Scikit-Learn ट्यूटोरियल: Scikit-Learn कैसे स्थापित करें और उदाहरण
⚡ स्मार्ट सारांश
Scikit-learn एक ओपन-सोर्स प्लेटफॉर्म है। Python यह लाइब्रेरी एक ही सुसंगत अनुमानक इंटरफ़ेस के पीछे प्रीप्रोसेसिंग, वर्गीकरण, प्रतिगमन, क्लस्टरिंग और मॉडल चयन को कवर करती है, जो कच्चे डेटा से लेकर स्कोर किए गए पूर्वानुमानों तक संपूर्ण मशीन लर्निंग वर्कफ़्लो को संक्षिप्त, पठनीय और पुनरुत्पादनीय बनाए रखती है।

स्किकिट-लर्न क्या है?
Scikit सीखने एक खुला स्रोत है Python पुस्तकालय के लिए यंत्र अधिगमयह KNN, ग्रेडिएंट बूस्टिंग, रैंडम फ़ॉरेस्ट और SVM जैसे सुस्थापित एल्गोरिदम का समर्थन करता है, और यह इसके ऊपर निर्मित है। Numpy और SciPy। Scikit-learn का व्यापक रूप से Kaggle प्रतियोगिताओं के साथ-साथ प्रमुख तकनीकी कंपनियों में भी उपयोग किया जाता है। यह प्रीप्रोसेसिंग, डाइमेंशनलिटी रिडक्शन, क्लासिफिकेशन, रिग्रेशन, क्लस्टरिंग और मॉडल सिलेक्शन को कवर करता है।
Scikit-learn के पास किसी भी ओपन-सोर्स लाइब्रेरी की तुलना में सबसे बेहतरीन डॉक्यूमेंटेशन है। यह एक इंटरैक्टिव एस्टीमेटर चार्ट भी प्रदान करता है। सही अनुमानक का चयन करनायह आपको आपके डेटासेट के आकार से लेकर आजमाने लायक एल्गोरिदम की एक छोटी सूची तक ले जाता है।
नीचे दिया गया चित्र दर्शाता है कि Scikit-learn कैसे काम करता है।
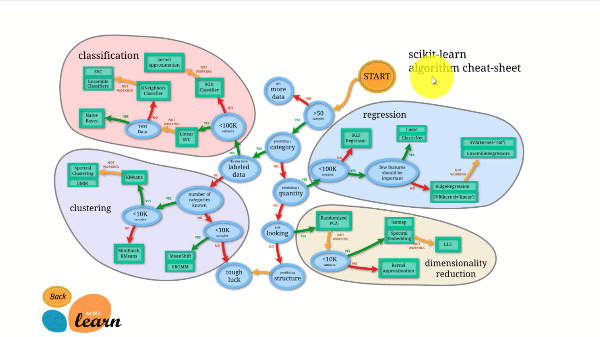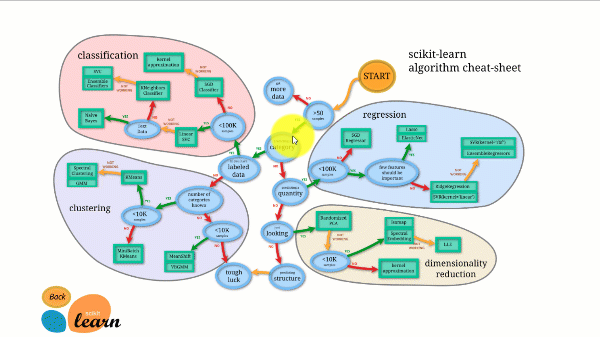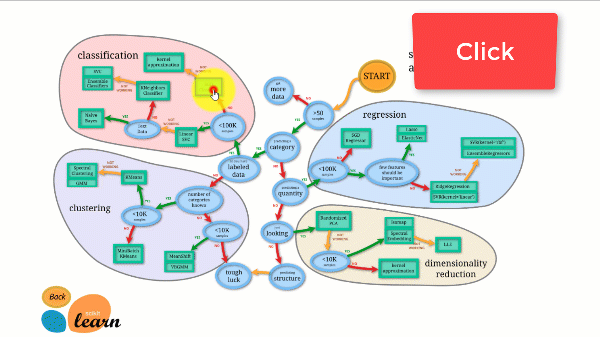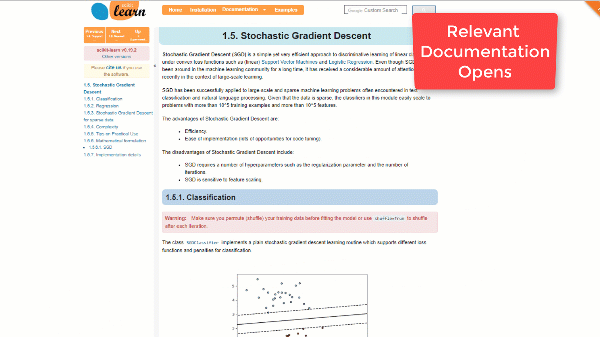
Scikit-learn का उपयोग करना कठिन नहीं है और यह उत्कृष्ट परिणाम देता है। हालांकि, यह CPU पर ही प्रशिक्षण देता है: n_jobs आर्गुमेंट का उपयोग करके कार्य को GPU के बजाय कोर में समानांतर रूप से विभाजित किया जाता है। इसके साथ डीप लर्निंग एल्गोरिदम चलाना संभव है, लेकिन यह शायद ही कभी सर्वोत्तम होता है, खासकर यदि आप पहले से ही इसका उपयोग करना जानते हों। TensorFlow.
Scikit-learn को कैसे डाउनलोड और इंस्टॉल करें
अब इसमें Python इस Scikit-learn ट्यूटोरियल में, आप सीखेंगे कि Scikit-learn को कैसे डाउनलोड और इंस्टॉल किया जाता है:
विकल्प 1: एडब्ल्यूएस
Scikit-learn को AWS पर इस्तेमाल किया जा सकता है। Scikit-learn पहले से इंस्टॉल किया हुआ Docker इमेज सेटअप के सारे काम को आसान बना देता है।
डेवलपर संस्करण स्थापित करने के लिए, नीचे दिए गए कमांड को चलाएँ। Jupyter:
import sys !{sys.executable} -m pip install git+git://github.com/scikit-learn/scikit-learn.git
विकल्प 2: मैक या Windows एनाकोंडा का उपयोग
एनाकोंडा इंस्टॉलेशन के बारे में जानने के लिए, निम्नलिखित देखें TensorFlow को डाउनलोड और इंस्टॉल कैसे करें.
