GLM i R: Generaliserad linjär modell och logistisk regression
⚡ Smart sammanfattning
Generaliserad linjär modell (GLM) i R utökar ordinär regression till utfall som är binära, antalsbaserade eller icke-normala. Denna genomgång bygger en logistisk GLM på vuxeninkomstdatasetet och utvärderar det med noggrannhet, precision, återkallelse och ROC.

Vad är en generaliserad linjär modell (GLM) i R?
A Generaliserad linjär modell (GLM) utökar vanlig linjär regression så att responsvariabeln kan följa en annan fördelning än den normala. R, du monterar en med den inbyggda glm() funktion från statistikpaketet.
Varje GLM definieras av tre komponenter:
- Slumpmässig komponent: sannolikhetsfördelningen för responsvariabeln, tagen från den exponentiala familjen (binomial, Poisson, Gamma, Gaussisk och andra).
- Systematisk komponent: den linjära prediktorn, det vill säga den viktade kombinationen av dina förklarande variabler.
- Länkfunktion: funktionen som kopplar medelvärdet av svaret till den linjära prediktorn, till exempel logit-länken för binära data eller logaritmiska länken för antal.
Den strukturen är det som gör modellen "generaliserad". Istället för att tvinga fram ett normalfördelat utfall deklarerar man den korrekta fördelningen genom familj argumentet och R uppskattar koefficienterna med maximal sannolikhet. Logistisk regression är helt enkelt en GLM med en binomialfamilj och en logit-länk, så det är den naturliga utgångspunkten.
Vad är logistisk regression i R?
Logistisk regression används för att förutsäga en klass, dvs en sannolikhet. Logistisk regression kan förutsäga ett binärt utfall exakt.
Föreställ dig att du vill förutsäga om ett lån nekas/accepteras baserat på många attribut. Den logistiska regressionen är av formen 0/1. y = 0 om ett lån avvisas, y = 1 om det accepteras.
En logistisk regressionsmodell skiljer sig från linjär regressionsmodell på två sätt.
- Först och främst accepterar den logistiska regressionen endast dikotom (binär) indata som en beroende variabel (dvs en vektor på 0 och 1).
- För det andra kartläggs resultatet genom en probabilistisk länkfunktion som kallas sigmoid (logistisk) funktion på grund av sin S-form:

Utgången för funktionen är alltid mellan 0 och 1. Kontrollera bilden nedan
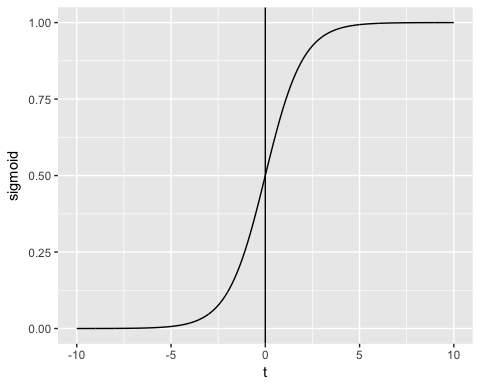
Sigmoidfunktionen returnerar värden från 0 till 1. För klassificeringsuppgiften behöver vi en diskret utdata på 0 eller 1.
För att omvandla ett kontinuerligt flöde till ett diskret värde kan vi sätta en beslutsgräns på 0.5. Alla värden över detta tröskelvärde klassificeras som 1

