Multipel linjär regression i R: Enkelt och stegvis med exempel
⚡ Smart sammanfattning
Enkel och multipel linjär regression i R modellerar ett kontinuerligt utfall som en viktad summa av prediktorer anpassade med ordinära minstakvadrater. Denna genomgång täcker lm(), koefficientavläsning, faktorprediktorer, residualdiagnostik, prediktion och automatiskt variabelval.

Var linjär regression passar in i maskininlärning
Linjär regression är en av de äldsta övervakade maskininlärning algoritmer, och det är fortfarande den första modellen som de flesta analytiker siktar på. En av de tidigaste maskininlärningsapplikationerna var spam filter.
Andra vanliga tillämpningar av maskininlärning inkluderar:
- Identifiering av oönskade spammeddelanden i e-post
- Segmentering av kundbeteende för riktad annonsering
- Minskning av bedrägliga kreditkortstransaktioner
- Optimering av energianvändning i bostäder och kontorsbyggnader
- Ansiktsigenkänning
Övervakat lärande
In Övervakat lärande, innehåller träningsdatan du matar till algoritmen en etikett.
Klassificering är förmodligen den mest använda övervakade inlärningstekniken. En av de första klassificeringsuppgifterna som forskare tog sig an var spamfiltret. Syftet med inlärningen är att förutsäga om ett e-postmeddelande klassificeras som spam eller skinka (bra e-post). Maskinen kan, efter träningssteget, upptäcka e-postens klass.
regressioner används ofta inom maskininlärning för att förutsäga kontinuerliga värden. En regressionsuppgift kan förutsäga värdet på en beroende variabel baserat på en uppsättning av oberoende variabler (även kallade prediktorer eller regressorer). Till exempel kan linjära regressioner förutsäga en aktiekurs, väderprognos, försäljning och så vidare.
Några grundläggande övervakade inlärningsalgoritmer är:
- Linjär regression
- Logistisk återgång
- Närmaste grannar
- Support Vector Machine (SVM)
- Beslutsträd och Random Forest
- Neurala nätverk
Oövervakat lärande
In Oövervakat lärande, är träningsdata omärkta. Systemet försöker lära sig utan referens. Nedan finns en lista över oövervakade inlärningsalgoritmer.
- K-medelvärde
- Hierarkisk Cluster Analys
- Förväntningsmaximering
- Visualisering och dimensionsreduktion
- Huvudkomponentanalys
- Kärna PCA
- Lokalt-linjär inbäddning
Med den kontexten på plats bygger resten av den här handledningen regressionsmodeller i R steg för steg.
Enkel linjär regression i R
Linjär regression besvarar en enkel fråga: kan man mäta ett exakt samband mellan en målvariabel och en uppsättning prediktorer?
Den enklaste probabilistiska modellen är den linjära modellen:
![]()
var
- y = Beroende variabel
- x = Oberoende variabel
-
 = slumpmässig felkomponent
= slumpmässig felkomponent -
 = avlyssna
= avlyssna -
 = Koefficient för x
= Koefficient för x
Tänk på följande plot:
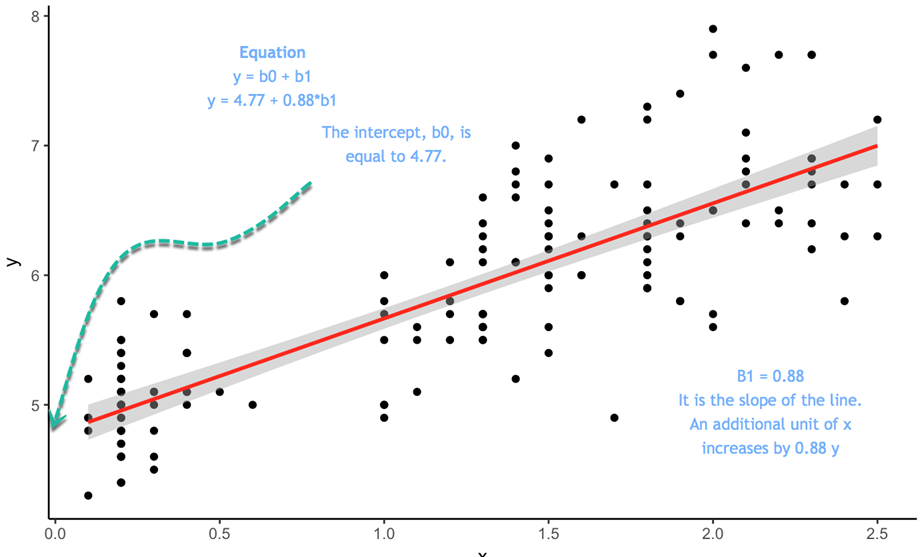
Ekvationen är ![]() I denna ekvation är skärningspunkten 4.77, så när x är lika med 0 är det anpassade värdet för y 4.77. Lutningen visar i vilken proportion y varierar när x varierar.