जब यह वॉकथ्रू लिखा गया था, तब scikit के डेवलपर्स ने एक डेवलपमेंट वर्जन जारी किया था जिसमें तत्कालीन रिलीज़ में मौजूद समस्याओं को ठीक किया गया था, इसलिए नीचे दिए गए चरणों में उसी डेवलपर बिल्ड का उपयोग किया गया है। आज एक नए कंप्यूटर पर, वर्तमान स्टेबल रिलीज़ में पहले से ही यहां उपयोग किए गए सभी ट्रांसफॉर्मर मौजूद हैं, और pip install -U scikit-learn पर्याप्त है।
कॉन्डा एनवायरनमेंट के साथ scikit-learn कैसे स्थापित करें
यदि आपने scikit-learn को conda वातावरण के साथ स्थापित किया है, तो संस्करण 0.20 में अपडेट करने के लिए नीचे दिए गए चरणों का पालन करें।
चरण 1) टेन्सरफ्लो वातावरण को सक्रिय करें
source activate hello-tf
चरण 2) conda कमांड का उपयोग करके scikit-learn को हटा दें
conda remove scikit-learn
चरण 3) डेवलपर संस्करण स्थापित करें
scikit-learn के डेवलपर संस्करण को आवश्यक लाइब्रेरी के साथ इंस्टॉल करें।
conda install -c anaconda git
pip install Cython
pip install h5py
pip install git+git://github.com/scikit-learn/scikit-learn.git
नोट: Windows उपयोगकर्ताओं को आवश्यकता है Microsoft दृश्य C++ 14. आप इसे प्राप्त कर सकते हैं यहाँ उत्पन्न करें.
मशीन लर्निंग के साथ Scikit-Learn उदाहरण
यह Scikit ट्यूटोरियल दो भागों में विभाजित है:
- स्किकिट-लर्न के साथ मशीन लर्निंग
- LIME के साथ अपने मॉडल पर भरोसा कैसे करें
पहले भाग में पाइपलाइन बनाने, मॉडल बनाने और हाइपरपैरामीटर को ट्यून करने के तरीके का विस्तार से वर्णन किया गया है, जबकि दूसरे भाग में मॉडल की व्याख्या को शामिल किया गया है।
चरण 1) डेटा आयात करें
इस स्किकिट लर्न ट्यूटोरियल के दौरान, आप वयस्क जनगणना डेटासेट का उपयोग करेंगे।
नीचे दिए गए कोड में फ़ाइल को सीधे यूसीआई मशीन लर्निंग रिपॉजिटरी से पढ़ा जाता है, इसलिए मैन्युअल डाउनलोड की आवश्यकता नहीं है। यदि आप वर्णनात्मक सांख्यिकी में रुचि रखते हैं, तो डाइव और ओवरव्यू टूल देखना उपयोगी होगा। संदर्भ के लिए देखें। इस ट्यूटोरियल डाइव और ओवरव्यू के बारे में अधिक जानने के लिए।
आप पांडास का उपयोग करके डेटासेट आयात करते हैं। ध्यान दें कि आपको निरंतर चर को फ्लोट प्रारूप में परिवर्तित करना होगा।
इस डेटासेट में आठ श्रेणीबद्ध चर शामिल हैं, जो CATE_FEATURES में सूचीबद्ध हैं:
- वर्कक्लास
- शिक्षा
- वैवाहिक
- व्यवसाय
- संबंध
- दौड़
- लिंग
- जन्मभूमि
इसमें CONTI_FEATURES में सूचीबद्ध छह सतत चर भी शामिल हैं:
- उम्र
- एफएनएलडब्ल्यूजीटी
- शिक्षा_संख्या
- पूंजी_लाभ
- पूंजी_हानि
- घंटे_सप्ताह
यहां सूचियां हाथ से भरी गई हैं ताकि आपको यह बेहतर ढंग से समझ आ सके कि कौन से कॉलम उपयोग में हैं। श्रेणीबद्ध या निरंतर कॉलम की सूची बनाने का एक तेज़ तरीका यह है:
## List Categorical CATE_FEATURES = df_train.iloc[:,:-1].select_dtypes('object').columns print(CATE_FEATURES) ## List continuous CONTI_FEATURES = df_train._get_numeric_data() print(CONTI_FEATURES)
डेटा आयात करने के लिए कोड यहां दिया गया है:
# Import dataset import pandas as pd ## Define path data COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country', 'label'] ### Define continuous list CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week'] ### Define categorical list CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country'] ## Prepare the data features = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data" df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False) df_train[CONTI_FEATURES] =df_train[CONTI_FEATURES].astype('float64') df_train.describe()
फ्रेम पर describe() फ़ंक्शन को कॉल करने से छह निरंतर स्तंभों के लिए सारांश सांख्यिकी प्राप्त होती है:
| उम्र | एफएनएलडब्ल्यूजीटी | शिक्षा_संख्या | पूंजी_लाभ | पूंजी_हानि | घंटे_सप्ताह | |
|---|---|---|---|---|---|---|
| गणना | 32561.000000 | 3.256100e + 04 | 32561.000000 | 32561.000000 | 32561.000000 | 32561.000000 |
| मतलब | 38.581647 | 1.897784e + 05 | 10.080679 | 1077.648844 | 87.303830 | 40.437456 |
| एसटीडी | 13.640433 | 1.055500e + 05 | 2.572720 | 7385.292085 | 402.960219 | 12.347429 |
| मिनट | 17.000000 | 1.228500e + 04 | 1.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% तक | 28.000000 | 1.178270e + 05 | 9.000000 | 0.000000 | 0.000000 | 40.000000 |
| 50% तक | 37.000000 | 1.783560e + 05 | 10.000000 | 0.000000 | 0.000000 | 40.000000 |
| 75% तक | 48.000000 | 2.370510e + 05 | 12.000000 | 0.000000 | 0.000000 | 45.000000 |
| मैक्स | 90.000000 | 1.484705e + 06 | 16.000000 | 99999.000000 | 4356.000000 | 99.000000 |
आप native_country फ़ीचर के अद्वितीय मानों की संख्या की जाँच कर सकते हैं। केवल एक परिवार हॉलैंड-नीदरलैंड से है। वह परिवार कोई जानकारी नहीं देता है और प्रशिक्षण के दौरान त्रुटि उत्पन्न करेगा।
df_train.native_country.value_counts()
United-States 29170 Mexico 643 ? 583 Philippines 198 Germany 137 Canada 121 Puerto-Rico 114 El-Salvador 106 India 100 Cuba 95 England 90 Jamaica 81 South 80 China 75 Italy 73 Dominican-Republic 70 Vietnam 67 Guatemala 64 Japan 62 Poland 60 Columbia 59 Taiwan 51 Haiti 44 Iran 43 Portugal 37 Nicaragua 34 Peru 31 France 29 Greece 29 Ecuador 28 Ireland 24 Hong 20 Cambodia 19 Trinadad&Tobago 19 Thailand 18 Laos 18 Yugoslavia 16 Outlying-US(Guam-USVI-etc) 14 Honduras 13 Hungary 13 Scotland 12 Holand-Netherlands 1 Name: native_country, dtype: int64
