Matrice di correlazione di Pearson e Spearman in R con esempio
⚡ Riepilogo intelligente
In R, la correlazione di Pearson e la correlazione di Spearman misurano la forza con cui due variabili si muovono insieme, utilizzando la funzione `cor()` per una singola coppia e una matrice di correlazione per più coppie. Questa guida illustra anche i test di significatività con `Hmisc` e visualizza i risultati con le mappe di calore di GGally.

Correlazione bivariata in R
Una relazione bivariata descrive una relazione, o correlazione, tra due variabili in R. In questo tutorial discuteremo il concetto di correlazione e mostreremo come può essere utilizzato per misurare la relazione tra due variabili qualsiasi in R.
Correlazione nella programmazione R
Esistono due metodi principali per calcolare la correlazione tra due variabili nella programmazione R:
- Pearson: Correlazione parametrica
- Spearman: Correlazione non parametrica
Matrice di correlazione di Pearson in R
Il metodo di correlazione di Pearson viene solitamente utilizzato come controllo primario per la relazione tra due variabili.
Migliori coefficiente di correlazione, scritto r, misura la forza del lineare relazione tra due variabili x e y. Si calcola nel modo seguente:
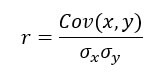
con
 è la deviazione standard di x
è la deviazione standard di x è la deviazione standard di y
è la deviazione standard di y
La correlazione varia tra -1 e 1.
- Un valore di r vicino o uguale a 0 implica una relazione lineare scarsa o nulla tra x e y.
- Quanto più r si avvicina a 1 o a -1, tanto più forte è la relazione lineare.
È possibile verificare se r è diverso da zero utilizzando la statistica t riportata di seguito, confrontandola con la distribuzione t di Student con n – 2 gradi di libertà:
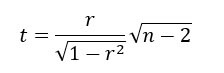
Correlazione del rango di Spearman in R
La correlazione di rango ordina le osservazioni in base al rango e calcola il livello di somiglianza tra i ranghi. La correlazione di rango ha il vantaggio di essere robusta rispetto ai valori anomali e non è legata alla distribuzione dei dati. La correlazione di rango è inoltre la scelta più appropriata per le variabili ordinali.
Il coefficiente di correlazione di rango di Spearman, indicato con rho, varia anch'esso da -1 a 1, e valori prossimi a uno dei due estremi indicano una forte relazione monotona. Si calcola nel modo seguente:
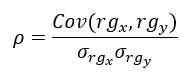
Il numeratore è la covarianza tra i ranghi di x e y, e il denominatore è il prodotto delle loro deviazioni standard.
In R, entrambi vengono calcolati con la funzione cor(), che accetta tre argomenti: x, y e metodo.
cor(x, y, method)
argomenti:
- x: Primo vettore
- y: Secondo vettore
- metodo: La formula utilizzata per calcolare la correlazione. Tre valori stringa:
- “perone”
- “Kendall”
- “lanciere”
È possibile aggiungere un argomento facoltativo se i vettori contengono valori mancanti: use = “complete.obs”
Utilizzeremo il set di dati BudgetUK. Questo set di dati riporta la dotazione di bilancio delle famiglie britanniche tra il 1980 e il 1982. Sono presenti 1519 osservazioni con dieci caratteristiche, tra cui:
- wfood: condividere la spesa per il cibo
- wcarburante: condividere la spesa per il carburante
- wcloth: quota di budget per la spesa in abbigliamento
- Walc: condividere la spesa per l'alcol
- wtrans: condividere la spesa per i trasporti
- altro: quota di spesa per altri beni
- totex: spesa totale delle famiglie in sterline
- reddito: reddito familiare netto totale
- : età del nucleo familiare
- bambini: Numero di bambini
Esempio
library(dplyr) PATH <- "https://raw.githubusercontent.com/guru99-edu/R-Programming/master/british_household.csv" data <- read.csv(PATH) %>% filter(income < 500) %>% mutate(log_income = log(income), log_totexp = log(totexp), children_fac = factor(children, order = TRUE, labels = c("No", "Yes"))) %>% select(-c(X, X.1, children, totexp, income)) glimpse(data)
Code Spiegazione
- Per prima cosa importiamo i dati e diamo un'occhiata con la funzione scorce() dalla libreria dplyr.