Nu när länkfunktionen är tydlig, jämför den generaliserade modellen med den vanliga linjära modellen du redan känner till.
GLM vs linjär regression: Viktiga skillnader i R
Innan du skriver någon kod är det bra att veta exakt när standarden linjär regression Funktionen lm() är inte längre lämplig och glm() bör ersätta den.
| Kriterier | Linjär regression (lm) | Generaliserad linjär modell (glm) |
|---|---|---|
| Svarsvariabel | Kontinuerlig och obegränsad | Binär, räknings-, proportions- eller positiv kontinuerlig |
| Felfördelning | Endast normalt | Alla exponentiella familjemedlemmar |
| Länkfunktion | Identitet (implicit) | Explicit: logit, logaritm, invers, probit |
| Uppskattningsmetod | Vanliga minstakvadrater | Maximal sannolikhet (IRLS) |
| Variansantagande | Konstant över observationer | Tillåtet att bero på medelvärdet |
| Goodness-of-fit-mått | R-kvadrat | AIC och kvarvarande avvikelse |
| R-funktion | lm(formel, data) | glm(formel, data, familj) |
Kort sagt, välj lm() när resultatet är ett normalfördelat mått och glm() när resultatet är ett ja/nej-beslut, en uppgift du annars skulle kunna ge till en beslutsträd klassificerare, ett händelseantal eller en strikt positiv kvantitet vars spridning växer med dess medelvärde.
Hur man skapar en generaliserad linjär modell (GLM) i R
När teorin är avklarad tillämpar resten av den här handledningen en binomial GLM ände-till-ände på en verklig datauppsättning.
Låt oss använda vuxen Dataset för att illustrera logistisk regression. "Vuxen" är en utmärkt datamängd för klassificeringsuppgiften. Målet är att förutsäga om en individs årsinkomst i amerikanska dollar kommer att överstiga 50 000. Datamängden innehåller 48 842 observationer och tio variabler:
- ålder: individens ålder. Numerisk
- utbildning: Individens utbildningsnivå. Faktor.
- marital.status: Mariindividens totala status. Faktor dvs aldrig gift, gift-civ-make, …
- genus: Individens kön. Faktor, dvs man eller kvinna
- inkomst: Target variabel. Inkomst över eller under 50K. Faktor dvs >50K, <=50K
bland andra
library(dplyr) data_adult <-read.csv("https://raw.githubusercontent.com/guru99-edu/R-Programming/master/adult.csv") glimpse(data_adult)
Produktion:
Observations: 48,842 Variables: 10 $ x <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,... $ age <int> 25, 38, 28, 44, 18, 34, 29, 63, 24, 55, 65, 36, 26... $ workclass <fctr> Private, Private, Local-gov, Private, ?, Private,... $ education <fctr> 11th, HS-grad, Assoc-acdm, Some-college, Some-col... $ educational.num <int> 7, 9, 12, 10, 10, 6, 9, 15, 10, 4, 9, 13, 9, 9, 9,... $ marital.status <fctr> Never-married, Married-civ-spouse, Married-civ-sp... $ race <fctr> Black, White, White, Black, White, White, Black, ... $ gender <fctr> Male, Male, Male, Male, Female, Male, Male, Male,... $ hours.per.week <int> 40, 50, 40, 40, 30, 30, 40, 32, 40, 10, 40, 40, 39... $ income <fctr> <=50K, <=50K, >50K, >50K, <=50K, <=50K, <=50K, >5...
Vi kommer att gå tillväga enligt följande:
- Steg 1: Kontrollera kontinuerliga variabler
- Steg 2: Kontrollera faktorvariabler
- Steg 3: Funktionsteknik
- Steg 4: Sammanfattande statistik
- Steg 5: Träna/testset
- Steg 6: Bygg modellen
- Steg 7: Bedöm modellens prestanda
- Steg 8: Förbättra modellen
Din uppgift är att förutsäga vilken individ som kommer att ha en intäkt högre än 50K.
I den här handledningen kommer varje steg att beskrivas i detalj för att utföra en analys på en riktig datauppsättning.
Steg 1) Kontrollera kontinuerliga variabler
I det första steget kan du se fördelningen av de kontinuerliga variablerna.
continuous <-select_if(data_adult, is.numeric) summary(continuous)
Code Förklaring
- kontinuerlig <- select_if(data_adult, is.numeric): Använd funktionen select_if() från dplyr-biblioteket för att bara välja de numeriska kolumnerna
- sammanfattning (kontinuerlig): Skriv ut sammanfattningsstatistiken
Produktion:
## X age educational.num hours.per.week ## Min. : 1 Min. :17.00 Min. : 1.00 Min. : 1.00 ## 1st Qu.:11509 1st Qu.:28.00 1st Qu.: 9.00 1st Qu.:40.00 ## Median :23017 Median :37.00 Median :10.00 Median :40.00 ## Mean :23017 Mean :38.56 Mean :10.13 Mean :40.95 ## 3rd Qu.:34525 3rd Qu.:47.00 3rd Qu.:13.00 3rd Qu.:45.00 ## Max. :46033 Max. :90.00 Max. :16.00 Max. :99.00
Från tabellen ovan kan du se att data har helt olika skalor och timmar.per.vecka har stora extremvärden (.dvs titta på den sista kvartilen och maxvärdet).
Du kan hantera det genom att följa två steg:
- Rita ut fördelningen av timmar per vecka.
- Standardisera de kontinuerliga variablerna
- Rita fördelningen
Låt oss titta närmare på fördelningen av timmar.per.vecka
# Histogram with kernel density curve library(ggplot2) ggplot(continuous, aes(x = hours.per.week)) + geom_density(alpha = .2, fill = "#FF6666")
Produktion:

Variabeln har många extremvärden och inte väldefinierad fördelning. Du kan delvis ta itu med detta problem genom att ta bort de översta 0.01 procenten av timmarna per vecka.
Grundläggande syntax för kvantil:
quantile(variable, percentile) arguments: -variable: Select the variable in the data frame to compute the percentile -percentile: Can be a single value between 0 and 1 or multiple value. If multiple, use this format: `c(A,B,C, ...) - `A`,`B`,`C` and `...` are all integer from 0 to 1.
Vi beräknar den 99:e percentilen av den veckoarbetstiden.
top_one_percent <- quantile(data_adult$hours.per.week, .99)
top_one_percent
Code Förklaring
- quantile(data_adult$hours.per.week, .99): Beräkna den 99:e percentilen av den veckovisa arbetstiden
Produktion:
## 99% ## 80
99 procent av befolkningen arbetar under 80 timmar per vecka.
Du kan släppa observationerna över denna tröskel. Du använder filtret från dplyr bibliotek.
data_adult_drop <-data_adult %>% filter(hours.per.week<top_one_percent) dim(data_adult_drop)
Produktion:
## [1] 45537 10
- Standardisera de kontinuerliga variablerna
Du kan standardisera varje kolumn för att förbättra prestandan eftersom dina data inte har samma skala. Du kan använda funktionen mutate_if från dplyr-biblioteket. Grundsyntaxen är:
mutate_if(df, condition, funs(function)) arguments: -`df`: Data frame used to compute the function - `condition`: Statement used. Do not use parenthesis - funs(function): Return the function to apply. Do not use parenthesis for the function
Du kan standardisera de numeriska kolumnerna enligt följande:
data_adult_rescale <- data_adult_drop %>% mutate_if(is.numeric, funs(as.numeric(scale(.)))) head(data_adult_rescale)
Code Förklaring
- mutate_if(is.numeric, funs(scale)): Villkoret är endast numerisk kolumn och funktionen är skala
Produktion:
## X age workclass education educational.num ## 1 -1.732680 -1.02325949 Private 11th -1.22106443 ## 2 -1.732605 -0.03969284 Private HS-grad -0.43998868 ## 3 -1.732530 -0.79628257 Local-gov Assoc-acdm 0.73162494 ## 4 -1.732455 0.41426100 Private Some-college -0.04945081 ## 5 -1.732379 -0.34232873 Private 10th -1.61160231 ## 6 -1.732304 1.85178149 Self-emp-not-inc Prof-school 1.90323857 ## marital.status race gender hours.per.week income ## 1 Never-married Black Male -0.03995944 <=50K ## 2 Married-civ-spouse White Male 0.86863037 <=50K ## 3 Married-civ-spouse White Male -0.03995944 >50K ## 4 Married-civ-spouse Black Male -0.03995944 >50K ## 5 Never-married White Male -0.94854924 <=50K ## 6 Married-civ-spouse White Male -0.76683128 >50K
Steg 2) Kontrollera faktorvariabler
Detta steg har två mål:
- Kontrollera nivån i varje kategorisk kolumn
- Definiera nya nivåer
Vi kommer att dela upp detta steg i tre delar:
- Välj de kategoriska kolumnerna
- Lagra stapeldiagrammet för varje kolumn i en lista
- Skriv ut graferna
Vi kan välja faktorkolumnerna med koden nedan:
# Select categorical column factor <- data.frame(select_if(data_adult_rescale, is.factor)) ncol(factor)
Code Förklaring
- data.frame(select_if(data_adult, is.factor)): Vi lagrar faktorkolumnerna i faktor i en dataramtyp. Biblioteket ggplot2 kräver ett dataramobjekt.
Produktion:
## [1] 6
Datauppsättningen innehåller 6 kategoriska variabler
Det andra steget är mer krävande. Du vill rita ett stapeldiagram för varje kolumn i dataframefaktorn. Det är mer praktiskt att automatisera processen, särskilt i situationer där det finns många kolumner.
library(ggplot2) # Create graph for each column graph <- lapply(names(factor), function(x) ggplot(factor, aes(get(x))) + geom_bar() + theme(axis.text.x = element_text(angle = 90)))
Code Förklaring
- lapply(): Använd funktionen lapply() för att skicka en funktion i alla kolumner i datamängden. Du lagrar resultatet i en lista
- function(x): Funktionen kommer att bearbetas för varje x. Här är x kolumnerna
- ggplot(faktor, aes(get(x))) + geom_bar()+ theme(axis.text.x = element_text(angle = 90)): Skapa ett stapeldiagram för varje x-element. Observera att för att returnera x som en kolumn måste du inkludera den i get()
Det sista steget är relativt enkelt. Du vill skriva ut de 6 graferna.
# Print the graph
graph
Produktion:
## [[1]]