आप इस अनुपयोगी पंक्ति को डेटासेट से हटा सकते हैं:
## Drop Netherland, because only one row df_train = df_train[df_train.native_country != "Holand-Netherlands"]
इसके बाद, आप निरंतर सुविधाओं की स्थिति को एक सूची में संग्रहीत करते हैं। पाइपलाइन बनाने के लिए आपको अगले चरण में इसकी आवश्यकता होगी।
नीचे दिया गया कोड CONTI_FEATURES में मौजूद सभी कॉलम नामों पर लूप चलाता है, प्रत्येक स्थान (अर्थात, उसका कॉलम नंबर) पढ़ता है और उसे conti_features नामक सूची में जोड़ता है।
## Get the column index of the categorical features conti_features = [] for i in CONTI_FEATURES: position = df_train.columns.get_loc(i) conti_features.append(position) print(conti_features)
[0, 2, 10, 4, 11, 12]
अगला ब्लॉक श्रेणीबद्ध चरों के लिए भी यही काम करता है।
## Get the column index of the categorical features categorical_features = [] for i in CATE_FEATURES: position = df_train.columns.get_loc(i) categorical_features.append(position) print(categorical_features)
[1, 3, 5, 6, 7, 8, 9, 13]
अब डेटासेट को ही देखिए। प्रत्येक श्रेणीबद्ध विशेषता एक स्ट्रिंग है, और मॉडल को स्ट्रिंग मान नहीं दिया जा सकता है, इसलिए डेटासेट को डमी वैरिएबल के साथ रूपांतरित करना होगा।
df_train.head(5)
दरअसल, प्रत्येक फ़ीचर में प्रत्येक समूह के लिए एक कॉलम की आवश्यकता होती है। सबसे पहले, आवश्यक कॉलम की कुल संख्या की गणना करने के लिए नीचे दिए गए कोड को चलाएँ।
print(df_train[CATE_FEATURES].nunique(), 'There are',sum(df_train[CATE_FEATURES].nunique()), 'groups in the whole dataset')
workclass 9
education 16
marital 7
occupation 15
relationship 6
race 5
sex 2
native_country 41
dtype: int64 There are 101 groups in the whole dataset
जैसा कि ऊपर दिखाया गया है, संपूर्ण डेटासेट में 101 समूह हैं। वर्कक्लास फ़ीचर में अकेले नौ समूह हैं। आप नीचे दिए गए कोड की सहायता से समूहों के नाम सूचीबद्ध कर सकते हैं; unique() फ़ंक्शन प्रत्येक श्रेणीबद्ध फ़ीचर के विशिष्ट मान लौटाता है।
for i in CATE_FEATURES: print(df_train[i].unique())
['State-gov' 'Self-emp-not-inc' 'Private' 'Federal-gov' 'Local-gov' '?' 'Self-emp-inc' 'Without-pay' 'Never-worked'] ['Bachelors' 'HS-grad' '11th' 'Masters' '9th' 'Some-college' 'Assoc-acdm' 'Assoc-voc' '7th-8th' 'Doctorate' 'Prof-school' '5th-6th' '10th' '1st-4th' 'Preschool' '12th'] ['Never-married' 'Married-civ-spouse' 'Divorced' 'Married-spouse-absent' 'Separated' 'Married-AF-spouse' 'Widowed'] ['Adm-clerical' 'Exec-managerial' 'Handlers-cleaners' 'Prof-specialty' 'Other-service' 'Sales' 'Craft-repair' 'Transport-moving' 'Farming-fishing' 'Machine-op-inspct' 'Tech-support' '?' 'Protective-serv' 'Armed-Forces' 'Priv-house-serv'] ['Not-in-family' 'Husband' 'Wife' 'Own-child' 'Unmarried' 'Other-relative'] ['White' 'Black' 'Asian-Pac-Islander' 'Amer-Indian-Eskimo' 'Other'] ['Male' 'Female'] ['United-States' 'Cuba' 'Jamaica' 'India' '?' 'Mexico' 'South' 'Puerto-Rico' 'Honduras' 'England' 'Canada' 'Germany' 'Iran' 'Philippines' 'Italy' 'Poland' 'Columbia' 'Cambodia' 'Thailand' 'Ecuador' 'Laos' 'Taiwan' 'Haiti' 'Portugal' 'Dominican-Republic' 'El-Salvador' 'France' 'Guatemala' 'China' 'Japan' 'Yugoslavia' 'Peru' 'Outlying-US(Guam-USVI-etc)' 'Scotland' 'Trinadad&Tobago' 'Greece' 'Nicaragua' 'Vietnam' 'Hong' 'Ireland' 'Hungary']
इसलिए प्रशिक्षण डेटासेट में 101 + 6 कॉलम होंगे: वन-हॉट समूह और छह निरंतर विशेषताएं।
Scikit-learn दो चरणों में रूपांतरण का काम संभाल सकता है:
- स्ट्रिंग को आईडी में बदलें। State-gov आईडी 1 बन जाता है, Self-emp-not-inc आईडी 2 बन जाता है, इत्यादि। LabelEncoder यह काम आपके लिए कर देता है।
- प्रत्येक आईडी को एक नए कॉलम में स्थानांतरित करें। डेटासेट में 101 समूह आईडी हैं, इसलिए प्रत्येक श्रेणीबद्ध विशेषता समूह को दर्शाने वाले 101 कॉलम होंगे। इस ऑपरेशन के लिए Scikit-learn OneHotEncoder प्रदान करता है।
चरण 2) ट्रेन/टेस्ट सेट बनाएं
अब जबकि डेटासेट तैयार है, इसे 80/20 में विभाजित करें: 80 प्रतिशत प्रशिक्षण सेट के लिए और 20 प्रतिशत परीक्षण सेट के लिए।
आप train_test_split का उपयोग कर सकते हैं। पहला आर्गुमेंट फीचर्स का डेटाफ्रेम है और दूसरा लेबल है। आप test_size का उपयोग करके टेस्ट सेट का आकार निर्धारित कर सकते हैं।
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df_train[features], df_train.label, test_size = 0.2, random_state=0) X_train.head(5) print(X_train.shape, X_test.shape)
(26048, 14) (6512, 14)
चरण 3) पाइपलाइन का निर्माण करें
इस पाइपलाइन की मदद से मॉडल को लगातार डेटा उपलब्ध कराना आसान हो जाता है। इसका उद्देश्य कच्चे डेटा को एक ऐसे ऑब्जेक्ट के माध्यम से भेजना है जो क्रमानुसार सभी ऑपरेशन करता है।
इस डेटासेट के साथ आपको सतत चरों का मानकीकरण करना होगा और श्रेणीबद्ध चरों को परिवर्तित करना होगा। कोई भी ऑपरेशन पाइपलाइन के भीतर किया जा सकता है: लुप्त मानों को माध्य या माध्यिका से बदला जा सकता है, और नए चर बनाए जा सकते हैं।
