Hadoop और Mapreduce उदाहरण: पहला प्रोग्राम बनाएँ Java
इस ट्यूटोरियल में, आप MapReduce उदाहरणों के साथ Hadoop का उपयोग करना सीखेंगे। उपयोग किया गया इनपुट डेटा है SalesJan2009.csvइसमें बिक्री से संबंधित जानकारी जैसे उत्पाद का नाम, मूल्य, भुगतान मोड, शहर, ग्राहक का देश आदि शामिल हैं। इसका लक्ष्य है प्रत्येक देश में बेचे गए उत्पादों की संख्या का पता लगाएं।
पहला Hadoop MapReduce प्रोग्राम
अब इसमें मैपरिड्यूस ट्यूटोरियल, हम अपना पहला निर्माण करेंगे Java मैपरिड्यूस कार्यक्रम:
सुनिश्चित करें कि आपके पास Hadoop इंस्टॉल है। वास्तविक प्रक्रिया शुरू करने से पहले, उपयोगकर्ता को 'hduser' में बदलें (Hadoop कॉन्फ़िगरेशन के दौरान उपयोग की गई आईडी, आप अपने Hadoop प्रोग्रामिंग कॉन्फ़िगरेशन के दौरान उपयोग की गई उपयोगकर्ता आईडी पर स्विच कर सकते हैं)।
su - hduser_

चरण 1)
नाम से एक नई निर्देशिका बनाएं मैपरिड्यूसट्यूटोरियल जैसा कि नीचे दिए गए MapReduce उदाहरण में दिखाया गया है
sudo mkdir MapReduceTutorial
![]()
अनुमति दें
sudo chmod -R 777 MapReduceTutorial
![]()
SalesMapper.जावा
package SalesCountry;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
public class SalesMapper extends MapReduceBase implements Mapper <LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
public void map(LongWritable key, Text value, OutputCollector <Text, IntWritable> output, Reporter reporter) throws IOException {
String valueString = value.toString();
String[] SingleCountryData = valueString.split(",");
output.collect(new Text(SingleCountryData[7]), one);
}
}
SalesCountryReducer.java
package SalesCountry;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
public class SalesCountryReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text t_key, Iterator<IntWritable> values, OutputCollector<Text,IntWritable> output, Reporter reporter) throws IOException {
Text key = t_key;
int frequencyForCountry = 0;
while (values.hasNext()) {
// replace type of value with the actual type of our value
IntWritable value = (IntWritable) values.next();
frequencyForCountry += value.get();
}
output.collect(key, new IntWritable(frequencyForCountry));
}
}
SalesCountryDriver.java
package SalesCountry;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
public class SalesCountryDriver {
public static void main(String[] args) {
JobClient my_client = new JobClient();
// Create a configuration object for the job
JobConf job_conf = new JobConf(SalesCountryDriver.class);
// Set a name of the Job
job_conf.setJobName("SalePerCountry");
// Specify data type of output key and value
job_conf.setOutputKeyClass(Text.class);
job_conf.setOutputValueClass(IntWritable.class);
// Specify names of Mapper and Reducer Class
job_conf.setMapperClass(SalesCountry.SalesMapper.class);
job_conf.setReducerClass(SalesCountry.SalesCountryReducer.class);
// Specify formats of the data type of Input and output
job_conf.setInputFormat(TextInputFormat.class);
job_conf.setOutputFormat(TextOutputFormat.class);
// Set input and output directories using command line arguments,
//arg[0] = name of input directory on HDFS, and arg[1] = name of output directory to be created to store the output file.
FileInputFormat.setInputPaths(job_conf, new Path(args[0]));
FileOutputFormat.setOutputPath(job_conf, new Path(args[1]));
my_client.setConf(job_conf);
try {
// Run the job
JobClient.runJob(job_conf);
} catch (Exception e) {
e.printStackTrace();
}
}
}
इन सभी फ़ाइलों की फ़ाइल अनुमतियाँ जाँचें

और यदि 'पढ़ने' की अनुमति नहीं है तो उसे प्रदान करें-
![]()
चरण 2)
नीचे दिए गए Hadoop उदाहरण में दिखाए अनुसार क्लासपथ निर्यात करें
export CLASSPATH="$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.2.0.jar:$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.2.0.jar:$HADOOP_HOME/share/hadoop/common/hadoop-common-2.2.0.jar:~/MapReduceTutorial/SalesCountry/*:$HADOOP_HOME/lib/*"

चरण 3)
संकलन करना Java फ़ाइलें (ये फ़ाइलें निर्देशिका में मौजूद हैं फाइनल-मैपरिड्यूसहैंड्सऑन) इसकी क्लास फाइलें पैकेज डायरेक्टरी में रखी जाएंगी
javac -d . SalesMapper.java SalesCountryReducer.java SalesCountryDriver.java