## ## [[2]]

## ## [[3]]

## ## [[4]]

## ## [[5]]

## ## [[6]]

Obs: Använd nästa-knappen för att navigera till nästa graf

Steg 3) Funktionsteknik
Två kategoriska variabler har fler nivåer än vad modellen behöver. Du kommer att omgruppera dem till bredare, mer välfyllda kategorier.
Omarbetad utbildning
Av grafen ovan kan man se att den rörliga utbildningen har 16 nivåer. Detta är betydande och vissa nivåer har ett relativt lågt antal observationer. Om du vill förbättra mängden information du kan få från den här variabeln kan du göra om den till en högre nivå. Man skapar nämligen större grupper med liknande utbildningsnivå. Till exempel kommer låg utbildningsnivå att omvandlas till avhopp. Högre utbildningsnivåer kommer att ändras till master.
Här är detaljen:
| Gammal nivå | Ny nivå |
|---|---|
| Förskola | hoppa av |
| 10:e | Hoppa av |
| 11:e | Hoppa av |
| 12:e | Hoppa av |
| 1st-4th | Hoppa av |
| 5th-6th | Hoppa av |
| 7th-8th | Hoppa av |
| 9:e | Hoppa av |
| HS-Grad | HighGrad |
| Något college | Community |
| Assoc-acdm | Community |
| Assoc-voc | Community |
| ungkarlar | ungkarlar |
| Masters | Masters |
| Prof-skola | Masters |
| Doktorsexamen | PhD |
recast_data <- data_adult_rescale %>% select(-X) %>% mutate(education = factor(ifelse(education == "Preschool" | education == "10th" | education == "11th" | education == "12th" | education == "1st-4th" | education == "5th-6th" | education == "7th-8th" | education == "9th", "dropout", ifelse(education == "HS-grad", "HighGrad", ifelse(education == "Some-college" | education == "Assoc-acdm" | education == "Assoc-voc", "Community", ifelse(education == "Bachelors", "Bachelors", ifelse(education == "Masters" | education == "Prof-school", "Master", "PhD")))))))
Code Förklaring
- Vi använder verbet mutera från dplyr library. Vi ändrar utbildningens värderingar med påståendet ifelse
I tabellen nedan skapar du en sammanfattande statistik för att i genomsnitt se hur många års utbildning (z-värde) som krävs för att nå Bachelor, Master eller PhD.
recast_data %>% group_by(education) %>% summarize(average_educ_year = mean(educational.num), count = n()) %>% arrange(average_educ_year)
Produktion:
## # A tibble: 6 x 3 ## education average_educ_year count ## <fctr> <dbl> <int> ## 1 dropout -1.76147258 5712 ## 2 HighGrad -0.43998868 14803 ## 3 Community 0.09561361 13407 ## 4 Bachelors 1.12216282 7720 ## 5 Master 1.60337381 3338 ## 6 PhD 2.29377644 557
omarbetning Marital-status
Det är också möjligt att skapa lägre nivåer för civilståndet. I följande kod ändrar du nivån enligt följande:
| Gammal nivå | Ny nivå |
|---|---|
| Aldrig gift | Inte gift |
| Gift-make-frånvarande | Inte gift |
| Gift-AF-make | Gift |
| Gift-civ-make | |
| Separerad | Separerad |
| Skild | |
| änkor | Änka |
# Change level marry recast_data <- recast_data %>% mutate(marital.status = factor(ifelse(marital.status == "Never-married" | marital.status == "Married-spouse-absent", "Not_married", ifelse(marital.status == "Married-AF-spouse" | marital.status == "Married-civ-spouse", "Married", ifelse(marital.status == "Separated" | marital.status == "Divorced", "Separated", "Widow")))))
Du kan kontrollera antalet individer inom varje grupp.
table(recast_data$marital.status)
Produktion:
## ## Married Not_married Separated Widow ## 21165 15359 7727 1286
Steg 4) Sammanfattningsstatistik
Det är dags att kolla lite statistik om våra målvariabler. I diagrammet nedan räknar du andelen individer som tjänar mer än 50 XNUMX givet deras kön.
# Plot gender income ggplot(recast_data, aes(x = gender, fill = income)) + geom_bar(position = "fill") + theme_classic()
Produktion:

Kontrollera sedan om individens ursprung påverkar deras inkomster.
# Plot origin income ggplot(recast_data, aes(x = race, fill = income)) + geom_bar(position = "fill") + theme_classic() + theme(axis.text.x = element_text(angle = 90))
Produktion:
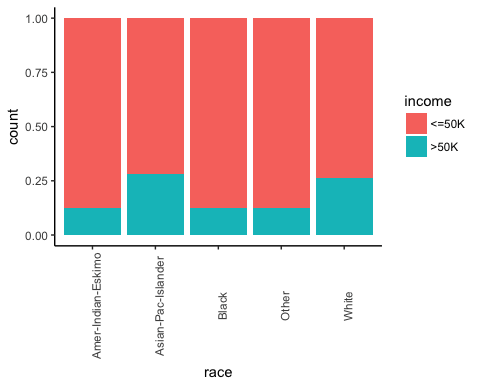
Antalet arbetstimmar per kön.
# box plot gender working time ggplot(recast_data, aes(x = gender, y = hours.per.week)) + geom_boxplot() + stat_summary(fun.y = mean, geom = "point", size = 3, color = "steelblue") + theme_classic()
Produktion:

Boxplotten bekräftar att arbetstidsfördelningen passar olika grupper. I boxplotten har båda könen inte homogena observationer.
Du kan kontrollera tätheten av den veckoarbetstiden per utbildningstyp. Fördelningarna har många olika val. Det kan förmodligen förklaras av typen av utbildning.traci USA.
# Plot distribution working time by education ggplot(recast_data, aes(x = hours.per.week)) + geom_density(aes(color = education), alpha = 0.5) + theme_classic()
Code Förklaring
- ggplot(recast_data, aes( x= hours.per.week)): En densitetsplot kräver bara en variabel
- geom_density(aes(färg = utbildning), alfa =0.5): Det geometriska objektet för att styra densiteten
Produktion:

För att bekräfta dina tankar kan du utföra en enkelriktad ANOVA test:
anova <- aov(hours.per.week~education, recast_data) summary(anova)
Produktion:
## Df Sum Sq Mean Sq F value Pr(>F) ## education 5 1552 310.31 321.2 <2e-16 *** ## Residuals 45531 43984 0.97 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
ANOVA-testet bekräftar skillnaden i genomsnitt mellan grupperna.
Icke-linjäritet
Innan du kör modellen kan du se om antalet arbetade timmar är relaterat till ålder.
library(ggplot2) ggplot(recast_data, aes(x = age, y = hours.per.week)) + geom_point(aes(color = income), size = 0.5) + stat_smooth(method = 'lm', formula = y~poly(x, 2), se = TRUE, aes(color = income)) + theme_classic()
Code Förklaring
- ggplot(recast_data, aes(x = ålder, y = timmar.per.vecka)): Ställ in grafens estetik
- geom_point(aes(färg= inkomst), storlek =0.5): Konstruera punktdiagrammet
- stat_smooth(): Lägg till trendlinjen med följande argument:
- method='lm': Rita det anpassade värdet om linjär regression
- formel = y~poly(x,2): Anpassa en polynomregression
- se = TRUE: Lägg till standardfelet
- aes(färg=inkomst): Bryt modellen efter inkomst
Produktion:

I ett nötskal kan du testa interaktionstermer i modellen för att fånga upp icke-linjäritetseffekten mellan veckoarbetstiden och andra funktioner. Det är viktigt att upptäcka under vilka förutsättningar arbetstiden skiljer sig.
Korrelation
Nästa kontroll är att visualisera korrelationen mellan variablerna. Du konverterar faktornivåtypen till numerisk så att du kan plotta en värmekarta som innehåller korrelationskoefficienten beräknad med Spearman-metoden.
library(GGally) # Convert data to numeric corr <- data.frame(lapply(recast_data, as.integer)) # Plot the graphggcorr(corr, method = c("pairwise", "spearman"), nbreaks = 6, hjust = 0.8, label = TRUE, label_size = 3, color = "grey50")
Code Förklaring
- data.frame(lapply(recast_data,as.integer)): Konvertera data till numeriska
- ggcorr() plotta värmekartan med följande argument:
- metod: Metod för att beräkna korrelationen
- nbreaks = 6: Antal breaks
- hjust = 0.8: Kontrollposition för variabelnamnet i plotten
- label = TRUE: Lägg till etiketter i mitten av fönstren
- label_size = 3: Storleksetiketter
- färg = "grå50"): Färg på etiketten
Produktion:
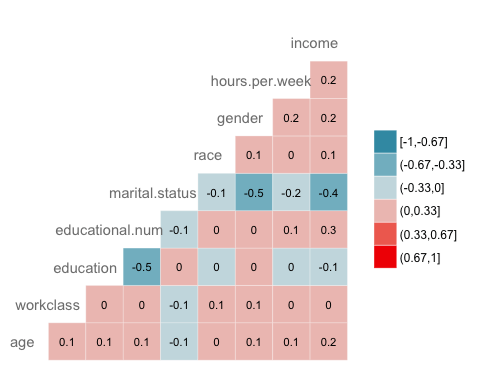
Steg 5) Träna/testset
Alla övervakade maskininlärning Uppgiften kräver att du delar upp data mellan en tåguppsättning och en testuppsättning. Du kan använda den "funktion" du skapade i de andra handledningarna för handledning för att skapa en tåg-/testuppsättning.
set.seed(1234) create_train_test <- function(data, size = 0.8, train = TRUE) { n_row = nrow(data) total_row = size * n_row train_sample <- 1: total_row if (train == TRUE) { return (data[train_sample, ]) } else { return (data[-train_sample, ]) } } data_train <- create_train_test(recast_data, 0.8, train = TRUE) data_test <- create_train_test(recast_data, 0.8, train = FALSE) dim(data_train)
Produktion:
## [1] 36429 9
dim(data_test)
Produktion:
## [1] 9108 9
Steg 6) Bygg modellen
För att se hur algoritmen presterar använder du glm()-funktionen från statspaketet. Generaliserad linjär modell är en samling modeller. Grundsyntaxen är:
glm(formula, data=data, family=linkfunction() Argument: - formula: Equation used to fit the model- data: dataset used - Family: - binomial: (link = "logit") - gaussian: (link = "identity") - Gamma: (link = "inverse") - inverse.gaussian: (link = "1/mu^2") - poisson: (link = "log") - quasi: (link = "identity", variance = "constant") - quasibinomial: (link = "logit") - quasipoisson: (link = "log")
Du är redo att uppskatta den logistiska modellen för att dela inkomstnivån mellan en uppsättning funktioner.
formula <- income~. logit <- glm(formula, data = data_train, family = 'binomial') summary(logit)
Code Förklaring
- formel <- inkomst ~ .: Skapa modellen som passar
- logit <- glm(formel, data = data_train, family = 'binomial'): Passa in en logistisk modell (familj = 'binomial') med data_train-data.
- summary(logit): Skriv ut sammanfattningen av modellen
Produktion:
## ## Call: ## glm(formula = formula, family = "binomial", data = data_train) ## ## Deviance Residuals: ## Min 1Q Median 3Q Max ## -2.6456 -0.5858 -0.2609 -0.0651 3.1982 ## ## Coefficients: ## Estimate Std. Error z value Pr(>|z|) ## (Intercept) 0.07882 0.21726 0.363 0.71675 ## age 0.41119 0.01857 22.146 < 2e-16 *** ## workclassLocal-gov -0.64018 0.09396 -6.813 9.54e-12 *** ## workclassPrivate -0.53542 0.07886 -6.789 1.13e-11 *** ## workclassSelf-emp-inc -0.07733 0.10350 -0.747 0.45499 ## workclassSelf-emp-not-inc -1.09052 0.09140 -11.931 < 2e-16 *** ## workclassState-gov -0.80562 0.10617 -7.588 3.25e-14 *** ## workclassWithout-pay -1.09765 0.86787 -1.265 0.20596 ## educationCommunity -0.44436 0.08267 -5.375 7.66e-08 *** ## educationHighGrad -0.67613 0.11827 -5.717 1.08e-08 *** ## educationMaster 0.35651 0.06780 5.258 1.46e-07 *** ## educationPhD 0.46995 0.15772 2.980 0.00289 ** ## educationdropout -1.04974 0.21280 -4.933 8.10e-07 *** ## educational.num 0.56908 0.07063 8.057 7.84e-16 *** ## marital.statusNot_married -2.50346 0.05113 -48.966 < 2e-16 *** ## marital.statusSeparated -2.16177 0.05425 -39.846 < 2e-16 *** ## marital.statusWidow -2.22707 0.12522 -17.785 < 2e-16 *** ## raceAsian-Pac-Islander 0.08359 0.20344 0.411 0.68117 ## raceBlack 0.07188 0.19330 0.372 0.71001 ## raceOther 0.01370 0.27695 0.049 0.96054 ## raceWhite 0.34830 0.18441 1.889 0.05894 . ## genderMale 0.08596 0.04289 2.004 0.04506 * ## hours.per.week 0.41942 0.01748 23.998 < 2e-16 *** ## ---## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## (Dispersion parameter for binomial family taken to be 1) ## ## Null deviance: 40601 on 36428 degrees of freedom ## Residual deviance: 27041 on 36406 degrees of freedom ## AIC: 27087 ## ## Number of Fisher Scoring iterations: 6
Sammanfattningen av vår modell avslöjar intressant information. Prestandan för en logistisk regression utvärderas med specifika nyckelmått.
- AIC (Akaike Information Criteria): Detta motsvarar R2 i logistisk regression. Den mäter passformen när ett straff läggs på antalet parametrar. Mindre AIC värden indikerar att modellen är närmare sanningen.
- Nollavvikelse: Passar endast modellen med intercept. Frihetsgraden är n-1. Vi kan tolka det som ett chi-kvadratvärde (anpassat värde som skiljer sig från testningen av verkligt värdehypotes).
- Residual Deviance: Modell med alla variabler. Det tolkas också som en chi-kvadrat hypotestestning.
- Antal Fisher Scoring-iterationer: Antal iterationer före konvergering.
Utdata från glm()-funktionen lagras i en lista. Koden nedan visar alla objekt som finns tillgängliga i logitvariabeln som vi konstruerade för att utvärdera den logistiska regressionen.
# Listan är mycket lång, skriv bara ut de tre första elementen
lapply(logit, class)[1:3]
Produktion:
## $coefficients ## [1] "numeric" ## ## $residuals ## [1] "numeric" ## ## $fitted.values ## [1] "numeric"
Varje värde kan vara t.ex.tracmed $-tecknet följt av namnet på måtten. Till exempel lagrade du modellen som logit. För att t.ex.tracEnligt AIC-kriterierna använder du:
logit$aic
Produktion:
## [1] 27086.65
Steg 7) Bedöm modellens prestanda
Förvirringsmatris
Ocuco-landskapet förvirringsmatris är ett bättre val för att utvärdera klassificeringsprestanda jämfört med de olika mätvärden du såg tidigare. Den allmänna idén är att räkna antalet gånger som sanna instanser klassificeras är falska.

