Tutorial Keras
⚡ Riepilogo intelligente
Questo tutorial su Keras introduce l'API di alto livello per le reti neurali che operano su TensorFlow. LessQuesta guida illustra cos'è Keras, la sua architettura, i modelli, i livelli, l'installazione, l'addestramento, la valutazione e il confronto con TensorFlow per i flussi di lavoro di deep learning.

Cos'è Keras?
Keras è una libreria di rete neurale open source scritta in Python che funziona sopra Theano o Tensorflow. È progettato per essere modulare, veloce e facile da usare. È stato sviluppato da François Chollet, un Google ingegnere. Keras non gestisce i calcoli di basso livello. Utilizza invece un'altra libreria per farlo, chiamata "Backend".
Keras è un wrapper API di alto livello per l'API di basso livello, in grado di funzionare su TensorFlow, CNTK o Theano. L'API di alto livello Keras gestisce il modo in cui creiamo modelli, definiamo livelli o impostiamo più modelli input-output. In questo livello, Keras compila anche il nostro modello con funzioni di perdita e ottimizzatore, processo di allenamento con funzione di adattamento. Keras dentro Python non gestisce API di basso livello come la creazione del grafico computazionale, la creazione di tensori o altre variabili perché è stata gestita dal motore "backend".
Cos'è un backend?
Backend è un termine in Keras che esegue tutti i calcoli di basso livello come prodotti tensoriali, convoluzioni e molte altre cose con l'aiuto di altre librerie come Tensorflow o Theano. Quindi, il “motore backend” eseguirà il calcolo e lo sviluppo dei modelli. Tensorflow è il "motore backend" predefinito ma possiamo modificarlo nella configurazione.
Theano, Tensorflow e backend CNTK

Theano è un progetto open source sviluppato dal gruppo MILA presso l'Università di Montreal, Quebec, Canada. È stato il primo Framework ampiamente utilizzato. È un Python libreria che aiuta negli array multidimensionali per operazioni matematiche usando Numpy o Scipy. Theano può usare GPU per un calcolo più veloce, può anche costruire automaticamente grafici simbolici per il calcolo dei gradienti. Sul suo sito web, Theano afferma di poter riconoscere espressioni numericamente instabili e calcolarle con algoritmi più stabili, il che è molto utile per le nostre espressioni instabili.

D'altra parte, Tensorflow è la stella nascente nel framework di deep learning. Sviluppato da GoogleIl team Brain ha creato lo strumento di deep learning più popolare. Ricco di funzionalità, vanta numerosi ricercatori che contribuiscono al suo sviluppo per scopi di deep learning.