इस चेतावनी को सुरक्षित रूप से नजरअंदाज किया जा सकता है।
यह संकलन जावा स्रोत फ़ाइल में निर्दिष्ट पैकेज नाम के साथ नामित वर्तमान निर्देशिका में एक निर्देशिका बनाएगा (यानी बिक्रीदेश हमारे मामले में) और इसमें सभी संकलित क्लास फ़ाइलें डाल दीजिये।

चरण 4)
एक नई फाइल बनाएं मैनिफ़ेस्ट.txt
sudo gedit Manifest.txt
इसमें निम्न पंक्तियाँ जोड़ें,
Main-Class: SalesCountry.SalesCountryDriver

SalesCountry.SalesCountryDriver मुख्य वर्ग का नाम है। कृपया ध्यान दें कि आपको इस पंक्ति के अंत में एंटर कुंजी दबानी होगी।
चरण 5)
एक Jar फ़ाइल बनाएँ
jar cfm ProductSalePerCountry.jar Manifest.txt SalesCountry/*.class
![]()
जाँच करें कि jar फ़ाइल बनाई गई है

चरण 6)
Hadoop प्रारंभ करें
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
चरण 7)
फ़ाइल कॉपी करें SalesJan2009.csv में ~/इनपुटमैपरिड्यूस
अब कॉपी करने के लिए नीचे दिए गए कमांड का उपयोग करें ~/इनपुटमैपरिड्यूस एचडीएफएस के लिए.
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal ~/inputMapReduce /

हम इस चेतावनी को सुरक्षित रूप से नजरअंदाज कर सकते हैं।
सत्यापित करें कि फ़ाइल वास्तव में कॉपी की गई है या नहीं.
$HADOOP_HOME/bin/hdfs dfs -ls /inputMapReduce

चरण 8)
MapReduce कार्य चलाएँ
$HADOOP_HOME/bin/hadoop jar ProductSalePerCountry.jar /inputMapReduce /mapreduce_output_sales

इससे mapreduce_output_sales नाम से एक आउटपुट निर्देशिका बनेगी एचडीएफएसइस निर्देशिका की सामग्री एक फ़ाइल होगी जिसमें प्रति देश उत्पाद बिक्री शामिल होगी।
चरण 9)
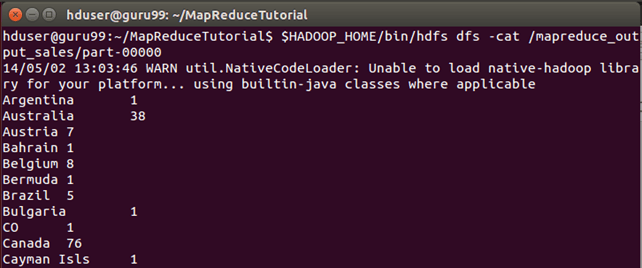
परिणाम कमांड इंटरफ़ेस के माध्यम से देखा जा सकता है,
$HADOOP_HOME/bin/hdfs dfs -cat /mapreduce_output_sales/part-00000
परिणाम वेब इंटरफेस के माध्यम से भी देखे जा सकते हैं-
वेब ब्राउज़र में r खोलें.

अब चयन 'फ़ाइल सिस्टम ब्राउज़ करें' और नेविगेट करें /mapreduce_output_sales

प्रारंभिक भाग-आर-00000

सेल्समैपर क्लास का स्पष्टीकरण
इस अनुभाग में हम इसके कार्यान्वयन को समझेंगे सेल्समैपर वर्ग.
1. हम अपनी क्लास के लिए पैकेज का नाम निर्दिष्ट करके शुरू करते हैं। बिक्रीदेश हमारे पैकेज का नाम है। कृपया ध्यान दें कि संकलन का आउटपुट, सेल्समैपर.क्लास इस पैकेज नाम से नामित निर्देशिका में जाएगा: बिक्रीदेश.
इसके बाद, हम लाइब्रेरी पैकेज आयात करते हैं।
नीचे दिया गया स्नैपशॉट इसका कार्यान्वयन दर्शाता है सेल्समैपर कक्षा-