आपके पास दो विकल्प हैं: या तो दोनों प्रक्रियाओं को हार्ड-कोड करें, या एक पाइपलाइन बनाएं। हार्ड-कोडिंग से परीक्षण डेटा फिट किए गए आंकड़ों में लीक हो सकता है और समय के साथ असंगतताएँ उत्पन्न हो सकती हैं, इसलिए पाइपलाइन बेहतर विकल्प है।
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder from sklearn.compose import ColumnTransformer, make_column_transformer from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression
लॉजिस्टिक क्लासिफायर को डेटा फीड करने से पहले पाइपलाइन दो ऑपरेशन करती है:
- वेरिएबल को मानकीकृत करें: StandardScaler()
- श्रेणीबद्ध विशेषताओं को परिवर्तित करें: OneHotEncoder(sparse=False)
आप make_column_transformer का उपयोग करके दोनों चरणों को पूरा करते हैं। जब यह वॉकथ्रू लिखा गया था, तब यह फ़ंक्शन scikit-learn के रिलीज़ किए गए संस्करण (0.19) में मौजूद नहीं था, इसलिए डेवलपर बिल्ड का उपयोग किया गया था; यह 0.20 के बाद से हर स्टेबल रिलीज़ में शामिल किया गया है।
make_column_transformer सीधा-सादा है: आप यह घोषित करते हैं कि किन कॉलम को रूपांतरित करना है और कौन सा रूपांतरण लागू करना है। निरंतर विशेषताओं को मानकीकृत करने के लिए आप निम्न पास करते हैं:
- conti_features, StandardScaler() make_column_transformer के अंदर
- conti_features: निरंतर स्तंभों की सूची
- StandardScaler: उन स्तंभों को मानकीकृत करता है
make_column_transformer के अंदर मौजूद OneHotEncoder ऑब्जेक्ट लेबल को स्वचालित रूप से एन्कोड करता है।
preprocess = make_column_transformer(
(conti_features, StandardScaler()),
### Need to be numeric not string to specify columns name
(categorical_features, OneHotEncoder(sparse=False))
)
संस्करण नोट: ऊपर दिए गए ब्लॉक में दो तर्क आगे बढ़ गए हैं। वर्तमान रिलीज़ में पहले ट्रांसफ़ॉर्मर और फिर कॉलम की अपेक्षा की जाती है, और विरल नाम बदल दिया गया था विरल आउटपुट scikit-learn 1.2 में मौजूद था और 1.4 में हटा दिया गया था, इसलिए नया कोड इस प्रकार है: वनहॉटएनकोडर(स्पार्स_आउटपुट=फॉल्स).
आप fit_transform का उपयोग करके यह जांच सकते हैं कि पाइपलाइन काम करती है या नहीं। आउटपुट का आकार 26048, 107 होना चाहिए।
preprocess.fit_transform(X_train).shape
(26048, 107)
डेटा ट्रांसफ़ॉर्मर तैयार है। आप make_pipeline कमांड का उपयोग करके पाइपलाइन बनाते हैं, और डेटा ट्रांसफ़ॉर्म होने के बाद आप इसे लॉजिस्टिक रिग्रेशन में डालते हैं।
model = make_pipeline(
preprocess,
LogisticRegression())
scikit-learn का उपयोग करके मॉडल को प्रशिक्षित करना बहुत आसान है: पाइपलाइन पर fit फ़ंक्शन को कॉल करें। आप score मेथड से सटीकता प्रिंट कर सकते हैं।
model.fit(X_train, y_train) print("logistic regression score: %f" % model.score(X_test, y_test))
logistic regression score: 0.850891
अंत में, आप predict_proba का उपयोग करके कक्षाओं का अनुमान लगा सकते हैं, जो प्रत्येक कक्षा की प्रायिकता लौटाता है। ध्यान दें कि दोनों प्रायिकताओं का योग एक होता है।
model.predict_proba(X_test)
array([[0.83576663, 0.16423337],
[0.94582765, 0.05417235],
[0.64760587, 0.35239413],
...,
[0.99639252, 0.00360748],
[0.02072181, 0.97927819],
[0.56781353, 0.43218647]])
चरण 4) ग्रिड सर्च में हमारी पाइपलाइन का उपयोग करना
मॉडल की संरचना को निर्धारित करने वाले मानों, यानी हाइपरपैरामीटर को समायोजित करना थकाऊ और बोझिल हो सकता है।
मॉडल का मूल्यांकन करने का एक तरीका यह होगा कि प्रशिक्षण सेट का आकार बदला जाए और प्रदर्शन को मापा जाए, स्कोर के फैलाव को देखने के लिए इस प्रक्रिया को दस बार दोहराया जाए। इसमें बहुत अधिक मैन्युअल काम करना पड़ेगा।
इसके बजाय, scikit-learn ऐसे फ़ंक्शन प्रदान करता है जो आपके लिए पैरामीटर ट्यूनिंग और क्रॉस-वैलिडेशन का कार्य करते हैं।
परिणाम का सत्यापन करना
क्रॉस-वैलिडेशन का अर्थ है कि प्रशिक्षण के दौरान प्रशिक्षण सेट को n गुना फोल्ड में विभाजित किया जाता है और मॉडल का n बार मूल्यांकन किया जाता है। यदि cv को 10 पर सेट किया जाता है, तो मॉडल को दस बार प्रशिक्षित और मूल्यांकित किया जाता है। प्रत्येक चरण में, क्लासिफायर नौ फोल्ड पर प्रशिक्षण लेता है जिन्हें यादृच्छिक रूप से चुना जाता है और दसवें फोल्ड को मूल्यांकन के लिए रखा जाता है।
ग्रिड खोज
प्रत्येक क्लासिफायर में ट्यून करने के लिए हाइपरपैरामीटर होते हैं। आप एक-एक करके मान आज़मा सकते हैं, या पैरामीटर ग्रिड सेट कर सकते हैं। scikit-learn दस्तावेज़ में लॉजिस्टिक क्लासिफायर द्वारा स्वीकार किए जाने वाले सभी पैरामीटर सूचीबद्ध हैं। प्रशिक्षण को तेज़ रखने के लिए, इस उदाहरण में केवल C पैरामीटर को ट्यून किया गया है, जो रेगुलराइज़ेशन को नियंत्रित करता है। यह धनात्मक होना चाहिए, और एक छोटा मान रेगुलराइज़र को अधिक महत्व देता है।
आप GridSearchCV ऑब्जेक्ट का उपयोग करते हैं, जो ट्यून करने के लिए हाइपरपैरामीटर की एक डिक्शनरी लेता है। प्रत्येक हाइपरपैरामीटर को उन मानों के साथ सूचीबद्ध करें जिन्हें आप आज़माना चाहते हैं। C को ट्यून करने के लिए आप इस प्रकार लिखते हैं:
- 'logisticregression__C': [0.001, 0.01, 0.1, 1.0] — पैरामीटर नाम से पहले लोअर केस में क्लासिफायर नाम और दो अंडरस्कोर होते हैं।
यह मॉडल चार अलग-अलग मानों को आजमाएगा: 0.001, 0.01, 0.1 और 1. इसे 10 फोल्ड के साथ प्रशिक्षित किया गया है, यानी cv=10.