- Tre nuclei familiari dichiarano un reddito pari o superiore a 500, quindi il filtro (reddito < 500) li rimuove e il numero di righe scende da 1,519 a 1,516.
- È una pratica comune convertire una variabile monetaria in log. Aiuta a ridurre l'impatto dei valori anomali e diminuisce l'asimmetria nel set di dati.
Produzione:
## Observations: 1,516 ## Variables: 10 ## $ wfood <dbl> 0.4272, 0.3739, 0.1941, 0.4438, 0.3331, 0.3752, 0... ## $ wfuel <dbl> 0.1342, 0.1686, 0.4056, 0.1258, 0.0824, 0.0481, 0... ## $ wcloth <dbl> 0.0000, 0.0091, 0.0012, 0.0539, 0.0399, 0.1170, 0... ## $ walc <dbl> 0.0106, 0.0825, 0.0513, 0.0397, 0.1571, 0.0210, 0... ## $ wtrans <dbl> 0.1458, 0.1215, 0.2063, 0.0652, 0.2403, 0.0955, 0... ## $ wother <dbl> 0.2822, 0.2444, 0.1415, 0.2716, 0.1473, 0.3431, 0... ## $ age <int> 25, 39, 47, 33, 31, 24, 46, 25, 30, 41, 48, 24, 2... ## $ log_income <dbl> 4.867534, 5.010635, 5.438079, 4.605170, 4.605170,... ## $ log_totexp <dbl> 3.912023, 4.499810, 5.192957, 4.382027, 4.499810,... ## $ children_fac <ord> Yes, Yes, Yes, Yes, No, No, No, No, No, No, Yes, ...
Possiamo calcolare il coefficiente di correlazione tra le variabili reddito e cibo con i metodi “pearson” e “spearman”.
cor(data$log_income, data$wfood, method = "pearson")
Produzione:
## [1] -0.2466986
cor(data$log_income, data$wfood, method = "spearman")
Produzione:
## [1] -0.2501252
Prima di estendere questo concetto a ogni coppia di variabili, è opportuno chiarire come interpretare un singolo coefficiente.
Come interpretare un coefficiente di correlazione
Un coefficiente è utile solo se se ne conosce il significato. Le bande sottostanti rappresentano la lettura convenzionale, e il segno si legge separatamente dall'intensità.
| Valore assoluto di r | Forza della relazione |
|---|---|
| 0.00 a 0.19 | Molto debole o assente |
| 0.20 a 0.39 | Debole |
| 0.40 a 0.59 | Moderato |
| 0.60 a 0.79 | Forte |
| 0.80 a 1.00 | Molto forte |
Il valore di -0.2467 calcolato in precedenza tra log_income e wfood indica quindi una debole correlazione negativa: le famiglie più ricche spendono una quota leggermente inferiore del loro budget per il cibo.
Per ogni coefficiente si applicano tre avvertenze.
- La correlazione non è causalità. Un valore elevato di r indica che le due variabili si muovono insieme, non che una causi l'altra. Spesso, una terza variabile non misurata influenza entrambe.
- Pearson vede solo linee rette. Una relazione a forma di U perfetta restituisce un valore di r prossimo allo zero. È sempre consigliabile rappresentare graficamente i dati prima di fidarsi del valore numerico.
- Le dimensioni contano più del significato. Con 1,516 osservazioni, un coefficiente di 0.06 può essere statisticamente significativo e al contempo praticamente privo di significato.
Come testare la significatività della correlazione con cor.test()
La funzione cor() restituisce solo il coefficiente e nient'altro. Per una singola coppia, cor.test() aggiunge il valore p e l'intervallo di confidenza in un'unica chiamata.
cor.test(data$log_income, data$wfood, method = "pearson")
Il risultato è suddiviso in quattro parti che meritano di essere lette.
- t e df: la statistica del test e i suoi gradi di libertà, n – 2.
- p-value: la probabilità di osservare un coefficiente così elevato se la vera correlazione fosse pari a zero.