नमूना Code स्पष्टीकरण:
1. सेल्समैपर क्लास परिभाषा-
सार्वजनिक वर्ग SalesMapper MapReduceBase का विस्तार करता है और Mapper को लागू करता है {
प्रत्येक मैपर वर्ग को विस्तारित किया जाना चाहिए मैपरिड्यूसबेस वर्ग और इसे लागू करना होगा नक्शाकार interface.
2. 'मैप' फ़ंक्शन को परिभाषित करना-
public void map(LongWritable key,
Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException
मैपर वर्ग का मुख्य भाग है 'मानचित्र()' विधि जो चार तर्क स्वीकार करती है.
हर कॉल पर 'मानचित्र()' विधि, एक मौलिक मूल्य जोड़ा ('चाबी' और 'कीमत' इस कोड में) पारित किया गया है।
'मानचित्र()' विधि इनपुट टेक्स्ट को विभाजित करके शुरू होती है जिसे एक तर्क के रूप में प्राप्त किया जाता है। यह इन पंक्तियों को शब्दों में विभाजित करने के लिए टोकनाइज़र का उपयोग करता है।
String valueString = value.toString();
String[] SingleCountryData = valueString.split(",");
यहाँ, ',' सीमांकक के रूप में प्रयोग किया जाता है।
इसके बाद, सरणी के 7वें इंडेक्स पर रिकॉर्ड का उपयोग करके एक जोड़ी बनाई जाती है 'सिंगलकंट्रीडेटा' और एक मूल्य '1'.
आउटपुट.collect(नया टेक्स्ट(सिंगलकंट्रीडेटा[7]), एक);
हम 7वें इंडेक्स पर रिकॉर्ड चुन रहे हैं क्योंकि हमें इसकी आवश्यकता है देश डेटा और यह सरणी में 7वें सूचकांक पर स्थित है 'सिंगलकंट्रीडेटा'.
कृपया ध्यान दें कि हमारा इनपुट डेटा नीचे दिए गए प्रारूप में है (जहाँ देश 7 पर हैth सूचकांक, 0 प्रारंभिक सूचकांक के रूप में)-
लेनदेन_तिथि, उत्पाद, मूल्य, भुगतान_प्रकार, नाम, शहर, राज्य,देश,खाता_बनाया_गया,अंतिम_लॉगिन,अक्षांश,देशांतर
मैपर का आउटपुट फिर से एक है मौलिक मूल्य जोड़ी जिसका उपयोग कर आउटपुट किया जाता है 'इकट्ठा करना()' उसकि विधि 'आउटपुटकलेक्टर'.
SalesCountryReducer क्लास का स्पष्टीकरण
इस अनुभाग में हम इसके कार्यान्वयन को समझेंगे सेल्सकंट्रीरिड्यूसर वर्ग.
1. हम अपनी क्लास के लिए पैकेज का नाम निर्दिष्ट करके शुरू करते हैं। बिक्रीदेश हमारे पैकेज का नाम है। कृपया ध्यान दें कि संकलन का आउटपुट, SalesCountryReducer.क्लास इस पैकेज नाम से नामित निर्देशिका में जाएगा: बिक्रीदेश.
इसके बाद, हम लाइब्रेरी पैकेज आयात करते हैं।
नीचे दिया गया स्नैपशॉट इसका कार्यान्वयन दर्शाता है सेल्सकंट्रीरिड्यूसर कक्षा-
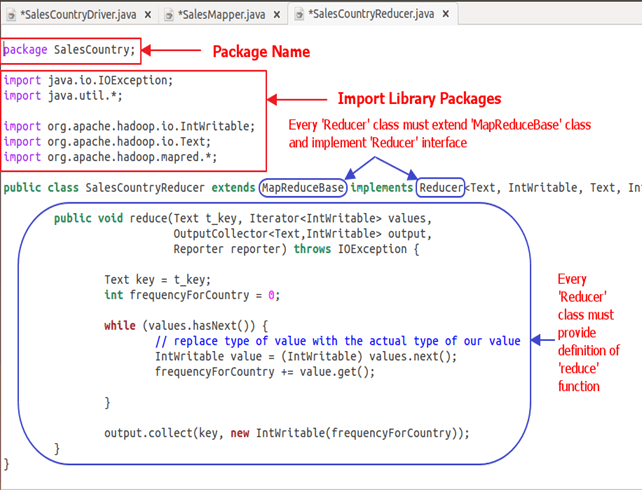
Code स्पष्टीकरण:
1. SalesCountryReducer वर्ग परिभाषा-
सार्वजनिक वर्ग SalesCountryReducer MapReduceBase का विस्तार करता है और Reducer को लागू करता है {
यहाँ, पहले दो डेटा प्रकार, 'मूलपाठ' और 'इंटराइटेबल' रिड्यूसर के लिए इनपुट कुंजी-मान का डेटा प्रकार हैं।
मैपर का आउटपुट इस रूप में है , मैपर का यह आउटपुट रिड्यूसर के लिए इनपुट बन जाता है। इसलिए, इसके डेटा प्रकार के साथ संरेखित करने के लिए, टेक्स्ट और इंटराइटेबल यहाँ डेटा प्रकार के रूप में उपयोग किया जाता है।
अंतिम दो डेटा प्रकार, 'टेक्स्ट' और 'इंटराइटेबल', कुंजी-मूल्य जोड़े के रूप में रिड्यूसर द्वारा उत्पन्न आउटपुट के डेटा प्रकार हैं।
प्रत्येक रिड्यूसर क्लास को विस्तारित किया जाना चाहिए मैपरिड्यूसबेस वर्ग और इसे लागू करना होगा Reducer interface.
2. 'रिड्यूस' फंक्शन को परिभाषित करना-
public void reduce( Text t_key,
Iterator<IntWritable> values,
OutputCollector<Text,IntWritable> output,
Reporter reporter) throws IOException {
एक इनपुट कम करना() विधि एक कुंजी है जिसमें एकाधिक मानों की सूची होती है।
उदाहरण के लिए, हमारे मामले में, यह होगा-
, , , , , .
यह reducer के रूप में दिया जाता है
इसलिए, इस फॉर्म के तर्कों को स्वीकार करने के लिए, पहले दो डेटा प्रकारों का उपयोग किया जाता है, अर्थात, टेक्स्ट और इटरेटर. टेक्स्ट कुंजी का एक डेटा प्रकार है और इटरेटर उस कुंजी के मानों की सूची के लिए एक डेटा प्रकार है।
अगला तर्क इस प्रकार का है आउटपुट कलेक्टर जो रिड्यूसर चरण का आउटपुट एकत्रित करता है।
कम करना() विधि कुंजी मान की प्रतिलिपि बनाकर और आवृत्ति गणना को 0 पर आरंभ करके शुरू होती है।
पाठ कुंजी = t_key;
int आवृत्तिForCountry = 0;
फिर, 'जबकि' लूप में, हम कुंजी से जुड़े मानों की सूची के माध्यम से पुनरावृत्ति करते हैं और सभी मानों को जोड़कर अंतिम आवृत्ति की गणना करते हैं।
while (values.hasNext()) {
// replace type of value with the actual type of our value
IntWritable value = (IntWritable) values.next();
frequencyForCountry += value.get();
}
अब, हम परिणाम को आउटपुट कलेक्टर तक इस रूप में भेजते हैं कुंजी और प्राप्त किया आवृत्ति गणना.
नीचे दिया गया कोड यह करता है-
output.collect(key, new IntWritable(frequencyForCountry));
SalesCountryDriver वर्ग का स्पष्टीकरण
इस अनुभाग में हम इसके कार्यान्वयन को समझेंगे सेल्सकंट्रीड्राइवर कक्षा
1. हम अपनी क्लास के लिए पैकेज का नाम निर्दिष्ट करके शुरू करते हैं। बिक्रीदेश हमारे पैकेज का नाम है। कृपया ध्यान दें कि संकलन का आउटपुट, SalesCountryDriver.क्लास इस पैकेज नाम से नामित निर्देशिका में जाएगा: बिक्रीदेश.
यहां पैकेज का नाम निर्दिष्ट करने वाली एक पंक्ति दी गई है जिसके बाद लाइब्रेरी पैकेज आयात करने के लिए कोड दिया गया है।