from sklearn.model_selection import GridSearchCV # Construct the parameter grid param_grid = { 'logisticregression__C': [0.001, 0.01,0.1, 1.0], }
अब आप ग्रिड और सीवी पैरामीटर के साथ ग्रिडसर्चसीवी का उपयोग करके मॉडल को प्रशिक्षित कर सकते हैं।
# Train the model grid_clf = GridSearchCV(model, param_grid, cv=10, iid=False) grid_clf.fit(X_train, y_train)
आउटपुट:
GridSearchCV(cv=10, error_score='raise-deprecating', estimator=Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...ty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False))]), fit_params=None, iid=False, n_jobs=1, param_grid={'logisticregression__C': [0.001, 0.01, 0.1, 1.0]}, pre_dispatch='2*n_jobs', refit=True, return_train_score='warn', scoring=None, verbose=0)
संस्करण नोट: la आईआईडी इस आउटपुट में दिखाई देने वाला तर्क scikit-learn 0.22 में अप्रचलित हो गया था और 0.24 में हटा दिया गया था, इसलिए इसे वर्तमान रिलीज़ पर GridSearchCV कॉल से हटा दिया जाना चाहिए।
सर्वोत्तम पैरामीटर तक पहुंचने के लिए, आप best_params_ का उपयोग करते हैं।
grid_clf.best_params_
आउटपुट:
{'logisticregression__C': 1.0}
चार अलग-अलग नियमितीकरण मानों के साथ मॉडल को प्रशिक्षित करने के बाद, इष्टतम पैरामीटर यह देता है:
print("best logistic regression from grid search: %f" % grid_clf.best_estimator_.score(X_test, y_test))
ग्रिड खोज से सर्वोत्तम लॉजिस्टिक प्रतिगमन: 0.850891
अनुमानित संभावनाओं तक पहुंचने के लिए:
grid_clf.best_estimator_.predict_proba(X_test)
array([[0.83576677, 0.16423323],
[0.9458291 , 0.0541709 ],
[0.64760416, 0.35239584],
...,
[0.99639224, 0.00360776],
[0.02072033, 0.97927967],
[0.56782222, 0.43217778]])
scikit-learn के साथ XGBoost मॉडल
अब बाज़ार में उपलब्ध सबसे शक्तिशाली क्लासिफायर में से एक को आज़माएँ। XGBoost, रैंडम फ़ॉरेस्ट का एक उन्नत संस्करण है जो ग्रेडिएंट बूस्टिंग पर आधारित है। इसका सैद्धांतिक आधार इस चर्चा के दायरे से बाहर है। Python स्किकिट ट्यूटोरियल देखें, लेकिन ध्यान रखें कि XGBoost ने कई कैगल प्रतियोगिताओं में जीत हासिल की है। औसत आकार के डेटासेट पर यह डीप लर्निंग एल्गोरिदम के बराबर या उससे भी बेहतर प्रदर्शन कर सकता है।
इस क्लासिफायर को प्रशिक्षित करना चुनौतीपूर्ण है क्योंकि इसमें बड़ी संख्या में पैरामीटर होते हैं। आप चाहें तो GridSearchCV का उपयोग करके इन्हें चुन सकते हैं।
यहां बेहतर विकल्प रैंडमाइज्ड सर्च सीवी है। ग्रिड बड़ा होने पर ग्रिड सर्च सीवी धीमा हो जाता है, क्योंकि हर पैरामीटर जोड़ने पर सर्च स्पेस बढ़ता जाता है। इसके विपरीत, रैंडमाइज्ड सर्च सीवी प्रत्येक पुनरावृति में प्रत्येक हाइपरपैरामीटर के मानों का यादृच्छिक रूप से नमूना लेता है, इसलिए 1,000 पुनरावृति में 1,000 संयोजनों का मूल्यांकन होता है। अन्यथा यह ग्रिड सर्च सीवी की तरह ही काम करता है।
आपको xgboost को इम्पोर्ट करना होगा। यदि लाइब्रेरी इंस्टॉल नहीं है, तो pip3 install xgboost कमांड चलाएँ, या इसे किसी अन्य फ़ाइल से इंस्टॉल करें। Jupyter नोटबुक जिसमें:
use import sys
!{sys.executable} -m pip install xgboost
फिर क्लासिफायर और दो सर्च हेल्पर को इम्पोर्ट करें:
import xgboost from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import StratifiedKFold
इस Scikit में अगला कदम Python इस ट्यूटोरियल का उद्देश्य ट्यूनिंग के लिए पैरामीटर निर्दिष्ट करना है। आधिकारिक XGBoost दस्तावेज़ में उन सभी की सूची दी गई है। इस संदर्भ में... Python Sklearn ट्यूटोरियल में आपको केवल दो हाइपरपैरामीटर चुनने होते हैं, जिनमें से प्रत्येक के दो मान होते हैं, क्योंकि XGBoost को प्रशिक्षित करने में लंबा समय लगता है और प्रत्येक अतिरिक्त ग्रिड बिंदु प्रतीक्षा समय को बढ़ा देता है।
params = {
'xgbclassifier__gamma': [0.5, 1],
'xgbclassifier__max_depth': [3, 4]
}
फिर आप XGBoost क्लासिफायर और 600 एस्टिमेटर्स के साथ एक नया पाइपलाइन बनाते हैं। n_estimators स्वयं ट्यून करने योग्य है, और इसका उच्च मान ओवरफिटिंग का कारण बन सकता है। आप अन्य मानों को भी आज़मा सकते हैं, लेकिन ध्यान रखें कि इसमें घंटों लग सकते हैं। अन्य सभी पैरामीटर अपने डिफ़ॉल्ट मानों पर बने रहते हैं।
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1)
)
आप स्ट्रैटिफाइड के-फोल्ड्स क्रॉस-वैलिडेटर का उपयोग करके क्रॉस-वैलिडेशन को बेहतर बना सकते हैं। गणना को गति देने के लिए यहाँ केवल तीन फोल्ड का उपयोग किया गया है, हालांकि इससे गुणवत्ता में कुछ कमी आ सकती है; बेहतर परिणामों के लिए आप अपने कंप्यूटर पर इन्हें 5 या 10 तक बढ़ा सकते हैं। मॉडल को चार पुनरावृत्तियों में प्रशिक्षित किया जाता है।
skf = StratifiedKFold(n_splits=3,
shuffle = True,
random_state = 1001)
random_search = RandomizedSearchCV(model_xgb,
param_distributions=params,
n_iter=4,
scoring='accuracy',
n_jobs=4,
cv=skf.split(X_train, y_train),
verbose=3,
random_state=1001)
रैंडम सर्च तैयार है, इसलिए आप मॉडल को प्रशिक्षित कर सकते हैं।
#grid_xgb = GridSearchCV(model_xgb, params, cv=10, iid=False)
random_search.fit(X_train, y_train)
Fitting 3 folds for each of 4 candidates, totalling 12 fits