I denna ekvation är skärningspunkten 4.77, så när x är lika med 0 är det anpassade värdet för y 4.77. Lutningen visar i vilken proportion y varierar när x varierar.
Att uppskatta de optimala värdena på ![]() och
och ![]() , använder du en metod som heter Vanliga minsta kvadrater (OLS). Denna metod försöker hitta de parametrar som minimerar summan av kvadratfelen, det vill säga det vertikala avståndet mellan de förutsagda y-värdena och de faktiska y-värdena. Skillnaden är känd som felterm.
, använder du en metod som heter Vanliga minsta kvadrater (OLS). Denna metod försöker hitta de parametrar som minimerar summan av kvadratfelen, det vill säga det vertikala avståndet mellan de förutsagda y-värdena och de faktiska y-värdena. Skillnaden är känd som felterm.
Innan du uppskattar modellen kan du avgöra om ett linjärt samband mellan y och x är rimligt genom att plotta ett spridningsdiagram.
Scatterplot
Vi kommer att använda ett mycket enkelt dataset för att förklara konceptet med enkel linjär regression. Vi kommer att importera de genomsnittliga höjderna och vikterna för amerikanska kvinnor. Datauppsättningen innehåller 15 observationer. Du vill mäta om höjder är positivt korrelerade med vikter.
library(ggplot2) path <- 'https://raw.githubusercontent.com/guru99-edu/R-Programming/master/women.csv' df <-read.csv(path) ggplot(df,aes(x=height, y = weight))+ geom_point()
Produktion:

Spridningsdiagrammet antyder en generell tendens att vikten ökar när längden ökar. I nästa steg mäter du hur mycket vikten ökar för varje ytterligare längdenhet.
Minsta kvadraters uppskattningar
I en enkel OLS-regression, beräkningen av ![]() och
och ![]() är enkelt. Den här handledningen härleder inte formlerna, den anger dem bara.
är enkelt. Den här handledningen härleder inte formlerna, den anger dem bara.
Du vill uppskatta: ![]()
Målet med OLS-regressionen är att minimera följande ekvation:
![]()
var
![]() är det faktiska värdet och
är det faktiska värdet och ![]() är det förutsagda värdet.
är det förutsagda värdet.
Lösningen för ![]() is
is ![]()
Observera att ![]() betyder medelvärdet av x
betyder medelvärdet av x
Lösningen för ![]() is
is ![]()
I R kan du använda funktionerna cov() och var() för att uppskatta ![]() och du kan använda funktionen mean() för att uppskatta
och du kan använda funktionen mean() för att uppskatta ![]()
beta <- cov(df$height, df$weight) / var (df$height) beta
Produktion:
##[1] 3.45
alpha <- mean(df$weight) - beta * mean(df$height) alpha
Produktion:
## [1] -87.51667
Betakoefficienten innebär att för varje ytterligare tum i längd ökar den genomsnittliga vikten med 3.45 pund.
Att uppskatta en linjär ekvation för hand är lärorikt men opraktiskt. R tillhandahåller funktionen lm() för att göra det åt dig, och du kommer att använda den från och med nästa avsnitt. I verkliga projekt kommer du nästan aldrig att anpassa en modell med en enda prediktor; regressionsuppgifter involverar normalt många estimatorer samtidigt.
Multipel linjär regression i R
Praktiska tillämpningar av regressionsanalys använder modeller som är mer komplexa än den enkla linjära modellen. Den probabilistiska modellen som inkluderar mer än en oberoende variabel kallas flera regressionsmodeller. Den allmänna formen för denna modell är:
![]()
I matrisnotation kan du skriva om modellen:
Den beroende variabeln y är nu en funktion av k oberoende variabler. Värdet av koefficienten ![]() bestämmer bidraget från den oberoende variabeln
bestämmer bidraget från den oberoende variabeln ![]() och
och ![]() .
.