- intervallo di confidenza del 95%: l'intervallo plausibile per la vera correlazione. Se esclude lo zero, la relazione è significativa a quel livello.
- stima del campione: il coefficiente stesso, identico a quello restituito da cor().
La stessa funzione esegue i test basati sul rango modificando un solo argomento:
# Spearman rank correlation with a p-value cor.test(data$log_income, data$wfood, method = "spearman") # One-sided test: is the correlation greater than zero? cor.test(data$log_income, data$wfood, alternative = "greater")
Quando usare l'uno o l'altro. Utilizza `cor.test()` quando esamini una coppia specifica, perché fornisce l'intervallo di confidenza che `rcorr()` omette. Utilizza `rcorr()` della classe `Hmisc`, mostrata sopra, quando hai bisogno dei valori p per un'intera matrice contemporaneamente. Tieni presente che testare molte coppie aumenta il tasso di falsi positivi, quindi correggi i valori p con `p.adjust(p_value, method = “BH”)` prima di trarre conclusioni da una matrice di grandi dimensioni.
Matrice di correlazione in R
Una correlazione bivariata è un buon punto di partenza, ma una visione multivariata offre un quadro più ampio. matrice di correlazione è una tabella quadrata che contiene la correlazione a coppie di ogni variabile con ogni altra.
La funzione cor() restituisce una matrice di correlazione. L'unica differenza con la correlazione bivariata è che non è necessario specificare quali variabili. Per impostazione predefinita, R calcola la correlazione tra tutte le variabili.
Non è possibile calcolare la correlazione per un fattore, quindi elimina tutte le colonne categoriche prima di passare il dataframe alla funzione cor().
Una matrice di correlazione è simmetrica, il che significa che i valori sopra la diagonale hanno gli stessi valori di quello sotto. È più visivo mostrare metà della matrice.
children_fac è escluso perché cor() non può operare su un fattore.
# the last column of data is a factor level. We don't include it in the code mat_1 <-as.dist(round(cor(data[,1:9]),2)) mat_1
Code Spiegazione
- cor(data[, 1:9])Calcola la matrice di correlazione sulle nove colonne numeriche
- round(…, 2): Arrotondare ogni coefficiente a due cifre decimali
- as.dist()Stampa solo il triangolo inferiore, poiché la matrice è simmetrica
Produzione:
## wfood wfuel wcloth walc wtrans wother age log_income ## wfuel 0.11 ## wcloth -0.33 -0.25 ## walc -0.12 -0.13 -0.09 ## wtrans -0.34 -0.16 -0.19 -0.22 ## wother -0.35 -0.14 -0.22 -0.12 -0.29 ## age 0.02 -0.05 0.04 -0.14 0.03 0.02 ## log_income -0.25 -0.12 0.10 0.04 0.06 0.13 0.23 ## log_totexp -0.50 -0.36 0.34 0.12 0.15 0.15 0.21 0.49
Livello di significatività
Un coefficiente da solo non indica se la relazione è statisticamente affidabile. La funzione rcorr() della libreria Hmisc restituisce il p-value per ogni coppia. Possiamo scaricare la libreria da contea e copia il codice per incollarlo nel terminale:
conda install -c r r-hmisc
rcorr() richiede che un frame di dati venga memorizzato come matrice. Possiamo convertire i nostri dati in una matrice prima di calcolare la matrice di correlazione con il valore p.
library("Hmisc") data_rcorr <-as.matrix(data[, 1: 9]) mat_2 <-rcorr(data_rcorr) # mat_2 <-rcorr(as.matrix(data)) returns the same output
L'oggetto lista mat_2 contiene tre elementi:
- r: Output della matrice di correlazione
- n: Numero di osservazioni
- P: valore p
A noi interessa il terzo elemento, il valore p. È comune mostrare la matrice di correlazione con il valore p anziché con il coefficiente di correlazione.