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8759645283888057, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8729701715996775, total= 1.0min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8706519235199263, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8735460094437406, total= 1.3min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8722791661868018, total= 57.7s
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8753886905447426, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8697304768486523, total= 1.3min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8740066797189912, total= 1.4min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8707671043538355, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8729701715996775, total= 1.2min
[Parallel(n_jobs=4)]: Done 10 out of 12 | elapsed: 3.6min remaining: 43.5s
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8736611770125533, total= 1.2min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8692697535130154, total= 1.2min
[Parallel(n_jobs=4)]: Done 12 out of 12 | elapsed: 3.6min finished /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/model_selection/_search.py:737: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal. DeprecationWarning)
RandomizedSearchCV(cv=<generator object _BaseKFold.split at 0x1101eb830>,
error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))]),
fit_params=None, iid='warn', n_iter=4, n_jobs=4,
param_distributions={'xgbclassifier__gamma': [0.5, 1], 'xgbclassifier__max_depth': [3, 4]},
pre_dispatch='2*n_jobs', random_state=1001, refit=True,
return_train_score='warn', scoring='accuracy', verbose=3)
जैसा कि आप देख सकते हैं, XGBoost का स्कोर पहले के लॉजिस्टिक रिग्रेशन से बेहतर है।
print("Best parameter", random_search.best_params_) print("best logistic regression from grid search: %f" % random_search.best_estimator_.score(X_test, y_test))
Best parameter {'xgbclassifier__max_depth': 3, 'xgbclassifier__gamma': 0.5}
best logistic regression from grid search: 0.873157
random_search.best_estimator_.predict(X_test)
array(['<=50K', '<=50K', '<=50K', ..., '<=50K', '>50K', '<=50K'], dtype=object)
scikit-learn में MLPClassifier के साथ DNN बनाएं
अंत में, आप scikit-learn का उपयोग करके ही एक न्यूरल नेटवर्क को प्रशिक्षित कर सकते हैं। यह विधि किसी भी अन्य क्लासिफायर के समान है, और एस्टीमेटर MLPClassifier है।
from sklearn.neural_network import MLPClassifier
नीचे दिए गए नेटवर्क को इस प्रकार परिभाषित किया गया है:
- एडम सॉल्वर
- ReLU सक्रियण फ़ंक्शन
- अल्फा = 0.0001
- बैच का आकार 150
- क्रमशः 200 और 100 न्यूरॉन्स वाली दो छिपी हुई परतें
model_dnn = make_pipeline(
preprocess,
MLPClassifier(solver='adam',
alpha=0.0001,
activation='relu',
batch_size=150,
hidden_layer_sizes=(200, 100),
random_state=1))
आप मॉडल को बेहतर बनाने के लिए परतों की संख्या बदल सकते हैं।
model_dnn.fit(X_train, y_train) print("DNN regression score: %f" % model_dnn.score(X_test, y_test))
DNN प्रतिगमन स्कोर: 0.821253
लाइम: अपने मॉडल पर भरोसा करें
अब जबकि आपके पास एक अच्छा मॉडल है, आपको इस पर भरोसा करने का एक तरीका चाहिए। मशीन लर्निंग एल्गोरिदम, विशेष रूप से रैंडम फ़ॉरेस्ट और न्यूरल नेटवर्क, ब्लैक-बॉक्स मॉडल के रूप में जाने जाते हैं: वे काम करते हैं, लेकिन कोई यह नहीं देख सकता कि ऐसा क्यों होता है।
तीन शोधकर्ताओं ने एक ऐसा उपकरण बनाया है जो दर्शाता है कि कंप्यूटर भविष्यवाणी तक कैसे पहुँचता है। उनका शोध पत्र यह है: मुझे तुम पर भरोसा क्यों करना चाहिए?और उन्होंने जो एल्गोरिदम प्रकाशित किया है, उसे लोकल इंटरप्रिटेबल मॉडल-एग्नोस्टिक एक्सप्लेनेशंस (LIME) कहा जाता है।
एक उदाहरण लीजिए। कभी-कभी आपको यह पता नहीं होता कि मशीन लर्निंग द्वारा की गई भविष्यवाणी भरोसेमंद है या नहीं। एक डॉक्टर किसी निदान को केवल इसलिए स्वीकार नहीं कर सकता क्योंकि वह कंप्यूटर द्वारा दिया गया है, और किसी मॉडल को उपयोग में लाने से पहले आपको यह जानना आवश्यक है कि वह विश्वसनीय है या नहीं।
कल्पना कीजिए कि आप यह देख सकें कि किसी भी क्लासिफायर ने भविष्यवाणी क्यों की, यहाँ तक कि न्यूरल नेटवर्क, रैंडम फ़ॉरेस्ट या किसी भी कर्नेल वाले एसवीएम जैसे जटिल मॉडलों के लिए भी। जब भविष्यवाणी के पीछे के कारण स्पष्ट होते हैं, तो उस पर भरोसा करना कहीं अधिक आसान हो जाता है, और यह तय करना भी उतना ही आसान हो जाता है कि किसी मॉडल पर भरोसा नहीं किया जाना चाहिए। LIME आपको बताता है कि किन विशेषताओं ने क्लासिफायर के निर्णय को प्रभावित किया।
डेटा तैयारी
LIME को चलाने के लिए आपको कुछ चीजें बदलनी होंगी। Pythonसबसे पहले, टर्मिनल में pip install lime कमांड का उपयोग करके लाइम इंस्टॉल करें।
लाइम मॉडल को स्थानीय रूप से अनुमानित करने के लिए एक LimeTabularExplainer ऑब्जेक्ट का उपयोग करता है। इस ऑब्जेक्ट के लिए निम्नलिखित की आवश्यकता होती है:
- एक डेटासेट में Numpy प्रारूप
- सुविधाओं का नाम: feature_names
- कक्षाओं का नाम: class_names
- श्रेणीबद्ध विशेषताओं के स्तंभ का सूचकांक: categorical_features
- प्रत्येक श्रेणीबद्ध विशेषता के लिए समूह का नाम: categorical_names
NumPy ट्रेन सेट बनाएं
आप पांडा से df_train को NumPy में बहुत आसानी से कॉपी और कन्वर्ट कर सकते हैं।
df_train.head(5)