Vi presenterar kort antagandet vi gjorde om det slumpmässiga felet ![]() av OLS:
av OLS:
- Medelvärde lika med 0
- Varians lika med

- Normal distribution
- Slumpmässiga fel är oberoende (i en probabilistisk mening)
Du måste lösa för ![]() , vektorn av regressionskoefficienter som minimerar summan av de kvadratiska felen mellan de förutsagda och faktiska y-värdena.
, vektorn av regressionskoefficienter som minimerar summan av de kvadratiska felen mellan de förutsagda och faktiska y-värdena.
Lösningen i sluten form är:
![]()
med:
- indikerar transponering av matrisen X
 indikerar inverterbar matris
indikerar inverterbar matris
Exemplen nedan använder den inbyggda mtcars-datauppsättningen. Målet är att förutsäga miles per gallon (mpg) från en uppsättning funktioner.
Kontinuerliga variabler i R
För närvarande kommer du bara att använda de kontinuerliga variablerna och lägga undan kategoriska funktioner. Variabeln am är en binär variabel som tar värdet 1 om växellådan är manuell och 0 för automatiska bilar; vs är också en binär variabel.
library(dplyr) df <- mtcars %>% select(-c(am, vs, cyl, gear, carb)) glimpse(df)
Produktion:
## Observations: 32 ## Variables: 6 ## $ mpg <dbl> 21.0, 21.0, 22.8, 21.4, 18.7, 18.1, 14.3, 24.4, 22.8, 19.... ## $ disp <dbl> 160.0, 160.0, 108.0, 258.0, 360.0, 225.0, 360.0, 146.7, 1... ## $ hp <dbl> 110, 110, 93, 110, 175, 105, 245, 62, 95, 123, 123, 180, ... ## $ drat <dbl> 3.90, 3.90, 3.85, 3.08, 3.15, 2.76, 3.21, 3.69, 3.92, 3.9... ## $ wt <dbl> 2.620, 2.875, 2.320, 3.215, 3.440, 3.460, 3.570, 3.190, 3... ## $ qsec <dbl> 16.46, 17.02, 18.61, 19.44, 17.02, 20.22, 15.84, 20.00, 2...
Du kan använda lm()-funktionen för att beräkna parametrarna. Den grundläggande syntaxen för denna funktion är:
lm(formula, data, subset)
Arguments:
-formula: The equation you want to estimate
-data: The dataset used
-subset: Estimate the model on a subset of the dataset
Kom ihåg att en ekvation har följande form
![]()
i R
- Symbolen = ersätts med ~
- Varje x ersätts av variabelnamnet
- Om du vill släppa konstanten, lägg till -1 i slutet av formeln
Exempel:
Du vill uppskatta vikten av individer baserat på deras längd och inkomst. Ekvationen är
![]()
Ekvationen i R skrivs så här:
y ~ X1+ X2+…+Xn # Med skärning
Så för vårt exempel:
- Väg ~ höjd + intäkter
Ditt mål är att uppskatta milen per gallon baserat på en uppsättning variabler. Ekvationen att uppskatta är:
![]()
Du kommer att uppskatta din första linjära regression och lagra resultatet i passningsobjektet.
model <- mpg ~ disp + hp + drat + wt + qsec
fit <- lm(model, df)
fit
Code Förklaring
- modell <- mpg ~ disp + hk + drat + wt + qsec: Lagra modellen för att uppskatta
- lm(modell, df): Uppskatta modellen med dataramen df
## ## Call: ## lm(formula = model, data = df) ## ## Coefficients: ## (Intercept) disp hp drat wt ## 16.53357 0.00872 -0.02060 2.01577 -4.38546 ## qsec ## 0.64015
Utdata ger inte tillräckligt med information om kvaliteten på passformen. Du kan komma åt fler detaljer såsom betydelsen av koefficienterna, graden av frihet och formen på residualerna med summary()-funktionen.
summary(fit)
Produktion:
## return the p-value and coefficient ## ## Call: ## lm(formula = model, data = df) ## ## Residuals: ## Min 1Q Median 3Q Max ## -3.5404 -1.6701 -0.4264 1.1320 5.4996 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 16.53357 10.96423 1.508 0.14362 ## disp 0.00872 0.01119 0.779 0.44281 ## hp -0.02060 0.01528 -1.348 0.18936 ## drat 2.01578 1.30946 1.539 0.13579 ## wt -4.38546 1.24343 -3.527 0.00158 ** ## qsec 0.64015 0.45934 1.394 0.17523 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 2.558 on 26 degrees of freedom ## Multiple R-squared: 0.8489, Adjusted R-squared: 0.8199 ## F-statistic: 29.22 on 5 and 26 DF, p-value: 6.892e-10
Slutledning från tabellen ovan
- Tabellen visar ett starkt negativt samband mellan wt och mpg, och en positiv koefficient för drakt.