Un altro motore backend per Keras è The Microsoft Toolkit cognitivo o CNTK. È un framework di deep learning open source sviluppato da Microsoft Squadra. Può essere eseguito su più GPU o più macchine per l'addestramento del modello di deep learning su vasta scala. In alcuni casi, CNTK è stato segnalato più velocemente di altri framework come Tensorflow o Theano. Successivamente in questo tutorial di Keras CNN, confronteremo i backend di Theano, TensorFlow e CNTK.
Confronto tra i backend
Dobbiamo fare un benchmark per conoscere il confronto tra questi due backend. Come puoi vedere in Il punto di riferimento di Jeong-Yoon Lee, vengono confrontate le prestazioni di 3 diversi backend su hardware diverso. E il risultato è che Theano è più lento dell'altro backend, è stato riferito volte 50 più lento, ma la precisione è vicina l'una all'altra.
Un altro test di riferimento viene eseguito da Jas incontra Bhatia. Ha riferito che Theano è più lento di Tensorflow per alcuni test. Ma la precisione complessiva è quasi la stessa per ogni rete testata.
Quindi, tra Theano, Tensorflow e CTK è ovvio che TensorFlow è migliore di Theano. Con TensorFlow, il tempo di calcolo è molto più breve e la CNN è migliore delle altre.
Avanti in questo Keras Python tutorial, impareremo la differenza tra Keras e TensorFlow (Keras contro Tensorflow).
Keras contro Tensorflow
| Scheda Sintetica | Keras | tensorflow |
|---|---|---|
| Tipo | Wrapper API di alto livello | API di basso livello |
| Complessità | Facile da usare se tu Python Lingua | È necessario imparare la sintassi dell'utilizzo di alcune funzioni di Tensorflow |
| Missione | Distribuzione rapida per creare modelli con livelli standard | Consente di creare un grafico computazionale arbitrario o livelli di modello |
| Strumenti | Utilizza altri strumenti di debug API come TFDBG | Puoi utilizzare gli strumenti di visualizzazione Tensorboard |
| Comunità | Grandi comunità attive | Grandi comunità attive e risorse ampiamente condivise |
Vantaggi di Keras
Distribuzione rapida e facile da comprendere
Keras è molto veloce nel realizzare un modello di rete. Se vuoi creare un semplice modello di rete con poche righe, Python Keras può aiutarti in questo. Guarda l'esempio di Keras qui sotto:
from keras.models import Sequential from keras.layers import Dense, Activation model = Sequential() model.add(Dense(64, activation='relu', input_dim=50)) #input shape of 50 model.add(Dense(28, activation='relu')) #input shape of 50 model.add(Dense(10, activation='softmax'))
Grazie all'API amichevole, possiamo facilmente comprendere il processo. Scrivere il codice con una funzione semplice e senza bisogno di impostare più parametri.
Grande supporto della comunità
Esistono molte comunità di intelligenza artificiale che utilizzano Keras per il loro framework di deep learning. Molti di loro pubblicano i propri codici e tutorial per il grande pubblico.
Avere più backend
Puoi scegliere Tensorflow, CNTK e Theano come backend con Keras. Puoi scegliere un backend diverso per progetti diversi a seconda delle tue esigenze. Ogni backend ha il suo vantaggio unico.
Distribuzione multipiattaforma e semplice del modello
Con una varietà di dispositivi e piattaforme supportati, puoi distribuire Keras su qualsiasi dispositivo come
- iOS con CoreML
- Android con Tensorflow Android,
- Browser Web con supporto .js
- Motore cloud
- Raspberry Pi
Supporto per più GPU
Puoi addestrare Keras su una singola GPU o utilizzare più GPU contemporaneamente. Perché Keras ha un supporto integrato per il parallelismo dei dati in modo da poter elaborare grandi volumi di dati e accelerare il tempo necessario per addestrarli.
Svantaggi di Keras
Impossibile gestire l'API di basso livello
Keras gestisce solo API di alto livello che vengono eseguite sopra altri framework o motori di backend come Tensorflow, Theano o CNTK. Quindi non è molto utile se vuoi creare il tuo assolutotract layer per i tuoi scopi di ricerca perché Keras ha già layer preconfigurati.
Installazione di Keras
In questa sezione esamineremo i vari metodi disponibili per installare Keras
Installazione diretta o ambiente virtuale
Qual è il migliore? Installazione diretta sul Python corrente o utilizzo di un ambiente virtuale? Suggerisco di utilizzare un ambiente virtuale se hai molti progetti. Vuoi sapere perché? Questo perché progetti diversi potrebbero utilizzare una versione diversa di una libreria Keras.
Ad esempio, ho un progetto che necessita Python 3.5 usando OpenCV 3.3 con il vecchio backend Keras-Theano ma nell'altro progetto devo usare Keras con l'ultima versione e un Tensorflow come backend con Python Supporto 3.6.6
Non vogliamo che le librerie Keras entrino in conflitto tra loro, giusto? Quindi utilizziamo un ambiente virtuale per localizzare il progetto con un tipo specifico di libreria oppure possiamo utilizzare un'altra piattaforma come il servizio cloud per eseguire i calcoli per noi come Amazon Servizio web.
Installazione di Keras su Amazon Servizio Web (AWS)
Amazon Web Service è una piattaforma che offre servizi e prodotti di cloud computing per ricercatori o per qualsiasi altro scopo. AWS noleggia il proprio hardware, rete, database, ecc. in modo che possiamo utilizzarlo direttamente da Internet. Uno dei servizi AWS popolari per scopi di deep learning è Amazon Servizio Machine Image Deep Learning o DL
Per istruzioni dettagliate su come utilizzare AWS, fare riferimento a questo lezione
Nota sull'AMI: avrai a disposizione la seguente AMI
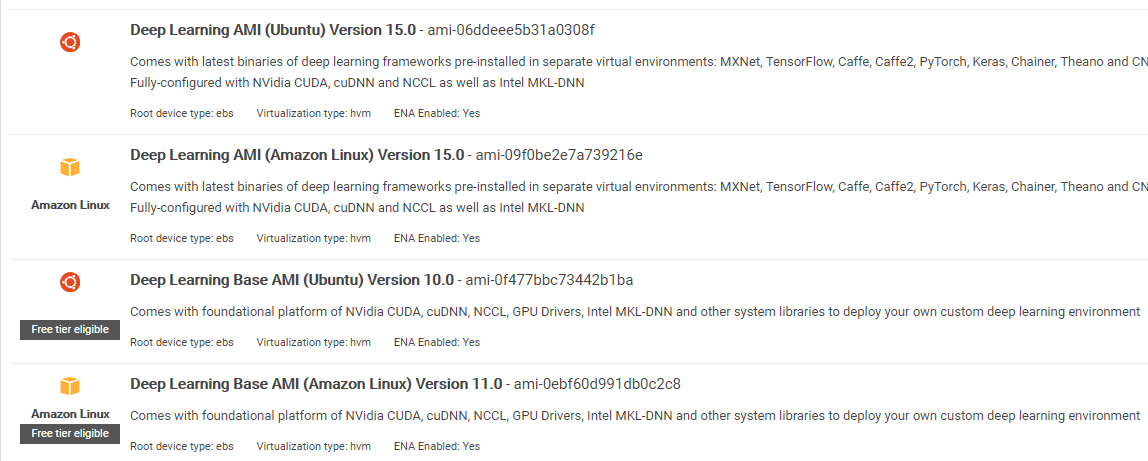
AWS Deep Learning AMI è un ambiente virtuale nel servizio AWS EC2 che aiuta ricercatori o professionisti a lavorare con il deep learning. DLAMI offre motori con CPU di piccole dimensioni fino a motori multi GPU ad alta potenza con CUDA e cuDNN preconfigurati e viene fornito con una varietà di framework di deep learning.
Se desideri utilizzarlo immediatamente, dovresti scegliere Deep Learning AMI perché viene preinstallato con i più diffusi framework di deep learning.
Ma se vuoi provare un framework di deep learning personalizzato per la ricerca, dovresti installare la Deep Learning Base AMI perché include librerie fondamentali come CUDA, cuDNN, driver GPU e altre librerie necessarie per l'esecuzione con il tuo ambiente di deep learning.
Come installare Keras su Amazon SageMaker
Amazon SageMaker è una piattaforma di deep learning che ti aiuta nella formazione e nell'implementazione della rete di deep learning con il miglior algoritmo.
Come principiante, questo è di gran lunga il metodo più semplice per utilizzare Keras. Di seguito è riportato un processo su come installare Keras su Amazon SageMaker:
Passaggio 1) Apri Amazon SageMaker
Nel primo passaggio, apri il file Amazon Sagemaker console e fare clic su Crea istanza notebook.