# Create numpy data
df_lime = df_train
df_lime.head(3)
कक्षा का नाम प्राप्त करें
यह लेबल unique() के माध्यम से एक्सेस किया जा सकता है। आपको यह दिखना चाहिए:
- '<=50K'
- '>50 हजार'
# Get the class name
class_names = df_lime.label.unique()
class_names
array(['<=50K', '>50K'], dtype=object)
श्रेणीबद्ध विशेषता स्तंभों को अनुक्रमित करें
प्रत्येक समूह का नाम प्राप्त करने के लिए पहले सीखी गई विधि का उपयोग करें। लेबल को LabelEncoder से एन्कोड करें और प्रत्येक श्रेणीबद्ध विशेषता पर इस प्रक्रिया को दोहराएं।
## import sklearn.preprocessing as preprocessing categorical_names = {} for feature in CATE_FEATURES: le = preprocessing.LabelEncoder() le.fit(df_lime[feature]) df_lime[feature] = le.transform(df_lime[feature]) categorical_names[feature] = le.classes_ print(categorical_names)
{'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
df_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 label object dtype: object
अब जबकि डेटासेट तैयार है, आप नीचे दिए गए Scikit Learn उदाहरणों में दिखाए गए विभिन्न डेटासेट बना सकते हैं। LIME में त्रुटियों से बचने के लिए डेटा को पाइपलाइन के बाहर रूपांतरित किया जाता है: LimeTabularExplainer को दिया जाने वाला प्रशिक्षण सेट बिना स्ट्रिंग वाला NumPy ऐरे होना चाहिए, और उपरोक्त विधि ने पहले ही ऐसा ऐरे तैयार कर दिया है।
from sklearn.model_selection import train_test_split X_train_lime, X_test_lime, y_train_lime, y_test_lime = train_test_split(df_lime[features], df_lime.label, test_size = 0.2, random_state=0) X_train_lime.head(5)
आप XGBoost द्वारा खोजे गए इष्टतम मापदंडों के साथ पाइपलाइन बना सकते हैं।
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(max_depth = 3,
gamma = 0.5,
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1))
model_xgb.fit(X_train_lime, y_train_lime)
/Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py:351: FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values. If you want the future behavior and silence this warning, you can specify "categories='auto'."In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly. warnings.warn(msg, FutureWarning)
Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,... reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None, silent=True, subsample=1))])
आपको एक चेतावनी मिलेगी। इसमें बताया गया है कि पाइपलाइन से पहले लेबल एनकोडर बनाने की आवश्यकता नहीं है। यदि आप LIME का उपयोग नहीं कर रहे हैं, तो Scikit-learn के साथ मशीन लर्निंग ट्यूटोरियल के पहले भाग में बताई गई विधि ठीक रहेगी। अन्यथा, इस तरीके का पालन करें: पहले एक एनकोडेड डेटासेट बनाएं, फिर पाइपलाइन के अंदर वन-हॉट एनकोडर लागू करें।
print("best logistic regression from grid search: %f" % model_xgb.score(X_test_lime, y_test_lime))
best logistic regression from grid search: 0.873157
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
LIME का उपयोग शुरू करने से पहले, गलत तरीके से वर्गीकृत की गई पंक्तियों की विशेषताओं को रखने वाला एक NumPy ऐरे बनाएं। आप बाद में उस सूची का उपयोग यह समझने के लिए कर सकते हैं कि किस कारण से क्लासिफायर को भ्रम हुआ।
temp = pd.concat([X_test_lime, y_test_lime], axis= 1) temp['predicted'] = model_xgb.predict(X_test_lime) temp['wrong']= temp['label'] != temp['predicted'] temp = temp.query('wrong==True').drop('wrong', axis=1) temp= temp.sort_values(by=['label']) temp.shape
(826, 16)
फिर आप एक लैम्डा फ़ंक्शन बनाते हैं जो नए डेटा के लिए मॉडल से पूर्वानुमान प्राप्त करता है। आपको इसकी जल्द ही आवश्यकता होगी।
predict_fn = lambda x: model_xgb.predict_proba(x).astype(float)
X_test_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 dtype: object
predict_fn(X_test_lime)
array([[7.96461046e-01, 2.03538969e-01],
[9.51730132e-01, 4.82698716e-02],
[7.93448269e-01, 2.06551731e-01],
...,
[9.90314305e-01, 9.68566816e-03],
[6.45816326e-04, 9.99354184e-01],
[9.71042812e-01, 2.89571714e-02]])
आप पांडास डेटाफ्रेम को नम्पी ऐरे में परिवर्तित करते हैं।
X_train_lime = X_train_lime.values X_test_lime = X_test_lime.values X_test_lime
array([[4.00000e+01, 5.00000e+00, 1.93524e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.70000e+01, 4.00000e+00, 2.16481e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.50000e+01, 4.00000e+00, 2.56263e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
...,
[2.80000e+01, 6.00000e+00, 2.11032e+05, ..., 0.00000e+00,
4.00000e+01, 2.50000e+01],
[4.40000e+01, 4.00000e+00, 1.67005e+05, ..., 0.00000e+00,
6.00000e+01, 3.80000e+01],
[5.30000e+01, 4.00000e+00, 2.57940e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01]])
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
print(features,
class_names,
categorical_features,
categorical_names)