- Endast variabeln wt har en statistisk inverkan på mpg. Kom ihåg att för att testa en hypotes i statistik använder vi:
- H0: Ingen statistisk påverkan
- H1: Prediktorn har en meningsfull inverkan på y
- Om p-värdet är lägre än 0.05 indikerar det att variabeln är statistiskt signifikant
- Justerad R-kvadrat: andelen av variansen i y som förklaras av modellen, korrigerad för antalet prediktorer. Här är den 0.8199, så modellen förklarar cirka 82 procent av variansen i mpg. R-kvadrat ligger alltid mellan 0 och 1, och högre desto bättre.
Du kan köra ANOVA test för att uppskatta effekten av varje funktion på varianserna med funktionen anova().
anova(fit)
Produktion:
## Analysis of Variance Table ## ## Response: mpg ## Df Sum Sq Mean Sq F value Pr(>F) ## disp 1 808.89 808.89 123.6185 2.23e-11 *** ## hp 1 33.67 33.67 5.1449 0.031854 * ## drat 1 30.15 30.15 4.6073 0.041340 * ## wt 1 70.51 70.51 10.7754 0.002933 ** ## qsec 1 12.71 12.71 1.9422 0.175233 ## Residuals 26 170.13 6.54 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Ett mer konventionellt sätt att uppskatta modellens prestanda är att visa restprodukten mot olika mått.
Du kan använda funktionen plot() för att visa fyra grafer:
– Residualer vs Fitted värden
– Normal QQ-plot: Teoretisk kvartil vs standardiserade residualer
– Skala-placering: Inpassade värden vs kvadratrötter av de standardiserade residualerna
– Residualer vs Hävstång: Hävstång vs Standardiserade residualer
Du lägger till koden par(mfrow = c(2, 2)) före plot(fit). Om du inte lägger till denna kodrad uppmanas du att trycka på enter-kommandot för att visa nästa graf i R.
par(mfrow = c(2, 2))
Code Förklaring
- (mfrow=c(2,2)): returnera ett fönster med de fyra graferna sida vid sida.
- De första 2 lägger till antalet rader
- Den andra 2 lägger till antalet kolumner.
- Om du skriver (mfrow=c(3,2)): skapar du ett fönster med 3 rader och 2 kolumner
plot(fit)
Produktion:

Formeln lm() returnerar en lista som innehåller mycket användbar information. Du kan komma åt dem med det fit-objekt du har skapat, följt av $-tecknet och den information du vill ex.tract.
– koefficienter: "fit$koefficienter".
– residualer: `fit$residuals`
– anpassat värde: `fit$fitted.values`
Faktorer regression i R
I den senaste modelluppskattningen regresserar du mpg endast på kontinuerliga variabler. Det är enkelt att lägga till faktorvariabler till modellen. Du lägger till variabeln am till din modell. Det är viktigt att vara säker på att variabeln är en faktornivå och inte kontinuerlig.
df <- mtcars %>%
mutate(cyl = factor(cyl),
vs = factor(vs),
am = factor(am),
gear = factor(gear),
carb = factor(carb))
model <- mpg ~ .
summary(lm(model, df))
Produktion:
## ## Call: ## lm(formula = model, data = df) ## ## Residuals: ## Min 1Q Median 3Q Max ## -3.5087 -1.3584 -0.0948 0.7745 4.6251 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 23.87913 20.06582 1.190 0.2525 ## cyl6 -2.64870 3.04089 -0.871 0.3975 ## cyl8 -0.33616 7.15954 -0.047 0.9632 ## disp 0.03555 0.03190 1.114 0.2827 ## hp -0.07051 0.03943 -1.788 0.0939 . ## drat 1.18283 2.48348 0.476 0.6407 ## wt -4.52978 2.53875 -1.784 0.0946 . ## qsec 0.36784 0.93540 0.393 0.6997 ## vs1 1.93085 2.87126 0.672 0.5115 ## am1 1.21212 3.21355 0.377 0.7113 ## gear4 1.11435 3.79952 0.293 0.7733 ## gear5 2.52840 3.73636 0.677 0.5089 ## carb2 -0.97935 2.31797 -0.423 0.6787 ## carb3 2.99964 4.29355 0.699 0.4955 ## carb4 1.09142 4.44962 0.245 0.8096 ## carb6 4.47757 6.38406 0.701 0.4938 ## carb8 7.25041 8.36057 0.867 0.3995 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 2.833 on 15 degrees of freedom ## Multiple R-squared: 0.8931, Adjusted R-squared: 0.779 ## F-statistic: 7.83 on 16 and 15 DF, p-value: 0.000124
R använder den första faktornivån som en basgrupp. Du måste jämföra koefficienterna för den andra gruppen mot basgruppen.