För att beräkna förvirringsmatrisen måste du först ha en uppsättning förutsägelser så att de kan jämföras med de faktiska målen.
predict <- predict(logit, data_test, type = 'response') # confusion matrix table_mat <- table(data_test$income, predict > 0.5) table_mat
Code Förklaring
- predict(logit,data_test, type = 'response'): Beräkna förutsägelsen på testsetet. Ange typ = 'svar' för att beräkna svarssannolikheten.
- table(data_test$income, predict > 0.5): Beräkna förvirringsmatrisen. förutsäga > 0.5 betyder att det returnerar 1 om de förutspådda sannolikheterna är över 0.5, annars 0.
Produktion:
## ## FALSE TRUE ## <=50K 6310 495 ## >50K 1074 1229
Varje rad i en förvirringsmatris representerar ett faktiskt mål, medan varje kolumn representerar ett förutsagt mål. Den första raden i denna matris beaktar inkomsten lägre än 50 000 (den negativa klassen): 6 310 observationer klassificerades korrekt som individer med inkomst lägre än 50 000 (Riktigt negativt), medan 495 felaktigt klassificerades som över 50 000 (Falskt positivtDen andra raden tar hänsyn till inkomsten över 50 000: 1 229 identifierades korrekt (Riktigt positivt), medan 1 074 missades (Falskt negativ).
Du kan beräkna modellen noggrannhet genom att summera det sanna positiva + sanna negativa över den totala observationen