2. एक ड्राइवर वर्ग को परिभाषित करें जो एक नया क्लाइंट जॉब, कॉन्फ़िगरेशन ऑब्जेक्ट बनाएगा और मैपर और रिड्यूसर वर्गों को विज्ञापित करेगा।
ड्राइवर वर्ग हमारे MapReduce कार्य को चलाने के लिए सेट करने के लिए जिम्मेदार है Hadoopइस वर्ग में, हम निर्दिष्ट करते हैं जॉब नाम, इनपुट/आउटपुट का डेटा प्रकार और मैपर और रिड्यूसर क्लास के नाम.

3. नीचे दिए गए कोड स्निपेट में, हमने इनपुट और आउटपुट निर्देशिकाएं सेट की हैं जिनका उपयोग क्रमशः इनपुट डेटासेट का उपभोग करने और आउटपुट उत्पन्न करने के लिए किया जाता है।
तर्क[0] और तर्क[1] मैपरिड्यूस हैंड्स-ऑन में दिए गए कमांड के साथ पास किए गए कमांड-लाइन तर्क हैं, यानी,
$HADOOP_HOME/bin/hadoop जार ProductSalePerCountry.jar /inputMapReduce /mapreduce_output_sales

4. हमारी नौकरी को सक्रिय करें
नीचे दिया गया कोड MapReduce जॉब का निष्पादन प्रारंभ करता है-
try {
// Run the job
JobClient.runJob(job_conf);
} catch (Exception e) {
e.printStackTrace();
}