Antaganden om linjär regression i R
Vanliga minstakvadratmetoder ger endast tillförlitliga koefficienter och p-värden när fem villkor uppfylls. De fyra diagnostiska diagrammen som produceras av plot(fit) finns just för att kontrollera dem.
- linjäritet: Sambandet mellan varje prediktor och y är linjärt. Kontrollera Residualer vs. monterade plot; en synlig kurva betyder att du behöver en transformation eller en polynomterm.
- Oberoende: Feltermerna är okorrelerade. Tidsordnad data bryter ofta mot detta, vilket du kan testa med durbinWatsonTest() från bilpaketet.
- homoskedasticitet: Felvariansen är konstant över anpassade värden. En trattform i Skalplats plotten signalerar ett brott.
- Residualernas normalitet: Felen följer en normalfördelning. Punkterna ska sitta på diagonalen till Normal QQ komplott.
- Ingen multikollinearitet: Prediktorer är inte i närheten av varandras kopior. En variansinflationsfaktor över 5 är den vanliga varningslinjen.
library(car) vif(fit) # variance inflation factors shapiro.test(residuals(fit)) # normality of residuals
Överträdelser ogiltigförklarar inte alltid en modell, men de förändrar hur säker du kan vara på p-värdena, så kontrollera dem innan du rapporterar någon koefficient.
Hur man gör förutsägelser med en linjär regressionsmodell i R
Att anpassa en modell är bara halva jobbet. Funktionen predict() tillämpar de anpassade koefficienterna på nya observationer.
predict(object, newdata, interval = "none", level = 0.95) arguments: -object: The model returned by lm() -newdata: A data frame whose columns match the predictors used in the formula -interval: "none", "confidence" for the mean response, or "prediction" for a single new case -level: The confidence level, 0.95 by default
Följ dessa tre steg.
- Bygg en dataram med nya fall. Kolumnnamnen måste exakt matcha prediktornamnen i formeln, och faktornivåerna måste matcha träningsdata.
- Anropa predict(). Skicka det anpassade objektet och den nya dataframen.
- Lägg till ett intervall. Välj ”konfidens” när du vill ha osäkerheten kring det genomsnittliga svaret och ”förutsägelse” när du vill ha räckvidden för en enskild bil.
new_cars <- data.frame(wt = c(2.5, 3.2), hp = c(110, 175)) fit_final <- lm(mpg ~ wt + hp, data = mtcars) predict(fit_final, newdata = new_cars) predict(fit_final, newdata = new_cars, interval = "prediction")
Läser resultatet. En bil som väger 11 000 kg och har 110 hästkrafter förväntas ha en förbrukning på ungefär 24.1 mpg. Prediktionintervallet är alltid bredare än konfidensintervallet, eftersom det bär osäkerheten i en enda observation utöver osäkerheten i den anpassade linjen.
Två regler håller förutsägelser ärliga. Extrapolera aldrig bortom träningsprediktorernas intervall, eftersom det inte finns några bevis för den raka linjen. Och utvärdera alltid på data som modellen inte har sett, annars är det rapporterade felet optimistiskt.
Linjär regression vs. logistisk regression i R
Analytiker använder ofta lm() när resultatet inte är kontinuerligt. Tabellen nedan visar var gränsen går.
| Kriterier | linjär regression | Logistisk återgång |
|---|---|---|
| Svarsvariabel | Kontinuerlig | Binär eller kategorisk |
| Förutspådd produktion | Vilket reellt tal som helst | En sannolikhet mellan 0 och 1 |
| Uppskattning | Vanliga minstakvadrater | Maximal sannolikhet |
| Passformsmått | R-kvadrat, RMSE | AIC, avvikelse, noggrannhet |
| R-funktion | lm(formel, data) | glm(formel, data, familj = "binomial") |
Om resultatet blir ett ja eller nej, gå vidare till generaliserad linjär modell istället för att tvinga fram en rak linje genom nollor och ettor.