Passaggio 2) Inserisci i dettagli
- Inserisci il nome del tuo taccuino.
- Crea un ruolo IAM. Creerà un ruolo AMI Amazon Ruolo IAM nel formato di AmazonSageMaker-Executionrole-AAAAMMGG|HHmmSS.
- Infine, scegli Crea istanza notebook. Dopo alcuni istanti, Amazon Sagemaker avvia un'istanza notebook.

Note:: Se vuoi accedere alle risorse dal tuo VPC, imposta l'accesso diretto a Internet come abilitato. Altrimenti, questa istanza del notebook non avrà accesso a Internet, quindi è impossibile addestrare o ospitare modelli
Passaggio 3) Avvia l'istanza
Fare clic su Apri per avviare l'istanza

Passaggio 4) Inizia a programmare
In Jupyter, Fai clic su Nuovo> conda_tensorflow_p36 e sei pronto per codificare

Installa Keras su Linux
Per abilitare Keras con Tensorflow come motore backend, dobbiamo prima installare Tensorflow. Esegui questo comando per installare tensorflow con CPU (senza GPU)
pip install --upgrade tensorflow
se vuoi abilitare il supporto GPU per tensorflow puoi usare questo comando
pip install --upgrade tensorflow-gpu

facciamo il check-in Python per vedere se la nostra installazione ha avuto successo grazieping
user@user:~$ python Python 3.6.4 (default, Mar 20 2018, 11:10:20) [GCC 5.4.0 20160609] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import tensorflow >>>
se non viene visualizzato alcun messaggio di errore, il processo di installazione ha avuto esito positivo
Installa Keras
Dopo aver installato Tensorflow, iniziamo a installare Keras. Digita questo comando nel terminale
pip install keras
inizierà l'installazione di Keras e anche di tutte le sue dipendenze. Dovresti vedere qualcosa di simile a questo:

Ora abbiamo Keras installato nel nostro sistema!
verifica
Prima di iniziare a utilizzare Keras, dovremmo verificare se il nostro Keras utilizza Tensorflow come backend aprendo il file di configurazione:
gedit ~/.keras/keras.json
dovresti vedere qualcosa del genere
{
"floatx": "float32",
"epsilon": 1e-07,
"backend": "tensorflow",
"image_data_format": "channels_last"
}
come puoi vedere, il “backend” utilizza tensorflow. Significa che keras utilizza Tensorflow come backend come previsto
e ora eseguilo sul terminale di typing
user@user:~$ python3 Python 3.6.4 (default, Mar 20 2018, 11:10:20) [GCC 5.4.0 20160609] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import keras Using TensorFlow backend. >>>
Come installare Keras su Windows
Prima di installare tensorflow e Keras, dovremmo installare Python, pip e virtualenv. Se hai già installato queste librerie, dovresti procedere al passaggio successivo, altrimenti fai così:
Installazione Python 3 scaricandolo da questo link
Installa pip eseguendo questo
Installa virtualenv con questo comando
pip3 install –U pip virtualenv
Installazione Microsoft Visivo C++ Aggiornamento ridistribuibile 2015 del 3
- Vai al sito di download di Visual Studio https://www.microsoft.com/en-us/download/details.aspx?id=53587
- Seleziona Ridistribuibili e Strumenti di creazione
- Scaricare e installare il Microsoft Visivo C++ Aggiornamento ridistribuibile 2015 del 3
Quindi esegui questo script
pip3 install virtualenv
Configura l'ambiente virtuale
Viene utilizzato per isolare il sistema funzionante dal sistema principale.
virtualenv –-system-site-packages –p python3 ./venv
Attiva l'ambiente
.\venv\Scripts\activate
Dopo aver preparato l'ambiente, l'installazione di Tensorflow e Keras rimane la stessa di Linux. Successivamente in questo tutorial sull'apprendimento profondo con Keras, impareremo i fondamenti di Keras per l'apprendimento profondo.
Fondamenti di Keras per il deep learning
La struttura principale di Keras è il Modello che definisce il grafico completo di una rete. Puoi aggiungere più livelli a un modello esistente per creare un modello personalizzato necessario per il tuo progetto.
Ecco come creare un modello sequenziale e alcuni livelli comunemente utilizzati nel deep learning
1. Modello sequenziale
from keras.models import Sequential from keras.layers import Dense, Activation,Conv2D,MaxPooling2D,Flatten,Dropout model = Sequential()
2. Strato convoluzionale
Questo è un Keras Python esempio di strato convoluzionale come strato di input con la forma di input di 320x320x3, con 48 filtri di dimensione 3×3 e utilizza ReLU come funzione di attivazione.
input_shape=(320,320,3) #this is the input shape of an image 320x320x3 model.add(Conv2D(48, (3, 3), activation='relu', input_shape= input_shape))
un altro tipo è
model.add(Conv2D(48, (3, 3), activation='relu'))
3. maxPooling Strato
Per sottocampionare la rappresentazione dell'input, utilizzare MaxPool2d e specificare la dimensione del kernel
model.add(MaxPooling2D(pool_size=(2, 2)))
4. Strato denso
aggiungendo un livello completamente connesso specificando semplicemente la dimensione di output
model.add(Dense(256, activation='relu'))
5. Livello di abbandono
Aggiunta di un livello di esclusione con una probabilità del 50%.
model.add(Dropout(0.5))
Compilazione, formazione e valutazione
Dopo aver definito il nostro modello, iniziamo ad addestrarli. È necessario compilare prima la rete con la funzione di perdita e la funzione di ottimizzazione. Ciò consentirà alla rete di modificare i pesi e ridurre al minimo la perdita.
model.compile(loss='mean_squared_error', optimizer='adam')
Ora, per iniziare l'addestramento, utilizzare fit per alimentare i dati di addestramento e convalida al modello. Ciò ti consentirà di addestrare la rete in batch e impostare le epoche.
model.fit(X_train, X_train, batch_size=32, epochs=10, validation_data=(x_val, y_val))
Il nostro passaggio finale è valutare il modello con i dati di test.
score = model.evaluate(x_test, y_test, batch_size=32)
Proviamo a utilizzare una semplice regressione lineare
import keras from keras.models import Sequential from keras.layers import Dense, Activation import numpy as np import matplotlib.pyplot as plt x = data = np.linspace(1,2,200) y = x*4 + np.random.randn(*x.shape) * 0.3 model = Sequential() model.add(Dense(1, input_dim=1, activation='linear')) model.compile(optimizer='sgd', loss='mse', metrics=['mse']) weights = model.layers[0].get_weights() w_init = weights[0][0][0] b_init = weights[1][0] print('Linear regression model is initialized with weights w: %.2f, b: %.2f' % (w_init, b_init)) model.fit(x,y, batch_size=1, epochs=30, shuffle=False) weights = model.layers[0].get_weights() w_final = weights[0][0][0] b_final = weights[1][0] print('Linear regression model is trained to have weight w: %.2f, b: %.2f' % (w_final, b_final)) predict = model.predict(data) plt.plot(data, predict, 'b', data , y, 'k.') plt.show()
Dopo aver addestrato i dati, l'output dovrebbe assomigliare a questo
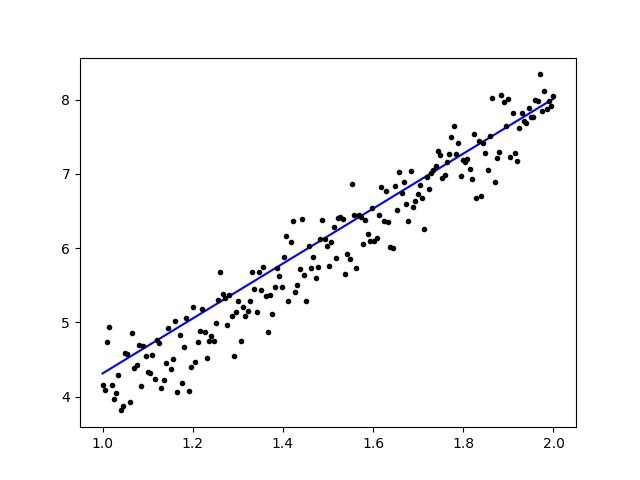
con il peso iniziale
Linear regression model is initialized with weights w: 0.37, b: 0.00
e peso finale
Linear regression model is trained to have weight w: 3.70, b: 0.61
Ottimizzazione dei modelli preaddestrati in Keras e come utilizzarli
Perché utilizziamo i modelli Fine Tune e quando lo utilizziamo
La messa a punto è un compito per modificare un modello pre-addestrato in modo tale che i parametri si adattino al nuovo modello. Quando vogliamo allenarci da zero su un nuovo modello, abbiamo bisogno di una grande quantità di dati, in modo che la rete possa trovare tutti i parametri. Ma in questo caso utilizzeremo un modello pre-addestrato in modo che i parametri siano già appresi e abbiano un peso.
Ad esempio, se vogliamo addestrare il nostro modello Keras a risolvere un problema di classificazione ma disponiamo solo di una piccola quantità di dati, possiamo risolverlo utilizzando un Trasferimento di apprendimento + Metodo di messa a punto.
Utilizzando una rete e pesi pre-addestrati non è necessario addestrare l'intera rete. Dobbiamo solo addestrare l'ultimo livello utilizzato per risolvere il nostro compito come lo chiamiamo metodo di messa a punto.
Preparazione del modello di rete
Per il modello pre-addestrato, possiamo caricare una varietà di modelli che Keras ha già nella sua libreria come:
- VGG16
- InizioV3
- RESNET
- Rete Mobile
- xception
- InceptionResNetV2
Ma in questo processo utilizzeremo il modello di rete VGG16 e imageNet come peso per il modello. Metteremo a punto una rete per classificare 8 diversi tipi di classi utilizzando Immagini da Set di dati delle immagini naturali di Kaggle
Architettura del modello VGG16

Caricamento dei nostri dati nel bucket AWS S3
Per il nostro processo di formazione, utilizzeremo un'immagine di immagini naturali di 8 classi diverse come aeroplani, auto, gatto, cane, fiore, frutta, moto e persona. Per prima cosa dobbiamo caricare i nostri dati su Amazon Benna S3.
Amazon Secchio S3
Passo 1) Dopo aver effettuato l'accesso al tuo account S3, creiamo un bucket timbrando creare benna

Passo 2) Ora scegli un nome per il bucket e la tua regione in base al tuo account. Assicurati che il nome del bucket sia disponibile. Dopo quel clic Creare.
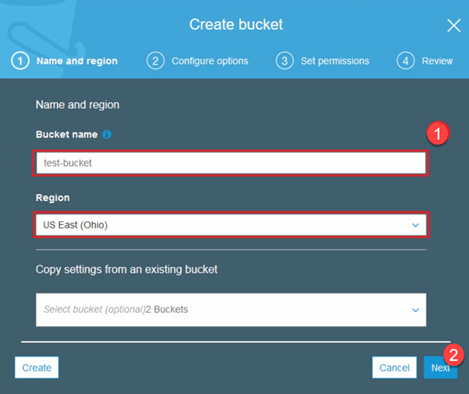
Passo 3) Come puoi vedere, il tuo Bucket è pronto per l'uso. Ma come puoi vedere, l'accesso non è pubblico, è un bene per te se vuoi mantenerlo privato per te stesso. Puoi modificare questo bucket per l'accesso pubblico nelle Proprietà del bucket

Passo 4) Ora inizi a caricare i dati di allenamento nel tuo bucket. Qui caricherò il file tar.gz che consiste di immagini per il processo di formazione e test.