p_value <-round(mat_2[["P"]], 3) p_value
Code Spiegazione
- mat_2[[“P”]]: I valori p sono memorizzati nell'elemento chiamato P
- giro(mat_2[[“P”]], 3): Arrotonda gli elementi con tre cifre
Produzione:
wfood wfuel wcloth walc wtrans wother age log_income log_totexp wfood NA 0.000 0.000 0.000 0.000 0.000 0.365 0.000 0 wfuel 0.000 NA 0.000 0.000 0.000 0.000 0.076 0.000 0 wcloth 0.000 0.000 NA 0.001 0.000 0.000 0.160 0.000 0 walc 0.000 0.000 0.001 NA 0.000 0.000 0.000 0.105 0 wtrans 0.000 0.000 0.000 0.000 NA 0.000 0.259 0.020 0 wother 0.000 0.000 0.000 0.000 0.000 NA 0.355 0.000 0 age 0.365 0.076 0.160 0.000 0.259 0.355 NA 0.000 0 log_income 0.000 0.000 0.000 0.105 0.020 0.000 0.000 NA 0 log_totexp 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 NA
Visualizzazione della matrice di correlazione in R
Una mappa di calore è un altro modo per leggere una matrice di correlazione. La libreria GGally estende ggplot2 e viene installata da CRAN anziché da conda:
install.packages("GGally")

La libreria include diverse funzioni per mostrare le statistiche riassuntive come la correlazione e la distribuzione di tutte le variabili in a matrice.
La funzione ggcorr() ha molti argomenti. Introdurremo solo gli argomenti che utilizzeremo nel tutorial:
La funzione ggcorr
ggcorr(df, method = c("pairwise", "pearson"), nbreaks = NULL, digits = 2, low = "#3B9AB2", mid = "#EEEEEE", high = "#F21A00", geom = "tile", label = FALSE, label_alpha = FALSE)
Argomenti:
- df: set di dati utilizzato
- metodo: Formula per calcolare la correlazione. Per impostazione predefinita, vengono calcolati pairwise e Pearson
- nbreaks: Restituisce un intervallo categoriale per la colorazione dei coefficienti. Per impostazione predefinita, nessuna interruzione e la sfumatura di colore è continua
- cifre: Arrotonda il coefficiente di correlazione. Per impostazione predefinita, impostato su 2
- Basso: controlla il livello inferiore della colorazione
- e lancio di program changes: controlla il livello medio della colorazione
- alto: Controlla il livello elevato della colorazione
- geome: controlla la forma dell'argomento geometrico. Per impostazione predefinita, "piastrella"
- etichetta: valore booleano. Visualizzare o meno l'etichetta. Per impostazione predefinita, impostato su "FALSE".
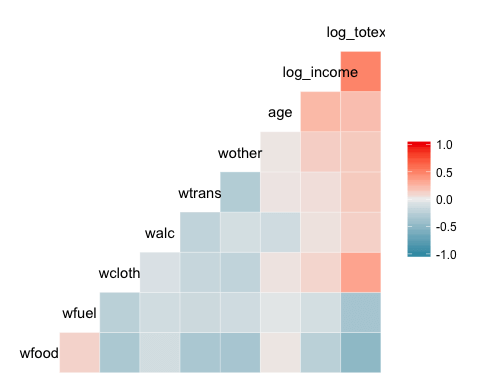
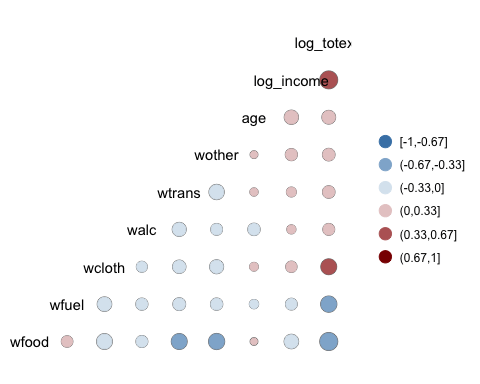
Mappa termica di base
La trama più semplice del pacchetto è una mappa termica. La legenda del grafico mostra un gradiente di colore da – 1 a 1, con il colore caldo che indica una forte correlazione positiva e il colore freddo, una correlazione negativa.
library(GGally) ggcorr(data)
Code Spiegazione
- ggcorr(dati): è necessario un solo argomento, ovvero il nome del frame di dati. Le variabili a livello di fattore non sono incluse nel grafico.