accuracy_Test <- sum(diag(table_mat)) / sum(table_mat) accuracy_Test
Code Förklaring
- sum(diag(table_mat)): Summan av diagonalen
- sum(table_mat): Summan av matrisen.
Produktion:
## [1] 0.8277339
Modellen verkar lida av ett problem: den producerar för många falska negativa resultat. Detta kallas paradox för noggrannhetstestVi konstaterade att noggrannheten är förhållandet mellan korrekta förutsägelser och det totala antalet fall. Vi kan ha relativt hög noggrannhet men en värdelös modell. Det händer när det finns en dominerande klass. Om du tittar tillbaka på förvirringsmatrisen kan du se att de flesta fallen klassificeras som sant negativa. Tänk dig nu att modellen klassificerar varje observation som negativ (dvs. lägre än 50 000). Du skulle fortfarande få en noggrannhet på cirka 75 procent (6 805 / 9 108). Din modell presterar bättre men kämpar för att skilja det sant positiva från det sant negativa.
I en sådan situation är det att föredra att ha ett mer kortfattat mått. Vi kan titta på:
- Precision=TP/(TP+FP)
- Recall=TP/(TP+FN)
Precision vs Recall
Precision tittar på träffsäkerheten i den positiva förutsägelsen. Recall är förhållandet mellan positiva instanser som detekteras korrekt av klassificeraren;
Du kan konstruera två funktioner för att beräkna dessa två mätvärden
- Konstruera precision
precision <- function(matrix) { # True positive tp <- matrix[2, 2] # false positive fp <- matrix[1, 2] return (tp / (tp + fp)) }
Code Förklaring
- mat[1,1]: Returnera den första cellen i den första kolumnen i dataramen, dvs den sanna positiva
- matta[1,2]; Returnera den första cellen i den andra kolumnen i dataramen, dvs den falska positiva
recall <- function(matrix) { # true positive tp <- matrix[2, 2]# false positive fn <- matrix[2, 1] return (tp / (tp + fn)) }
Code Förklaring
- mat[1,1]: Returnera den första cellen i den första kolumnen i dataramen, dvs den sanna positiva
- matta[2,1]; Returnera den andra cellen i den första kolumnen i dataramen, dvs det falska negativa
Du kan testa dina funktioner
prec <- precision(table_mat) prec rec <- recall(table_mat) rec
Produktion:
## [1] 0.712877 ## [2] 0.5336518
Läs dessa två siffror noggrant. Precisionen är 0.71, så när modellen säger att en individ tjänar över 50 000 är det korrekt i 71 procent av fallen. Recall är 0.53, så modellen upptäcker bara 53 procent av de individer som verkligen tjänar över 50 000.
Du kan skapa ![]() poäng baserat på precision och återkallelse. De
poäng baserat på precision och återkallelse. De ![]() är ett harmoniskt medelvärde av dessa två mått, vilket betyder att det ger större vikt åt de lägre värdena.
är ett harmoniskt medelvärde av dessa två mått, vilket betyder att det ger större vikt åt de lägre värdena.