Passo 5) Ora fai clic sul tuo file e copia il file vetro in modo che possiamo scaricarlo.

Preparazione dei dati
Dobbiamo generare i nostri dati di addestramento utilizzando Keras ImageDataGenerator.
Per prima cosa devi scaricare utilizzando wget con il collegamento al tuo file da S3 Bucket.
!wget https://s3.us-east-2.amazonaws.com/naturalimages02/images.tar.gz
!tar -xzf images.tar.gz
Dopo aver scaricato i dati, iniziamo il processo di formazione.
from keras.preprocessing.image import ImageDataGenerator import numpy as np import matplotlib.pyplot as plt train_path = 'images/train/' test_path = 'images/test/' batch_size = 16 image_size = 224 num_class = 8 train_datagen = ImageDataGenerator(validation_split=0.3, shear_range=0.2, zoom_range=0.2, horizontal_flip=True) train_generator = train_datagen.flow_from_directory( directory=train_path, target_size=(image_size,image_size), batch_size=batch_size, class_mode='categorical', color_mode='rgb', shuffle=True)
I dati immagineGenerator creerà un dato X_training da una directory. La sottodirectory in quella directory verrà utilizzata come classe per ciascun oggetto. L'immagine verrà caricata con la modalità colore RGB, con la modalità di classe categoriale per i dati Y_training, con una dimensione batch di 16. Infine, mescola i dati.
Vediamo le nostre immagini in modo casuale tracciandole con matplotlib
x_batch, y_batch = train_generator.next() fig=plt.figure() columns = 4 rows = 4 for i in range(1, columns*rows): num = np.random.randint(batch_size) image = x_batch[num].astype(np.int) fig.add_subplot(rows, columns, i) plt.imshow(image) plt.show()

Successivamente creiamo il nostro modello di rete da VGG16 con il peso pre-addestrato imageNet. Congeleremo questi livelli in modo che non siano addestrabili per aiutarci a ridurre il tempo di calcolo.
Creazione del nostro modello da VGG16
import keras from keras.models import Model, load_model from keras.layers import Activation, Dropout, Flatten, Dense from keras.preprocessing.image import ImageDataGenerator from keras.applications.vgg16 import VGG16 #Load the VGG model base_model = VGG16(weights='imagenet', include_top=False, input_shape=(image_size, image_size, 3)) print(base_model.summary()) # Freeze the layers for layer in base_model.layers: layer.trainable = False # # Create the model model = keras.models.Sequential() # # Add the vgg convolutional base model model.add(base_model) # # Add new layers model.add(Flatten()) model.add(Dense(1024, activation='relu')) model.add(Dense(1024, activation='relu')) model.add(Dense(num_class, activation='softmax')) # # Show a summary of the model. Check the number of trainable parameters print(model.summary())
Come puoi vedere qui sotto, il riepilogo del nostro modello di rete. Da un input da VGG16 Layers, aggiungiamo 2 Fully Connected Layer che esplorerannotract 1024 caratteristiche e un livello di output che calcolerà le 8 classi con l'attivazione softmax.
Layer (type) Output Shape Param # ================================================================= vgg16 (Model) (None, 7, 7, 512) 14714688 _________________________________________________________________ flatten_1 (Flatten) (None, 25088) 0 _________________________________________________________________ dense_1 (Dense) (None, 1024) 25691136 _________________________________________________________________ dense_2 (Dense) (None, 1024) 1049600 _________________________________________________________________ dense_3 (Dense) (None, 8) 8200 ================================================================= Total params: 41,463,624 Trainable params: 26,748,936 Non-trainable params: 14,714,688
Formazione
# # Compile the model from keras.optimizers import SGD model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=1e-3), metrics=['accuracy']) # # Start the training process # model.fit(x_train, y_train, validation_split=0.30, batch_size=32, epochs=50, verbose=2) # # #save the model # model.save('catdog.h5') history = model.fit_generator( train_generator, steps_per_epoch=train_generator.n/batch_size, epochs=10) model.save('fine_tune.h5') # summarize history for accuracy import matplotlib.pyplot as plt plt.plot(history.history['loss']) plt.title('loss') plt.ylabel('loss') plt.xlabel('epoch') plt.legend(['loss'], loc='upper left') plt.show()
Risultati
Epoch 1/10 432/431 [==============================] - 53s 123ms/step - loss: 0.5524 - acc: 0.9474 Epoch 2/10 432/431 [==============================] - 52s 119ms/step - loss: 0.1571 - acc: 0.9831 Epoch 3/10 432/431 [==============================] - 51s 119ms/step - loss: 0.1087 - acc: 0.9871 Epoch 4/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0624 - acc: 0.9926 Epoch 5/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0591 - acc: 0.9938 Epoch 6/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0498 - acc: 0.9936 Epoch 7/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0403 - acc: 0.9958 Epoch 8/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0248 - acc: 0.9959 Epoch 9/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0466 - acc: 0.9942 Epoch 10/10 432/431 [==============================] - 52s 120ms/step - loss: 0.0338 - acc: 0.9947