Produzione:
Aggiunta di controllo alla mappa di calore
Possiamo aggiungere più controlli al grafico:
ggcorr(data, nbreaks = 6, low = "steelblue", mid = "white", high = "darkred", geom = "circle")
Code Spiegazione
- ninterruzioni=6: spezza la leggenda con 6 gradi.
- basso = “bluacciaio”: utilizza colori più chiari per la correlazione negativa
- metà = “bianco”: utilizzare i colori bianchi per la correlazione dei range medi
- alto = “rosso scuro”: utilizza colori scuri per una correlazione positiva
- geom = “cerchio”: Usa il cerchio come forma delle finestre nella mappa termica. La dimensione del cerchio è proporzionale al valore assoluto della correlazione.
Produzione:
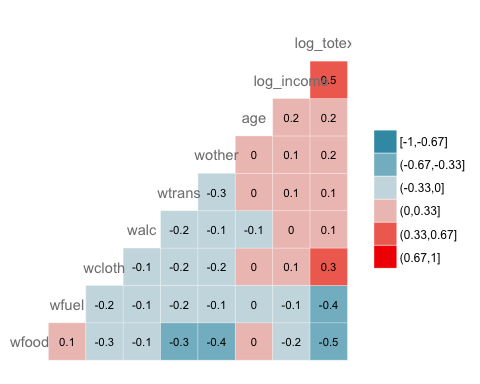
Aggiunta di un'etichetta alla mappa termica
GGally ci permette di aggiungere un'etichetta all'interno delle finestre:
ggcorr(data, nbreaks = 6, label = TRUE, label_size = 3, color = "grey50")
Code Spiegazione
- etichetta = VERO: Sommare i valori dei coefficienti di correlazione all'interno della mappa termica.
- colore = “grigio50”: Scegli il colore, ovvero grigio
- etichetta_dimensione = 3: imposta la dimensione dell'etichetta su 3
Produzione:
La funzione ggpairs
La libreria GGally fornisce anche la funzione ggpairs(), che restituisce una matrice di grafici. Per k variabili selezionate, il risultato è una griglia ak x k: la diagonale mostra la distribuzione di ciascuna variabile, mentre i pannelli sopra e sotto la diagonale possono contenere ciascuno un calcolo diverso. La sintassi è:
ggpairs(df, columns = 1:ncol(df), title = NULL, upper = list(continuous = "cor"), lower = list(continuous = "smooth"), mapping = NULL)
Argomenti:
- df: set di dati utilizzato
- colonne: Seleziona le colonne per disegnare la trama
- titolo: include un titolo
- superiore: Controlla le caselle sopra la diagonale del grafico. È necessario fornire il tipo di calcoli o grafico da restituire. Se continuous = “cor”, chiediamo a R di calcolare la correlazione. Nota che l'argomento deve essere un elenco. Sono disponibili altri argomenti; vedi il Documentazione GGally per maggiori informazioni.
- abbassarla: Controlla le caselle sotto la diagonale.
- carta geograficaping: Indica l'estetica del grafico. Ad esempio, possiamo calcolare il grafico per diversi gruppi.
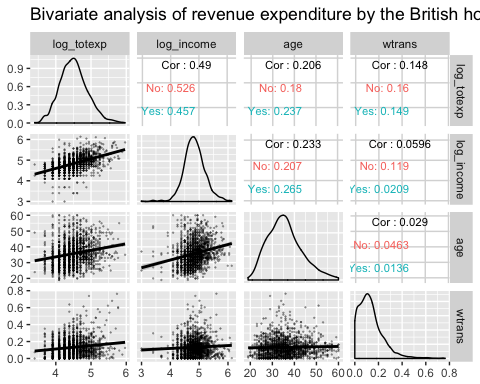
Analisi bivariata con ggpair con gruping
Il grafico successivo traccia tre informazioni:
- La matrice di correlazione tra log_totexp, log_reddito, età e la variabile wtrans raggruppata in base al fatto che la famiglia abbia o meno un figlio.