Stegvis linjär regression i R
Den sista delen av denna handledning handlar om stegvis regression algoritm. Syftet med denna algoritm är att lägga till och ta bort potentiella kandidater i modellerna och behålla de som har en betydande inverkan på den beroende variabeln. Denna algoritm är meningsfull när datasetet innehåller en stor lista med prediktorer. Du behöver inte lägga till och ta bort de oberoende variablerna manuellt. Den stegvisa regressionen är byggd för att välja ut de bästa kandidaterna för att passa modellen.
Låt oss se hur det fungerar i praktiken. Du använder mtcars-datasetet med de kontinuerliga variablerna endast för pedagogisk illustration. Innan du börjar analysen är det bra att inspektera sambanden i data med en korrelationsmatris. GGally-biblioteket är en utökning av ggplot2.
Biblioteket innehåller olika funktioner för att visa sammanfattande statistik såsom korrelation och fördelning av alla variabler i en matris. Vi kommer att använda ggscatmat-funktionen, men du kan referera till karikatyrerna för mer information om GGally-biblioteket.
Den grundläggande syntaxen för ggscatmat() är:
ggscatmat(df, columns = 1:ncol(df), corMethod = "pearson") arguments: -df: A matrix of continuous variables -columns: Pick up the columns to use in the function. By default, all columns are used -corMethod: Define the function to compute the correlation between variable. By default, the algorithm uses the Pearson formula
Du visar korrelationen för alla dina variabler och bestämmer vilka som är de bästa kandidaterna för det första steget i den stegvisa regressionen. Det finns några starka korrelationer mellan dina variabler och den beroende variabeln, mpg.
library(GGally) df <- mtcars %>% select(-c(am, vs, cyl, gear, carb)) ggscatmat(df, columns = 1: ncol(df))
Produktion:

Stegvis regression Steg för steg Exempel
Variabelval är en viktig del av att anpassa en modell, och stegvis regression utför den sökningen automatiskt. För att uppskatta hur många möjliga val det finns i datamängden beräknar du ![]() med k är antalet prediktorer. Mängden möjligheter växer sig större med antalet oberoende variabler. Det är därför du behöver ha en automatisk sökning.
med k är antalet prediktorer. Mängden möjligheter växer sig större med antalet oberoende variabler. Det är därför du behöver ha en automatisk sökning.
Du måste installera olsrr-paketet från CRAN. Paketet är ännu inte tillgängligt i Anaconda. Därför installerar du det direkt från kommandoraden:
install.packages("olsrr")
Du kan plotta alla delmängder av möjligheter med anpassningskriterierna (dvs. R-kvadrat, Justerat R-kvadrat, Bayesianska kriterier). Modellen med de lägsta AIC-kriterierna blir den slutliga modellen.
library(olsrr) model <- mpg~. fit <- lm(model, df) test <- ols_all_subset(fit) plot(test)
Code Förklaring
- mpg ~.: Konstruera modellen för att uppskatta
- lm(modell, df): Kör OLS-modellen
- ols_all_subset(anpassning): Konstruera graferna med relevant statistisk information
- plot(test): Rita graferna
Produktion:

Linjära regressionsmodeller använder t-test för att uppskatta den statistiska effekten av en oberoende variabel på den beroende variabeln. Forskare sätter vanligtvis den maximala tröskeln till 10 procent, och lägre p-värden indikerar ett starkare statistiskt samband. Stegvis regression byggs kring detta test för att lägga till och ta bort kandidatprediktorer. Algoritmen fungerar enligt följande:

- steg 1: Regressera varje prediktor på y separat. Nämligen, regress x_1 på y, x_2 på y till x_n. Förvara p-värde och håll regressorn med ett p-värde lägre än ett definierat tröskelvärde (0.1 som standard). Prediktorerna med en signifikans lägre än tröskeln kommer att läggas till den slutliga modellen. Om ingen variabel har ett p-värde som är lägre än ingångströskeln, så stannar algoritmen, och du har din slutliga modell med endast en konstant.
- steg 2: Använd prediktorn med det lägsta p-värdet och lägg till en variabel separat. Du regresserar en konstant, den bästa prediktorn för steg ett och en tredje variabel. Till den stegvisa modellen lägger du till de nya prediktorerna med ett värde som är lägre än ingångströskeln. Om ingen variabel har ett p-värde lägre än 0.1, så stannar algoritmen och du har din slutliga modell med endast en prediktor. Du regresserar den stegvisa modellen för att kontrollera betydelsen av de bästa prediktorerna i steg 1. Om den är högre än borttagningströskeln behåller du den i den stegvisa modellen. Annars utesluter du det.