['age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] ['<=50K' '>50K'] [1, 3, 5, 6, 7, 8, 9, 13] {'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private', 'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'], dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th', 'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad', 'Masters', 'Preschool', 'Prof-school', 'Some-college'], dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse', 'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'], dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair', 'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners', 'Machine-op-inspct', 'Other-service', 'Priv-house-serv', 'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support', 'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child', 'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other', 'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba', 'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England', 'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras', 'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica', 'Japan', 'Laos', 'Mexico', 'Nicaragua', 'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland', 'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan', 'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam', 'Yugoslavia'], dtype=object)}
import lime import lime.lime_tabular ### Train should be label encoded not one hot encoded explainer = lime.lime_tabular.LimeTabularExplainer(X_train_lime , feature_names = features, class_names=class_names, categorical_features=categorical_features, categorical_names=categorical_names, kernel_width=3)
अब परीक्षण समूह से एक यादृच्छिक परिवार का चयन करें और भविष्यवाणी और कंप्यूटर द्वारा उस तक पहुंचने के तरीके दोनों को देखें।
import numpy as np np.random.seed(1) i = 100 print(y_test_lime.iloc[i]) >50K
X_test_lime[i]
array([4.20000e+01, 4.00000e+00, 1.76286e+05, 7.00000e+00, 1.20000e+01,
2.00000e+00, 4.00000e+00, 0.00000e+00, 4.00000e+00, 1.00000e+00,
0.00000e+00, 0.00000e+00, 4.00000e+01, 3.80000e+01])
आप एक्सप्लेनर का उपयोग एक्सप्लेन_इंस्टेंस के साथ मॉडल के पीछे के तर्क की जांच करने के लिए कर सकते हैं। इसका चार्ट नीचे दिखाया गया है।
exp = explainer.explain_instance(X_test_lime[i], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

क्लासिफायर ने इस परिवार के बारे में सही अनुमान लगाया: वास्तव में आय 50 डॉलर से अधिक है।
सबसे पहले ध्यान देने वाली बात यह है कि यह वर्गीकरणकर्ता अपने आप में पूरी तरह आश्वस्त नहीं है। यह 50 डॉलर से अधिक आय का 64% संभावना के साथ अनुमान लगाता है, और यह 64% संभावना पूंजीगत लाभ और वैवाहिक स्थिति पर निर्भर करती है। नीला रंग सकारात्मक वर्ग में नकारात्मक योगदान देता है, जबकि नारंगी रेखा सकारात्मक योगदान देती है।
वर्गीकरणकर्ता संशय में है क्योंकि इस परिवार का पूंजीगत लाभ शून्य है, जबकि पूंजीगत लाभ आमतौर पर संपत्ति का अच्छा संकेतक होता है। परिवार प्रति सप्ताह 40 घंटे से कम काम करता है। आयु, व्यवसाय और लिंग सभी सकारात्मक रूप से योगदान करते हैं।
यदि वैवाहिक स्थिति अविवाहित होती, तो क्लासिफायर ने 50 से कम आय का अनुमान लगाया होता (0.64 – 0.18 = 0.46)।
अब एक और परिवार को आज़माएँ, जिसे गलत तरीके से वर्गीकृत किया गया था। इसका स्पष्टीकरण चार्ट कोड के बाद दिया गया है।
temp.head(3) temp.iloc[1,:-2]
age 58 workclass 4 fnlwgt 68624 education 11 education_num 9 marital 2 occupation 4 relationship 0 race 4 sex 1 capital_gain 0 capital_loss 0 hours_week 45 native_country 38 Name: 20931, dtype: object
i = 1 print('This observation is', temp.iloc[i,-2:])
This observation is label <=50K
predicted >50K
Name: 20931, dtype: object
exp = explainer.explain_instance(temp.iloc[1,:-2], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

वर्गीकरणकर्ता ने 50 से कम आय का अनुमान लगाया, जो गलत है। यह परिवार असामान्य है: इसमें न तो पूंजीगत लाभ है और न ही पूंजीगत हानि, व्यक्ति तलाकशुदा है, लगभग 60 वर्ष का है, और शिक्षित है, यानी शिक्षा का स्तर 12 से अधिक है। समग्र पैटर्न का अनुसरण करते हुए, वर्गीकरणकर्ता ने परिवार को 50 से कम आय वाला बताया।
LIME का उपयोग करके स्वयं देखें और आपको क्लासिफायर की कई स्पष्ट गलतियाँ नज़र आएंगी। लाइब्रेरी के लेखक के GitHub रिपॉजिटरी में इमेज और टेक्स्ट क्लासिफिकेशन के लिए अतिरिक्त दस्तावेज़ उपलब्ध हैं।
Scikit-learn कमांड संदर्भ
नीचे उपयोगी कमांडों की एक सूची दी गई है जो scikit-learn संस्करण 0.20 और उसके बाद के संस्करणों पर लागू होती हैं।
| कार्य | फ़ंक्शन या वर्ग |
|---|---|
| ट्रेन/टेस्ट डेटासेट बनाएं | ट्रेन_टेस्ट_स्प्लिट |
| पाइपलाइन का निर्माण करें | |
| कॉलम चुनें और रूपांतरण लागू करें | मेक_कॉलम_ट्रांसफॉर्मर |
| परिवर्तन का प्रकार | |
| मानकीकरण | स्टैंडर्डस्केलर |
| न्यूनतम-अधिकतम स्केलिंग | मिनमैक्सस्केलर |
| सामान्य | नॉर्मलाइज़र |
| लुप्त मानों का अनुमान लगाएं | सिंपलइम्प्यूटर |
| श्रेणीबद्ध रूपांतरित करें | वनहॉटएनकोडर |
| डेटा को फिट और रूपांतरित करें | फिट_ट्रांसफॉर्म |
| पाइपलाइन बनाओ | पाइपलाइन बनाएं |
| मूल मॉडल | |
| रसद प्रतिगमन | रसद प्रतिगमन |
| एक्सजीबूस्ट | XGBक्लासिफायर |
| तंत्रिका जाल | एमएलपीक्लासिफायर |
| ग्रिड खोज | ग्रिडसर्चसीवी |
| यादृच्छिक खोज | रैंडमाइज्डसर्चCV |