
これは理解のためのサンプル スクリプトにすぎません
- pv_users は、map_script で説明されているように、ユーザー ID や日付などのフィールドを持つユーザー テーブルです。
- pv_users テーブルの日付と数に基づいて定義された Reducer スクリプト