- steg 3: Du replikerar steg 2 på den nya bästa stegvisa modellen. Algoritmen lägger till prediktorer till den stegvisa modellen baserat på inmatningsvärdena och exkluderar prediktor från den stegvisa modellen om den inte uppfyller exkluderingströskeln.
- Algoritmen fortsätter tills ingen variabel kan läggas till eller exkluderas.
Du kan utföra algoritmen med funktionen ols_stepwise() från olsrr-paketet.
ols_stepwise(fit, pent = 0.1, prem = 0.3, details = FALSE) arguments: -fit: Model to fit. Need to use `lm()`before to run `ols_stepwise() -pent: Threshold of the p-value used to enter a variable into the stepwise model. By default, 0.1 -prem: Threshold of the p-value used to exclude a variable into the stepwise model. By default, 0.3 -details: Print the details of each step
⚠️ Paketinformation: senare versioner av olsrr har bytt namn på dessa funktioner. ols_step_all_possible() istället för ols_all_subset() och ols_step_both_p() istället för ols_stepwise(). Argumenten och utdata är oförändrade.
Innan det visar vi dig stegen i algoritmen. Nedan finns en tabell med de beroende och oberoende variablerna:
| Beroende variabel | Oberoende variabler |
|---|---|
| mpg | disp |
| hp | |
| råtta | |
| wt | |
| qsec |
Start
Till att börja med börjar algoritmen med att köra modellen på varje oberoende variabel separat. Tabellen visar p-värdet för varje modell.
## [[1]] ## (Intercept) disp ## 3.576586e-21 9.380327e-10 ## ## [[2]] ## (Intercept) hp ## 6.642736e-18 1.787835e-07 ## ## [[3]] ## (Intercept) drat ## 0.1796390847 0.0000177624 ## ## [[4]] ## (Intercept) wt ## 8.241799e-19 1.293959e-10 ## ## [[5] ## (Intercept) qsec ## 0.61385436 0.01708199
För att komma in i modellen behåller algoritmen variabeln med det lägsta p-värdet. Från ovanstående utdata är det wt
steg 1
I det första steget kör algoritmen mpg på wt och de andra variablerna oberoende.
## [[1]] ## (Intercept) wt disp ## 4.910746e-16 7.430725e-03 6.361981e-02 ## ## [[2]] ## (Intercept) wt hp ## 2.565459e-20 1.119647e-06 1.451229e-03 ## ## [[3]] ## (Intercept) wt drat ## 2.737824e-04 1.589075e-06 3.308544e-01 ## ## [[4]] ## (Intercept) wt qsec ## 7.650466e-04 2.518948e-11 1.499883e-03
Varje variabel är en potentiell kandidat att ingå i den slutliga modellen. Algoritmen behåller dock endast variabeln med det lägre p-värdet. Det visar sig att hp har ett något lägre p-värde än qsec, så hp ingår i den slutliga modellen.
steg 2
Algoritmen upprepar det första steget men denna gång med två oberoende variabler i den slutliga modellen.
## [[1]] ## (Intercept) wt hp disp ## 1.161936e-16 1.330991e-03 1.097103e-02 9.285070e-01 ## ## [[2]] ## (Intercept) wt hp drat ## 5.133678e-05 3.642961e-04 1.178415e-03 1.987554e-01 ## ## [[3]] ## (Intercept) wt hp qsec ## 2.784556e-03 3.217222e-06 2.441762e-01 2.546284e-01
Ingen av de återstående kandidaterna har ett p-värde under ingångströskeln. Algoritmen stannar här, och detta är den slutliga modellen:
## ## Call: ## lm(formula = mpg ~ wt + hp, data = df) ## ## Residuals: ## Min 1Q Median 3Q Max ## -3.941 -1.600 -0.182 1.050 5.854 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 37.22727 1.59879 23.285 < 2e-16 *** ## wt -3.87783 0.63273 -6.129 1.12e-06 *** ## hp -0.03177 0.00903 -3.519 0.00145 ** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 2.593 on 29 degrees of freedom ## Multiple R-squared: 0.8268, Adjusted R-squared: 0.8148 ## F-statistic: 69.21 on 2 and 29 DF, p-value: 9.109e-12
Du kan använda funktionen ols_stepwise() för att jämföra resultaten.
stp_s <-ols_stepwise(fit, details=TRUE)
Produktion:
Algoritmen hittar en lösning efter två steg och returnerar samma utdata som den manuella genomgången ovan.