Come puoi vedere, le nostre perdite sono diminuite in modo significativo e la precisione è quasi del 100%. Per testare il nostro modello, abbiamo selezionato immagini casuali su Internet e le abbiamo inserite nella cartella di test con una classe diversa da testare
Testare il nostro modello
model = load_model('fine_tune.h5') test_datagen = ImageDataGenerator() train_generator = train_datagen.flow_from_directory( directory=train_path, target_size=(image_size,image_size), batch_size=batch_size, class_mode='categorical', color_mode='rgb', shuffle=True) test_generator = test_datagen.flow_from_directory( directory=test_path, target_size=(image_size, image_size), color_mode='rgb', shuffle=False, class_mode='categorical', batch_size=1) filenames = test_generator.filenames nb_samples = len(filenames) fig=plt.figure() columns = 4 rows = 4 for i in range(1, columns*rows -1): x_batch, y_batch = test_generator.next() name = model.predict(x_batch) name = np.argmax(name, axis=-1) true_name = y_batch true_name = np.argmax(true_name, axis=-1) label_map = (test_generator.class_indices) label_map = dict((v,k) for k,v in label_map.items()) #flip k,v predictions = [label_map[k] for k in name] true_value = [label_map[k] for k in true_name] image = x_batch[0].astype(np.int) fig.add_subplot(rows, columns, i) plt.title(str(predictions[0]) + ':' + str(true_value[0])) plt.imshow(image) plt.show()
E il nostro test è quello indicato di seguito! Solo 1 immagine è prevista sbagliata da un test di 14 immagini!

Rete neurale di riconoscimento facciale con Keras
Perché abbiamo bisogno del riconoscimento
Abbiamo bisogno del Riconoscimento per renderci più facile riconoscere o identificare il volto di una persona, il tipo di oggetti, l'età stimata di una persona dal suo volto o persino conoscere le espressioni facciali di quella persona.

Forse ti rendi conto che ogni volta che provi a contrassegnare il volto di un tuo amico in una foto, la funzione di Facebook lo ha fatto per te, ovvero contrassegnare il volto del tuo amico senza che tu debba prima contrassegnarlo. Si tratta del riconoscimento facciale applicato da Facebook per renderci più semplice taggare gli amici.
Quindi, come funziona? Ogni volta che segniamo il volto di un nostro amico, l'intelligenza artificiale di Facebook lo imparerà e proverà a prevederlo finché non otterrà il risultato giusto. Lo stesso sistema che utilizzeremo per effettuare il nostro Face Recognition. Iniziamo a creare il nostro riconoscimento facciale utilizzando il Deep Learning
Modello di rete
Utilizzeremo un modello di rete VGG16 ma con peso VGGFace.
Architettura del modello VGG16