- Traccia la distribuzione di ciascuna variabile per gruppo
- Visualizza il grafico a dispersione con l'andamento per gruppo
library(ggplot2) ggpairs(data, columns = c("log_totexp", "log_income", "age", "wtrans"), title = "Bivariate analysis of revenue expenditure by the British household", upper = list(continuous = wrap("cor", size = 3)), lower = list(continuous = wrap("smooth", alpha = 0.3, size = 0.1)), mapping = aes(color = children_fac))
Code Spiegazione
- colonne = c("log_totexp", "log_reddito", "età", "wtrans"): Scegli le variabili da mostrare nel grafico
- title = “Analisi bivariata della spesa delle entrate delle famiglie britanniche”: aggiungi un titolo
- superiore = elenco(): controlla la parte superiore del grafico. Cioè sopra la diagonale
- continuo = avvolgere("cor", dimensione = 3)): Calcola il coefficiente di correlazione. Avvolgiamo l'argomento continuo all'interno della funzione wrap() per controllare l'estetica del grafico (cioè dimensione = 3) -lower = list(): controlla la parte inferiore del grafico. Cioè sotto la diagonale.
- continuo = avvolgere("liscio",alfa = 0.3,dimensione=0.1): aggiunge un grafico a dispersione con un andamento lineare. Avvolgiamo l'argomento continuo all'interno della funzione wrap() per controllare l'estetica del grafico (ad esempio size=0.1, alpha=0.3)
- carta geograficaping = aes(color = children_face): Dividi ogni pannello in base a children_fac, il fattore ordinato etichettato "No" per le famiglie senza figli e "Sì" per le famiglie con figli
Produzione:

Analisi bivariata con ggpair con gruppo parzialeping
Il grafico sottostante è leggermente diverso. Cambiamo la posizione della mappa.ping all'interno dell'argomento superiore.
ggpairs(data, columns = c("log_totexp", "log_income", "age", "wtrans"), title = "Bivariate analysis of revenue expenditure by the British household", upper = list(continuous = wrap("cor", size = 3), mapping = aes(color = children_fac)), lower = list( continuous = wrap("smooth", alpha = 0.3, size = 0.1)) )
Code Spiegazione
- Stesso codice dell'esempio precedente tranne che per:
- carta geograficaping = aes(color = children_fac): Sposta la lista in alto = list(). Vogliamo solo il calcolo impilato per gruppo nella parte superiore del grafico.
Produzione:
Correlazione in R: punti chiave e riferimento alle funzioni
- Una relazione bivariata descrive una relazione, o correlazione, tra due variabili in R.
- Esistono due metodi principali per calcolare la correlazione tra due variabili in R Programmazione: Pearson e Spearman.
- Il metodo di correlazione di Pearson viene solitamente utilizzato come controllo primario per la relazione tra due variabili.
- Una correlazione di rango ordina le osservazioni in base al rango e calcola il livello di somiglianza tra i ranghi.
- Il coefficiente di correlazione di rango di Spearman varia da -1 a 1, e valori prossimi a uno dei due estremi indicano una forte relazione monotona.
- Una matrice di correlazione è una tabella quadrata che contiene la correlazione a coppie di ogni variabile.
- Il valore p indica se una correlazione osservata è statisticamente distinguibile da zero.
Tutte le funzioni di correlazione utilizzate in questo tutorial sono elencate di seguito:
| Biblioteca | Obiettivo | Metodo | Code |
|---|---|---|---|
| Tavola XY | Correlazione bivariata | Pearson |
cor(dfx2, method = "pearson") |
| Tavola XY | Correlazione bivariata | Spearman |
cor(dfx2, method = "spearman") |
| Tavola XY | Correlazione multivariata | Pearson |
cor(df, method = "pearson") |
| Tavola XY | Correlazione multivariata | Spearman |
cor(df, method = "spearman") |
| Hmisc | Valore P | - |
rcorr(as.matrix(data[,1:9]))[["P"]] |
| GGally | Mappa di calore | - |
ggcorr(df)
|
| GGally | matrice di grafici multivariati | - |
ggpairs(df, columns = c("x1", "x2")) |