f1 <- 2 * ((prec * rec) / (prec + rec)) f1
Produktion:
## [1] 0.6103799
Avvägning mellan precision och återkallelse
Det är omöjligt att ha både hög precision och hög återkallelse.
Om vi ökar precisionen kommer den korrekta individen att bli bättre förutspådd, men vi skulle missa många av dem (lägre återkallelse). I vissa situationer föredrar vi högre precision än återkallelse. Det finns ett konkavt förhållande mellan precision och återkallelse.
- Föreställ dig, du måste förutsäga om en patient har en sjukdom. Du vill vara så exakt som möjligt.
- Om du behöver upptäcka potentiella bedrägliga personer på gatan genom ansiktsigenkänning, skulle det vara bättre att fånga många personer som stämplas som bedrägliga även om precisionen är låg. Polisen kommer att kunna släppa den icke-bedrägliga personen.
ROC-kurvan
Ocuco-landskapet Mottagare Operating Karakteristisk kurva är ett annat vanligt verktyg som används med binär klassificering. Den är väldigt lik precisions-/återkallningskurvan, men istället för att plotta precision mot återkallelse visar ROC-kurvan den sanna positiva frekvensen (dvs. återkallelse) mot den falska positiva frekvensen. Den falska positiva frekvensen är förhållandet mellan negativa instanser som felaktigt klassificeras som positiva. Det är lika med ett minus den verkliga negativa kursen. Den verkliga negativa räntan kallas också specificitet. Därav plottar ROC-kurvan känslighet (återkallelse) kontra 1-specificitet
För att plotta ROC-kurvan behöver vi installera ett paket som heter ROCR. Vi kan hitta det i conda . Du kan skriva in koden:
conda install -c r r-rocr --yes
Vi kan plotta ROC med funktionerna prediction() och performance().
library(ROCR) ROCRpred <- prediction(predict, data_test$income) ROCRperf <- performance(ROCRpred, 'tpr', 'fpr') plot(ROCRperf, colorize = TRUE, text.adj = c(-0.2, 1.7))
Code Förklaring
- prediction(predict, data_test$income): ROCR-biblioteket måste skapa ett prediktionsobjekt för att transformera indata
- performance(ROCRpred, 'tpr','fpr'): Returnera de två kombinationerna för att producera i grafen. Här är tpr och fpr konstruerade. För att plotta precision och återkalla tillsammans, använd "prec", "rec".
Produktion:
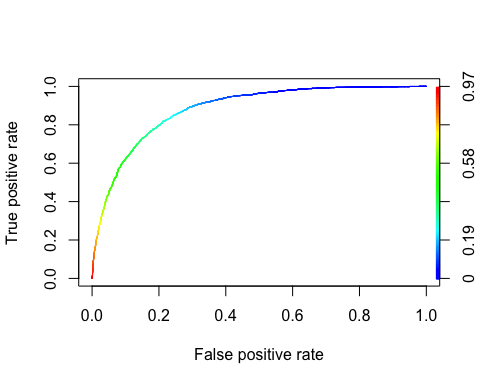
Steg 8) Förbättra modellen
Du kan försöka lägga till icke-linjäritet till modellen med interaktionen mellan
- ålder och timmar.per.vecka
- kön och timmar.per.vecka.
Sedan jämför du F1-poängen för båda modellerna.
formula_2 <- income~age: hours.per.week + gender: hours.per.week + . logit_2 <- glm(formula_2, data = data_train, family = 'binomial') predict_2 <- predict(logit_2, data_test, type = 'response') table_mat_2 <- table(data_test$income, predict_2 > 0.5) precision_2 <- precision(table_mat_2) recall_2 <- recall(table_mat_2) f1_2 <- 2 * ((precision_2 * recall_2) / (precision_2 + recall_2)) f1_2
Produktion:
## [1] 0.6109181
F1-poängen är något högre än den föregående. Du kan fortsätta arbeta med datan och försöka slå poängen.
Hur man tolkar GLM-koefficienter och oddskvoter i R
Sammanfattningstabellen som skrivs ut i steg 6 rapporterar koefficienter på log-odds skala, vilket är svårt att förklara för en icke-teknisk publik. Att omvandla dem till oddskvoter gör modellen mycket lättare att kommunicera.
Följ dessa fyra steg.
- Exponentiera koefficienterna. Tillämpa exp() på varje uppskattning så att log-oddsen blir multiplikativa oddskvoter.
- Lägg till ett konfidensintervall. Slå in confint() i exp() för att få 95-procentsintervallet på samma oddsskala.
- Jämför varje värde med 1. En oddskvot över 1 ökar sannolikheten för den positiva klassen, ett värde under 1 minskar den, och ett värde nära 1 innebär att prediktorn tillför lite.
- Kontrollera statistisk signifikans. Tolka endast prediktorer vars p-värde i sammanfattningsresultatet ligger under ditt valda tröskelvärde, vanligtvis 0.05.
# Convert log-odds coefficients into odds ratios odds_ratio <- exp(coef(logit)) round(odds_ratio, 3) # Odds ratios with 95% confidence intervals exp(cbind(OddsRatio = coef(logit), confint(logit)))
Läser utdata. Koefficienten för timmar per vecka i vår modell är 0.41942. Genom att exponentiera den får vi exp(0.41942) = 1.52, vilket innebär att en ökning med en standardavvikelse i veckoarbetstimmar multiplicerar oddsen för att tjäna över 50 000 med ungefär 1.5, medan alla andra variabler hålls konstanta.
Negativa koefficienter fungerar på samma sätt. marital.statusNot_married är -2.50346, så exp(-2.50346) = 0.08: ogifta individer har cirka 8 procent av oddsen för en gift individ. Eftersom de kontinuerliga prediktorerna standardiserades i steg 1, beskriv förändringar i standardavvikelseenheter, inte råa timmar.
Meddelande till andra familjer: Exponentierade koefficienter är oddskvoter endast under binomialfamiljen med en logit-länk. Med family = "poisson" och en logaritmisk länk läses samma exp()-värden som rate ratioer istället.
GLM i R: Snabbfunktionsreferens
Ha den här tabellen bredvid dig medan du programmerar. Den listar alla funktioner som används i de åtta stegen ovan, tillsammans med paketet som tillhandahåller dem och de argument som förväntas.
| Paket | Mål | Funktion | Argument |
|---|---|---|---|
| - | Skapa tåg/testdatauppsättning | create_train_set() | data, storlek, tåg |
| glm | Träna en generaliserad linjär modell | glm() | formel, data, familj* |
| glm | Sammanfatta modellen | sammanfattning() | monterad modell |
| bas | Gör förutsägelser | förutspå() | anpassad modell, dataset, typ = 'svar' |
| bas | Skapa en förvirringsmatris | tabell() | y, förutsäg() |
| bas | Skapa noggrannhetspoäng | summa(diag(tabell())/sum(tabell() | |
| ROCR | Skapa ROC: Steg 1 Skapa förutsägelse | förutsägelse() | förutsäga(), y |
| ROCR | Skapa ROC : Steg 2 Skapa prestanda | prestanda() | prediction(), 'tpr', 'fpr' |
| ROCR | Skapa ROC: Steg 3 Rita graf | komplott() | prestanda() |
Den andra GLM familjer som är tillgängliga genom familjeargumentet är:
- binomial: (länk = "logit")
- gaussisk: (länk = "identitet")
- Gamma: (länk = "invers")
- invers.gaussisk: (länk = "1/mu^2")
- poisson: (länk = "logg")
- kvasi: (länk = "identitet", varians = "konstant")
- kvasibinomial: (länk = "logit")
- kvasipoisson: (länk = "logg")