Cos'è VGGFace? è l'implementazione Keras di Deep Face Recognition introdotta da Parkhi, Omkar M. et al. "Deep Face Recognition." BMVC (2015). Il framework utilizza VGG16 come architettura di rete.
Puoi scaricare VGGFace da github
from keras.applications.vgg16 import VGG16 from keras_vggface.vggface import VGGFace face_model = VGGFace(model='vgg16', weights='vggface', input_shape=(224,224,3)) face_model.summary()
Come puoi vedere il riepilogo della rete
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ conv1_1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ conv1_2 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ pool1 (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ conv2_1 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ conv2_2 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ pool2 (MaxPooling2D) (None, 56, 56, 128) 0 _________________________________________________________________ conv3_1 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ conv3_2 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ conv3_3 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ pool3 (MaxPooling2D) (None, 28, 28, 256) 0 _________________________________________________________________ conv4_1 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ conv4_2 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ conv4_3 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ pool4 (MaxPooling2D) (None, 14, 14, 512) 0 _________________________________________________________________ conv5_1 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ conv5_2 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ conv5_3 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ pool5 (MaxPooling2D) (None, 7, 7, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 25088) 0 _________________________________________________________________ fc6 (Dense) (None, 4096) 102764544 _________________________________________________________________ fc6/relu (Activation) (None, 4096) 0 _________________________________________________________________ fc7 (Dense) (None, 4096) 16781312 _________________________________________________________________ fc7/relu (Activation) (None, 4096) 0 _________________________________________________________________ fc8 (Dense) (None, 2622) 10742334 _________________________________________________________________ fc8/softmax (Activation) (None, 2622) 0 ================================================================= Total params: 145,002,878 Trainable params: 145,002,878 Non-trainable params: 0 _________________________________________________________________ Traceback (most recent call last):
faremo un Trasferimento di apprendimento + Ottimizzazione per rendere l'addestramento più veloce con piccoli set di dati. Innanzitutto, congeleremo gli strati di base in modo che gli strati non siano addestrabili.
for layer in face_model.layers: layer.trainable = False
quindi aggiungiamo il nostro livello per riconoscere i nostri volti di prova. Aggiungeremo 2 livelli completamente connessi e un livello di output con 5 persone da rilevare.
from keras.models import Model, Sequential from keras.layers import Input, Convolution2D, ZeroPadding2D, MaxPooling2D, Flatten, Dense, Dropout, Activation person_count = 5 last_layer = face_model.get_layer('pool5').output x = Flatten(name='flatten')(last_layer) x = Dense(1024, activation='relu', name='fc6')(x) x = Dense(1024, activation='relu', name='fc7')(x) out = Dense(person_count, activation='softmax', name='fc8')(x) custom_face = Model(face_model.input, out)
Vediamo il riepilogo della nostra rete
Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ conv1_1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ conv1_2 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ pool1 (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ conv2_1 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ conv2_2 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ pool2 (MaxPooling2D) (None, 56, 56, 128) 0 _________________________________________________________________ conv3_1 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ conv3_2 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ conv3_3 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ pool3 (MaxPooling2D) (None, 28, 28, 256) 0 _________________________________________________________________ conv4_1 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ conv4_2 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ conv4_3 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ pool4 (MaxPooling2D) (None, 14, 14, 512) 0 _________________________________________________________________ conv5_1 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ conv5_2 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ conv5_3 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ pool5 (MaxPooling2D) (None, 7, 7, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 25088) 0 _________________________________________________________________ fc6 (Dense) (None, 1024) 25691136 _________________________________________________________________ fc7 (Dense) (None, 1024) 1049600 _________________________________________________________________ fc8 (Dense) (None, 5) 5125 ================================================================= Total params: 41,460,549 Trainable params: 26,745,861 Non-trainable params: 14,714,688
Come puoi vedere sopra, dopo il layer pool5, verrà appiattito in un unico vettore di feature che verrà utilizzato dal layer denso per il riconoscimento finale.
Preparare i nostri volti
Adesso prepariamo i nostri volti. Ho creato una directory composta da 5 personaggi famosi
- Jack Ma
- Jason Statham
- Johnny Depp
- Robert Downey Jr.
- Rowan Atkinson
Ogni cartella contiene 10 immagini, per ogni processo formativo e valutativo. Si tratta di una quantità di dati molto piccola, ma questa è la sfida, giusto?
Utilizzeremo l'aiuto dello strumento Keras per aiutarci a preparare i dati. Questa funzione eseguirà l'iterazione nella cartella del set di dati e quindi la preparerà in modo che possa essere utilizzata nella formazione.
from keras.preprocessing.image import ImageDataGenerator batch_size = 5 train_path = 'data/' eval_path = 'eval/' train_datagen = ImageDataGenerator(rescale=1./255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True) valid_datagen = ImageDataGenerator(rescale=1./255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True) train_generator = train_datagen.flow_from_directory( train_path, target_size=(image_size,image_size), batch_size=batch_size, class_mode='sparse', color_mode='rgb') valid_generator = valid_datagen.flow_from_directory( directory=eval_path, target_size=(224, 224), color_mode='rgb', batch_size=batch_size, class_mode='sparse', shuffle=True, )
Formazione del nostro modello
Iniziamo il nostro processo di formazione compilando la nostra rete con funzione di perdita e ottimizzatore. Qui utilizziamo sparse_categorical_crossentropy come funzione di perdita, con l'aiuto di SGD come ottimizzatore dell'apprendimento.
from keras.optimizers import SGD custom_face.compile(loss='sparse_categorical_crossentropy', optimizer=SGD(lr=1e-4, momentum=0.9), metrics=['accuracy']) history = custom_face.fit_generator( train_generator, validation_data=valid_generator, steps_per_epoch=49/batch_size, validation_steps=valid_generator.n, epochs=50) custom_face.evaluate_generator(generator=valid_generator) custom_face.save('vgg_face.h5') Epoch 25/50 10/9 [==============================] - 60s 6s/step - loss: 1.4882 - acc: 0.8998 - val_loss: 1.5659 - val_acc: 0.5851 Epoch 26/50 10/9 [==============================] - 59s 6s/step - loss: 1.4882 - acc: 0.8998 - val_loss: 1.5638 - val_acc: 0.5809 Epoch 27/50 10/9 [==============================] - 60s 6s/step - loss: 1.4779 - acc: 0.8597 - val_loss: 1.5613 - val_acc: 0.5477 Epoch 28/50 10/9 [==============================] - 60s 6s/step - loss: 1.4755 - acc: 0.9199 - val_loss: 1.5576 - val_acc: 0.5809 Epoch 29/50 10/9 [==============================] - 60s 6s/step - loss: 1.4794 - acc: 0.9153 - val_loss: 1.5531 - val_acc: 0.5892 Epoch 30/50 10/9 [==============================] - 60s 6s/step - loss: 1.4714 - acc: 0.8953 - val_loss: 1.5510 - val_acc: 0.6017 Epoch 31/50 10/9 [==============================] - 60s 6s/step - loss: 1.4552 - acc: 0.9199 - val_loss: 1.5509 - val_acc: 0.5809 Epoch 32/50 10/9 [==============================] - 60s 6s/step - loss: 1.4504 - acc: 0.9199 - val_loss: 1.5492 - val_acc: 0.5975 Epoch 33/50 10/9 [==============================] - 60s 6s/step - loss: 1.4497 - acc: 0.8998 - val_loss: 1.5490 - val_acc: 0.5851 Epoch 34/50 10/9 [==============================] - 60s 6s/step - loss: 1.4453 - acc: 0.9399 - val_loss: 1.5529 - val_acc: 0.5643 Epoch 35/50 10/9 [==============================] - 60s 6s/step - loss: 1.4399 - acc: 0.9599 - val_loss: 1.5451 - val_acc: 0.5768 Epoch 36/50 10/9 [==============================] - 60s 6s/step - loss: 1.4373 - acc: 0.8998 - val_loss: 1.5424 - val_acc: 0.5768 Epoch 37/50 10/9 [==============================] - 60s 6s/step - loss: 1.4231 - acc: 0.9199 - val_loss: 1.5389 - val_acc: 0.6183 Epoch 38/50 10/9 [==============================] - 59s 6s/step - loss: 1.4247 - acc: 0.9199 - val_loss: 1.5372 - val_acc: 0.5934 Epoch 39/50 10/9 [==============================] - 60s 6s/step - loss: 1.4153 - acc: 0.9399 - val_loss: 1.5406 - val_acc: 0.5560 Epoch 40/50 10/9 [==============================] - 60s 6s/step - loss: 1.4074 - acc: 0.9800 - val_loss: 1.5327 - val_acc: 0.6224 Epoch 41/50 10/9 [==============================] - 60s 6s/step - loss: 1.4023 - acc: 0.9800 - val_loss: 1.5305 - val_acc: 0.6100 Epoch 42/50 10/9 [==============================] - 59s 6s/step - loss: 1.3938 - acc: 0.9800 - val_loss: 1.5269 - val_acc: 0.5975 Epoch 43/50 10/9 [==============================] - 60s 6s/step - loss: 1.3897 - acc: 0.9599 - val_loss: 1.5234 - val_acc: 0.6432 Epoch 44/50 10/9 [==============================] - 60s 6s/step - loss: 1.3828 - acc: 0.9800 - val_loss: 1.5210 - val_acc: 0.6556 Epoch 45/50 10/9 [==============================] - 59s 6s/step - loss: 1.3848 - acc: 0.9599 - val_loss: 1.5234 - val_acc: 0.5975 Epoch 46/50 10/9 [==============================] - 60s 6s/step - loss: 1.3716 - acc: 0.9800 - val_loss: 1.5216 - val_acc: 0.6432 Epoch 47/50 10/9 [==============================] - 60s 6s/step - loss: 1.3721 - acc: 0.9800 - val_loss: 1.5195 - val_acc: 0.6266 Epoch 48/50 10/9 [==============================] - 60s 6s/step - loss: 1.3622 - acc: 0.9599 - val_loss: 1.5108 - val_acc: 0.6141 Epoch 49/50 10/9 [==============================] - 60s 6s/step - loss: 1.3452 - acc: 0.9399 - val_loss: 1.5140 - val_acc: 0.6432 Epoch 50/50 10/9 [==============================] - 60s 6s/step - loss: 1.3387 - acc: 0.9599 - val_loss: 1.5100 - val_acc: 0.6266
Come puoi vedere, la nostra precisione di convalida arriva fino al 64%, questo è un buon risultato per una piccola quantità di dati di addestramento. Possiamo migliorarlo aggiungendo più livelli o aggiungendo più immagini di addestramento in modo che il nostro modello possa apprendere di più sui volti e ottenere una maggiore precisione.
Mettiamo alla prova il nostro modello con un'immagine di prova