Den slutliga modellen förklaras därför av två prediktorer och en intercept: miles per gallon är negativt relaterad till både bruttohästkrafter och vikt.
## You are selecting variables based on p value... ## 1 variable(s) added.... ## Variable Selection Procedure ## Dependent Variable: mpg ## ## Stepwise Selection: Step 1 ## ## Variable wt Entered ## ## Model Summary ## -------------------------------------------------------------- ## R 0.868 RMSE 3.046 ## R-Squared 0.753 Coef. Var 15.161 ## Adj. R-Squared 0.745 MSE 9.277 ## Pred R-Squared 0.709 MAE 2.341 ## -------------------------------------------------------------- ## RMSE: Root Mean Square Error ## MSE: Mean Square Error ## MAE: Mean Absolute Error ## ANOVA ## -------------------------------------------------------------------- ## Sum of ## Squares DF Mean Square F Sig. ## -------------------------------------------------------------------- ## Regression 847.725 1 847.725 91.375 0.0000 ## Residual 278.322 30 9.277 ## Total 1126.047 31 ## -------------------------------------------------------------------- ## ## Parameter Estimates ## ---------------------------------------------------------------------------------------- ## model Beta Std. Error Std. Beta t Sig lower upper ## ---------------------------------------------------------------------------------------- ## (Intercept) 37.285 1.878 19.858 0.000 33.450 41.120 ## wt -5.344 0.559 -0.868 -9.559 0.000 -6.486 -4.203 ## ---------------------------------------------------------------------------------------- ## 1 variable(s) added... ## Stepwise Selection: Step 2 ## ## Variable hp Entered ## ## Model Summary ## -------------------------------------------------------------- ## R 0.909 RMSE 2.593 ## R-Squared 0.827 Coef. Var 12.909 ## Adj. R-Squared 0.815 MSE 6.726 ## Pred R-Squared 0.781 MAE 1.901 ## -------------------------------------------------------------- ## RMSE: Root Mean Square Error ## MSE: Mean Square Error ## MAE: Mean Absolute Error ## ANOVA ## -------------------------------------------------------------------- ## Sum of ## Squares DF Mean Square F Sig. ## -------------------------------------------------------------------- ## Regression 930.999 2 465.500 69.211 0.0000 ## Residual 195.048 29 6.726 ## Total 1126.047 31 ## -------------------------------------------------------------------- ## ## Parameter Estimates ## ---------------------------------------------------------------------------------------- ## model Beta Std. Error Std. Beta t Sig lower upper ## ---------------------------------------------------------------------------------------- ## (Intercept) 37.227 1.599 23.285 0.000 33.957 40.497 ## wt -3.878 0.633 -0.630 -6.129 0.000 -5.172 -2.584 ## hp -0.032 0.009 -0.361 -3.519 0.001 -0.050 -0.013 ## ---------------------------------------------------------------------------------------- ## No more variables to be added or removed.
Linjär regression i R: Viktiga slutsatser och funktionsreferens
- Linjär regression besvarar en enkel fråga: kan man mäta ett exakt samband mellan en målvariabel och en uppsättning prediktorer?
- Den vanliga minstakvadratmetoden hittar de parametrar som minimerar summan av de kvadrerade felen, det vill säga det vertikala avståndet mellan de förutspådda y-värdena och de faktiska y-värdena.
- Den sannolikhetsmodell som innehåller mer än en oberoende variabel kallas multipla regressionsmodeller.
- Syftet med Stepwise Linear Regression-algoritmen är att lägga till och ta bort potentiella kandidater i modellerna och behålla de som har en betydande inverkan på den beroende variabeln.
- Variabelval är en viktig del av att anpassa en modell, och stegvis regression utför den sökningen automatiskt.
Varje funktion som används i den här handledningen listas nedan:
| Bibliotek | Mål | Funktion | Argument |
|---|---|---|---|
| bas | Beräkna en linjär regression | lm() | formel, data |
| bas | Sammanfatta modellen | sammanfattning() | passa |
| bas | Extract-koefficienter | lm()$koefficient | |
| bas | Extract-rester | lm()$rester | |
| bas | Extract-anpassat värde | lm()$fitted.values | |
| olsrr | Kör stegvis regression | ols_stepwise() | passform, pent = 0.1, prem = 0.3, detaljer = FALSK |
AnmärkningarKom ihåg att konvertera kategoriska variabler till faktorer innan du anpassar modellen.