from keras.models import load_model from keras.preprocessing.image import load_img, save_img, img_to_array from keras_vggface.utils import preprocess_input test_img = image.load_img('test.jpg', target_size=(224, 224)) img_test = image.img_to_array(test_img) img_test = np.expand_dims(img_test, axis=0) img_test = utils.preprocess_input(img_test) predictions = model.predict(img_test) predicted_class=np.argmax(predictions,axis=1) labels = (train_generator.class_indices) labels = dict((v,k) for k,v in labels.items()) predictions = [labels[k] for k in predicted_class] print(predictions) ['RobertDJr']
utilizzando l'immagine di Robert Downey Jr. come immagine di prova, si dimostra che il volto previsto è vero!
Pronostico utilizzando Live Cam!
Che ne dici se mettiamo alla prova la nostra abilità nell'implementarlo con un input da una webcam? Utilizzando OpenCV con Haar Face cascade per trovare il nostro volto e con l'aiuto del nostro modello di rete, possiamo riconoscere la persona.
Il primo passo è preparare il viso tuo e del tuo amico. Più dati abbiamo, migliore sarà il risultato!
Prepara e addestra la tua rete come nel passaggio precedente, una volta completato l'addestramento, aggiungi questa riga per ottenere l'immagine di input dalla cam
#Load trained model from keras.models import load_model from keras_vggface import utils import cv2 image_size = 224 device_id = 0 #camera_device id model = load_model('my faces.h5') #make labels according to your dataset folder labels = dict(fisrtname=0,secondname=1) #and so on print(labels) cascade_classifier = cv2.CascadeClassifier('haarcascade_frontalface_default.xml') camera = cv2.VideoCapture(device_id) while camera.isOpened(): ok, cam_frame = camera.read() if not ok: break gray_img=cv2.cvtColor(cam_frame, cv2.COLOR_BGR2GRAY) faces= cascade_classifier.detectMultiScale(gray_img, minNeighbors=5) for (x,y,w,h) in faces: cv2.rectangle(cam_frame,(x,y),(x+w,y+h),(255,255,0),2) roi_color = cam_frame [y:y+h, x:x+w] roi color = cv2.cvtColor(roi_color, cv2.COLOR_BGR2RGB) roi_color = cv2.resize(roi_color, (image_size, image_size)) image = roi_color.astype(np.float32, copy=False) image = np.expand_dims(image, axis=0) image = preprocess_input(image, version=1) # or version=2 preds = model.predict(image) predicted_class=np.argmax(preds,axis=1) labels = dict((v,k) for k,v in labels.items()) name = [labels[k] for k in predicted_class] cv2.putText(cam_frame,str(name), (x + 10, y + 10), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,0,255), 2) cv2.imshow('video image', cam_frame) key = cv2.waitKey(30) if key == 27: # press 'ESC' to quit break camera.release() cv2.destroyAllWindows()
Qual è il migliore? Keras o Tensorflow
Keras offre semplicità durante la scrittura della sceneggiatura. Possiamo iniziare a scrivere e capire direttamente con Keras poiché non è troppo difficile da capire. È più user-friendly e facile da implementare, non è necessario creare molte variabili per eseguire il modello. Pertanto, non è necessario comprendere ogni dettaglio del processo di backend.
D'altra parte, Tensorflow sono le operazioni di basso livello che offrono flessibilità e operazioni avanzate se si desidera creare un grafico o un modello computazionale arbitrario. Tensorflow può anche visualizzare il processo con l'aiuto di Scheda Tensor e uno strumento di debug specializzato.
Quindi, se vuoi iniziare a lavorare con il deep learning con non troppa complessità, usa Keras. Perché Keras offre semplicità e facilità d'uso e di implementazione rispetto a Tensorflow. Ma se vuoi scrivere il tuo algoritmo in un progetto o una ricerca di deep learning, dovresti usare Tensorflow.